分类器的准确率、召回率以及综合评价指标
引言
需求:如何评价一个分类器的好坏
我们都知道机器学习要建模,但对于模型的好坏(即模型的泛化能力),并不知道是怎样的,可能模型很差,泛化能力弱,对测试集不能很好的预测和分类,所以,为了了解和对比不同模型的泛化能力,我们需要用某个指标来衡量,有了这个指标,我们就可以进一步调参逐步优化我们的模型。
混淆矩阵
假设分类目标只有两类,计为正例(positive)和负例(negative)则有:
1)True positives(TP): 正确划分的正例,实质为正例
2)False positives(FP): 错误划分的正例,实质为负例,然而被划分为正例
3)True negatives(TN):正确划分的负例,实质为正例
4)False negatives(FN):错误划分的负例,实质为正例
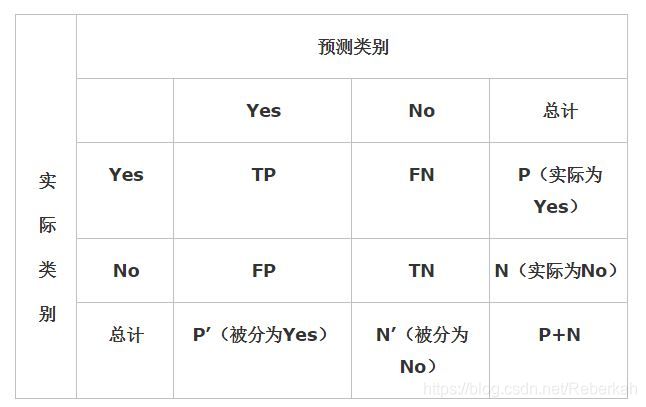 上图是四个术语的混淆矩阵,P代表了实际为正例的样本数,P’代表被划分为正例(划分的准确不准确咱们不知道),这里,其实,只需要知道,true和false代表的是分类器的判断是否准确,yes和no代表的是标签为1和0的样本。整个混淆矩阵的对角线上,代表的都是分类器正确判断的总样本量。
上图是四个术语的混淆矩阵,P代表了实际为正例的样本数,P’代表被划分为正例(划分的准确不准确咱们不知道),这里,其实,只需要知道,true和false代表的是分类器的判断是否准确,yes和no代表的是标签为1和0的样本。整个混淆矩阵的对角线上,代表的都是分类器正确判断的总样本量。
准确率(Accuarcy)
分类指标中,最自然想到的就是准确率,即 预测正确的结果占总样本的百分比。
然而,在样本不均衡的情况下,比如说在ECG信号的预测中,我们截取的心拍中正常样本的数量有70000多,而某些异常心拍数甚至只有几十个,那假设总共的样本量我取90000个,我把所有样本的预测都改为正常心拍,那么,我的准确率怎么说也有
86%左右,虽然不算高,只是举个例子,但实际上我们是无脑操作,这样的模型分类器也并不是我们想要的。
总结下来,由于样本不平衡,导致得到的高准确率结果是注有很大水分的,所以,在这种情况下,咱们盯着accuarcy是无意义的,这时候,就需要看精准率和召回率。
召回率(recall)
实际为正的样本(P)中被分对(TP)的概率,召回率的应用场景:比如说网贷违约,相比较好用户,我们更关心坏用户,召回率越高,说明坏用户被预测出来的概率越高,它的含义类似于,宁可错杀一千,绝不放过一百。
各种评价指标
1)正确率(accuarcy)
最常见的指标,accuarcy=(TP+TN)/ (P+N) ,通常来说,准确率越高,分类器越好。
so,错误率=1-accuary。
2)灵敏度(senstive)
所有正例中被分对的比例,senstive=TP/P,衡量了分类器对于正例的识别能力。
3)特异度(specificity)
所有负例中被分对的比例,specificity=TN/N,衡量了分类器对于负例的识别能力。
这里,我理解的特效,应该是将负例当做一种特殊情况对待。
4)精准率(precision)
表示被分为正例中实际也为正例的比例,precision=TP/(TP+FP)
6)召回率(recall)
同灵敏度
7)其他评价指标
计算速度:分类器训练和预测需要的时间
鲁棒性:处理缺失值和异常的能力
可扩展性:处理大数据集的能力
可解释性:分类器预测结果的可理解性,比如神经网络,只能看成是一个黑盒子。
对于具体的分类器,我们不可能同时提高上面所有的指标,这种分类器也往往不存在。
