Lottery抽奖项目第二章第二节:搭建DDD四层结构
搭建DDD四层结构
DDD:Domain Driven Design
描述:基于DDD架构构建,初始化搭建工程结构
本节是陆续搭建系统和编码的开始,我们会优先完成一个基础工程的创建。一般在互联网企业这部分工作可能不需要反复处理,只需要在承接产品需要后使用脚手架或者直接复制以往工程就可以创建现有需要使用的工程了。例如 Spring 官网也提供了创建工程的脚手架,https://start.spring.io Spring Initializr 本质上也是一个 Web 应用,它可以通过 Web 界面、Spring Tool Suite、IntelliJ IDEA 等方式,构建出一个基本的 Spring Boot 项目结构。但是,我们创建的项目结构并不是一个简单的 MVC 结构,而是需要基于 DDD 四层架构进行模块化拆分,并把分布式组件 RPC 结合进行,所以这里我们需要进行框架搭建。
DDD分层架构介绍
DDD(Domain-Driven Design 领域驱动设计)是由Eric Evans最先提出,目的是对软件所涉及到的领域进行建模,以应对系统规模过大时引起的软件复杂性的问题。整个过程大概是这样的,开发团队和领域专家一起通过 通用语言(Ubiquitous Language)去理解和消化领域知识,从领域知识中提取和划分为一个一个的子领域(核心子域,通用子域,支撑子域),并在子领域上建立模型,再重复以上步骤,这样周而复始,构建出一套符合当前领域的模型。

依靠领域驱动设计的设计思想,通过事件风暴建立领域模型,合理划分领域逻辑和物理边界,建立领域对象及服务矩阵和服务架构图,定义符合DDD分层架构思想的代码结构模型,保证业务模型与代码模型的一致性。通过上述设计思想、方法和过程,指导团队按照DDD设计思想完成微服务设计和开发。
- 拒绝泥球小单体(??)、拒绝污染功能与服务、拒绝一加功能排期一个月
- 架构出高可用极易符合互联网高速迭代的应用服务
- 物料化、组装化、可编排的服务,提高人效
好多专业名词,上来就是看不懂的样子。
服务架构调用关系

- 应用层{Application}:专业名词真JB多
- 应用服务位于应用层。用来表述应用和用户行为,负责服务的组合、编排和转发,负责处理业务用例的执行顺序以及结构的拼装。
- 应用层的服务包括服务和邻域事件相关服务。
- 应用服务可对微服务内的领域服务以及微服务外的应用服务进行组合和编排,或者对基础层如文件、缓存等数据直接操作形成应用服务,对外提供粗粒度的服务。
- 领域事件服务包括两类:领域事件的发布和订阅。通过事件总线和消息队列实现异步数据传输,实现微服务之间的解耦。
- 领域层{Domain}:
- 领域服务位于领域层,为完成领域中跨实体或值对象的操作转换而封装的服务,领域服务以与实体和值对象相同的方式参与实施过程。
- 领域服务队同一个实体的一个或多个方法进行组合和封装(类?接口?),或对多个不同实体的操作进行组合或编排,对外暴露成领域服务。领域服务封装了核心的业务逻辑。实体自身的行为在实体类内部实现,向上封装成领域服务暴露。
- 为隐藏领域层的业务逻辑实现,所有领域方法和服务等均须通过领域服务对外暴露。通过领域服务向外暴露??
- 为实现微服务内聚合之间的解耦,原则上禁止跨聚合的领域服务调用和跨聚合的数据相互关联。
- 基础层{infrastructure}:
- 基础服务位于基础层。为各层提供资源服务(如数据库、缓存等),实现各层的解耦,降低外部资源变化对业务逻辑的影响。
- 基础服务主要为仓储服务,通过依赖反转的方式为各层提供基础资源服务,领域服务和应用服务调用仓储服务接口,利用仓储实现持久化数据对象或直接访问基础资源。
- 接口层{interfaces}:
- 接口服务位于用户接口层,用于处理用户发送的Restful请求和解析用户输入的配置文件等,并将信息传递给应用层。
问题:
-
接口层的三个都不太明白;
-
应用层与MQ的联系;MQ是什么?其存在的原因以及作用?MQ的各种功能是什么?
