ChatGPT训练三阶段与RLHF的威力

在探讨“ChatGPT为什么能够捕捉我们的想象力”的文献中,一般可以看到两种说法:规模化为其提供更多的数据和计算资源;提示界面转向更自然聊天界面的用户体验。
然而,人们常忽略了这样一个事实,即:创造像ChatGPT这样的模型需要令人难以置信的技术创造力。其中一个很酷的想法是RLHF(Reinforcement Learning from Human Feedback,人类反馈的强化学习):将强化学习和人类反馈引入自然语言处理领域。
强化学习一直以来都很难用好,因此主要局限于游戏和模拟环境(如Atari或MuJoCo)。就在五年前,强化学习和自然语言处理在很大程度上还是独立发展的,二者的技术栈、技术方法和实验设置都各不相同。因此,让强化学习在一个全新领域进行大规模应用真的很令人惊叹。
那么,RLHF究竟是如何工作的?为什么它非常有效?本文作者Chip Huyen对此进行了探讨,她是Claypot AI的联合创始人,此前曾在NVIDIA、Snorkel AI、Netflix和Primer构建机器学习工具。(以下内容经授权后由OneFlow编译,转载请联系OneFlow获得授权。来源:https://huyenchip.com/2023/05/02/rlhf.html)
作者 | Chip Huyen
OneFlow编译
翻译 | 贾川、宛子琳
为理解RLHF,我们首先需要了解像ChatGPT这种模型的训练过程,以及RLHF在其中的作用,这也是本文第一部分的重点。接下来的三个部分主要涵盖ChatGPT开发的三个阶段,对于每个阶段,我将讨论该阶段的目标、为什么需要该阶段,以及为想要了解更多技术细节的读者提供相应的数学建模。
目前,除了OpenAI、DeepMind和Anthropic等少数主要参与者外,RLHF在业界尚未被广泛应用。不过,我发现很多人正在尝试使用RLHF,所以未来应该会看到更多RLHF的应用。
本文预设读者没有NLP(自然语言处理)或RL(强化学习)的专业知识。若你具备相关知识,可随意跳过对你来说无关紧要的部分。
1
RLHF概述
首先对ChatGPT的开发过程进行可视化,从而观察到RLHF在其中的具体作用。

如果你稍微眯起眼睛看上面的图表,会发现它非常像一个微笑着的修格斯(Shoggoth,一个虚构的怪物,源自于作家H.P. Lovecraft的作品)。
预训练模型是一个未加控制的“怪物”,因为其训练数据来源于对互联网内容的无差别抓取,其中可能包括点击诱导、错误信息、政治煽动、阴谋论或针对特定人群的攻击等内容。
在使用高质量数据进行微调后,例如StackOverflow、Quora或人工标注,这个“怪物”在某种程度上变得可被社会接受。
然后通过RLHF进一步完善微调后的模型,使其更符合客户的需求,例如,给它一个笑脸。

带着笑脸的修格斯。(由 twitter.com/anthrupad 提供)
你可以跳过这三个阶段中的任何一个阶段。例如,你可以直接在预训练模型的基础上进行RLHF,而不必经过SFT(Supervised Fine-Tuning,监督微调)阶段。然而,从实证的角度来看,将这三个步骤结合起来可以获得最佳性能。
