语言模型(language model)
文章目录
- 引言
- 1. 什么是语言模型
- 2. 语言模型的主要用途
-
- 2.1 言模型-语音识别
- 2.2 语言模型-手写识别
- 2.3 语言模型-输入法
- 3. 语言模型的分类
- 4. N-gram语言模型
-
- 4.1 N-gram语言模型-平滑方法
- 4.2 ngram代码
- 4.3 语言模型的评价指标
- 4.4 两类语言模型的对比
- 5. 神经网络语言模型
- 6. 语言模型的应用
-
- 6.1 语言模型的应用-话者分离
- 6.2 语言模型的应用-文本纠错
- 6.3 语言模型的应用-数字归一化
- 6.4 语言模型的应用-文本打标
- 7. 总结
引言
语言模型是一种用于预测文本序列中下一个词或字符的概率分布的模型。它可以捕获语言结构的某些方面,如语法、句式和上下文信息。传统的语言模型通常使用N-gram方法或隐藏马尔可夫模型,但这些模型往往不能捕捉到长距离依赖和复杂的语义信息。
1. 什么是语言模型
通俗来讲
语言模型评价一句话是否“合理”或“是人话”
数学上讲
P(今天天气不错) > P(今错不天天气)
语言模型用于计算文本的成句概率
2. 语言模型的主要用途
2.1 言模型-语音识别
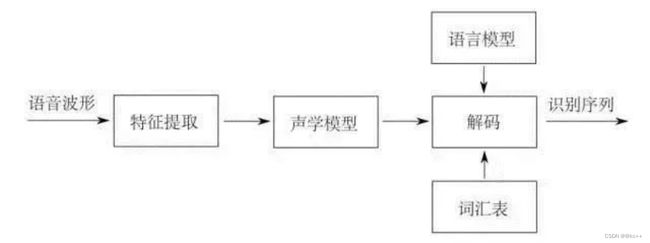
- 语音识别:声音 -> 文本
- 声音本质是一种波

- 将波按时间段切分很多帧,如25ms一段
- 之后进行声学特征提取,将每一帧转化成一个向量
- 以声学特征提取后的向量为输入,经过声学模型,预测得到音素
- 音素与拼音类似,但要考虑声调
- 音素序列对应多条文本序列,由语言模型挑选出成句概率最高的序列
- 使用beam search或维特比的方式解码
- 语音识别示意图
2.2 语言模型-手写识别

- 识别模型将图片中文字转化为候选汉字(一般分定位和识别两步),再有语言模型挑选出成句概率最高的序列
2.3 语言模型-输入法
- 输入即为拼音序列,每个拼音自然的有多个候选汉字,根据语言模型挑选高概率序列
- 输入法是一个细节繁多的任务,在语言模型这一基础算法上,需要考虑常见的打字手误,常见误读,拼音缩略,中英混杂,输出符号,用户习惯等能力
- 手写输入法,语音输入法同理
3. 语言模型的分类
- 基于统计语言模型
- 对于一份语料进行词频、词序、词共现的统计
- 计算相关概率得到语言模型
- 代表:N-gram语言模型
- 基于神经网络的语言模型
- 根据设定好的网络结构使用语料进行模型训练
- 代表:LSTM语言模型,BERT等
- 自回归(auto regressive)语言模型
- 在训练时由上文预测下文(或反过来)
- 单向模型,仅使用单侧序列信息
- 代表:N-gram,ELMO
- 自编码(auto encoding)语言模型
- 在训练时预测序列中任意位置的字符
- 双向模型,吸收上下文信息
- 代表:BERT
4. N-gram语言模型
N-gram语言模型是一种基础的语言模型,用于预测下一个词或字符出现的概率,基于前N-1个词或字符。该模型将文本看作是词或字符的有序序列,并假设第n个词仅与前N-1个词相关。
比如,在一个bigram(2-gram)模型中,每个词的出现只依赖于它前面的一个词。例如,"我吃"之后是"苹果"的概率可以表示为P(苹果|我吃)。
优点:
- 计算简单:只需要统计词频和条件词频。
- 实现容易:不需要复杂的算法。
缺点:
- 稀疏性问题:随着N的增加,模型需要的存储空间急剧增加,而大多数N-gram组合在实际数据中可能并不存在。
- 上下文限制:只能捕捉到N-1个词的上下文信息。
尽管有这些局限性,N-gram模型由于其简单和高效仍然在很多应用场景中被广泛使用,如拼写检查、语音识别和机器翻译等。
如何计算成句概率?