- 这里的应用事件是指什么??
- 为什么应用层会有仓储服务接口的存在??
-
什么是领域层?
- 为什么第二列三个都是“实体/值对象”??各自指代有何不同?
-
基础层DB和ES/文件是完全分开的?
- 我印象ES应该是与DB有联系的?;
;
综上,就是对 DDD 领域驱动设计的一个基本描述,不过也不用过于神秘化DDD,我们可以把DDD四层架构和MVC三层架构架构理解为家里的格局,三居和四居,只不过DDD是在MVC的基础上可以更加明确了房间的布局,可能效果上就像你原来有个三居中没有独立的书房,现在四居了你可以有一个自己的小空间了。
那么,这里还有一点就是DDD结构它是一种充血模型结构,所有的服务实现都以领域为核心,应用层定义接口,领域层实现接口,领域层定义数据仓储,基础层实现数据仓储中关于DAO和Redis的操作,但同时几方又有互相的依赖。那么这样的结构再开发独立领域提供 http 接口时候,并不会有什么问题体现出来。但如果这个时候需要引入 RPC 框架,就会暴露问题了,因为使用 RPC 框架的时候,需要对外提供描述接口信息的 Jar 让外部调用方引入才可以通过反射调用到具体的方法提供者,那么这个时候,RPC 需要暴露出来,而 DDD 的系统结构又比较耦合,怎么进行模块化的分离就成了问题点。所以我们本章节在模块系统结构搭建的时候,也是以解决此项问题为核心进行处理的。
DDD+RPC,模块分离系统搭建
RPC究竟是个啥?
如果按照模块化拆分,那么会需要做一些处理,包括:
- 应用层,应用层,不再给领域层定义接口,而是自行处理对领域层接口的包装。否则领域层既引入了应用层的Jar,应用层也引入了领域层的Jar,就会出现循环依赖的问题。
- 基础层中的数据仓储的定义也需要从领域层剥离,否则也会出现循环依赖的问题。
- RPC 层定义接口描述,包括:入参Req、出参Res、DTO对象,接口信息,这些内容定义出来的Jar给接口层使用,也给外部调用方使用。

那么,这样拆分以后就可以按照模块化的结构进行创建系统结构了,每一层按照各自的职责完成各自的功能,同时又不会破坏DDD中领域充血模型的实现。
知识点
- 学习源码DDD结构分层(见个人补充部分)
- 知晓每个模块分层要完成的职责
- 直到为什么要把RPC层单独拆分出来
个人补充
DDD分层与传统三层的区别
更具DDD领域驱动设计原则,对应的软件架构也需要相应的调整。
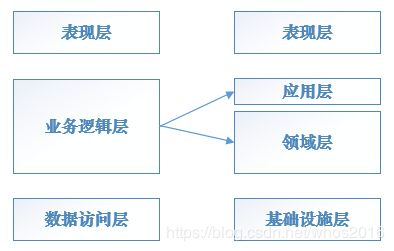
常用的三层架构模型划分为表现层、业务逻辑层、数据访问层等,在DDD分层结构中既有联系又有区别。
主要有以下异同:
- 在架构设计上,在
DDD分层结构中,将传统三层结构的领域层拆解为应用层和领域层。其中Application划分为很薄的一层服务,非核心的逻辑放在此层去实现,核心的业务逻辑表现下沉到领域层去实现,凝练为更加精准的业务规则集合,通过领域对象去阐述说明。
- 在建模方式上,
DDD分层的建模思维方式有别于传统三层,传统三层通常是以数据库为起点进行数据库分析设计,而DDD则需要以业务领域模型为核心建模(即面向对象建模的方式),更能体现对现实世界的抽象。因此在DDD分层凸显领域层的重要作用,领域层为系统的核心,包括所有业务领域模型的抽象表达。- 私以为这样最好,数据库只是存储设备就类似于外存,领域层类似于内存+CPU,需要处理数据并做数据暂存,应该作为核心。表现层类似于显示器,内部封装的操作不需要完全知道。
- 在职责划分上,基础设施层涵盖了2方面内容
- 持久层功能,其中原三层架构的数据访问层下沉到基础设施层的持久化机制实现
- 通用技术支持,一些公共通用技术也放到基础设施层去实现。
DDD分层讲解
四层架构图

应用层所在的位置,让人感觉多加了一层,感觉是复杂化的架构。
在该架构中,上层模块可以调用下层模块,反之不行。即