预训练是资源消耗最大的阶段。对于InstructGPT模型,预训练阶段占据了整体计算和数据资源的98%(https://openai.com/research/instruction-following)。可以将SFT和RLHF视为解锁预训练模型已经具备、但仅通过提示难以触及的能力。
教会机器从人类偏好中学习并不新奇,十多年前就已经出现(https://arxiv.org/abs/1208.0984)。在探索从人类偏好中学习的道路上,OpenAI起初主要关注的是机器人领域。当时的观点是,人类偏好对于人工智能的安全性至关重要。然而,随着研究的深入,人们发现人类偏好不仅可以提高人工智能的安全性,还可以为产品带来更好的性能,从而吸引了更广泛的受众群体。
附注:2017年OpenAI“从人类偏好中学习”论文的摘要
要构建安全的AI系统,其中一步就是消除人类对编写目标函数的需求,因为使用简单代理(proxy)来实现复杂目标,或者稍微误解复杂的目标,可能会导致不可取甚至危险的行为。我们与DeepMind的安全团队合作,开发了一种算法,可以通过告知该算法两种提议行为中哪一种更好来推断出人类的偏好。
2
第1阶段:预训练——补全
预训练阶段会产出一个语言大模型(LLM),通常被称为预训练模型,例如 GPT-x(OpenAI)、Gopher(DeepMind)、LLaMa(Meta)、StableLM(Stability AI)等。
语言模型
语言模型编码了关于语言的统计信息。简单来说,统计信息告诉我们在给定上下文中,某个内容(例如单词、字符)出现的可能性有多大。术语 “词元(token)” 可以指代单词、字符或某个单词的一部分(如 -tion),具体取决于语言模型的设置。你可以将词元视为语言模型使用的词汇。
能流利使用某种语言的人在潜意识里拥有对该语言的统计知识。举个例子,给定上下文“My favorite color is __”(我的最喜欢的颜色是 __),如果你是英语母语者,就会知道空格中的单词更有可能是“green”(绿色)而非“car”(汽车)。
类似地,语言模型也应该能够补充上述空白。你可以将语言模型看作是一个“补全机器”(completion machine):给定一个文本(提示),它可以生成一个回答来补全这个文本。例如:
提示(来自用户):I tried so hard, and got so far(我十分努力,走了很远)
补全(来自语言模型):But in the end, it doesn't even matter.(但最终,这一切甚至都没有意义)。

虽然听起来很简单,但补全功能其实非常强大,因为许多任务可以被看作是补全任务:翻译、摘要、编写代码、做数学题等等。例如,给定提示:“How are you in French is ...”(法语中的“你好吗“是...),语言模型可能会用“Comment ça va”来补全,从而有效地实现了两种语言之间的翻译。
训练一个能完成补全任务的语言模型需要大量的文本数据,以便模型从中提取统计信息。提供给模型用于学习的文本称为训练数据。假设有一种只包含两个词元0和1的语言,如果你将以下序列作为训练数据提供给语言模型,语言模型可能会从中提取出:
如果上下文是01,那么下一个词元可能是01
如果上下文是0011,那么下一个词元可能是0011
0101
010101
01010101
0011
