Ascend C 第一份代码
Ascend C是昇腾AI异构计算架构CANN针对算子开发场景推出的编程语言,原生支持C和C++标准规范,最大化匹配用户开发习惯;通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大提高算子开发效率,助力AI开发者低成本完成算子开发和模型调优部署。
本文提供Ascend C保姆级教程,从一个简单的实例出发,带你体验Ascend C算子开发的基本流程。
完成实例开发之前,需要先了解一些必备的背景知识。
1. 背景知识
- 多核并行
使用Ascend C开发的算子运行在AI Core上,AI Core是昇腾NPU硬件平台的计算核心,NPU内部有多个AI Core。Ascend C编程过程中会将需要处理的数据拆分同时在多个AI Core上运行,从而获取更高的性能。多个AI Core共享相同的指令代码,每个核上的运行实例唯一的区别是block_idx不同,开发者只需要关注单核上的处理程序,也就是核函数。

- 流水并行
上文提到,开发者只需要关注单核处理程序(核函数),那么如何实现核函数的具体逻辑呢?Ascend C提供流水线式的编程范式,基于编程范式可以快速搭建算子实现的代码框架,实现流水并行。
流水线并行的概念和工业生产中的流水线是类似的,任务1完成对某片数据的处理后,将其加入到通信队列,任务2空闲时就会从队列中取出数据继续处理;可以类比为生产流水线中的工人只完成某一项固定工序,完成后就交由下一项工序负责人继续处理。
Ascend C编程范式是一种流水线式的编程范式,把算子核内的处理程序,分成多个流水任务:“搬入、计算、搬出”,通过队列(Queue)完成任务间通信和同步,并通过统一的内存管理模块(Pipe)管理任务间通信内存。开发者只需聚焦实现“搬入、计算、搬出”内容。

- 孪生调试
基于NPU域算子的调用接口编写程序,通过毕昇编译器编译后运行,可以完成算子NPU域的运行验证;基于CPU域算子的调用接口编写程序,通过标准的GCC编译器进行编译后运行,并通过GDB通用调试工具进行单步调试,精准验证程序执行流程是否符合预期。孪生调试的能力,大大提升了算子的调试效率。下文的示例开发,仅介绍核函数CPU侧和NPU侧的运行验证,具体的调试步骤将会在后续的文章中详细介绍。
2. 开发流程
本文将引导你完成以下任务,体验Ascend C算子开发的基本流程。
- 使用Ascend C完成Add算子核函数开发;
- 使用ICPU_RUN_KF CPU调测宏完成算子核函数CPU侧运行验证;
- 使用<<<>>>内核调用符完成算子核函数NPU侧运行验证。
在正式的开发之前,还需要先完成环境准备和算子分析工作,开发Ascend C算子的基本流程如下图所示:
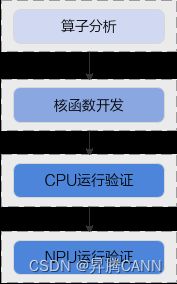
参考本文进行开发之前请先获取样例代码目录quick-start,该样例代码只保留了部分代码框架,核心代码在下文的指导步骤中体现。您可以在阅读本文时,将指导步骤中的代码拷贝至对应位置,即可快速完成Ascend C算子的开发。
3. 环境准备
- CANN软件安装
开发算子前,需要先准备好开发环境和运行环境,开发环境和运行环境的介绍和具体的安装步骤可参见昇腾社区文档的CANN软件安装指南。
- 环境变量配置
安装CANN软件后,使用CANN运行用户编译、运行时,需要以CANN运行用户登录环境,执行source ${install_path}/set_env.sh命令设置环境变量,其中${install_path}为CANN软件的安装目录。
4. 算子分析
主要分析算子的数学表达式、输入、输出以及计算逻辑的实现,明确需要调用的Ascend C接口。
- 明确算子的数学表达式及计算逻辑。
Add算子的数学表达式为:
z = x + y
计算逻辑是:要完成AI Core上的数据计算,输入数据需要先从外部存储Global Memory搬运进AI Core的内部存储Local Memory,然后使用计算接口完成两个输入参数相加,得到最终结果,再搬出到外部存储Global Memory上。

2. 明确输入和输出。
- Add算子有两个输入:x与y,输出为z。
- 本样例中算子的输入支持的数据类型为half(float16),算子输出的数据类型与输入数据类型相同。
- 算子输入支持shape(8,2048),输出shape与输入shape相同。
- 算子输入支持的format为:ND。
3. 确定核函数名称和参数。
- 您可以自定义核函数名称,本样例中核函数命名为add_custom。
- 根据对算子输入输出的分析,确定核函数有3个参数x,y,z;x,y为输入在Global Memory上的内存地址,z为输出在Global Memory上的内存地址。
- 确定算子实现所需接口。
- 实现涉及外部存储和内部存储间的数据搬运,查看Ascend C API参考中的数据搬移接口,需要使用DataCopy来实现数据搬移。
- 本样例只涉及矢量计算的加法操作,查看Ascend C API参考中的矢量计算接口,初步分析可使用双目指令Add接口实现x+y。
- 计算中使用到的Tensor数据结构(数据操作的基础数据结构),使用AllocTensor、FreeTensor进行申请和释放。
- 并行流水任务之间使用Queue队列完成通信和同步,会使用到EnQue、DeQue等接口。
