Spark基础学习笔记05:搭建Spark Standalone集群
文章目录
零、本讲学习目标
搭建Spark Standalone模式的集群
能够启动Spark Standalone模式的集群
学会Spark应用程序的提交
Spark的两种集群运行模式:Spark Standalone模式和Spark On YARN模式。Standalone模式需要启动Spark集群,而Spark On YARN模式不需要启动Spark集群,只需要启动YARN集群即可。先来搭建Spark Standalone模式的集群。
一、Spark Standalone架构
Spark Standalone模式为经典的Master/Slave(主/从)架构,资源调度是Spark自己实现的。在Standalone模式中,根据应用程序提交的方式不同,Driver(主控进程)在集群中的位置也有所不同。应用程序的提交方式主要有两种:client和cluster,默认是client。可以在向Spark集群提交应用程序时使用–deploy-mode参数指定提交方式。
(一)client提交方式
当提交方式为client时,运行架构如下图所示
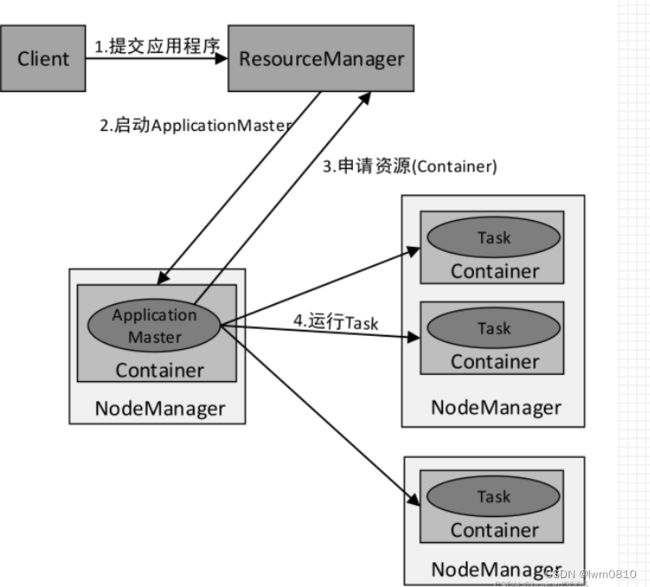
集群的主节点称为Master节点,在集群启动时会在主节点启动一个名为Master的守护进程,类似YARN集群的ResourceManager;从节点称为Worker节点,在集群启动时会在各个从节点上启动一个名为Worker的守护进程,类似YARN集群的NodeManager。
Spark在执行应用程序的过程中会启动Driver和Executor两种JVM进程。
Driver为主控进程,负责执行应用程序的main()方法,创建SparkContext对象(负责与Spark集群进行交互),提交Spark作业,并将作业转化为Task(一个作业由多个Task任务组成),然后在各个Executor进程间对Task进行调度和监控。通常用SparkContext代表Driver。在上图的架构中,Spark会在客户端启动一个名为SparkSubmit的进程,Driver程序则运行于该进程。
Executor为应用程序运行在Worker节点上的一个进程,由Worker进程启动,负责执行具体的Task,并存储数据在内存或磁盘上。每个应用程序都有各自独立的一个或多个Executor进程。在Spark Standalone模式和Spark on YARN模式中,Executor进程的名称为CoarseGrainedExecutorBackend,类似运行MapReduce程序所产生的YarnChild进程,并且同时与Worker、Driver都有通信。
(二)cluster提交方式
当提交方式为cluster时,运行架构如下图所示

Standalone cluster提交方式提交应用程序后,客户端仍然会产生一个名为SparkSubmit的进程,但是该进程会在应用程序提交给集群之后就立即退出。当应用程序运行时,Master会在集群中选择一个Worker进程启动一个名为DriverWrapper的子进程,该子进程即为Driver进程,所起的作用相当于YARN集群的ApplicationMaster角色,类似MapReduce程序运行时所产生的MRAppMaster进程。
二、Spark集群拓扑
(一)集群拓扑
一个主节点,两个从节点