- 用S代表句子,w代表单个字或词
- S = w1w2w3w4w5…wn
- P(S) = P(w1,w2,w3,w4,w5…wn)
- 成句概率 -> 词W1~Wn按顺序出现的概率
- P(w1,w2,w3,…,wn) = P(w1)P(w2|w1)P(w3|w1,w2)…P(wn|w1,…,wn-1)
以字为单位
- P(今天天气不错) = P(今)*P(天|今) *P(天|今天) *P(气|今天天) *P(不|今天天气) *P(错|今天天气不)
以词为单位
- P(今天 天气 不错) = P(今天)*P(天气|今天) *P(不错|今天 天气)
如何计算P(今天)?
- P(今天) = Count(今天) / Count_total 语料总词数
- P(天气|今天) = Count(今天 天气) / Count(今天)
- P(不错|今天 天气) = Count(今天 天气 不错) / Count(今天 天气)
- 二元组:今天 天气 2 gram
- 三元组:今天 天气 不错 3 gram
困难:句子太多了!
- 对任意一门语言,N-gram数量都非常庞大,无法穷举,需要简化
马尔科夫假设
- P(wn|w1,…,wn-1) ≈ P(wn|wn-3,wn-2,wn-1)
- 假设第n个词出现的概率,仅受其前面有限个词影响
- P(今天天气不错) = P(今)*P(天|今) *P(天|今天) *P(气|天天) *P(不|天气) *P(错|气不)
马尔科夫假设的缺陷:
- 影响第n个词的因素可能出现在前面很远的地方
long distance dependency例:我读过关于马尔科夫的生平的书
我看过关于马尔科夫的生平的电影
我听过关于马尔科夫的生平的故事
- 影响第n个词的因素可能出现在其后面
- 影响第n个词的因素可能并不在文中
但是,马尔科夫假设下依然可以得到非常有效的模型
语料:
今天 天气 不错 P(今天) = 3 / 12 = 1/4
明天 天气 不错 P(天气|今天) = 2 / 3
今天 天气 不行 P(不错|今天 天气) = 1 / 2
今天 是 晴天 P(不错|天气) = 2/3
3 gram模型
P(今天 天气 不错) = P(今天)*P(天气|今天) *P(不错|今天 天气) = 1 / 12
2 gram模型
P(今天 天气 不错) = P(今天)*P(天气|今天) *P(不错|天气) = 1 / 9
语料:
今天 天气 不错 P(今天) = 3 / 12 = 1/4
明天 天气 不错 P(天气|今天) = 2 / 3
今天 天气 不行 P(不错|今天 天气) = 1 / 2
今天 是 晴天 P(不错|天气) = 2/3
问题:如何给出语料中没出现过的词或ngram概率?