通过以上分析,得到Ascend C Add算子的设计规格如下:
| 表1 Ascend C Add算子设计规格 |
||||
| 算子类型(OpType) |
AddCustom |
|||
| 算子输入 |
name |
shape |
data type |
format |
| x |
(8, 2048) |
half |
ND |
|
| y |
(8, 2048) |
half |
ND |
|
| 算子输出 |
z |
(8, 2048) |
half |
ND |
| 核函数名称 |
add_custom |
|||
| 使用的主要接口 |
DataCopy:数据搬移接口 |
|||
| Add:矢量双目指令接口 |
||||
| AllocTensor、FreeTensor:内存管理接口 |
||||
| EnQue、DeQue接口:Queue队列管理接口 |
||||
| 算子实现文件名称 |
add_custom.cpp |
|||
5 核函数开发
完成环境准备和初步的算子分析后,即可开始Ascend C核函数的开发。开发之前请先获取样例代码目录quick-start,以下核函数开发的样例代码在add_custom.cpp中实现。
本样例中使用多核并行计算,即把数据进行分片,分配到多个核上进行处理。Ascend C核函数是在一个核上的处理函数,所以只处理部分数据。分配方案是:数据整体长度TOTAL_LENGTH为8* 2048,平均分配到8个核上运行,每个核上处理的数据大小BLOCK_LENGTH为2048。下文的核函数,只关注长度为BLOCK_LENGTH的数据应该如何处理。
5.1 核函数的定义
进行核函数的定义,并在核函数中调用算子类的Init和Process函数。请将下文代码添加至add_custom.cpp的“核函数实现”注释处。
extern "C" __global__ __aicore__ void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}1. 使用__global__函数类型限定符来标识它是一个核函数,可以被<<<...>>>调用;使用__aicore__函数类型限定符来标识该核函数在设备端AI Core上执行。指针入参变量需要增加变量类型限定符__gm__,表明该指针变量指向Global Memory上某处内存地址为了统一表达,使用GM_ADDR宏来修饰入参,GM_ADDR宏定义如下:
#define GM_ADDR __gm__ uint8_t* __restrict__2. 算子类的Init函数,完成内存初始化相关工作,Process函数完成算子实现的核心逻辑。
5.2 算子类定义
本样例中定义KernelAdd算子类,其具体成员如下。请将下文代码添加至add_custom.cpp的“算子类实现”注释处。
class KernelAdd {
public:
__aicore__ inline KernelAdd(){}
// 初始化函数,完成内存初始化相关操作
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z){}
// 核心处理函数,实现算子逻辑,调用私有成员函数CopyIn、Compute、CopyOut完成矢量算子的三级流水操作
__aicore__ inline void Process(){}
private:
// 搬入函数,完成CopyIn阶段的处理,被核心Process函数调用
__aicore__ inline void CopyIn(int32_t progress){}
// 计算函数,完成Compute阶段的处理,被核心Process函数调用
__aicore__ inline void Compute(int32_t progress){}
// 搬出函数,完成CopyOut阶段的处理,被核心Process函数调用
__aicore__ inline void CopyOut(int32_t progress){}
private:
TPipe pipe; //Pipe内存管理对象
TQue inQueueX, inQueueY; //输入数据Queue队列管理对象,QuePosition为VECIN
TQue outQueueZ; //输出数据Queue队列管理对象,QuePosition为VECOUT
GlobalTensor xGm, yGm, zGm; //管理输入输出Global Memory内存地址的对象,其中xGm, yGm为输入,zGm为输出
}; 内部函数的调用关系示意图如下:
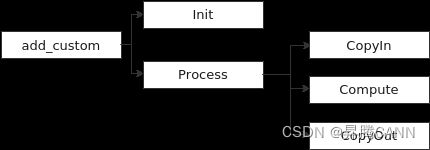
由此可见除了Init函数完成初始化外,Process中完成了对流水任务:“搬入、计算、搬出”的调用,开发者可以重点关注三个流水任务的实现。
5.3 Init 函数实现
初始化函数Init主要完成以下内容:设置输入输出Global Tensor的Global Memory内存地址,通过Pipe内存管理对象为输入输出Queue分配内存。
上文我们介绍到,本样例将数据切分成8块,平均分配到8个核上运行,每个核上处理的数据大小BLOCK_LENGTH为2048。那么我们是如何实现这种切分的呢?