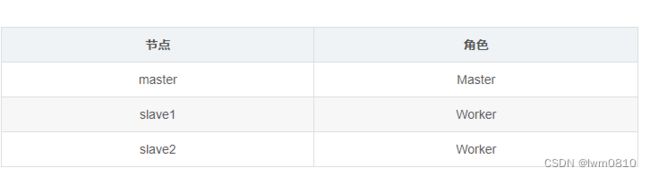
(二)集群角色分配
Spark Standalone模式的集群搭建需要在集群的每个节点都安装Spark,集群角色分配如下表所示。
三、搭建三节点集群
(一)在私有云上创建三台虚拟机
创建配置过程,参看本博《在OpenStack私有云上创建与配置虚拟机》
(二)利用FinalShell登录三台虚拟机
在宿主机win7上启动FinalShell

1、创建SSH连接
创建三个SSH连接,连接master、slave1和slave2三个节点

1、登录master虚拟机
单击连接管理器里的master,登录master虚拟机

测试能否ping通百度 - www.baidu.com

2、登录slave1虚拟机
单击连接管理器里的slave1,登录slave1虚拟机
测试能否ping通百度 - www.baidu.com
3、登录slave2虚拟机
单击连接管理器里的slave2,登录slave2虚拟机
测试能否ping通百度 - www.baidu.com
(三)查看三台虚拟机主机名
查看master虚拟机主机名
查看slave1虚拟机主机名

查看slave2虚拟机主机名
设置主机名命令:hostnamectl set-hostname <主机名>
(四)配置三台虚拟机IP-主机名映射
在三台虚拟机上安装vim编辑器,执行命令:yum -y install vim
1、配置master虚拟机IP-主机名映射
执行命令:vim /etc/hosts
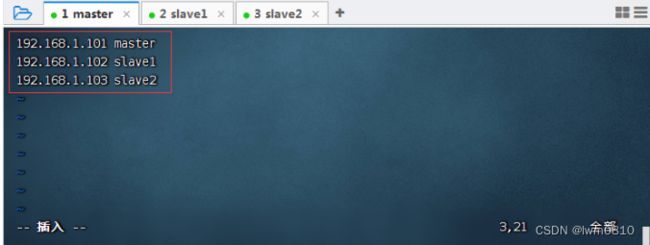
查看主机映射配置文件
2、配置slave1虚拟机IP-主机名映射
执行命令:vim /etc/hosts

查看主机映射配置文件
3、配置slave2虚拟机IP-主机名映射
执行命令:vim /etc/hosts
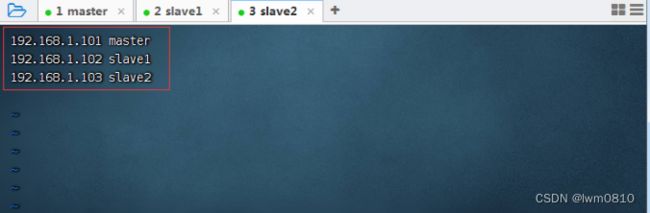
查看主机映射配置文件
(五)关闭与禁用防火墙
1、了解相关命令
(1)关闭防火墙命令
systemctl stop firewalld
(2)禁用防火墙命令
systemctl disable firewalld
(3)查看防火墙状态
systemctl status firewalld
2、关闭与禁用防火墙
(1)关闭与禁用master虚拟机防火墙
关闭防火墙

禁用防火墙

查看防火墙状态

(2)关闭与禁用slave1虚拟机防火墙
关闭防火墙
禁用防火墙
查看防火墙状态
(3)关闭与禁用slave2虚拟机防火墙
关闭防火墙
禁用防火墙
查看防火墙状态
(六)关闭SeLinux安全机制
安全增强型 Linux(Security-Enhanced Linux)简称 SELinux,它是一个 Linux 内核模块,也是 Linux 的一个安全子系统。
SELinux 主要作用就是最大限度地减小系统中服务进程可访问的资源(最小权限原则)。
SELinux 有三种工作模式,分别是enforcing:强制模式;permissive:宽容模式;disabled:关闭 SELinux。
/etc/sysconfig/selinux 文件里SELINUX=enforcing,将enforcing改成disabled,就可以关闭SeLinux安全机制
1、在master虚拟机上关闭SeLinux安全机制
执行命令:vim /etc/sysconfig/selinux