Interface—>Application|Domain|InfrastructureApplication---->Domain|InfrastructureDomain---->Infrastructure
分层作用
| 分层 | 英文 | 描述 |
|---|---|---|
| 表现层 | User Interface | 用户界面层,或者表现层,负责向用户显示解释用户命令 |
| 应用层 | Application Layer | 定义软件要完成的任务,并且指挥协调领域对象进行不同的操作。该层不包含业务领域知识。 |
| 领域层 | Domain Layer | 或称为模型层,系统的核心,负责表达业务概念,业务状态信息以及业务规则。即包含了该领域(问题域)所有复杂的业务知识抽象和规则定义。该层主要精力要放在领域对象分析上,可以从实体,值对象,聚合(聚合根),邻域服务,领域事件,仓储,工厂等方面入手 |
| 基础设施层 | Infrastructure Layer | 主要有2方面内容,一是为领域模型提供持久化机制,当软件需要持久化能力时候才需要进行规划;一是对其他层提供通用的技术支持能力,如消息通信,通用工具,配置等的实现; |
领域对象
根据战术设计,关注的领域对象主要包括:
| 类型 | 英文 | 描述 |
|---|---|---|
| 值对象 | Value | 无唯一标识的简单对象 |
| 实体 | Entity | 充血的领域模型,有唯一标识 |
| 聚合(聚合根) | Aggravate | 实体的聚合,拥有聚合根,可为某一个实体 |
| 领域服务 | Service | 无法归类到某个具体领域模型的行为 |
| 领域事件 | Event | 不常用 |
| 仓储 | Repository | 持久化相关,与基础设施层关联 |
| 工厂 | Factory | 负责复杂对象创建 |
| 模块 | Module | 子模块引入,可以理解为子域划分 |
DDD编码实践(改进分层)
本文在对上述的传统四层的实践中,(1)根据依赖倒置原则对分层结构进行了改进,通过改变不同层的依赖关系(即将基础设施层倒置)来改进具体实现与抽象之间关系;(2)在基础设施层中增加引用适配层(防腐层)来增强防御策略,用来统一封装外部系统接口的引用。改进的分层结构如下:
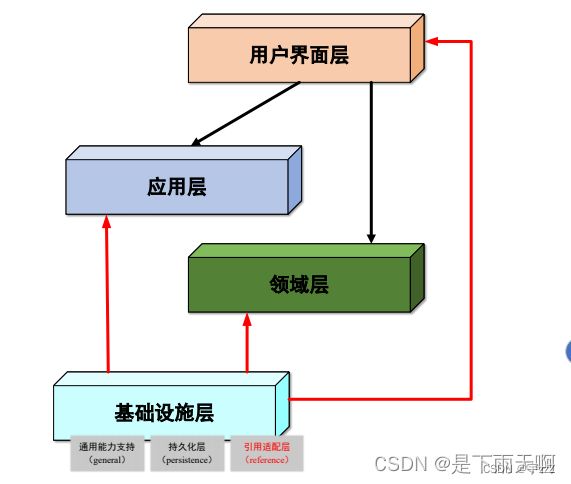
依赖倒置原则(DIP):
- 高层模块不依赖与低层模块,两者都依赖于抽象;
- 抽象不应该依赖于细节,细节依赖抽象
代码结构描述
eg.后端Java代码工程为例,表现层为此代码结构中表现为api层,对外暴露接口的最上层;
├─com.company.microservice
├─com.company.microservice
│ │
│ ├─apis API接口层
│ │ └─controller 控制器,对外提供(Restful)接口
│ │
│ ├─application 应用层
│ │ ├─model 数据传输对象模型及其装配器(含校验)
│ │ │ ├─assembler 装配器,,实现模型转换eg. apiModel<=> domainModel
│ │ │ └─dto 模型定义(含校验规则)
│ │ ├─service 应用服务,非核心服务,跨领域的协作、复杂分页查询等
│ │ ├─task 任务定义,协调领域模型
│ │ ├─listener 事件监听定义
│ │ └─*** others
│ │
│ ├─domain 领域层
│ │ ├─common 模块0-公共代码抽取,限于领域层有效
│ │ ├─module-xxx 模块1-xxx,领域划分的模块,可理解为子域划分
│ │ ├─module-user 模块2-用户子域(领域划分的模块,可理解为子域划分)
│ │ │ ├─action 行为定义