每个核上处理的数据地址需要在起始地址上增加GetBlockIdx()*BLOCK_LENGTH(每个block处理的数据长度)的偏移来获取。这样也就实现了多核并行计算的数据切分。
以输入x为例,x + BLOCK_LENGTH * GetBlockIdx()即为单核处理程序中x在Global Memory上的内存偏移地址,获取偏移地址后,使用GlobalTensor类的SetGlobalBuffer接口设定该核上Global Memory的起始地址以及长度。具体示意图如下。

上面已经实现了多核数据的切分,那么单核上的处理数据如何进行切分?
对于单核上的处理数据,可以进行数据切块(Tiling),在本示例中,仅作为参考,将数据切分成8块(并不意味着8块就是性能最优)。切分后的每个数据块再次切分成2块,即可开启double buffer,实现流水线之间的并行。
这样单核上的数据(2048个数)被切分成16块,每块TILE_LENGTH(128)个数据。Pipe为inQueueX分配了两块大小为TILE_LENGTH * sizeof(half)个字节的内存块,每个内存块能容纳TILE_LENGTH(128)个half类型数据。数据切分示意图如下。

具体的初始化函数代码如下:
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
// 多核并行,设定当前核上Global Memory的起始地址以及长度 xGm.SetGlobalBuffer((__gm__ half*)x + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
yGm.SetGlobalBuffer((__gm__ half*)y + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
zGm.SetGlobalBuffer((__gm__ half*)z + BLOCK_LENGTH * GetBlockIdx(), BLOCK_LENGTH);
// 通过pipe为queue分配内存,单位为Bytes
pipe.InitBuffer(inQueueX, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, TILE_LENGTH * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, TILE_LENGTH * sizeof(half));
}5.4 核心处理函数实现
基于矢量编程范式,将核函数的实现分为3个基本任务:CopyIn,Compute,CopyOut。任务之间通过队列进行通信,交互示意图如下:
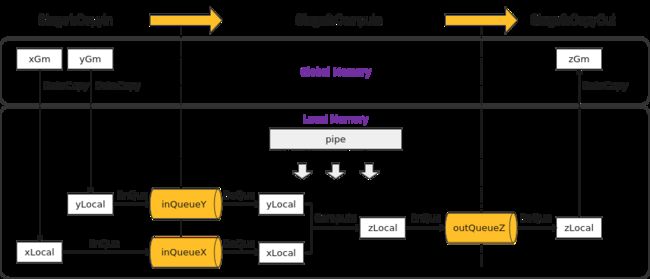
Process函数中通过如下方式调用这三个函数。
__aicore__ inline void Process()
{
// 开启double buffer后循环次数需要乘以2
constexpr int32_t loopCount = TILE_NUM * BUFFER_NUM;
// 多个任务实现流水并行
for (int32_t i = 0; i < loopCount; i++) {
CopyIn(i);
Compute(i);
CopyOut(i);
}
}- CopyIn函数实现。
__aicore__ inline void CopyIn(int32_t progress)
{
// 1、从队列中分配Tensor
LocalTensor xLocal = inQueueX.AllocTensor();
LocalTensor yLocal = inQueueY.AllocTensor();
// 2、使用DataCopy接口将GlobalTensor数据拷贝到LocalTensor
DataCopy(xLocal, xGm[progress * TILE_LENGTH], TILE_LENGTH);
DataCopy(yLocal, yGm[progress * TILE_LENGTH], TILE_LENGTH);
// 3、将LocalTensor放入搬入数据的存放位置VecIn的Queue中
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
} - Compute函数实现。
__aicore__ inline void Compute(int32_t progress)
{
// 1、使用DeQue从VecIn中取出LocalTensor
LocalTensor xLocal = inQueueX.DeQue();
LocalTensor yLocal = inQueueY.DeQue();
LocalTensor zLocal = outQueueZ.AllocTensor();
// 2、调用Add指令完成双目矢量计算
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
