java和数据库之间的关系,看这一篇就足够~~~
1.jdbc的基本概念
java database connectiveity:Java数据库连接
说人话就是:java语言操作数据库
程序员 操作 Java语言
此时程序员就希望使用一套统一的java代码
这套java代码面对不同的数据库都是一样的。
所以java的东家sun公司就做出了jdbc,
本质上就是一套接口,定义了操作所有关系型数据库的规则。
实现类交给各家数据厂商去写。
每一个产商都写出了不同的实现类,也就是说,只要有数据库产商想要自己的产品被java使用,就得迎合jdbc,去为它编写实现类。
例如mysql
很明显
java项目中想要操作mysql数据库,就必须使用mysql它们家的一个jar包。
mysql-connector-java-版本号
这个jar也被叫做数据驱动。
2.对jdbc中各个接口和类的详解
导入驱动
注册驱动
数据库连接对象:Connection
定义sql语句
执行sql的对象:statement
执行的结果对像:
处理结果对象
释放资源
很明显,也就是一个套最基本的语言操作数据库的逻辑
以下的对象,在java种都是导入java.sql包下的接口,但是实际上调用的是我们具体使用的jar包种的实现类。
2.1 DriverManager
驱动管理对象
一是注册驱动
二是获取连接对象
事实上注册驱动,是利用反射,将jar包中的com.mysql.jdbc.driver来加载进内存之后,利用静态代码块执行一个方法:

值得一提的是:mysql5之后的jar包,可以在代码中省略注册代码。
因为,版本5以后,将jar包中的这个驱动类的全路径名写进了配置文件。
至于获取连接对象实在是太简单不过。

重点是这个路径,这个路径决定了这个连接对象连接的到底是哪一个机器上的哪一个数据库
语法上每一种数据库都有差别,这里使用mysql举例:
![]()
2.2 Connection
数据库连接对象
一是获取sql的执行对象
二是管理事务,提供了对应的三种方法来开启事务,回滚事务,还有提交事务。
获取sql的执行对象太简单不过:

至于管理事务的三个方法:

2.3 Statement
执行sql对象
执行静态sql,也就是参数是给定的
反之也即是动态的sql,参数是不固定的。
一些方法:
int executeUpdate(String sql):执行DML语句,和DDL语句
增删改表数据都是这个方法
还有创建表,删除表,更改表也是
一般就是DML
int是返回影响的行数。
可以用来判断sql是否执行成功,大于0就是成功,反之就是失败。
ResultSet executeQuery(String sql):执行DQL语句,返回一个结果集对像。
2.4 ResultSet
结果集对象
结果集使用类似集合的迭代器一样的原理来访问结果集的数据
主要就是一个next方法和一个getXXX方法

结果集也是一种资源也需要close。
next方法的返回值是一个Boolean值,true表示有数据。
2.5 PreparedStatement
继承自Statement
也是执行sql的对象
但是功能比Statement更加的强大
执行动态的sql,预编译的sql
一来首先理解什么是sql的注入
举例:比如这一个select单个元组的语句,只是用用户名和密码去查找一个相应的用户,sql的字符串就是这么写的:
sql = "select * from tb_user where username = '" + userName + "' and password = '" + passWord + "'";
这条sql就是一条静态的sql,一定会有两个where后的条件参数进来完成的本sql语句的拼接。
那么,如果passWord这个字符串变量传进来的是这样的一个值:
a' or 'a' = 'a
这样一来,这个静态sql的password处最后的结果是这样的:
password = ' a' or 'a' = 'a '
此时我们就会发现,userName和passWord具体是什么值已经没有关系了,整个where之后就是true,于是和select all没有区别。
所以什么是sql的注入:
就是拼接sql字符串时,有一些sql的特殊关键字参与了拼接,安全性出问题。
如上例中这条sql原本只是要使用where之后的两个条件参数使用and连接,
and后还拼接了or,导致where整个变成了恒等式。
那么jdbc怎么解决这种注入问题呢?
sun公司专门提供了PreparedStatement对象,来应对这种问题。
提供了预编译sql的概念
静态的sql是参数进来就完成了sql的拼接,所以静态的sql容易出注入问题。
而预编译sql就是sql中的参数先使用?号代替,?被叫做占位符。
直到sql被执行时,给?号附上值就好了。
预编译说白了,就是sql的结构不会再因为参数的传入而改变,参数的值就是绝对的作为?号的值。
(注意:这里的sql的结构,可以是根据参数的有无和个数,而动态生成的。这里sql结构不会因参数变化指的是到了参数给?赋值的阶段,此时sql的结构已然是确定的了。)
获取PreparedStatement对象:
![]()
然后在使用方法之前必须要先给预编译的sql中的?号set值。