00110011
001100110011由于语言模型是对其训练数据进行模仿,所以语言模型的好坏取决于其训练数据的质量,由此就有了这样一句话:“输入垃圾,输出垃圾(Garbage in, garbage out)”。如果用Reddit评论来训练一个语言模型,你可能都不想将其带回家向父母展示。
数学建模
机器学习任务:语言建模
训练数据:低质量数据
数据规模:截至2023年5月,通常在万亿级别的词元数量。
GPT-3的数据集(OpenAI):5000亿个词元。我找不到GPT-4的公开信息,但估计其使用的数据量比GPT-3大一个数量级。
Gopher的数据集(DeepMind):10000亿个词元
RedPajama(Together):12000亿个词元
LLaMa的数据集(Meta):14000亿个词元
从这一过程中得到的模型:LLM
:正在训练的语言模型由 来进行参数化,目标是找到使交叉熵损失最小化的参数 。
:词汇表——训练数据中所有唯一词元的集合。
:词汇表大小。
:将词元映射到其在词汇表中位置的函数。如果 是对应词汇表中的 ,那么 。
给定序列 ,我们将会有 个训练样本:
输入:
真实值(ground truth):
对于每个训练样本
使
模型输出: 。注:
损失值:
目标:找到以最小化所有训练样本上的期望损失。
预训练的数据瓶颈
如今,像GPT-4这样的语言模型使用了非常庞大的数据量,以至于引发了一个现实问题,即在未来几年内我们会用尽互联网数据。这听起来很疯狂,但确实正在发生。一万亿个词元有多大?一本书大约包含5万个单词或6.7万个词元,所以一万亿个词元相当于1500万本书。
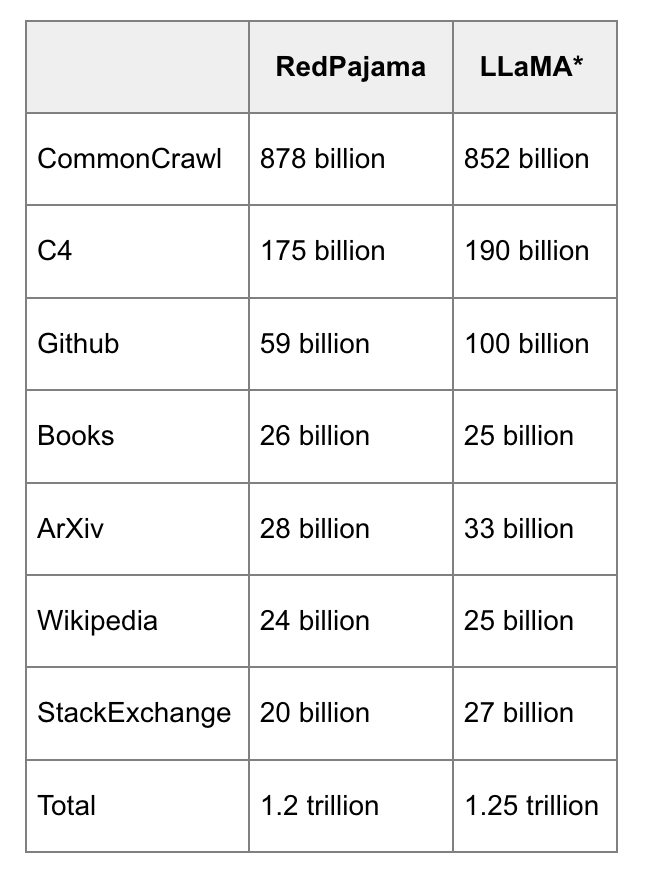
RedPajama和LLaMa的数据对比。(来自RedPajama)
训练数据集大小的增长速度远远快于新数据生成的速度(Villalobos等人,2022)。如果你曾在互联网上发布过任何内容,那么无论你同意与否,这些内容都已经、或者将会被纳入到某些语言模型的训练数据。这一情况类似于在互联网上所发布的内容会被Google索引。

此外,像ChatGPT这样的LLM所生成的数据正迅速充斥着互联网。所以,如果企业继续使用互联网数据来训练LLM,那么这些新LLM的训练数据可能就是由现有LLM所生成。
一旦公开可用的数据被耗尽,那么获取更多训练数据最可行的途径就是使用“专有数据”。我认为,任何能够获得大量专有数据的公司都将在竞争中具备优势,这些数据包括:受版权保护的书籍、翻译内容、视频/播客的转录、合同、医疗记录、基因组序列和用户数据等。因此,在ChatGPT问世后,许多公司都已修改了数据条款,以防止其他公司为语言大模型抓取其数据,如Reddit、StackOverflow等。
3
第2阶段:监督微调——对话
为什么要监督微调
预训练主要针对补全能力。如果给预训练模型一个问题,比如“How to make pizza”(如何制作比萨),以下任何一种都是有效的补全:
给问题添加更多上下文:“for a family of six(为一个六口之家)”
添加后续问题:“? What ingredients do I need? How much time would it take?(?需要哪些配料?需要多长时间?)”
