ddia(4)----Chapter4.Encoding and Evolution
In Chapter 1, we introduce the idea of evolvability: we should aim to build systems that make it easy to adapt to change. In most cases, a change to an application’s features also requires a change to data that it stores: perhaps a new field or a record type needs to be captured, or perhaps existing data needs to be presented in a new way.
In Chapter 2, we discussed different ways of coping with such change.
With server-side applications you may want to perform a rolling upgrade. With cliend-side applications, client may not install the update for some time.
In order for the system to continue work smoothly, we need to maintain compatibility in both old codes and new codes.
- Backward compatibility: Newer code can read data that was written by older code.
- Forward compatibility: Older code can read data that was written by newer code.
Formats for Encoding Data
There are two different representations of data, they are:
- In memory, data is kept in objects, structs, trees, etc. They are optimized for efficient access and manipulation by the CPU.
- When you want to write data to a file or send it over the network, you have to encode it as some kind of self-contained sequence of bytes, such as JSON.
The translation from the in-memory representation to a byte sequence is called encoding, and the reverse is called decoding.
Language-Specific Formats
Many programming languages come with built-in support for encoding in-memory objects into byte sequences. But they have a number of deep problems.
- The encoding is often tied a particular programming language.
- Versioning data is often an afterthought in these libraries.
- Efficiency
- Security problems
JSON, XML, and Binary Variants
Problems:
- In XML and CSV, you cannot distinguish between a number and a string that happens to consist of digits. JSON distingushes strings and numbers, but it doesn’t distingush integers and floats/
- JSON and XML have good support for Unicode character strings, but they don’t support binary strings.
Binary encoding
the following is an example:
- This is JSON format:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
- binary encoding for JSON:
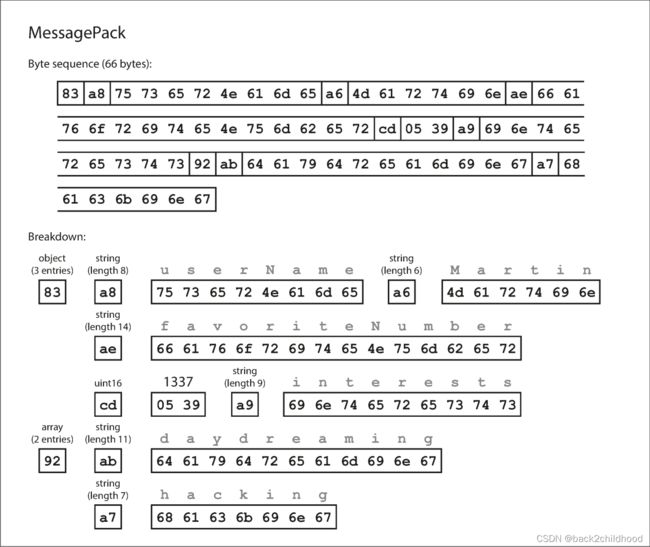
- The first byte, 0x83, indicates that what follows is an object (top four bits = 0x80) with three fields (bottom four bits = 0x03). (In case you’re wondering what happens if an object has more than 15 fields, so that the number of fields doesn’t fit in four bits, it then gets a different type indicator, and the number of fields is encoded in two or four bytes.)
Thrift and Protocol Buffers
Thrift interface definition language (IDL) is like this:
struct Person{
1:required string userName,
2:optional i64 favoriteNumber,
3:optional list<string> interests
}
Protocol Buffers IDL very similar:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
Thrift
Thrift has two different binary encoding formats, called BinaryProtocol and CompactProtocol.
- This is BinaryProtocol:
The big difference compared toMessagePackis that there are no field names(userName, favoriteNumber). Instead, the encoded data contains field tags.

- This is CompactProtocol:
Rather than using a full eight bytes for the number 1337, it is encoded in two bytes, with the top bit of each byte used to indicate whether there are still more bytes to come. This means numbers between –64 and 63 are encoded in one byte, numbers between –8192 and 8191 are encoded in two bytes, etc.