这个prepared的对象在使用方法时,直接调用即可。
3.原生jdbc访问数据库
3.1 简单示例

3.2 框架的雏形
jdbc工具类思想:进一步做正确的释放资源,并做一个工具类改善这些繁杂且重复的工作,使用静态块在工具类的加载时,加载jdbc配置文件信息,做信息和代码的解耦。
这种思想是细思极恐的,因为这种将jdbc的操作封装起来的,改进起来,将数据库的连接信息和代码分离出来的做法,就是框架的雏形。
3.3 原生的事务管理
其实就是使用的连接对像的三个方法来实现事务的管理
在try{}中获取到连接对象后直接setAutoCommit(false);
在try{}中,只要程序正常走完自然就是commit();
但是如果被catch到异常,那么直接就是rollback();
4.改进原生,使用数据库连接池
4.1 为什么要有数据库连接池
每一次dao层的方法都要获取一次连接对象。
完了又每一次都要释放掉。
相当于现在的代码逻辑是:每当有客人来,新招聘一个服务员,客人走了,就解雇一个该服务员,这样的逻辑是十分浪费性能的。
因为所谓的连接对象事实上完全可以用来重复的使用。
就像服务员,完全可以对不同的客人服务。
4.2 连接对象的容器
就是以后每一次访问数据库时,不再是获取一个新的连接对象,而是统一的去一个管理连接对象的容器中,拿一个连接对象出来用。用完之后的连接对象也不再是释放掉,而是归还这个容器。
这个连接对象存放的容器被叫做数据库连接池。
4.3 DataSource接口
事实上,sun公司也定义了什么是数据库连接池:
就是java.sql包中的DataSource接口。
也和jdbc一样,由对应的数据库产商提供实现。
有三种实现:
1.基本实现:生成标准的连接对象
2.连接池实现:生成将自动参与连接池的连接对象
3.分布式实现:生成可用于分布式事务的连接对象
DataSource中一定会有一个方法,用这个方法来获取连接对象。
getConnection()
那么关键就是这个DataSource接口的实现到底使用的什么实现jar包。
一种是C3P0
一种是Druid
这两种技术都实现了DataSource接口。
值得注意的是:所有的实现技术,都将连接对象的close方法改成了归还给连接池,而不是原来的直接释放。
4.4 使用德鲁伊实现技术
以下就是基本步骤:
1.druid-版本号.jar
2.编写properties配置文件
3.配置文件怎么加载读取
4.怎么获取连接对象的容器
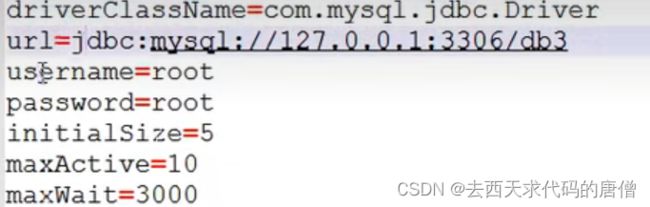
一些配置信息:
驱动类名称:这个就是jdbc具体是那个数据库产商实现jar包的驱动类
url:具体的数据库位置
用户名:
密码:
初始化的连接对象个数:
最大的连接对象个数:
拿连接对象时最多等待几秒:
加载配置文件:
Properties pro = new Properties();
InputStream is = 当前类的名称.class.getClassLoader().getResourceAsStream(“druid.properties”);
pro.load(is);
获取容器对象:
德鲁伊的技术实现中有一个工厂类:DruidDataSourceFactory
它有个静态方法:createDataSource(pro)
这套操作下来就是得到了DateSource的实例。
4.4 一个项目中,一个目标数据库有且只有一个数据源
也就意味着,数据源这东西应该随着项目的启动而创建,并且,有且只有一个实例,还要能够在项目中随处可拿。
使用工具类:
使用静态变量和静态代码块技术:

5.使用spring框架的数据库处理方案
5.1 jdbc模板
spring框架提供Dao层的一个解决方案:
当我们使用原生的JDBC时,
要再try{}执行的操作如下:
0.申请连接
1.我们要写一个字符串:作为预编译的sql
2.然后要利用这个预编译的sql作为参数得到执行对象
3.执行对象要对占位符set值
4.执行对象再调用executeUpDate或者executeQuery方法
5.如果是executeQuery方法,还要处理Result对象。
6.归还连接
特别是处理Result对象的时候,麻烦死了。
Spring框架就对此提供了一套简单的封装,提供了一个JDBCTemplate对象。
1.jar包
2.创建JdbcTemplate对象,这个对象依赖于DataSource
3.dao层使用JdbcTemplate提供的一套方法。
从此,不关心连接的申请和归还,只关心预编译sql的书写,执行和处理。
一些方法:
int update(预编译sql,?列表):执行DML语句,也就是我们的增删改,就是insert、delete、update。
Map
用于查询一个元组的情形,键对应元组的字段名,值对应该元组的字段值。
注意:如果查询结果有两个元素就会报错。
List
注意,list中的每一个元素就是一个map集合。
用于查询结果是多个元组的情形。
List<泛型> query(预编译sql,RowMapper<泛型>接口的实现类,?列表):将结果封装成javaBean对象的list。
注意:RowMapper<泛型>这个接口可以自己实现,实现方式一般就是使用匿名内部类。(匿名内部类的知识忘了就自己去查)
也可以直接使用已经有的实现类,BeanPropertyRowMapper<泛型>(泛型的反射)。
注意:使用这个BeanPropertyRowMapper实现类对javabean是有要求的,属性的数据类型必须是引用类型,也就是基本数据类型也要写成它的包装类。道理很简单,因为表中的数据有的字段值是null,如果不是引用类,值为null时就会报错,没有基本数据值是为null的。
还有就是属性名要和字段名一致。
基本类型的包装类 queryForObject(预编译sql,包装类的反射,?列表):将结果封装成对象,一般是基本数据类型的对象。
5.1.1 一些小案例
查询id为1的记录,将其封装成map集合
查询所有记录,将其封装成list集合
查询所有记录,将其封装成javabean对象的list集合
查询总记录数
5.2 Spring中怎么做事务控制
既然spring框架提供了一套封装的JDBC操作
这套操作使用DataSource作为参数
得到JdbcTemplate对像
而JdbcTemplate对象的每一个方法都默认是一次事务。
从此,再也不用管原生的jdbc中的conn对象,pstate对像,Result对象
而原生的jdbc中事务管理是使用的conn的三个方法。
这样就很难受。
那么spring自然应该对事务的管理也提供解决方案。
5.3 编程式事务控制
了解spring框架提供的管理事务的对象和方法
这个是后面学习AOP声明式事务控制的基础,因为就算是AOP,底层肯定也是使用的这些方法。作为一种增强。才能取代编程式,对代码解耦合。
首先spring给提供的一个东西
叫做平台事务管理器
PlatformTransactionManager
这个接口就提供了我们操作事务的方法
注意:这个平台事务管理器是一个接口,是spring框架提供的。
既然是接口那么就要有相应的实现jar包
就像java.sql提供了jdbc接口和DataSource接口。
jdbc的实现取决于项目使用什么数据库产商的产品
datasource的实现取决于使用什么连接对象的池化技术
由此推断,PlatformTransactionManager的实现应该就取决于spring框架整合了什么数据层的技术,也就是说,项目的dao层是使用的什么技术。
这里介绍一个PlatformTransactionManager的实现类
是org.springframework.DataSourceTransactionManager
这个是当dao层使用的是原生的jdbc技术时使用。
和JdbcTeamplate对象一样,PlatformTransactionManager对象也依赖数据源。因为说到底,jdbc的连接对象的那三个方法才是控制事务的最底层。
PlatformTransactionManager提供了以下的方法:
1.TransactionStatus getTransaction(TransactionDefination td);
这个方法的返回值是一个TransactionStatus对象,参数是一个TransactionDefination对象,作用是获取事务的状态信息。
2.void commit(TransactionStatus ts);提交事务
这个方法要传入一个TransactionStatus对象
3.void rollback(TransactionStatus ts):回滚事务
这个方法也要一个TransactionStatus对象。
5.3.1 事务定义信息对象td
TransactionStatus对象就依赖于这个定义信息对象
td中有这样一些方法:
int getIsolationLevel():获取事务的隔离级别
int getPropogationBahavior():获取事务的传播行为
int getTimeout():获取事务的超时时间
boolean isReadOnly():事务是否只读
也就是说,TransactionStatus事务的状态对象的获取依赖于一个封装着事务的所有基本信息的事务定义信息对象。
5.3.2 事务的状态对象ts
TransactionStatus也就是这个对象
这个对象是spring的平台事务管理器PlatformTransactionManager的
提交和回滚方法的依赖
有这样的方法:
boolean hasSavepoint() :是否存储回滚点
boolean isCompleted():事务是否完成
boolean isNewTransaction():是否是新事物
boolean isRollbackOnly():事务是否回滚
事务的状态是随着时间的变化而变化的。
总结:也就是说事务的定义对象td的信息是主动的,是我们人为设置的,
而事务的状态对象ts的信息是被动的,是在程序的运行过程中得到的。
5.3.3 总结spring提供的事务解决方案
spring框架的编程式事务三大对象:
PlatformTransactionManager:
TransactionDefination:
TransactionStatus
以下简称平台对象,定义对象和状态对象
平台对象操作事务的行为,
定义对象设置事务的属性
状态对象反馈事务运行过程的信息
5.4 基于xml的声明式事务控制
在配置文件中声明,底层利用AOP的原理,对方法进行事务控制的增强。
在什么配置文件中声明
怎么声明
声明后怎么发挥作用
声明式的事务控制,事务管理不再是硬编码的方式,不侵入开发的组件,也就是说,业务逻辑对象(方法)不知道自己正在事务的管理之中,事务管理是属于系统层面的服务,而不是业务逻辑的一部分,如果想要改变对某一个或者某一批业务逻辑对象的事务管理策划,只需要在配置文件中改动即可。
注意:事务控制的增强类(通知)不需要我们写了,已经有人帮我们抽取出来做好了。我们需要做的就是引入相应的命名空间,tx命名空间。
在applicationContext.xml中
锁定切点
切点在哪里
就在spring容器的某一个或者某些对象里(方法)
锁定通知
通知类依赖于平台对象,所以平台对像也要交给spring容器管理。
5.4.1 声明的步骤
1.将平台对象配置进spring的容器
2.配置通知(增强)信息
3.配置织入
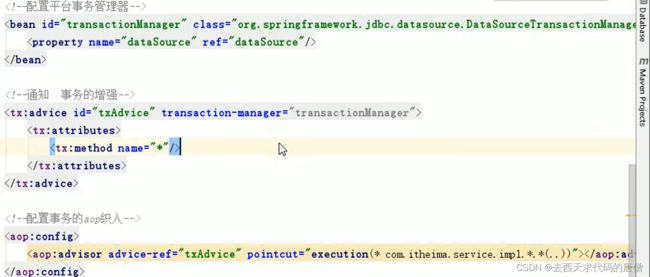
值得注意的是:这个平台事务管理器,是Spring框架的接口的实现类,这个实现类和具体的dao层技术有关。
5.4.2 关键在于第二步:配置增强的信息