// 3、使用EnQue将计算结果LocalTensor放入到搬出数据的存放位置VECOUT的Queue中
outQueueZ.EnQue(zLocal);
// 4、使用FreeTensor将释放不再使用的LocalTensor
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
} - CopyOut函数实现。
__aicore__ inline void CopyOut(int32_t progress)
{
// 1、使用DeQue接口从VecOut的Queue中取出LocalTensor
LocalTensor zLocal = outQueueZ.DeQue();
// 2、使用DataCopy接口将LocalTensor拷贝到GlobalTensor上
DataCopy(zGm[progress * TILE_LENGTH], zLocal, TILE_LENGTH);
// 3、使用FreeTensor将不再使用的LocalTensor进行回收
outQueueZ.FreeTensor(zLocal);
} 6 核函数运行验证
异构计算架构中,NPU(kernel侧)与CPU(host侧)是协同工作的,完成了kernel侧核函数开发后,即可编写host侧的核函数调用程序,实现从host侧的APP程序调用算子,执行计算过程。
除了上文核函数实现文件add_custom.cpp外,核函数的调用与验证还需要需要准备以下文件:
- 调用算子的应用程序:main.cpp。
- 输入数据和真值数据生成脚本文件:add_custom.py。
- 编译cpu侧或npu侧运行的算子的编译工程文件:CMakeLists.txt。
- 编译运行算子的脚本:run.sh。
本文仅介绍调用算子的应用程序的编写,该应用程序在main.cpp中体现,其他内容您可以在quick-start中直接获取。
6.1 host侧应用程序框架编写
内置宏__CCE_KT_TEST__ 是区分运行CPU模式或NPU模式逻辑的标志,在同一个main函数中通过对__CCE_KT_TEST__宏定义的判断来区分CPU和NPU侧的运行程序。
int32_t main(int32_t argc, char* argv[])
{
size_t inputByteSize = 8 * 2048 * sizeof(uint16_t); // uint16_t represent half
size_t outputByteSize = 8 * 2048 * sizeof(uint16_t); // uint16_t represent half
uint32_t blockDim = 8;
#ifdef __CCE_KT_TEST__
// 用于CPU调试的调用程序
#else
// NPU侧运行算子的调用程序
#endif
return 0;
}6.2 CPU运行验证
完成算子核函数CPU侧运行验证的步骤如下:
- 分配共享内存,并进行数据初始化;
- 调用ICPU_RUN_KF调测宏,完成核函数CPU侧的调用;
- 释放申请的资源。
请将下文代码添加至上面代码框架的“用于CPU调试的调用程序”注释处。
uint8_t* x = (uint8_t*)AscendC::GmAlloc(inputByteSize);
uint8_t* y = (uint8_t*)AscendC::GmAlloc(inputByteSize);
uint8_t* z = (uint8_t*)AscendC::GmAlloc(outputByteSize);
ReadFile("./input/input_x.bin", inputByteSize, x, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, y, inputByteSize);
AscendC::SetKernelMode(KernelMode::AIV_MODE);
ICPU_RUN_KF(add_custom, blockDim, x, y, z); // use this macro for cpu debug
WriteFile("./output/output_z.bin", z, outputByteSize);
AscendC::GmFree((void *)x);
AscendC::GmFree((void *)y);
AscendC::GmFree((void *)z);6.3 NPU侧运行验证
完成算子核函数NPU侧运行验证的步骤如下:
- 初始化Device设备;
- 创建Context绑定设备;
- 分配Host内存,并进行数据初始化;
- 分配Device内存,并将数据从Host上拷贝到Device上;
- 用内核调用符<<<>>>调用核函数完成指定的运算;
- 将Device上的运算结果拷贝回Host;
- 释放申请的资源。
请将下文代码添加至上面代码框架的“NPU侧运行算子的调用程序”注释处。
// AscendCL初始化
CHECK_ACL(aclInit(nullptr));
// 创建Context绑定设备