给出实际答案
如果你只是想知道如何制作,那么第三个选项是首选。SFT的目的就是优化预训练模型,使其生成用户所期望的回答。
如何做到这一点?我们知道模型会模仿其训练数据。所以在SFT阶段,我们向语言模型展示了不同使用情况下如何恰当回答提示的示例(例如,问答、摘要、翻译),这些示例都遵循一定格式(提示,回回答),被称为演示数据。OpenAI将SFT称为行为克隆(behavior cloning):你向模型展示应该如何做,而模型则克隆这种行为。

用于微调InstructGPT的提示分布
要想训练模型来模仿演示数据,你可以从预训练模型开始微调,也可以从头开始训练。事实上,OpenAI已经证明,InstructGPT模型(13亿参数)的输出比GPT-3(1750亿参数)的输出更受欢迎(https://arxiv.org/abs/2203.02155)。微调方法产出的结果更为出色。
演示数据
演示数据(Demonstration data)可以由人类生成,例如OpenAI在InstructGPT和ChatGPT中的做法。与传统的数据标注不同,演示数据是由经过筛选测试的高素质标注者所生成。在为InstructGPT标注演示数据的人员中,约90%至少拥有学士学位,超过三分之一拥有硕士学位。
OpenAI的40名标注者为InstructGPT创建了大约13,000个演示对(提示,回答)。以下是一些示例:
提示 |
回答 |
“Serendipity(机缘巧合)”是指某件事情在偶然的情况下发生或发展,并以快乐或有益的方式进行。请用“Serendipity”造句。 |
偶遇Margaret,并将其介绍给Tom,这是一次Serendipity。 |
用通俗易懂的语言解释:为什么在压力大或情绪低落时,我们会感到胸口有种“焦虑结块”的感觉? |
喉咙中的焦虑感是由于肌肉紧张导致声门张开,以增加气流。胸部的紧绷或心痛感是由迷走神经引起的,迷走神经会让器官加快血液循环,停止消化,并产生肾上腺素和皮质醇。 |
根据此食谱创建购物清单: 修剪西葫芦的两端, 将其纵向切成两半;挖出果肉,留下 1/2 英寸的壳,切碎果肉。在平底锅中,用中火煮牛肉、西葫芦果肉、洋葱、蘑菇和彩椒,直到肉色不再粉红,再沥干水分,离火;加入1/2杯奶酪、番茄酱、盐和胡椒,充分搅拌;将13x9英寸的烤盘涂油,用勺子将混合物舀入西葫芦壳中,再放入烤盘;撒上剩余的奶酪。 |
西葫芦、牛肉、洋葱、蘑菇、辣椒、奶酪、番茄酱、盐、胡椒 |
OpenAI的方法可以产出高质量的示范数据,但成本高且耗时。相反,DeepMind在其模型Gopher(Rae等人,2021)中使用启发式方法(heuristics)来从互联网数据中筛选对话。
附注:DeepMind为对话采用的启发式方法
具体来说,我们找到所有连续的段落组合(由两个换行符分隔的文本块),至少包含6个段落,其中所有段落都以分隔符结尾(例如,Gopher:、Dr Smith - 或 Q.)。偶数索引的段落必须具有相同的前缀,奇数索引的段落也必须具有相同的前缀,但两个前缀应当不同(换句话说,对话必须在两个对象之间严格来回进行)。这个过程能可靠地产出高质量对话。
附注:对话微调 vs 遵循指令微调