P(今天 天气 糟糕) = P(今天)*P(天气|今天) *P(糟糕|天气)
- 平滑问题(smoothing)
- 理论上说,任意的词组合成的句子,概率都不应当为零
- 如何给没见过的词或ngram分配概率即为平滑问题
- 也称折扣问题(discounting)
4.1 N-gram语言模型-平滑方法
- 回退(backoff)
当三元组a b c不存在时,退而寻找b c二元组的概率
P(c | a b) = P(c | b) * Bow(ab)
Bow(ab)称为二元组a b的回退概率
回退概率有很多计算方式,甚至可以设定为常数
回退可以迭代进行,如序列 a b c d
P(d | a b c) = P(d | b c) * Bow(abc)
P(d | bc) = P(d | c) * Bow(bc)
P(d | c ) = P(d) * Bow©
P(word)不存在如何处理
加1平滑 add-one smooth
对于1gram概率P(word) = Count(word)+1/Count(total_word)+V
V为词表大小
对于高阶概率同样可以

将低频词替换为
预测中遇到的未见过的词,也用代替
一语成谶 -> 一语成
P(|一 语 成)
这是一种nlp处理未登录词(OOV)的常见方法
插值
受到回退平滑的启发,在计算高阶ngram概率是同时考虑低阶的ngram概率值,以插值给出最终结果
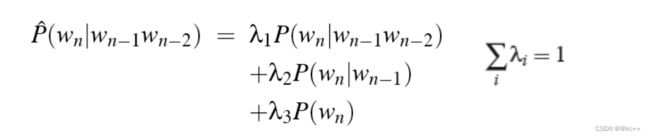
实践证明,这种方式效果有提升
λ 可以在验证集上调参确定
4.2 ngram代码
import math
from collections import defaultdict
class NgramLanguageModel:
def __init__(self, corpus=None, n=3):
self.n = n
self.sep = "_" # 用来分割两个词,没有实际含义,只要是字典里不存在的符号都可以
self.sos = "" #start of sentence,句子开始的标识符
self.eos = "" #end of sentence,句子结束的标识符
self.unk_prob = 1e-5 #给unk分配一个比较小的概率值,避免集外词概率为0
self.fix_backoff_prob = 0.4 #使用固定的回退概率
self.ngram_count_dict = dict((x + 1, defaultdict(int)) for x in range(n))
self.ngram_count_prob_dict = dict((x + 1, defaultdict(int)) for x in range(n))
self.ngram_count(corpus)
self.calc_ngram_prob()
#将文本切分成词或字或token
def sentence_segment(self, sentence):
return sentence.split()
#return jieba.lcut(sentence)
#统计ngram的数量
def ngram_count(self, corpus):
for sentence in corpus:
word_lists = self.sentence_segment(sentence)
word_lists = [self.sos] + word_lists + [self.eos] #前后补充开始符和结尾符
for window_size in range(1, self.n + 1): #按不同窗长扫描文本
for index, word in enumerate(word_lists):
#取到末尾时窗口长度会小于指定的gram,跳过那几个
if len(word_lists[index:index + window_size]) != window_size:
continue
#用分隔符连接word形成一个ngram用于存储
ngram = self.sep.join(word_lists[index:index + window_size])
self.ngram_count_dict[window_size][ngram] += 1
#计算总词数,后续用于计算一阶ngram概率
self.ngram_count_dict[0] = sum(self.ngram_count_dict[1].values())
return
#计算ngram概率
def calc_ngram_prob(self):
for window_size in range(1, self.n + 1):
for ngram, count in self.ngram_count_dict[window_size].items():
if window_size > 1:
ngram_splits = ngram.split(self.sep) #ngram :a b c
ngram_prefix = self.sep.join(ngram_splits[:-1]) #ngram_prefix :a b
ngram_prefix_count = self.ngram_count_dict[window_size - 1][ngram_prefix] #Count(a,b)
else:
ngram_prefix_count = self.ngram_count_dict[0] #count(total word)
# word = ngram_splits[-1]
# self.ngram_count_prob_dict[word + "|" + ngram_prefix] = count / ngram_prefix_count
self.ngram_count_prob_dict[window_size][ngram] = count / ngram_prefix_count
return
#获取ngram概率,其中用到了回退平滑,回退概率采取固定值
def get_ngram_prob(self, ngram):
n = len(ngram.split(self.sep))
if ngram in self.ngram_count_prob_dict[n]:
#尝试直接取出概率
return self.ngram_count_prob_dict[n][ngram]
elif n == 1:
#一阶gram查找不到,说明是集外词,不做回退