2、在slave1虚拟机上关闭SeLinux安全机制
执行命令:vim /etc/sysconfig/selinux
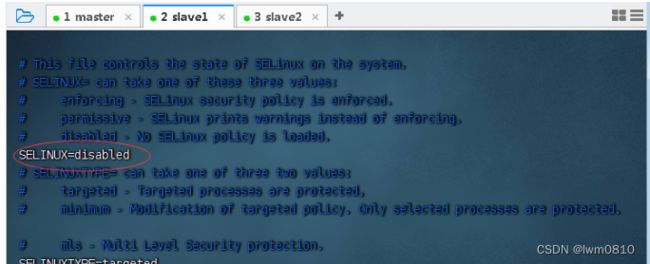
3、在slave2虚拟机上关闭SeLinux安全机制
执行命令:vim /etc/sysconfig/selinux

(七)设置三台虚拟机免密登录
1、master虚拟机免密登录master
执行命令:ssh-keygen,生成密钥对

执行命令:ssh-copy-id root@master,将公钥拷贝到master

测试master节点是否免密登录自己

2、master虚拟机免密登录slave1
执行命令:ssh-copy-id root@slave1,将公钥拷贝到slave1

测试master节点是否免密登录slave1

3、master虚拟机免密登录slave2
执行命令:ssh-copy-id root@slave2,将公钥拷贝到slave2

测试master节点是否免密登录slave2
(八)上传大数据相关软件到虚拟机
在win7虚拟机上查看相关软件

上传到master虚拟机/opt目录

(九)在三台虚拟机上安装配置JDK
1、在master虚拟机上安装配置JDK
进入/opt目录

执行命令:tar -zxvf jdk-8u162-linux-x64.tar.gz -C /usr/local,将Java安装包解压到指定目录

执行命令:ll /usr/local/jdk1.8.0_162,查看解压之后的jdk1.8.0_162目录

执行命令:vim /etc/profile,配置环境变量

存盘退出,执行命令:source /etc/profile,让配置生效

查看JDK版本

编写一个Java程序 - HelloWorld.java
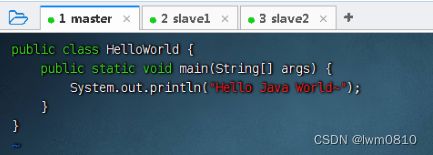
存盘退出后,执行命令:javac HelloWorld.java,编译成字节码文件
执行命令:java HelloWorld
2、将master虚拟机上安装的JDK分发到slave1和slave2虚拟机
执行命令:scp -r J A V A H O M E r o o t @ s l a v e 1 : JAVA_HOME root@slave1: JAVAHOMEroot@slave1:JAVA_HOME (-r recursive - 递归)

在slave1虚拟机上查看JDK是否拷贝成功

执行命令:scp -r J A V A H O M E r o o t @ s l a v e 2 : JAVA_HOME root@slave2: JAVAHOMEroot@slave2:JAVA_HOME (-r recursive - 递归)

在slave2虚拟机上查看JDK是否拷贝成功

3、将master虚拟机上环境配置文件分发到slave1和slave2虚拟机
执行命令:scp /etc/profile root@slave1:/etc

执行命令:scp /etc/profile root@slave2:/etc

在slave1与slave2节点上执行命令:source /etc/profile,让环境配置生效
四、配置完全分布式Hadoop
(一)在master虚拟机上安装配置hadoop
1、将hadoop安装包解压到指定位置
执行命令:tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local

查看解压之后的hadoop目录(bin: 可执行文件;etc/hadoop: 配置目录;sbin: 启动关闭系统的命令)