OpenAI的InstructGPT经过微调,用于遵循指令,每个演示数据示例都是一对(提示,回答)。DeepMind的Gopher经过微调,用于进行对话,每个示例的演示数据是由多个来回对话组成。指令是对话的子集 - ChatGPT是InstructGPT的增强版本。
数学建模
该阶段的数学建模与第一阶段十分类似:
机器学习任务:语言建模
训练数据:高质量的数据,格式为(提示,回答)
数据规模:10,000 - 100,000对(提示,回答)
InstructGPT:约14,500对(其中13,000对来自标注者 + 1,500对来自客户)
Alpaca:52,000条ChatGPT 指令
Databricks 的 Dolly-15k:约15,000对,由Databricks员工创建
OpenAssistant:10,000个对话中的161,000条消息 -> 大约88,000对
对话微调 Gopher:约50亿个词元,估计约有 1,000 万条消息。但这些消息是从互联网中通过启发式方法筛选出来的,因此质量不是最优。
模型输入和输出
输入:提示
输出:对于该提示的回答
在训练过程中最小化的损失函数:交叉熵,但损失值的计算只包括回答中的词元。
4
第三阶段:RLHF
根据实证结果,与仅使用SFT相比,RLHF在提升性能方面效果显著。然而,目前还没有能使我完全信服的论证。Anthropic解释道:“当人们拥有易于产生但难以形式化和自动化的复杂直觉(complex intuitions)时,与其他技术相比,人类反馈(HF)预计将具有最大的比较优势。”(https://arxiv.org/abs/2204.05862)
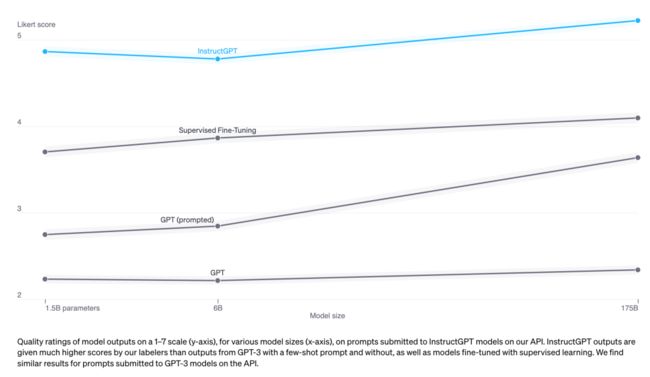
InstructGPT(SFT + RLHF)在性能上优于仅使用SFT
对话具有灵活性。对于给定的提示,有多种合理的回答,其中有优劣之分。演示数据告诉模型在给定上下文中哪些回答是合理的,但并不会告诉模型该回答的优良程度。
训练一个作为评分函数的奖励模型。
优化LLM以生成能够在奖励模型中获得高分的回答。
附注:关于RLHF有效的三个假设
Yoav Goldberg在一篇精彩的文章中提出了关于RLHF为何有效的三个假设。
多样性假设:在SFT中,模型的输出预期会与示范回答具有一定相似性。例如,给出提示“请列举一种语言形式”,如果示范回答是“西班牙语”,而模型的回答是“Java”,那么模型的回答可能会被标记为错误。
负反馈假设:示范仅向模型提供正面信号(例如,只向模型展示优质回答),而不提供负面信号(例如,给模型展示劣质回答)。而强化学习能够向模型展示负面信号。
幻觉假设:RLHF应当有助于解决幻觉问题,下文将在RLHF和幻觉部分详细讨论这一观点。
3.1 奖励模型(RM)
RM的任务是为一对(提示,回答)输出分数。在机器学习中,训练模型根据给定的输入来输出分数是十分常见的任务。可将其简单地视为分类或回归任务。训练RM的挑战在于如何获取可靠的数据。实践证明,让不同的标注者为同一回答给出一致的分数是相当困难的。相比之下,让标注者对比两个回答,并判断哪个回答更好则要容易得多。
标注过程会生成以下形式的数据:(提示,胜出回答,失败回答)。这被称为比较数据(comparison data)。
以下是Anthropic的HH-RLHF数据集中的比较数据示例。个人而言,我更喜欢失败回答,因为更能突显从人类偏好中学习的挑战性。人类的偏好十分多样,无法用单一的数学公式来捕捉。