return self.unk_prob
else:
#高于一阶的可以回退
ngram = self.sep.join(ngram.split(self.sep)[1:])
return self.fix_backoff_prob * self.get_ngram_prob(ngram)
#回退法预测句子概率
def calc_sentence_ppl(self, sentence):
word_list = self.sentence_segment(sentence)
word_list = [self.sos] + word_list + [self.eos]
sentence_prob = 0
for index, word in enumerate(word_list):
ngram = self.sep.join(word_list[max(0, index - self.n + 1):index + 1])
prob = self.get_ngram_prob(ngram)
# print(ngram, prob)
sentence_prob += math.log(prob)
return 2 ** (sentence_prob * (-1 / len(word_list)))
if __name__ == "__main__":
corpus = open("sample.txt", encoding="utf8").readlines()
lm = NgramLanguageModel(corpus, 3)
print("词总数:", lm.ngram_count_dict[0])
print(lm.ngram_count_prob_dict)
print(lm.calc_sentence_ppl("e f g b d"))
4.3 语言模型的评价指标
- 困惑度 perplexity

- PPL值与成句概率成反比
一般使用合理的目标文本来计算PPL,若PPL值低,则说明成句概率高,也就说明由此语言模型来判断,该句子的合理性高,这样是一个好的语言模型
- 另一种PPL,用对数求和代替小数乘积
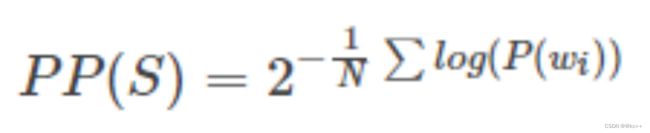
- 本质是相同的,与成句概率呈反比
- 思考:PPL越小,语言模型效果越好,这一结论是否正确?
- 成句概率是个相对值!
4.4 两类语言模型的对比

5. 神经网络语言模型
- Bengio et al. 2003
- 与ngram模型相似使用前n个词预测下一个词
- 输出在字表上的概率分布
- 得到了词向量这一副产品
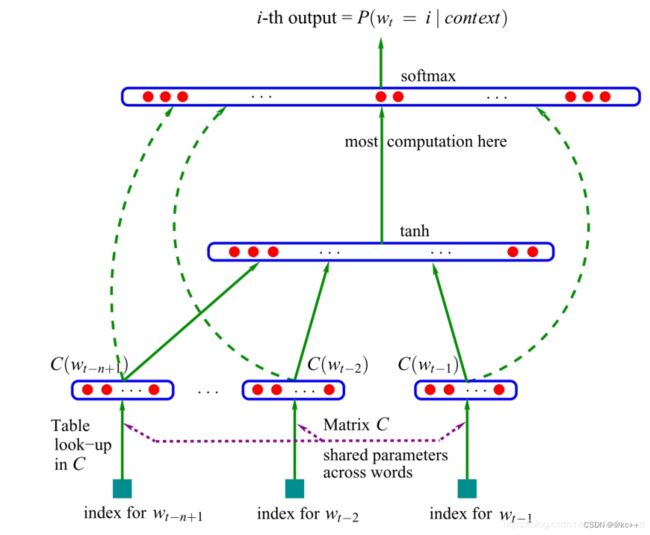
- 随着相关研究的发展,隐含层模型结构的复杂度不断提升
- DNN -> CNN/RNN -> LSTM/GRU -> transformer

- Devlin et al. 2018 BERT 诞生
- 主要特点:不再使用预测下一个字的方式训练语言模型,转而预测文本中被随机遮盖的某个字
- 这种方式被称为MLM(masked language model)
- 实际上这种方式被提出的时间非常早,并非bert原创
代码
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
import math
import random
import os
import re
import matplotlib.pyplot as plt
"""
基于pytorch的rnn语言模型
"""
class LanguageModel(nn.Module):
def __init__(self, input_dim, vocab):
super(LanguageModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim)
self.layer = nn.RNN(input_dim, input_dim, num_layers=2, batch_first=True)
self.classify = nn.Linear(input_dim, len(vocab) + 1)
self.dropout = nn.Dropout(0.1)
self.loss = nn.functional.cross_entropy
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #output shape:(batch_size, sen_len, input_dim)
x, _ = self.layer(x) #output shape:(batch_size, sen_len, input_dim)
x = x[:, -1, :] #output shape:(batch_size, input_dim)
x = self.dropout(x)
y_pred = self.classify(x) #output shape:(batch_size, input_dim)
if y is not None:
return self.loss(y_pred, y)
else:
return torch.softmax(y_pred, dim=-1)
#读取语料获得字符集
#输出一份
def build_vocab_from_corpus(path):
vocab = set()
with open(path, encoding="utf8") as f:
for index, char in enumerate(f.read()):
vocab.add(char)
vocab.add("" ) #增加一个unk token用来处理未登录词
writer = open("vocab.txt", "w", encoding="utf8")
for char in sorted(vocab):
writer.write(char + "\n")
return vocab
#加载字表
def build_vocab(vocab_path):
vocab = {}
with open(vocab_path, encoding="utf8") as f:
for index, line in enumerate(f):
char = line[:-1] #去掉结尾换行符
vocab[char] = index + 1 #留出0位给pad token
vocab["\n"] = 1
return vocab
#加载语料