2、配置hadoop环境变量
执行命令:vim /etc/profile

存盘退出,执行命令:source /etc/profile,让配置生效
3、编辑Hadoop环境配置文件 - hadoop-env.sh
执行命令:cd $HADOOP_HOME/etc/hadoop,进入hadoop配置目录
执行命令:vim hadoop-env.sh

存盘退出后,执行命令source hadoop-env.sh,让配置生效
查看三个配置的三个环境变量
4、编辑Hadoop核心配置文件 - core-site.xml
执行命令:vim core-site.xml
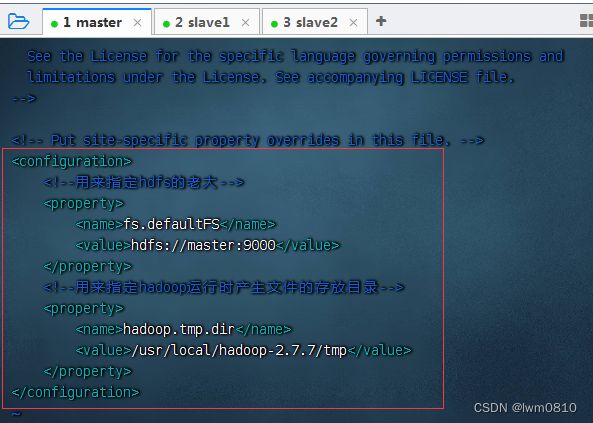
由于配置了IP地址主机名映射,因此配置HDFS老大节点可用hdfs://master:9000,否则必须用IP地址hdfs://192.168.1.101:9000
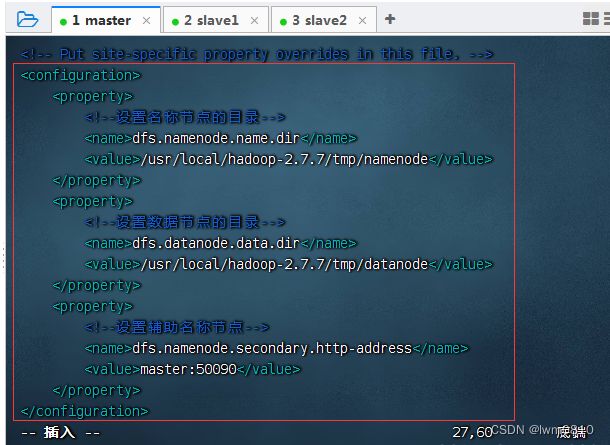
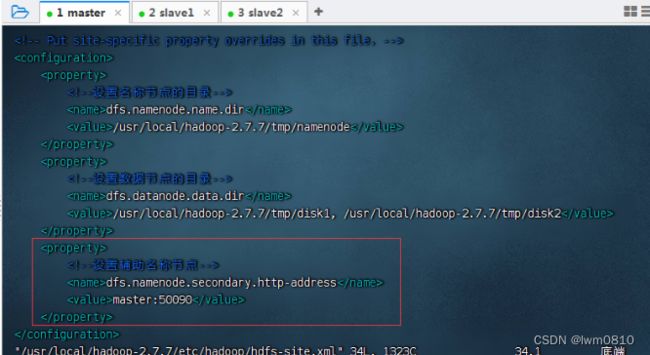
5、编辑HDFS配置文件 - hdfs-site.xml
执行命令:vim hdfs-site.xml
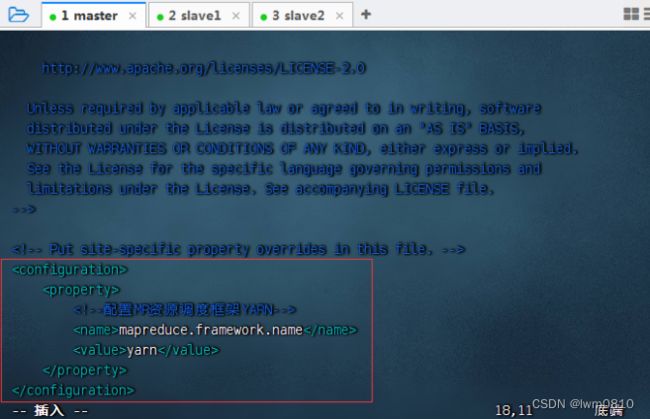
6、编辑MapReduce配置文件 - mapred-site.xml
基于模板生成配置文件,执行命令:cp mapred-site.xml.template mapred-site.xml