分类是一种重要的数据挖掘的方法,分类器主要做的就是,将数据对象映射到某一个给定的类别中(废话),分类器的主要评价指标有,精确率(precision),召回率(recall),Fb-score,ROC,AUC,等等。这里注意,准确率(precision),其实也就是精度啦,和正确率(accuarcy)是两回事。
精确率代表对正样本结果中的预测准确程度,而正确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
精确率(Precision) 和召回率(Recall) 是信息检索领域两个最基本的指标。
废话:精确率也称为查准率,召回率也称为查全率。
Fb-score是准确率和召回率的调和平均:Fb=[(1+b2)PR]/(b2*P+R),
比较常用的是F1(即b=1)
精确率和召回率是相互影响的,我们希望两者同时都非常高,实际中,往往精确率高,召回率就低,或者,召回率低,精确率就高。具体问题具体分析,如果想要在二者中找到一个平衡点,可以借助一个指标,F1分数。
介绍ROC和AUC之前,再介绍两个指标,它们是让ROC,AUC可以无视样本不平衡的关键,分别是:灵敏度,1-特异度,也叫做 真正率(TPR)和假正率(FPR)
灵敏度(Sensitivity) = TP/(TP+FN)
特异度(Specificity) = TN/(FP+TN)
可以看出灵敏度和召回率一模一样,假正率(FPR) = 1- 特异度 = FP/(FP+TN)
我们发现TPR和FPR分别是基于实际表现1和0出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。总样本中,90%是正样本,10%是负样本。我们知道用准确率是有水分的,但是用TPR和FPR不一样。这里,TPR只关注90%正样本中有多少是被真正覆盖的,而与那10%毫无关系,同理,FPR只关注10%负样本中有多少是被错误覆盖的,也与那90%毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用TPR和FPR作为ROC/AUC的指标的原因。
ROC AUC
ROC( receiver operating characteristic curve )曲线,其中横坐标为假正率(FPR),纵坐标为真正率(TPR)
假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
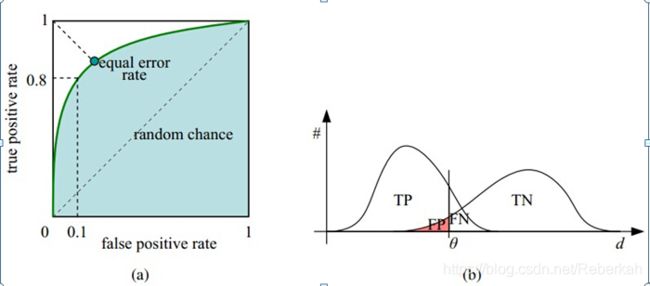
ROC的阈值问题
前面的P-R曲线类似,ROC曲线也是通过遍历所有阈值来绘制整条曲线的。如果我们不断的遍历所有阈值,预测的正样本和负样本是在不断变化的,相应的在ROC曲线图中也会沿着曲线滑动。
如何判断ROC曲线的好坏
改变阈值,只是不断地改变预测的正负样本量,但曲线本身不会变,这个还是要回归到我们的目的:FPR表示模型虚报的响应程度,而TPR表示模型预测响应的覆盖程度。我们所希望的当然是:虚报的越少越好,覆盖的越多越好。所以总结一下就是TPR越高,同时FPR越低(即ROC曲线越陡),那么模型的性能就越好。
ROC曲线是无视样本不平衡的。
为了计算 ROC 曲线上的点,我们可以使用不同的分类阈值多次评估逻辑回归模型,但这样做效率非常低。幸运的是,有一种基于排序的高效算法可以为我们提供此类信息,这种算法称为曲线下面积(Area Under Curve)。
AUC的一般判断标准
0.5 - 0.7:效果较低,但用于预测股票已经很不错了
0.7 - 0.85:效果一般
0.85 - 0.95:效果很好
0.95 - 1:效果非常好,但一般不太可能
写在后面:导师让了解的一些关于分类器的评价标准,于是整理了一些,感谢前辈们的科普,关于AUC,ROC有了一些概念上认识,后续会更新在实践中对于这两个评价指标的深入认识。