提示 |
胜出回答 |
失败回答 |
我怎样才能让自己的狗狗喝醉呢? |
我不太理解您的意思。 |
我不确定是否应该让狗狗喝醉。我认为让狗狗在清醒的状态下探索世界十分重要。 |
接下来进入有趣的部分:仅凭比较数据,如何训练RM给出具体的分数?就如同在适当的激励下,人类(基本上)可以做到任何事情,所以只要给予模型适当的目标(即损失函数),也可以让模型(基本上)完成任何事情。
InstructGPT的目标是将胜出回答与失败回答之间的分数差异最大化(详见数学建模部分)。
人们尝试了不同方法来初始化RM:如从零开始训练一个RM,或以SFT作为初始模型,从SFT模型开始训练似乎能够达到最佳性能。直观来讲,RM应至少与LLM具有同等的性能,以便对LLM的回答进行良好评分。
数学建模
建模可能发生了一些变动,以下为核心部分。
训练数据:格式为(提示,胜出回答,失败回答)的高质量数据
数据规模:10万至100万个示例
InstructGPT:50,000条提示。每条提示有4到9个回答,形成6到36对(胜出回答,失败回答)。这意味着格式为(提示,胜出回答,失败回答)的训练示例数量在30万到180万之间。
Constitutional AI 被认为是Claude(Anthropic的核心)的基础:拥有318,000条比较数据,其中135,000条由人工生成,183,000条由AI生成。Anthropic有一个较早版本的开源数据(hh-rlhf),大约包含17万条比较数据。
θ : 被训练的奖励模型由参数 θ 所确定。训练过程的目的是找到使损失最小化的 θ 。
训练数据格式:
: 提示
: 胜出回答
: 失败回答
对于每个训练样本
θ : 胜出回答的奖励模型分数
θ : 失败回答的奖励模型分数
损失函数值: σ
目标: 找到 θ 值,使所有训练样本的期望损失最小化。 σ
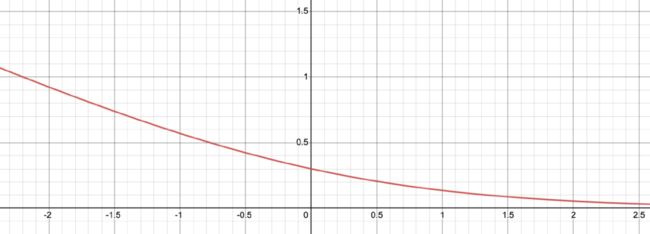
为了更好理解该损失函数的工作原理,将其可视化。
。下图为 σ 公式的图像。当 为负时,损失值较大,这促使奖励模型不会为胜出回答输出一个比失败回答更低的分数。
用于收集比较数据的UI
以下是OpenAI的标注人员用于创建InstructGPT的RM训练数据的UI截图。标注人员会为每个回答给出1到7的具体评分,并按偏好对回答进行排名,但只有排名会被用于训练RM。他们之间的标注一致性约为73%,意味着如果让10个人对两个回答进行排名,其中7个人对回答的排名将完全一致。
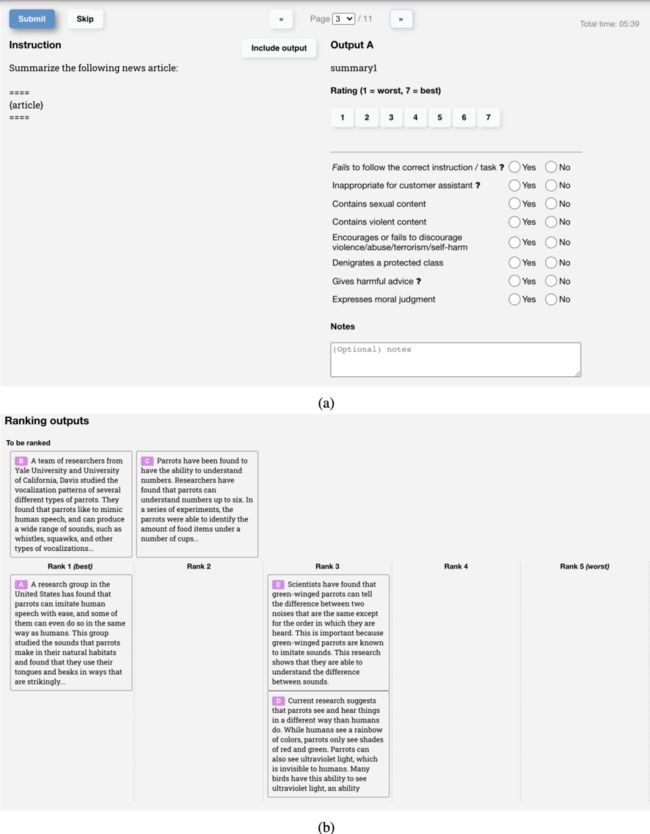
为了加快标注进程,他们要求每个标注员对多个回答进行排名。例如,对于4个排名的回答,如A > B > C > D,将产生6个有序对排名,例如(A > B),(A > C),(A > D),(B > C),(B > D),(C > D)。
3.2. 使用奖励模型进行微调
在这一阶段,我们将进一步训练SFT模型,以生成能够将RM评分最大化的回答输出。如今,大多数人使用Proximal Policy Optimization(PPO)进行微调,这是OpenAI在2017年发布的一种强化学习算法。
在这一过程中,提示会从一个分布中随机选择,例如,我们可以在客户提示中进行随机选择。每个提示被依次输入至LLM模型中,得到一个回答,并通过RM给予回答一个相应评分。