执行命令:vim mapred-site.xml
7、编辑yarn配置文件 - yarn-site.xml
执行命令:vim yarn-site.xml

说明:在hadoop-3.0.0的配置中,yarn.nodemanager.aux-services项的默认值是“mapreduce.shuffle”,但如果在hadoop-2.7 中继续使用这个值,NodeManager 会启动失败,必须改成“mapreduce_shuffle”。
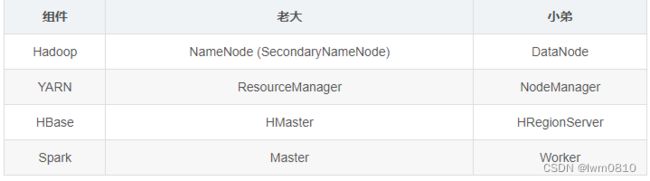
补充:大数据组件的老大和小弟
8、编辑slaves文件(定名分)
通过slaves文件定义从节点,有两个:slave1与slave2
执行命令:vim slaves

如此配置,数据节点在slave1和slave2上,master上就不会有数据节点
(二)在slave1虚拟机上安装配置hadoop
1、将master虚拟机上的hadoop分发到slave1虚拟机
执行命令:scp -r H A D O O P H O M E r o o t @ s l a v e 1 : HADOOP_HOME root@slave1: HADOOPHOMEroot@slave1:HADOOP_HOME

在slave1节点上查看分发的hadoop

2、将master虚拟机上环境配置文件分发到slave1虚拟机
执行命令:scp /etc/profile root@slave1:/etc/profile

3、在slave1虚拟机上让环境配置生效
切换到slave1虚拟机,执行命令:source /etc/profile

(三)在slave2虚拟机上安装配置hadoop
1、将master虚拟机上的hadoop分发到slave2虚拟机
执行命令:scp -r H A D O O P H O M E r o o t @ s l a v e 2 : HADOOP_HOME root@slave2: HADOOPHOMEroot@slave2:HADOOP_HOME

在slave2节点上查看分发的hadoop

2、将master虚拟机上环境配置文件分发到slave2虚拟机
执行命令:scp /etc/profile root@slave2:/etc/profile
3、在slave2虚拟机上让环境配置生效
切换到slave2虚拟机,执行命令:source /etc/profile
(四)在master虚拟机上格式化名称节点
在master虚拟机上,执行命令:hdfs namenode -format

看到22/04/27 00:41:52 INFO common.Storage: Storage directory /usr/local/hadoop-2.7.7/tmp/namenode has been successfully formatted. ,表明名称节点格式化成功。
(五)启动Hadoop集群
1、在master虚拟机上启动hadoop集群
执行命令:start-dfs.sh,启动hdfs服务

一个名称节点(namenode)——老大,在master虚拟机上;两个数据节点(datanode)——小弟,在slave1与slave2虚拟机上。辅助名称节点(secondarynamenode)的地址是master,因为在hdfs-site.xml文件里配置了辅助名称节点。
此时查看三个虚拟机的进程
执行命令:start-yarn.sh,启动YARN服务
启动了YARN守护进程;一个资源管理器(resourcemanager)在master虚拟机上,两个节点管理器(nodemanager)在slave1与slave2虚拟机上
执行命令jps查看master虚拟机的进程,只有NameNode、SecondaryNameNode和ResourceManager
查看slave1和slave2上的进程,只有NodeManager和DataNode
2、查看hadoop集群HDFS的WebUI界面
在win7虚拟机上浏览器访问http://master:50070

不能通过主机名master加端口50070的方式,原因在于没有在hosts文件里IP与主机名的映射,现在可以访问http://192.168.1.101:50070