说白了就是细化到具体的方法上的事务属性td的设置。

5.4.3 总结xml配置事务
一是平台事务管理器的配置
也就是配置spring框架的PlatformTransactionManager接口,这个接口的配置取决于spring想整合什么dao层的技术。
二是对通知的配置,也就是增强的配置,这个通知是不需要我们自己编写的spring也帮我们做好了,既然是事务的通知,用于对方法进行事务的增强,这里自然有关于事务的属性的信息的配置,并且可以细化到具体的某个方法。当然,方法的来源自然来自下方配置的切点表达式。
三是对通知和切点进行织入,这一步决定了,这个事务的通知能在哪个包下的哪些类的哪些方法上起作用。关键就在于这个切点表达式怎么写。
5.5 基于注解的声明式事务控制
将xml的配置转换成注解
首先容器中的bean用注解配置
像什么dao的实现类呀
service的实现类
spring的原则上就是自定义的bean使用注解配置进容器,非自定义的bean使用配置文件配置进容器
@Repository(“id”):dao层
@Service(“id”):业务层
@Autowired:依赖注入
使用注解的话,要记得配置组件扫描:
组件扫描使用到context命名空间。
除了平台事务管理器的配置依然要配置在xml中
通知的配置和织入的配置可以换成注解
@Transaction(isolation = 枚举,…)
但是:xml中取而代之的是一个事务的注解驱动,和组件扫描是一个道理。
同时这个事务的注解驱动依赖于平台事务管理器。
![]()
这个注解可以加到方法上也可以加到类上。
6.使用mybatis的数据库处理方案
6.1 spring提供的解决方案有什么不足
JdbcTemplate是spring为dao层提供的一套解决方案,
本质上是就原生的jdbc操作进行了一层封装
对内传入一个数据源
对外屏蔽了对连接对象,执行对象和结果集对象,还有事务控制的操作。
也就是一个方法本身就是一个事务,并且包含了资源的申请和释放的操作
使得我们可以只关注于sql和结果的处理
但是,它的不足之处就是
1.sql依然是和代码耦合到一块,当sql的结构要随着参数的变化而变化时,依然得用代码来控制。
2.这套jdbc模板的查询结果无非就是查询单个元组的map集合,查询多个元组的list集合,和查询单个字段的object。当业务的sql是复杂的多表查询时,依然显得呆板。
3.没法满足一些java数据类型和数据库数据类型之间互相转换的需求,例如进了java程序是一个日期对象,但是存到数据库中是一个拟定格式的字符串。
6.2 mybatis概述
内部封装了jdbc,使得开发只需要关注sql本身。可以满足高级的复杂的sql语句的业务需求。结果也不用开发人员处理,开发者只需要关注配置时的sql怎么写和结果集怎么和javabean映射。
使用了mybatis,我们和jdbc的API就屏蔽了。
本质上也是对jdbc的升级优化。这点很重要,说明底层还是jdbc。
mybatis中有一种思想叫做对象关系映射,就是数据表和javabean之间的互相映射。称为ORM
6.2 入门使用
1.导入坐标
2.编写数据表和实体类的映射文件XXXMapper.xml
3.编写核心配置文件SqlMapConfig.xml
4.进行测试
6.2.1 映射文件
映射文件使用dtd约束
在mapper根标签中
有个属性叫namespace=“”:命名空间,对应dao层的接口。
可以配置多个DML和DQL标签。
也即是select、update、delete、insert。
id属性就是映射方法名
parameterType属性就是映射方法的参数
resultType属性就是映射结果集类型,对应方法的返回值(这个resultType的意义就和JdbcTemplate方法参数中的RowMapper<泛型>接口的实现类或者包装类的反射的意义差不多)
6.2.2 核心配置文件
核心配置文件也有自己的约束
根标签是configuration
1.配置数据源环境,可以分成开发环境,测试环境