def load_corpus(path):
return open(path, encoding="utf8").read()
#随机生成一个样本
#从文本中截取随机窗口,前n个字作为输入,最后一个字作为输出
def build_sample(vocab, window_size, corpus):
start = random.randint(0, len(corpus) - 1 - window_size)
end = start + window_size
window = corpus[start:end]
target = corpus[end]
# print(window, target)
x = [vocab.get(word, vocab["" ]) for word in window] #将字转换成序号
y = vocab[target]
return x, y
#建立数据集
#sample_length 输入需要的样本数量。需要多少生成多少
#vocab 词表
#window_size 样本长度
#corpus 语料字符串
def build_dataset(sample_length, vocab, window_size, corpus):
dataset_x = []
dataset_y = []
for i in range(sample_length):
x, y = build_sample(vocab, window_size, corpus)
dataset_x.append(x)
dataset_y.append(y)
return torch.LongTensor(dataset_x), torch.LongTensor(dataset_y)
#建立模型
def build_model(vocab, char_dim):
model = LanguageModel(char_dim, vocab)
return model
#计算文本ppl
def calc_perplexity(sentence, model, vocab, window_size):
prob = 0
model.eval()
with torch.no_grad():
for i in range(1, len(sentence)):
start = max(0, i - window_size)
window = sentence[start:i]
x = [vocab.get(char, vocab["" ]) for char in window]
x = torch.LongTensor([x])
target = sentence[i]
target_index = vocab.get(target, vocab["" ])
if torch.cuda.is_available():
x = x.cuda()
pred_prob_distribute = model(x)[0]
target_prob = pred_prob_distribute[target_index]
prob += math.log(target_prob, 10)
return 2 ** (prob * ( -1 / len(sentence)))
def train(corpus_path, save_weight=True):
epoch_num = 10 #训练轮数
batch_size = 128 #每次训练样本个数
train_sample = 10000 #每轮训练总共训练的样本总数
char_dim = 128 #每个字的维度
window_size = 6 #样本文本长度
vocab = build_vocab("vocab.txt") #建立字表
corpus = load_corpus(corpus_path) #加载语料
model = build_model(vocab, char_dim) #建立模型
if torch.cuda.is_available():
model = model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=0.001) #建立优化器
for epoch in range(epoch_num):
model.train()
watch_loss = []
for batch in range(int(train_sample / batch_size)):
x, y = build_dataset(batch_size, vocab, window_size, corpus) #构建一组训练样本
if torch.cuda.is_available():
x, y = x.cuda(), y.cuda()
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
watch_loss.append(loss.item())
loss.backward() #计算梯度
optim.step() #更新权重
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
if not save_weight:
return
else:
base_name = os.path.basename(corpus_path).replace("txt", "pth")
model_path = os.path.join("model", base_name)
torch.save(model.state_dict(), model_path)
return
#训练corpus文件夹下的所有语料,根据文件名将训练后的模型放到莫得了文件夹
def train_all():
for path in os.listdir("corpus"):
corpus_path = os.path.join("corpus", path)
train(corpus_path)
if __name__ == "__main__":
# build_vocab_from_corpus("corpus/all.txt")
# train("corpus.txt", True)
train_all()
6. 语言模型的应用
6.1 语言模型的应用-话者分离
- 根据说话内容判断说话人
- 常用于语言识别系统中,判断录音对话中角色
- 如客服对话录音,判断坐席或客户
- 根据不同腔调判断说话人
- 翻译腔: 这倒霉的房子里竟然有蟑螂,你可以想象到吗?这真是太可怕了!