修改宿主机的C:\Windows\System32\drivers\etc\hosts文件

此时,访问http://master:50070
查看数据节点信息
点开【Utilities】下拉菜单,选择【Browse the file system】
在HDFS上创建一个目录BigData,执行命令:hdfs dfs -mkdir /BigData
在Hadoop WebUI界面查看刚才创建的目录
3、查看hadoop集群Yarn的WebUI界面
访问http://master:8088/cluster

单击[About]链接
(六)停止Hadoop集群
在master虚拟机上执行命令:stop-all.sh(相当于同时执行了stop-dfs.sh与stop-yarn.sh)

提示:This script is Deprecated. Instead use stop-dfs.sh and stop-yarn.sh,说明stop-all.sh脚本已经被废弃掉了,让我们最好分开使用stop-dfs.sh与stop-yarn.sh。
再次启动Hadoop服务后,采用分开方式停止Hadoop集群

五、配置Spark Standalone集群
(一)在master虚拟机上安装配置Spark
1、进入/opt目录,查看spark安装包

2、将spark安装包解压到指定目录
执行命令:tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local

3、配置spark环境变量
执行命令:vim /etc/profile
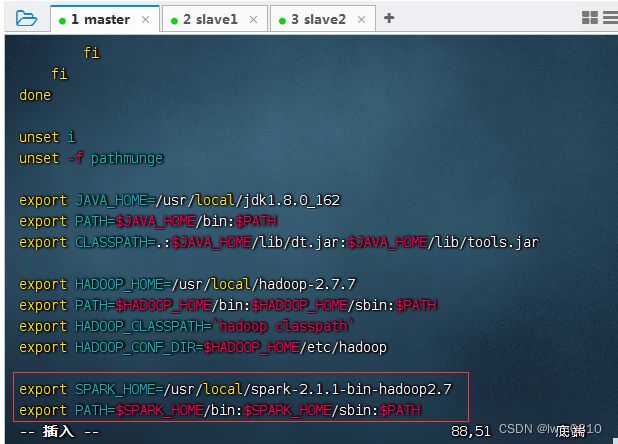
存盘退出后,执行命令:source /etc/profile,让配置生效
查看spark安装目录(bin、sbin和conf三个目录很重要)
4、编辑spark环境配置文件 - spark-env.sh
进入spark配置目录后,执行命令:cp spark-env.sh.template spark-env.sh与vim spark-env.sh

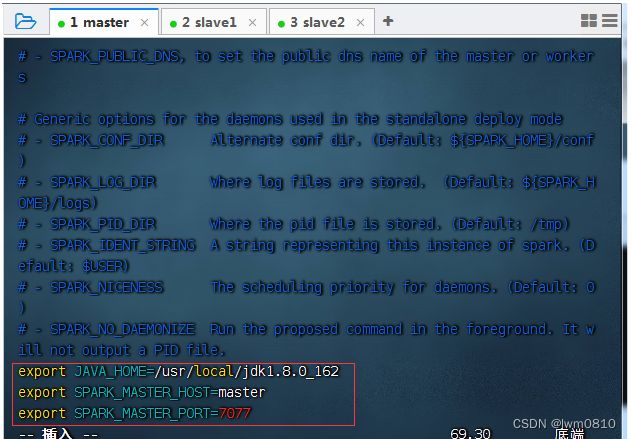
JAVA_HOME:指定JAVA_HOME的路径。若集群中每个节点在/etc/profile文件中都配置了JAVA_HOME,则该选项可以省略,Spark集群启动时会自动读取。为了防止出错,建议此处将该选项配置上。
SPARK_MASTER_HOST:指定集群主节点(master)的主机名,此处为master。
SPARK_MASTER_PORT:指定Master节点的访问端口,默认为7077。
存盘退出,执行命令:source spark-env.sh,让配置生效
5、创建slaves文件,添加从节点
执行命令:vim slaves,添加两个从节点主机名
(二)在slave1虚拟机上安装配置Spark
1、把master虚拟机上安装的spark分发给slave1虚拟机
执
行命令:scp -r S P A R K H O M E r o o t @ s l a v e 1 : SPARK_HOME root@slave1: SPARKHOMEroot@slave1:SPARK_HOME
2、将master虚拟机上环境变量配置文件分发到slave1虚拟机
在master虚拟机上,执行命令:scp /etc/profile root@slave1:/etc/profile