2.加载映射文件

6.2.3 加载核心配置文件+传统实现
加载核心配置文件
mybatis提供了一个类:Resources
有个静态方法叫getResourceAsStream(“核心配置文件名”)
得到核心配置文件的inputStream进入内存
还有个类:SqlSessionFactoryBuiler
有个非静态方法叫build(“核心配置文件的字节流”)
得到一个SqlSessionFactory,叫会话工厂对象
这个对象有个openSession方法
得到一个SqlSession,叫会话对象。
这个对象中有一套方法
用来执行映射文件中的具体的sql。
注意:会话对象是需要手动释放的。
注意:会话对象执行方法默认是开启了事务,并且查询操作默认只读,不需要提交,但是如果不是查询的方法,是需要手动提交的
本质上,和JdbcTemplate对象一样,只不过实现了sql语句从代码中抽取了出来。
6.3 深入使用
6.3.1 映射文件
(1)参数
首先就是parameterType属性
这个属性决定了sql语句中能传进来什么参数
不同于JdbcTemplate的方法,参数是一个一个跟着占位符的顺序传进来。
parameterType还多一个层封装,从此预编译的这个sql中的?号将写成#{字段名},意义是一样的。
(2)动态sql结构
第二个就是动态sql:
这里的动态sql和预编译那里的动态sql是不一样的概念
预编译的动态指的是sql语句在被执行之前,不是写死(静态)的,是根据执行时占位符具体传入的值决定的。
这里的动态指的是,根据参数的有无和个数决定sql的结构不同。
例如根据条件查询:where之后跟一个条件还是多个条件
该预编译sq执行之前l的结构自然就不一样。
where标签,也可以使用where 1 = 1来平替
if标签,test属性就是if的条件
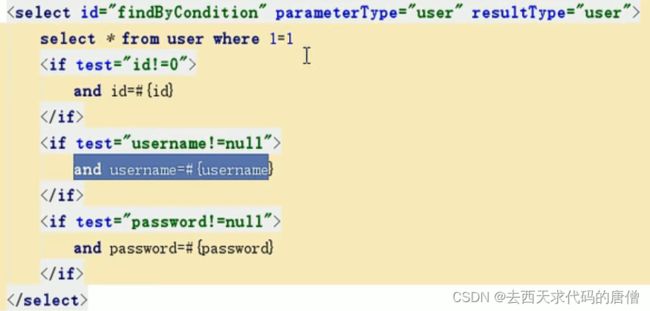
以上是and条件的结构变化,如果是or呢,换句话说是in呢
foreach标签,collection属性是参数收集器,可以是list或者array,说白了看方法参数是不是数组或者list。open属性是前缀,close标签是后缀,在拼接之中,循环之外。item属性就是循环对象,separator属性是分隔符。
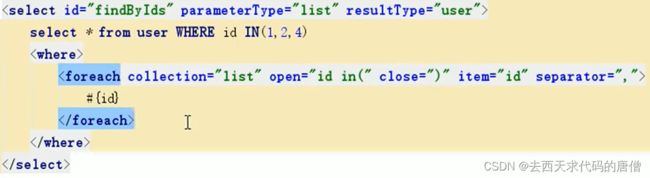
本质上就是在配置文件层面将sql的结构进行了逻辑控制。
(3)sql片段的抽取
第三个就是sql片段的抽取
抽取
![]()
在引用
![]()
连这都想着解耦,疯狂啊
(4)返回值
第四个就是自定义结果集
就是针对性的将查询结果中的一些字段封装到一个对象,而这个对象实际上是javaBean的一个属性。
说白了就是多表查询时,原来的resultType映射的实体不够用了,因为多表查询的字段数必定超过单个实体类。
可是mybatis目前的结果映射只能是用resultType属性映射到一个javabean。
如今应该怎么做呢?
使用resultMap标签自定义结果集和javabean的关系。
要使用resultMap属性替换resultMap
这个的强大之处在于手动的指定字段和实体属性的映射关系。
有三种方法
第一种:
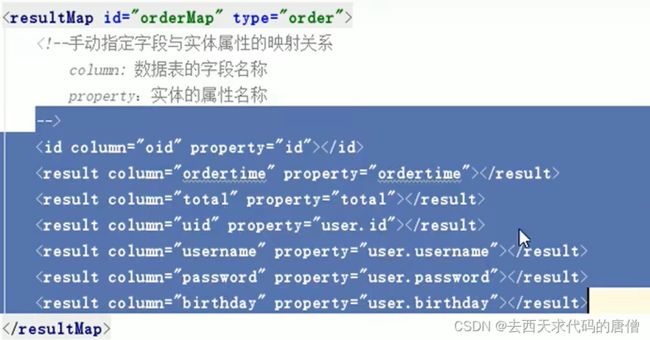
一个字段一个字段的解释。
第二种:部分字段和javabean的属性对象进行匹配

这个方法的可读性就更高了。
第三种:当javabean中的属性是一个list时,这部分字段应该和list的泛型进行匹配

注意:使用association还是collection就是看javabean中属性是单个对象还是对象的list。分别对应的业务不就正是一对一和一对多嘛。
6.3.2 核心配置文件
(1)数据源环境
首先就是数据源环境
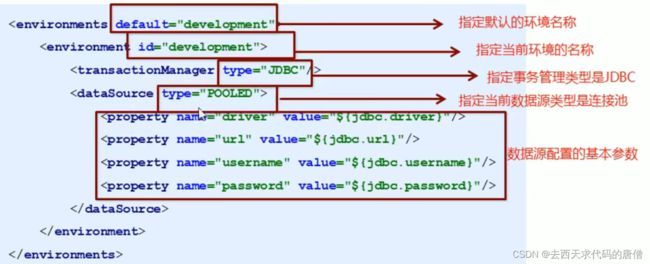
这个重点就是两个地方:一个事务管理类型,一个是数据源类型
事务类型一般就是JDBC:意味着依然使用原生的JDBC的连接对象来控制事务,如果是MANAGED:意味着将事务的控制交给容器来管理,并且默认情况下,会将连接对象关闭。
数据源类型:就是三种:一个是UNPOOLED:就是非池数据源,每一次连接对象都是新申请的,一种就是POOLED,池化数据源,连接对象存放在一个容器中,一种就是JNDI:这个数据源是为了能够在EJB或者应用服务器这个类容器中使用,容器可以集中或者在外部配置数据源,然后放置一个JNDI上下文的引用。
(2)加载映射文件
再来就是加载映射文件的时候:
主要就是使用mapper标签

常用的就是第一种方法。
第四种,常用于注解开发。
(3)加载其他配置文件
第三个配置就是核心配置文件怎么加载其他配置文件
使用properties标签
然后使用${}获取值

将数据源的配置信息再解耦
(4)设置别名
第四个配置就是,类的全路径设置别名
使用的是typeAliases标签

像java.lang.Integer可以直接写成int
那是mybatis自己帮我们定义过了
而其他的需求就需要自己自定义了
(5)类型转换处理器
第五个就是类型处理器了
事实上,mybatis已经做了基本类型的转换工作
在预编译占位符传值时,在结果集取值时
都会触发java数据类型和数据库数据类型的转换工作

但是如果是特殊的转换需求呢?例如java的时间类型和数据库字符串类型的转换
mybatis提供了一个接口,叫做
![]()
还有一个实现类,叫做
![]()
例如,如果使用BaseTypeHandler实现类
第一步:继承并指定泛型,这个泛型就是java的某一个数据类型,必须是引用类型。
第二步:重写他的四个方法,第一个方法是处理参数进Preparedsql时转换成数据库数据类型,剩下的都是出数据库时转成java类型。
第三步:在核心配置文件中进行实现类(转换器)注册