│ │ │ │ ├─UserDomainService.java 领域服务,用户领域服务
│ │ │ │ ├─UserPermissionChecker.java 其他行为,用户权限检查器
│ │ │ │ ├─WhenUserCreatedEventPublisher.java 领域事件,当用户创建完成时的事件
│ │ │ ├─model 领域聚合内模型
│ │ │ │ ├─UserEntity.java 领域实体,有唯一标识的充血模型,如本身的CRUD操作在此处
│ │ │ │ ├─UserDictVObj.java 领域值对象,用户字典kv定义
│ │ │ | ├─UserDPO.java 领域负载对象
│ │ │ ├─repostiory 领域仓储接口
│ │ │ │ ├─UserRepository.java
│ │ │ ├─reference 领域适配接口
│ │ │ │ ├─UserEmailSenderFacade.java
│ │ │ └─factory 领域工厂
│ │
│ ├─infrastructure 基础设施层
│ │ ├─persistence 持久化机制
│ │ │ ├─converter 持久化模型转换器
│ │ │ ├─po 持久化对象定义
│ │ │ └─repository.impl 仓储类,持久化接口&实现,可与ORM映射框架结合
│ │ ├─general 通用技术支持,向其他层输出通用服务
│ │ │ ├─config 配置类
│ │ │ ├─toolkit 工具类
│ │ │ ├─extension 扩展定义
│ │ │ └─common 基础公共模块等
│ │ ├─reference 引用层,包装外部接口用,防止穿插到Domain层腐化领域模型等
│ │ │ ├─dto 传输模型定义
│ │ │ ├─converter 传输模型转换器
│ │ │ └─facade.impl 适配器具体实现,此处的RPC、Http等调用
│ │
│ └─resources
│ ├─statics 静态资源
│ ├─template 系统页面
│ └─application.yml 全局配置文件
其中在上述目录结构中,Domain层中为对module进行划分,实际上默认该层只有一个模块,根据微服务划分可以进行增加模块来规范代码结构。
扩展定义注解和接口声明
领域模型注入仓储类的问题
一些作者思考
项目按上述经典四层架构进行搭建,可以说是DDD结构实践吗?
关于这个问题,笔者想引入一对哲学概念,哲学有言形式与内容,现象与本质等辩证关系(当然与本文可能也没啥太大关系啦);从这两个角度来阐述本人的观点:
- 形式与内容:经典四层架构是一个DDD实现的形式,相当于给我们提供了一个框框来让我们自己去实现;在这个框框里面我们怎么实现是自由发挥的,但也是有约束的,这个约束体现在DDD对每一层的作用的约定,如每个层约定做了什么功能,充当什么角色等。尤其是对Domain层的约定,才是最重要的。那么我们按照哲学辩证的套话来说,形式上满足了DDD架构,但这应该是片面的,具体还要看内容,即具体实现是怎样的。
- 现象与本质:接着上述观点,如果要看实现,就要具体分析一下现象与本质嘞。上面笔者也有提到,DDD除了四层经典架构,还有五层架构(包括其演化的多层架构)、六边形架构等也都是DDD提供的架构模型(形式),那这些都可以理解DDD架构模式的外显形式,那么又有哪些共性呢?可自行查询,本文直接给结论,即它们都有Domain层,Domain层,Domain层(重要的事情说三遍~~,该结论DDD作者译著有写到…),所以不管架构模式怎么演化,Domain是核心不能变。
那么如上分析,我们在回到这个问题,我们是不是可以给出一个这样的答案:
形式上符合DDD架构,具体是不是DDD的架构实践,本质上还要看
- (1)项目是否包括有Domain层;
