pySpark(一) 概述
pyspark
介绍:
pySpark是spark的一个工具,是spark提供的用python写的sparkAPI库。
原理:
通过py4j这个,,将pythonAPI链接到sparkContext上,以此python程序可以动态的访问jvm中的java对象,java也可以动态的回调python对象
架构图:
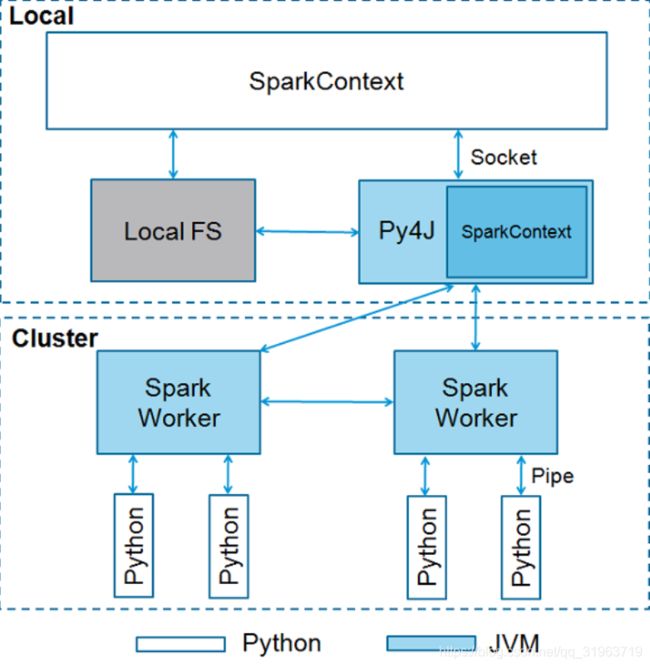
首先SparkContext是spark程序的入口,SparkContext使用Py4J启动 JVM 并创建 JavaSparkContext。
py4J启动sparkContext后, 分发到work节点, 所以集群节点上必须有python环境才能解析python文件。
pyspark sparkContext的参数及意义:
- Master - 它是连接到的集群的URL。
- appName - 您的工作名称。
- sparkHome - Spark安装目录。
- pyFiles - 要发送到集群并添加到PYTHONPATH的.zip或.py文件。
- environment - 工作节点环境变量。
- batchSize - 表示为单个Java对象的Python对象的数量。 设置1以禁用批处理,设置0以根据对象大小自动选择批处理大小,或设置为-1以使用无限批处理大小。
- serializer - RDD序列化器。
- Conf - L {SparkConf}的一个对象,用于设置所有Spark属性。
- gateway - 使用现有网关和JVM,否则初始化新JVM。
- JSC - JavaSparkContext实例。
- profiler_cls - 用于进行性能分析的一类自定义Profiler(默认为pyspark.profiler.BasicProfiler)。
在上述参数中,主要使用 master 和 appname 。任何PySpark程序的前两行如下所示:
from pyspark import sparkContext
sc = SparkContext("local", "appName")
sparkConf:
要运行spark必须要sparkContext 但是需要配置参数 就需要sparkConf,其参数及意义:
- set(key,value) - 设置配置属性。
- setMaster(value) - 设置主URL。
- setAppName(value) - 设置应用程序名称。
- get(key,defaultValue = None) - 获取密钥的配置值。
- setSparkHome(value) - 在工作节点上设置Spark安装路径。
运行方式:
1.pySpark shell 交互型
2.执行python.py脚本,其实就是提交的过程,用spark-submit #参数# #file.py#
pySpark语法:
其实语法与 rdd的常规语法相似
官方API文档:http://spark.apache.org/docs/latest/api/python/