使用的一个typehandlers标签
(6)插件
第六个配置的就是mybatis的插件了
mybatis可以使用第三方的插件来对功能进行扩展,例如使用分页助手Pagehelper
第一步:导入pagehelper的依赖
第二步:在核心配置文件中配置

记住还有一个解析器

记得这个插件是要指定参数的,分页的limit是mysql的方言嘛。
配置完了之后,就会有一个类叫PageHelper,这个类有一些静态方法,
startPage(int pageNum,int pageSize);
意思就是设置当前页和每页显示条数
这个方法写在findAll方法之前,就会使得findAll方法的sql自动加上limit
更有意思的是,分页的信息的获取
又有一个叫做PageInfo的对象
这个对像要指定泛型,参数就是分页查询出来的结果,一般就是list对象
这个对像new出来以后,就能轻而易举的得到当前页,每页显示条数,总条数,总页数,上一页数,下一页数,是否是第一页,是否是最后一页等信息。
6.3.3 接口代理实现
mybatis做dao层的技术的话,
传统的开发方式就是和以前一样为dao层的接口编写实现类,然后在实现类的方法中使用那套mybatis固定的API得到SqlSession对象,调用insert、delete、update、select*方法指定对应的映射文件中的某个sql语句。
但是仔细观察发现,dao层只写接口也可以,因为接口中的方法和映射文件中的CRUD标签一一对应,而根据标签中的sql语句,又能直接知道具体是执行SqlSession对象的哪一个方法,其余的什么commit和close都是通用的共有的。
于是mybatis做了一套接口代理的开发方案,为dao层的接口提供一个代理对象,这个代理对象就是运行时的接口实例,然后,这个代理对象直接调用dao层接口的方法即可。

接口开发必须满足这四个规范。
sqlSession对象:提供了一个方法:
getMapper(接口的反射);
得到一个代理对象。
6.4 mybatis的注解开发
注解开发,本质上的目的是为了简化配置
要记得具体是减少了哪些xml的配置,新增了什么xml配置
注解开发:
一般有引进新的命名空间,组件扫描,注解驱动几个概念。
可以去除映射文件,同时核心配置文件中加载映射文件处改成加载映射关系,本质上也是一种注解扫描,是一种对@insert、update、delete、select注解的扫描。
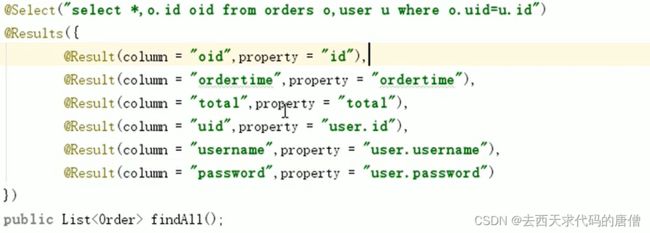

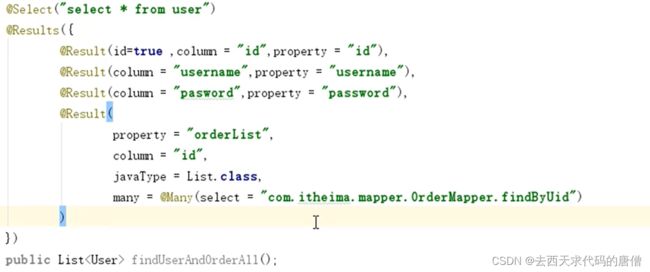
7.spring整合mybatis
目前,mybatis的开发虽然可以使用接口代理的方法简化很多代码。
就算再进一步使用工具类,但是依然在service层有这样的重复代码
就是
![]()

也就是得到代理对象的工作和事务控制的工作
如果和spring整合到一起可以不可以将接口代理对象交给Spring容器控制,可不可以将事务的控制交给Spring容器进行声明式事务控制。
spring整合mybatis做四个事情:
一个是将数据源的配置放进了spring,取代核心配置文件中的数据源环境配置,毕竟多环境以后也是由系统层面来控制。
二是是在将会话工厂对象配置进spring容器。

三是配置声明式事务
注意,由于mybatis的底层使用的也是jdbc的那一套技术,所以spring配置事务平台管理器时,mybatis的和JdbcTemplate的PlatformTransactionManager是一样的。
四是,扫描映射文件和mapper接口,分两种情况,一种是接口和映射文件在同一个路径下和同一个包中时使用