- (2)Domain层是否满足DDD战术篇的要求(或者可暂时简单理解为充血模型吧)
题外话:Spring与DDD
- Spring框架中,Spring为我们提供了
@Service@Repository等注解,为我们分离行为和行为(注册为Bean)和属性(数据模型),同时通过@Autowired在合适地方进行注入行为,因为行为被注册为Spring容器中的Bean后,减少了频繁创建行为的开销,只有属性的数据模型作为数据的载体来传递数据。提供很大的便捷性。但也阻碍了我们应用DDD编码实践, Spring框架主张分离,DDD思想主张合并,我们在Spring框架中使用DDD则需要在其基础上进行一些权衡取舍,即如何将注册为Bean的行为穿插到原有的贫血模型中来构建充血模型是我们要解决的问题 - 关于这个问题,笔者使用了Spring框架提供的获取容器内已经注册的Bean接口,直接调用接口,在有属性的领域模型中来获取行为;主要还是体现融入领域模型中的部分Service获取仓储接口来实现持久化过程。
参考链接:DDD-经典四层架构应用
为什么把RPC层单独拆分出来
RPC,Remote Procedute Cells,远程函数调用,完成远程函数的映射,并且将数据转化为字节流,使用网络进行传输;
woc?RPC可以实现不同编程语言之间的函数调用??
RPC层对外提供接口描述信息;
听起来RPC层是和前后端分离紧密相关的层;不无关系,但其实是跟为其他项目提供服务有关。将A项目的RPC模块打包之后,通过在B项目中引入pom的方式即可复用A中的RPC服务。
GPT的回答:
在领域驱动设计(Domain-Driven Design,简称DDD)中,将RPC层(Remote Procedure Call layer)单独拆分为一个模块的目的是为了分离不同的关注点,提高系统的可扩展性和可维护性。
以下是一些原因和好处:
- 解耦领域逻辑和通信层:RPC层负责与其他系统或服务进行远程通信,通过将其与领域逻辑分离,可以确保领域模型的纯粹性和独立性。将通信细节从领域模型中分离出来,使得领域模型可以专注于解决业务问题,而不需要关注与外部系统的交互。
- 支持多种通信协议和技术:RPC层的拆分为一个独立的模块,使得可以灵活选择不同的通信协议和技术,比如RESTful API、SOAP、gRPC等。这样可以根据具体需求选择适合的通信方式,而不影响领域模型的实现。
- 提供可插拔性:通过将RPC层拆分为一个独立的模块,可以轻松地替换或添加其他的通信实现,而不需要修改领域模型的代码。这种可插拔性使得系统更加灵活,可以根据需要进行扩展和调整。
- 接口隔离和依赖管理:将RPC层作为一个独立模块,定义清晰的接口和契约,可以隔离不同模块之间的依赖,并且让各个模块之间的通信更加明确和可管理。这种接口隔离有助于降低系统的耦合度,提高系统的可维护性和可测试性。
需要注意的是,将RPC层拆分为一个独立模块并不是必须的,这取决于具体的系统需求和设计决策。有些情况下可能不需要将RPC层单独拆分,而是将其直接集成到领域模型中。设计时需要权衡不同的因素,并根据具体情况做出适当的决策。
项目学习源自小傅哥的知识星球
处于版权考虑,后续章节内容将以仅个人可见的形式发布。
番外:有关Java注解
Java注解基础知识
注解是JDK1.5版本开始引入的一个特性,用于对代码进行说明,可以对包、类、接口、字段、方法参数、局部变量等进行注解。它主要的作用有以下四方面:
· 生成文档,通过代码里标识的元数据生成javadoc文档。
· 编译检查,通过代码里标识的元数据让编译器在编译期间进行检查验证。
· 编译时动态处理,编译时通过代码里标识的元数据动态处理,例如动态生成代码。
· 运行时动态处理,运行时通过代码里标识的元数据动态处理,例如使用反射注入实例。
源代码当中为什么感觉有一些冗余的类?后期会优化吗?