aclrtContext context;
int32_t deviceId = 0;
CHECK_ACL(aclrtSetDevice(deviceId));
CHECK_ACL(aclrtCreateContext(&context, deviceId));
aclrtStream stream = nullptr;
CHECK_ACL(aclrtCreateStream(&stream));
// 分配Host内存,并进行数据初始化
uint8_t *xHost, *yHost, *zHost;
uint8_t *xDevice, *yDevice, *zDevice;
CHECK_ACL(aclrtMallocHost((void**)(&xHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&yHost), inputByteSize));
CHECK_ACL(aclrtMallocHost((void**)(&zHost), outputByteSize));
// 分配Device内存,并将数据从Host上拷贝到Device上
CHECK_ACL(aclrtMalloc((void**)&xDevice, inputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&yDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
CHECK_ACL(aclrtMalloc((void**)&zDevice, outputByteSize, ACL_MEM_MALLOC_HUGE_FIRST));
ReadFile("./input/input_x.bin", inputByteSize, xHost, inputByteSize);
ReadFile("./input/input_y.bin", inputByteSize, yHost, inputByteSize);
CHECK_ACL(aclrtMemcpy(xDevice, inputByteSize, xHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
CHECK_ACL(aclrtMemcpy(yDevice, inputByteSize, yHost, inputByteSize, ACL_MEMCPY_HOST_TO_DEVICE));
// 用内核调用符<<<>>>调用核函数完成指定的运算
add_custom_do(blockDim, nullptr, stream, xDevice, yDevice, zDevice);
CHECK_ACL(aclrtSynchronizeStream(stream));
// 将Device上的运算结果拷贝回Host
CHECK_ACL(aclrtMemcpy(zHost, outputByteSize, zDevice, outputByteSize, ACL_MEMCPY_DEVICE_TO_HOST));
WriteFile("./output/output_z.bin", zHost, outputByteSize);
// 释放申请的资源
CHECK_ACL(aclrtFree(xDevice));
CHECK_ACL(aclrtFree(yDevice));
CHECK_ACL(aclrtFree(zDevice));
CHECK_ACL(aclrtFreeHost(xHost));
CHECK_ACL(aclrtFreeHost(yHost));
CHECK_ACL(aclrtFreeHost(zHost));
CHECK_ACL(aclrtDestroyStream(stream));
CHECK_ACL(aclrtDestroyContext(context));
CHECK_ACL(aclrtResetDevice(deviceId));
CHECK_ACL(aclFinalize());6.4 执行一键式编译运行脚本,编译和运行应用程序
脚本执行方式如下:
bash run.sh
-
表示需要运行的算子。 表示算子运行的AI处理器型号。 表示在AiCore上或者VectorCore上运行。 表示算子以cpu模式或npu模式运行。
CPU模式下执行如下命令(算子运行的AI处理器型号以Ascend 910为例):
bash run.sh add_custom ascend910 AiCore cpu
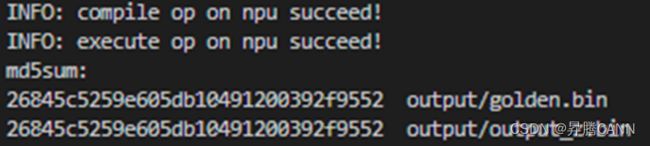
运行结果如下,当前使用md5sum对比了所有输出bin文件,md5值一致表示实际的输出数据和真值数据相符合。

NPU模式下执行如下命令:bash run.sh add_custom ascend910 AiCore npu
运行结果如下,当前使用md5sum对比了所有输出bin文件,md5值一致表示实际的输出数据和真值数据相符合。
至此,你已经完成了Ascend C算子开发的快速入门,更多内容请参考:
《Ascend C 官方教程》