一般不直接在Mybatis的配置文件里进行配置,而会在Spring的配置文件里使用MapperScannerConfigurer来配置。
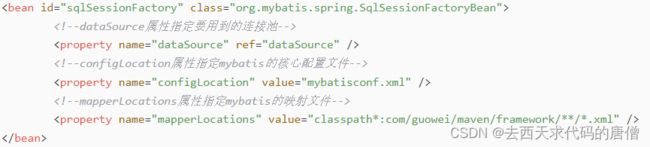
如果Mybatis映射XML文件和映射接口文件不放在同一个包下,那就还需要在上面的基础上,手动配置SqlSessionFactoryBean的mapperLocations属性,如下所示:
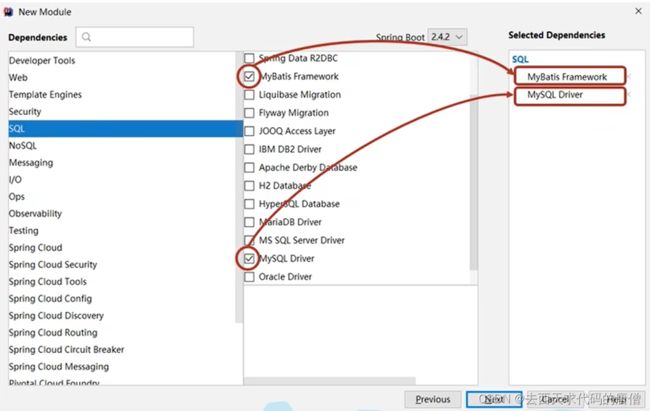
8.在spring boot工程中使用mybatis
在springboot中导入对应的starter
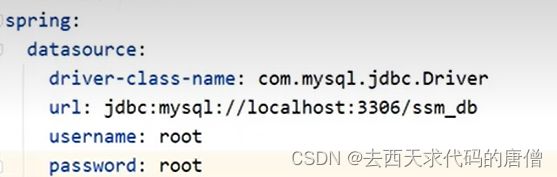
配置数据源
非Druid数据源
@Mapper+@Repository
这里的@Mapper也是可以去掉的,但是要在启动类上加上
@MapperScan(value = {“com.bf.spring4.mapper”})
这句话的意思是扫描Mapper类。
如果不是使用注解开发
需要配置扫描映射文件
配置mapper
mybatis:
mapperLocations: classpath:mapper/*.xml
config-location: classpath:mybatis-config.xml
typeAliasesPackage: com.example.domain
注意:springboot工程中,mybatis的核心配置文件中的各项配置也是在application.yml文件中配置的。
注意:别名是这样的com.example.domain.User --> User.
就是类名。
将数据源配置成使用德鲁伊的技术实现
spring:
datasource:
url: jdbc:mysql://localhost:3306/springbootdata?serverTimezone=UTC&useUnicode=true&characterEncoding=utf8&useSSL=false
username: root
password: 111111
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
druid:
#初始化大小
initialSize: 5
#最小值
minIdle: 5
#最大值
maxActive: 20
#最大等待时间,配置获取连接等待超时,时间单位都是毫秒ms
maxWait: 60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接
timeBetweenEvictionRunsMillis: 60000
#配置一个连接在池中最小生存的时间
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,
#'wall’用于防火墙,SpringBoot中没有log4j,我改成了log4j2
filters: stat,wall,log4j2
#最大PSCache连接
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# 配置StatFilter
web-stat-filter:
#默认为false,设置为true启动
enabled: true
url-pattern: “/"
exclusions: ".js,.gif,.jpg,.bmp,.png,.css,.ico,/druid/"
#配置StatViewServlet
stat-view-servlet:
url-pattern: "/druid/”
#允许那些ip
allow: 127.0.0.1
login-username: admin
login-password: 123456
#禁止那些ip
deny: 192.168.1.102
#是否可以重置
reset-enable: true
#启用
enabled: true
8.1 多数据源
spring:
datasource:
one:
driver-class-name: com.mysql.jdbc.Driver
jdbc-url: "jdbc:mysql://localhost:3306/xxx?useUnicode=true&characterEncoding\
=utf8&useJDBCCompliantTimezoneShift=true\
&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8&useSSL=true&allowMultiQueries=true&autoReconnect=true&useAffectRows=true"
username: root
password: root
two:
driver-class-name: com.microsoft.sqlserver.jdbc.SQLServerDriver
jdbc-url: jdbc:sqlserver://localhost:1433;DatabaseName=xxxx//1433 sqlService 默认端口
username: sa//默认用户名
password: root
————————————————
编写两个spring的配置类
@Configuration //第一个包扫描
@MapperScan(basePackages = {"xx.xx.xx.dao.xxdao"}, sqlSessionFactoryRef = "oneSqlSessionFactory")
public class OneDataSourceConfig {
@Value("${spring.datasource.one.driver-class-name}")
String driverClass;
@Value("${spring.datasource.one.jdbc-url}")
String url;
@Value("${spring.datasource.one.username}")
String userName;
@Value("${spring.datasource.one.password}")
String passWord;
@Primary
@Bean(name = "oneDataSource")
@ConfigurationProperties("spring.datasource.one")
public DataSource oneDataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(userName);
dataSource.setPassword(passWord);
return dataSource;
}
@Bean(name = "oneSqlSessionFactory")
@Primary
public SqlSessionFactory oneSqlSessionFactory(@Qualifier("oneDataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean();
sessionFactoryBean.setDataSource(dataSource);
sessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath*:mapper/xxxMapper/*.xml"));//第一个mapper.xml
//配置多数据源需要设置驼峰规则,否则不生效
org.apache.ibatis.session.Configuration configuration=new org.apache.ibatis.session.Configuration();
configuration.setMapUnderscoreToCamelCase(true);
sessionFactoryBean.setConfiguration(configuration);
return sessionFactoryBean.getObject();
}
@Bean(name = "oneSqlSessionTemplate")
@Primary
public SqlSessionTemplate oneSqlSessionFactoryTemplate(@Qualifier("oneSqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
————————————————
@Configuration
@MapperScan(basePackages = "xx.xx.xx.xx.xxdao",sqlSessionFactoryRef = "twoSqlSessionFactory")
public class TwoDataSourceConfig {
@Value("${spring.datasource.two.driver-class-name}")
String driverClass;
@Value("${spring.datasource.two.jdbc-url}")
String url;
@Value("${spring.datasource.two.username}")
String userName;
@Value("${spring.datasource.two.password}")
String passWord;
@Bean(name = "twoDataSource")
@ConfigurationProperties("spring.datasource.two")
public DataSource masterDataSource(){
DriverManagerDataSource dataSource = new DriverManagerDataSource();
// dataSource.setDriverClassName(driverClass);
dataSource.setUrl(url);
dataSource.setUsername(userName);
dataSource.setPassword(passWord);
return dataSource;
}
@Bean(name = "twoSqlSessionFactory")
public SqlSessionFactory sqlSessionFactory(@Qualifier("twoDataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean();
sessionFactoryBean.setDataSource(dataSource);
sessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath*:/mapper/xxMapper/*.xml"));
//**配置多数据源需要设置驼峰规则,否则不生效**
org.apache.ibatis.session.Configuration configuration=new org.apache.ibatis.session.Configuration();
configuration.setMapUnderscoreToCamelCase(true);
sessionFactoryBean.setConfiguration(configuration);
return sessionFactoryBean.getObject();
}
@Bean(name = "twoSqlSessionTemplate")
public SqlSessionTemplate sqlSessionFactoryTemplate(@Qualifier("twoSqlSessionFactory")SqlSessionFactory sqlSessionFactory ) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
————————————————