在slave1虚拟机上,执行命令:source /etc/profile,让环境配置生效

3、在slave1虚拟机上让spark环境配置文件生效
在slave1虚拟机上,进入spark配置目录,执行命令:source spark-env.sh
(三)在slave2虚拟机上安装配置Spark
1、把master虚拟机上安装的spark分发给slave2虚拟机
执行命令:scp -r S P A R K H O M E r o o t @ s l a v e 2 : SPARK_HOME root@slave2: SPARKHOMEroot@slave2:SPARK_HOME

2、将master虚拟机上环境变量配置文件分发到slave2虚拟机
在master虚拟机上,执行命令:scp /etc/profile root@slave2:/etc/profile

在slave2虚拟机上,执行命令:source /etc/profile,让环境配置生效

3、在slave2虚拟机上让spark环境配置文件生效
在slave2虚拟机上,进入spark配置目录,执行命令:source spark-env.sh

六、启动Spark Standalone集群
Spark Standalone集群使用Spark自带的资源调度框架,但一般我们把数据保存在HDFS上,用HDFS做数据持久化,所以Hadoop还是需要配置,但是可以只配置HDFS相关的,而Hadoop YARN不需要配置。启动Spark Standalone集群,不需要启动YARN服务,因为Spark会使用自带的资源调度框架。
(一)启动hadoop的dfs服务
在master虚拟机上执行命令:start-dfs.sh

(二)启动Spark集群
执行命令:start-all.sh
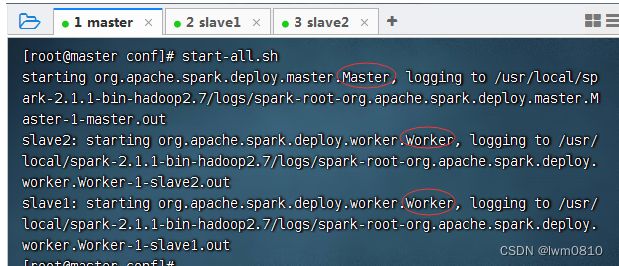
查看start-all.sh的源码启动Master与Worker的命令
可以看到,当执行start-all.sh命令时,会分别执行start-master.sh命令启动Master,执行start-slaves.sh命令启动Worker。
注意,若spark-evn.sh中配置了SPARK_MASTER_HOST属性,则必须在该属性指定的主机上启动Spark集群,否则会启动不成功;若没有配置SPARK_MASTER_HOST属性,则可以在任意节点上启动Spark集群,当前执行启动命令的节点即为Master节点。
启动完毕后,分别在各节点执行jps命令,查看启动的进程。若在master节点存在Master进程,slave1节点存在Worker进程,slave2节点存在Worker进程,则说明集群启动成功。
查看master节点进程
查看slave1节点进程
查看slave2节点进程
(三)访问Spark的WebUI
在宿主机上,访问http://master:8080
查看Wokers
七、使用Spark Standalone集群
(一)启动Scala版Spark Shell
执行命令:spark-shell --master spark://master:7077

在/opt目录里执行命令:vim test.txt

在HDFS上创建park目录,将test.txt上传到HDFS的/park目录

在其它虚拟机上也可以查看到该文件

读取HDFS上的文件,创建RDD,执行命令:val rdd = sc.textFile(“hdfs://master:9000/park/test.txt”)