- 港台腔:你这个人怎么可以这个样子
- 东北味: 我不稀得说你那些事儿就拉倒了
- 本质上为文本分类任务
- 对于每个类别,使用类别语料训练语言模型
- 对于一个新输入的文本,用所有语言模型计算成句概率
- 选取概率最高的类别为预测类别

- 相比一般文本分类模型,如贝叶斯,rf,神经网络等
- 优势:
- 每个类别模型互相独立,样本不均衡或样本有错误对其他模型没有影响
- 可以随时增加新的类别,而不影响旧的类别的效果
- 效果上讲:一般不会有显著优势
- 效率上讲:一般会低于统一的分类模型
6.2 语言模型的应用-文本纠错
- 纠正文本中的错误
- 如:
- 我今天去了天暗门看人民英雄记念碑
- 我今天去了天安门看人民英雄纪念碑
- 错误可能是同音字或形近字等
- 对每一个字建立一个混淆字集合
- 计算整句话成句概率
- 用混淆字集合中的词替代原句中的字,重新计算概率
- 选取得分最高的一个候选句子,如果这个句子比原句的得分增长超过一定的阈值
- 对下一个字重复步骤3-4,直到句子末尾

这种方式有一些缺陷:
- 无法解决多字少字问题
- 阈值的设置非常难把握,如果设置过大,达不到纠错效果;如果设置过小,造成大量替换,有可能改变句子的原意
- 混淆字字表难以完备
- 语言模型的领域性会影响修改结果
- 连续的错字会大幅提升纠错难度
- 一般工业做法:
- 限定一个修改白名单,只判断特定的字词是否要修改
- 如限定只对所有发音为shang wu的片段,计算是否修改为“商务”,其余一概不做处理
- 对于深度学习模型而言,错别字是可以容忍的,所以纠错本身的重要性在下降,一般只针对展示类任务
6.3 语言模型的应用-数字归一化
- 将一个文本中的数字部分转化成对读者友好的样式
- 常见于语言识别系统后,展示文本时使用
- 如:
- 秦皇岛港煤炭库存量在十一月初突然激增,从四百五十四点九万吨增加到七百七十三点四万吨,打破了一九九九年以来的记录
- 秦皇岛港煤炭库存量在11月初突然激增,从454.9万吨增加到773.4万吨,打破了1999年以来的记录
- 找到数字形式符合规范的文本作为原始语料
- 用正则表达式找到数字部分(任意形式)
- 将数字部分依照其格式替换为<阿拉伯数字><汉字数字><汉字连读>等token
- 使用带token文本训练语言模型
- 对于新输入的文本,同样使用正则表达式找到数字部分,之后分别带入各个token,使用语言模型计算概率
- 选取概率最高的token最为最终数字格式,按照规则转化后填入原文本
6.4 语言模型的应用-文本打标

- 本质为序列标注任务
- 可以依照类似方式,处理分词、文本加标点、文本段落切分等任务
- 分词或切分段落只需要一种token;打标点时,可以用多种分隔token,代表不同标点
7. 总结
- 语言模型的核心能力是计算成句概率,依赖这一能力,可以完成大量不同类型的NLP任务。
- 基于统计的语言模型和基于神经网络的语言模型各有使用的场景,大体上讲,基于统计的模型优势在于解码速度,而神经网络的模型通常效果更好。
- 单纯通过PPL评价语言模型是有局限的,通过下游任务效果进行整体评价更好。
- 深入的理解一种算法,有助于发现更多的应用方式。
- 看似简单(甚至错误)的假设,也能带来有意义的结果,事实上,这是简化问题的常见方式。