8.2 多环境
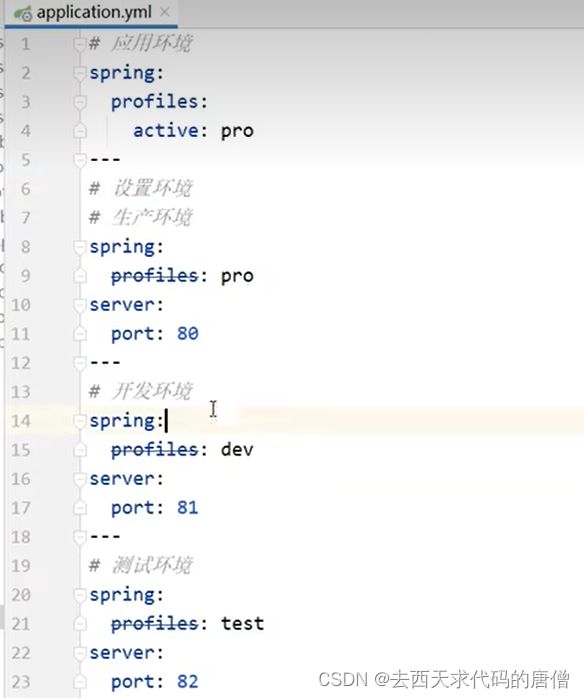
这种多文件的方式


根据这个思路,在多环境的同时,将功能配置也做一个拆分
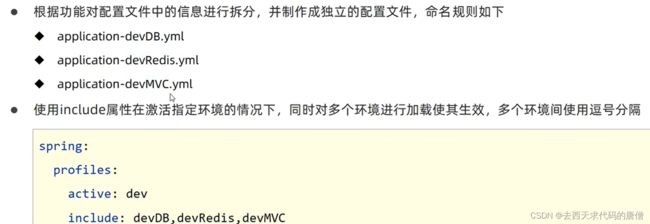
这里要注意加载顺序,include是顺序加载,而active是之后加载的,后加载会覆盖之前的。
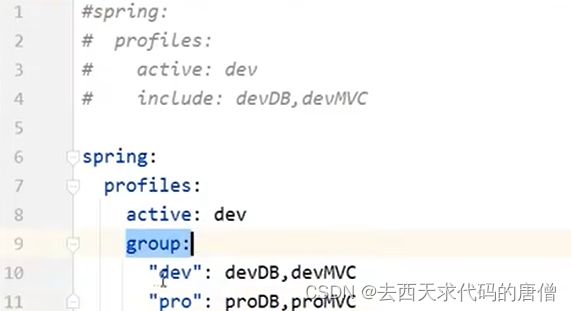
在springboot2.4版本之后,这样的开发
那么是springboot依赖于maven
还是maven依赖于是springboot
答案是Springboot是基于maven在运行的。
如果在maven中也配置了多环境,一定是以maven中配置的为主
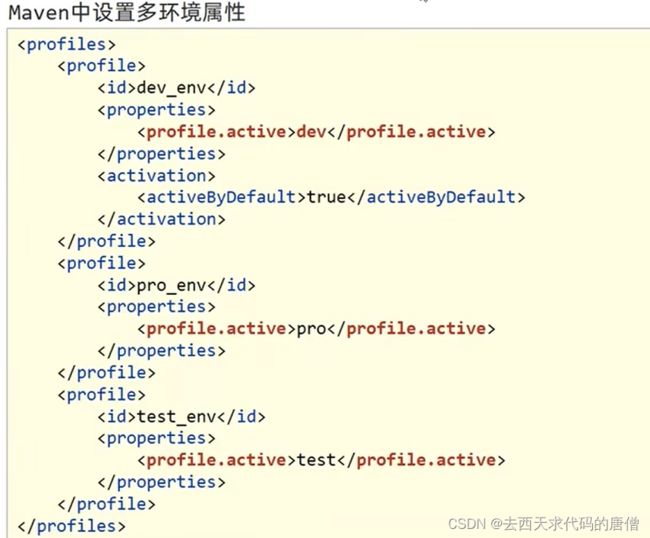


8.3 使用事务
Spring声明式事物的实现,有两种方式;第一种是配置xml,第二种是使用相关注解
SpringBoot中默认配置了第二种方式,所以,SpringBoot直接使用注解即可。下面介绍SpringBoot通过注解开启事物的使用。
在启动类上开启事物支持

在业务逻辑层接口的实现类中的相关方法上声明事物
![]()