收集rdd的数据,执行命令:rdd.collect
进行词频统计,按单词个数降序排列,执行命令:val wordcount = rdd.flatMap(.split(" ")).map((, 1)).reduceByKey(_ + ).sortBy(._2, false)与wordcount.collect.foreach(println)
(二)提交Spark应用程序
1、提交语法格式
Spark提供了一个客户端应用程序提交工具spark-submit,使用该工具可以将编写好的Spark应用程序提交到Spark集群。
spark-submit的使用格式如下:$ bin/spark-submit [options] [app options]
options表示传递给spark-submit的控制参数;
app jar表示提交的程序JAR包(或Python脚本文件)所在位置;
app options表示jar程序需要传递的参数,例如main()方法中需要传递的参数。
2、spark-submit常用参数
除了–master参数外,spark-submit还提供了一些控制资源使用和运行时环境的参数。
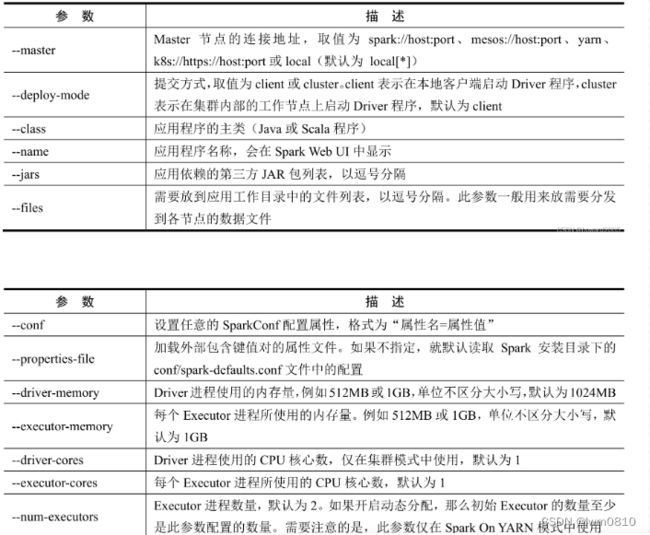
3、案例演示 - 提交Spark自带的圆周率计算程序
进入Spark安装目录
(1)Standalone模式,采用client提交方式
执行下述命令,将Spark自带的求圆周率的程序提交到集群

查看运行结果

上述命令中的–master参数指定了Master节点的连接地址。该参数根据不同的Spark集群模式,其取值也有所不同,常用取值如下表所示。

取值 描述
spark://host:port Standalone模式下的Master节点的连接地址,默认端口为7077
yarn 连接到YARN集群。若YARN中没有指定ResourceManager的启动地址,则需要在ResourceManager所在的节点上进行应用程序的提交,否则将因找不到ResourceManager而提交失败
local 运行本地模式,使用1个CPU核心
local [N] 运行本地模式,使用N个CPU核心。例如,local[2]表示使用两个CPU核心运行程序
local[] 运行本地模式,尽可能使用最多的CPU核心
若不添加–master参数,则默认使用本地模式local[]运行。
(2)Standalone模式,采用cluster提交方式
在Standalone模式下,将Spark自带的圆周率计算程序提交到集群,并且设置Driver进程使用内存为512MB,每个Executor进程使用内存为1GB,每个Executor进程所使用的CPU核心数为2,提交方式为cluster(Driver进程运行在集群的工作节点中),执行命令如下:

运行会有警告信息

在Spark WebUI界面上查看运行结果,访问http://master:8080
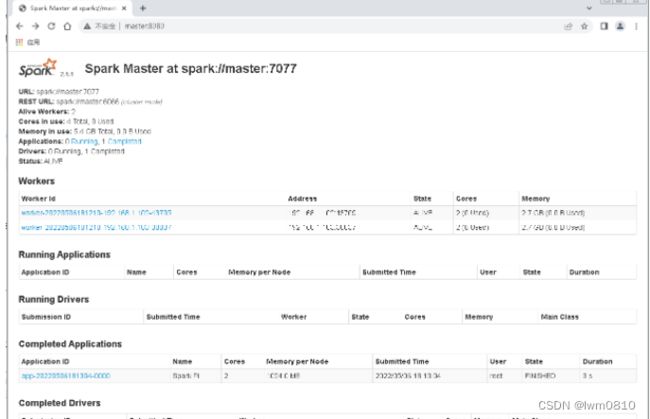
单击圈红的Worder超链接
单击stdout超链接
(三)停止Spark集群服务
在master节点执行命令:stop-all.sh