Protocol Buffers
It is similar to Thrift’s CompactProtocol.

in the schemas shown earlier, each field was marked either required or optional, but this makes no difference to how the field is encoded(nothing in the binary data indicates whether a field was required). The difference is simply that required enables a runtime check that fails if the field is not set, which can be useful for catching bugs.
Field tags and schema evolution
How to keep backward and forward compatibility?
- backward compatibility: every field you add after the initial deployment of the schema must be optional or have a default value.
- forward compatibility: only can remove a field that is optional.
Datatypes and schema evolution
However, if old code reads data written by new code, the old code is still using a 32-bit variable to hold the value. If the decoded 64-bit value won’t fit in 32 bits, it will be truncated.
Protocol Buffers is not have a list or array datatype, but instead has a repeated marker for fields.
Thrift has a dedicated list datatype.
Avro
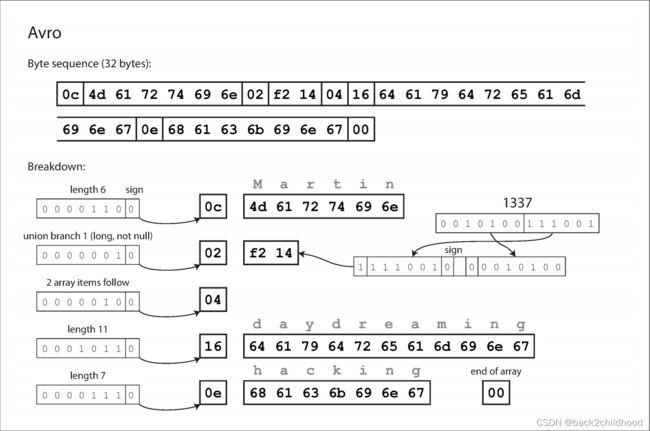
Avro’s IDL look like this:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
The writer’s schema and the reader’s schema
The Avro library resolves the differences by looking at the writer’s schema and the reader’s schema side by side and translating the data from the writer’s schema into the reader’s schema.
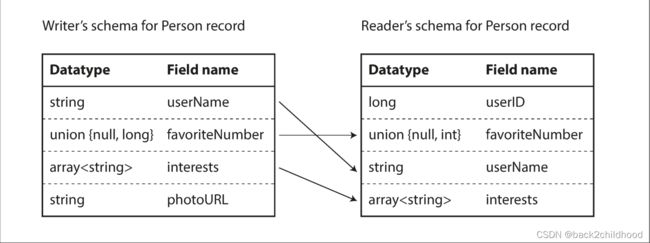
Schema evolution rules
To maintain compatibility, you may only add or remove a field that has a default value.
For example, union { null, long, string } field; indicates that field can be a number, a string, or null.
But what is the writer’s schema?
How does the reader know the writer’s schema?
The answer depends on the context in which Avro is being used. To give a few examples:
- Large file with lots of records
Avro usually stores a large file containing millions of records, in this case, the writer of that file can just include the writer’s schema at the beginning of the file. - Database with individually written records
The simplest solution is to include a version number at the beginning of every encoded record, and to keep a list of schema versions in your database. A reader can fetch a record, extract the version number, and then fetch the writer’s schema for that version number from the database.
Dynamically generated schemas
Avro schema can be easily generated from the relational schema and encode the database contents using that schema. If the database schema changes (for example, a table has one column added and one column removed), you can just generate a new Avro schema from the updated database schema and export data in the new Avro schema.
Code generation and dynamically typed languages
In dynamically typed programming languages such as JavaScript, Ruby, or Python, there is not much point in generating code, since there is no compile-time type checker to satisfy.
Avro provides optional code generation for statically typed programming languages, but it can be used just as well without any code generation.
The Merits of Schemas
Binary encodings have a number of nice properties:
- They can be much more compact than the various “binary JSON” variants, since they can omit field names from the encoded data.
- The schema is a valuable form of documentation, and because the schema is required for decoding, you can be sure that it is up to date (whereas manually maintained documentation may easily diverge from reality).
- Keeping a database of schemas allows you to check forward and backward compatibility of schema changes, before anything is deployed.
- For users of statically typed programming languages, the ability to generate code from the schema is useful, since it enables type checking at compile time.
In summary, schema evolution allows the same kind of flexibility as schemaless/schema-on-read JSON databases provide, while also providing better guarantees about your data and better tooling.
Modes of Dataflow
Compatibility is a relationship between one process that encodes the data, and another process that decodes it. In the rest of this chapter we will explore some of the most common ways how data flows between processes.