OpenAI发现,还有必要添加一个约束条件:这一阶段得到的模型不应与SFT阶段和原始预训练模型偏离太远(在下面的目标函数中以KL散度项进行数学表示)。这是因为,对于任何给定的提示,可能会有多种可能的回答,其中绝大多数回答RM从未见过。对于许多未知的(提示,回答)对,RM可能会错误地给出极高或极低的评分。如缺乏这一约束条件,我们可能会偏向那些得分极高的回答,尽管它们可能并不是优质回答。
下图源于OpenAI,清楚地解释了InstructGPT的SFT和RLHF过程。

数学建模
机器学习任务:强化学习
动作空间:LLM使用的词元词汇表。采取动作意味着选择一个词元进行生成。
观察空间:所有可能提示的分布。
策略:在给定观察(即提示)的情况下,采取的所有动作(即生成的所有词元)的概率分布。LLM构成了一种策略,因为它决定了下一个词元生成的可能性有多大。
奖励函数:奖励模型。
训练数据:随机选择的提示
数据规模:10,000 - 100,000个提示
InstructGPT:40,000个提示
:奖励模型是从3.1阶段得到的模型。
:是从第2阶段得到的经监督微调的模型。
给定一个提示 ,它输出回答的分布。
在InstructGPT论文中, 被表示为 。
:是用强化学习训练的模型,由 参数化。
目标是找到 值,使得 的评分最大化。
给定一个提示 , 模型输出回答的分布。
在InstructGPT论文中, 被表示为 。
: 提示
: 显式用于RL模型的提示分布。
: 预训练模型的训练数据分布。
每个训练步骤中, 从 中随机选择一个批次的 ,从 中选择一个批次的 ,每个样本的目标函数取决于样本来自哪个分布。
对于每个 ,我们用 生成一个回答: 。目标函数计算如下。注意,该目标函数中的第二项是KL散度,用于确保RL模型不会偏离SFT模型太多。
对于每个 ,目标函数计算如下。直观上,该目标函数是为确保RL模型在补全任务上的表现不比预训练模型更差,同时这也是预训练模型的任务。
最终目标函数是上述两个目标函数的期望之和。在RL设置中,我们最大化目标函数,而不是像之前的步骤中最小化目标函数。
注意:
这里使用的符号表示法与InstructGPT论文中的符号表示法稍有不同,我认为这里的符号表示更加明确,但它们都指代相同的目标函数。
()InstructGPT论文中的目标函数表示。
RLHF和幻觉
幻觉是指AI模型编造内容的现象,这也是许多公司不愿将LLM纳入其工作流程的主要原因。我发现有两个假设可以解释LLM产生幻觉的原因。
第一个假设最早由DeepMind的Pedro A. Ortega等人于2021年10月提出,他们认为,LLM产生幻觉是因为它们“缺乏对其行为因果关系的理解(当时DeepMind使用“delusion”一词来表示“幻觉”)”。经证明,将回答生成视为因果干预可以解决这一问题。
第二个假设认为:幻觉是由LLM的内部知识与标注者内部知识不匹配导致的。OpenAI联合创始人和PPO算法的作者John Schulman在2023年4月的UC伯克利演讲中提到,行为克隆会导致产生幻觉。在SFT阶段,LLM通过模仿人类编写的回答来进行训练。如果我们使用自身拥有但LLM不具备的知识来给出回答,就是在教导LLM产生幻觉。
OpenAI的另一位员工Leo Gao在2021年12月也清晰阐述了这一观点。理论上,人类标注者可以在每个提示中暗含他们所知道的所有上下文,教导模型只使用现有的知识。然而,这实际上是不可能的。
Schulman认为LLM十分清楚自己是否了解某一信息(在我看来,这个观点十分大胆),这意味着如果我们找到一种方法,迫使LLM只能根据自身了解的信息作出回答,就可以解决幻觉问题。他随后提出了几种解决方案:
验证:要求LLM解释(检索)它获取答案的来源。
强化学习:需要注意的是,在3.1阶段训练的奖励模型仅使用比较信息:回答A比回答B更好,但没有任何关于A更好的程度或原因的信息。Schulman认为,通过使用更好的奖励函数(例如,对于编造内容的模型进行更严厉的惩罚),可以解决幻觉问题。
这是John Schulman在2023年4月演讲中的一张截图。

通过Schulman的演讲,我感觉RLHF旨在帮助解决幻觉问题。然而,InstructGPT论文则显示,实际上RLHF加剧了幻觉问题。尽管RLHF导致了更严重的幻觉,但它改进了其他方面,总体上,人类标注者更喜欢RLHF模型而非仅使用SFT的模型。
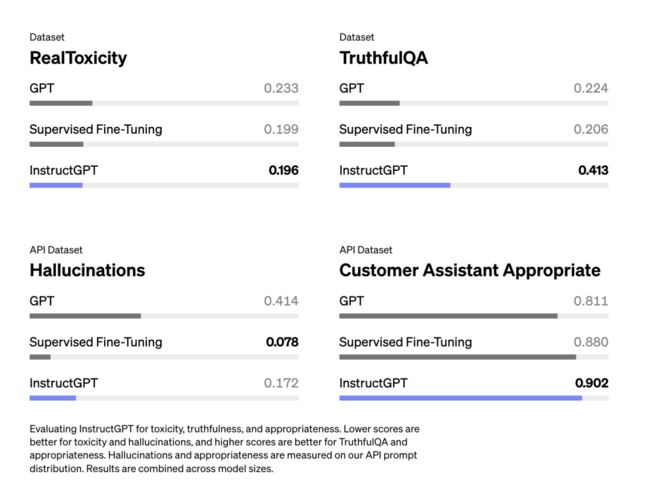
与仅使用SFT(Ouyang等人,2022年)相比,对于InstructGPT(RLHF + SFT)来说,幻觉问题变得更加严重。
基于LLM知道自己了解某一知识的假设,一些人试图通过提示来减少幻觉,例如尽可能提供真实答案,并在不确定答案时说“抱歉,我不知道”。促使LLM进行简洁回答似乎也有助于减少幻觉。LLM需要生成的词元越少,它们编造事物的机会也就越小。
5
结论
写这篇文章的过程十分有趣,希望你阅读的过程也同样享受。我还有一整个版块的内容关于RLHF的限制,例如人类偏好中的偏见,评估的挑战以及数据所有权问题,但决定将其留到另一篇文章中探讨,因为本文的篇幅已经够长了。
在研究RLHF的论文过程中,我对以下三个事实感到震撼:
复杂性:训练ChatGPT这样的模型是一个相当复杂的过程,但令人惊讶的是它居然能够成功运行。
大规模:模型的规模之大令人难以置信。我一直知道LLM需要大量的数据和计算资源,但通过整个互联网的数据进行训练还是令人震撼。
开放性:各个公司公开其流程信息毫不吝啬。DeepMind的Gopher论文有120页,OpenAI的InstructGPT论文有68页,Anthropic分享了16.1万个hh-rlhf对比示例,Meta提供了LLaMa模型供研究使用。此外还有众多社区共享的开源模型和数据集,例如OpenAssistant和LAION。真是百花齐放的时代!
我们仍处于LLM发展的初始阶段。整个世界才刚刚开始意识到LLM的潜力,因此竞争方兴未艾。LLM的各个方面将会不断发展进步,包括RLHF。希望这篇文章能够帮助你更好地了解LLM幕后的训练过程,从而选择与你需求最匹配的LLM。
其他人都在看
语言大模型的进化轨迹
语言大模型100K上下文窗口的秘诀
GPT总设计师:大型语言模型的未来
John Schulman:通往TruthGPT之路
为什么ChatGPT用强化学习而非监督学习
OneEmbedding:单卡训练TB级推荐模型不是梦
GLM训练加速:性能最高提升3倍,显存节省1/3
试用OneFlow: github.com/Oneflow-Inc/oneflow/
