TSM,TRN 神经网络模型解析附代码
TSM是一个保持2DCNN复杂度但是却能达到3DCNN效果的网络结构
对于视频识别的关键就是时间信息,这也是众多分析序列网络模型的研究点。
TSM提出了一种可以基于现存的网络模型(Resnet)加入temporal shift module的方法
例如基于resnet50的改进办法:
首先得到resnet50的网络模型,在每个残差块的第一卷积之前,进行shift操作,
假如入模型输入为[8,3,224,224],八张RGB图像,经过卷积,BN,RELU,maxpoling后进入第一个残差块输入为[8,64,56,56],然后对这个张量进行right shift ,left shift操作,即将后7帧选取八分之一通道,替换掉前七帧,将前7帧选取八分之一替换到后7帧八分之一,达到你中有我,我中有你的效果。然后将shift之后的tensor 送入残差块学习。
以上仅供参考
注意点 :
一次要输入八张图像,即每一次dataloader,要loader进八张图像,即一个batchsize =1 时的输入维度为【1,24,224,224】 然后变成【8,3,224,224】进行处理,当然也可以指定batchsize为任意数目。
shift 操作一定的核心代码:
class TemporalShift(nn.Module):
def __init__(self, net, n_segment=3, n_div=8, inplace=False):
super(TemporalShift, self).__init__()
self.net = net
self.n_segment = n_segment
self.fold_div = n_div
self.inplace = inplace
if inplace:
print('=> Using in-place shift...')
print('=> Using fold div: {}'.format(self.fold_div))
def forward(self, x):
x = self.shift(x, self.n_segment, fold_div=self.fold_div, inplace=self.inplace)
return self.net(x)
@staticmethod
def shift(x, n_segment, fold_div=3, inplace=False):
nt, c, h, w = x.size()
n_batch = nt // n_segment
x = x.view(n_batch, n_segment, c, h, w)
fold = c // fold_div
if inplace:
out = InplaceShift.apply(x, fold)
else:
out = torch.zeros_like(x)
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return out.view(nt, c, h, w)TRN: temporal relation Network
先利用resnet作为提取图片特征的网络,从输出的【8,256】,按顺序索引出几种组合,组合内的特征图相加,然后每种组合在相加。来达到时序建模的思想。
TRN 致力于探索时间维度上的关系,主要提出了两个方面的创新点:
1 设计了新的融合函数来表征不同时间帧的关系,
2 通过时间维度上的多尺度特征融合,来提高视频的鲁棒性,抗快速和慢速动作的干扰
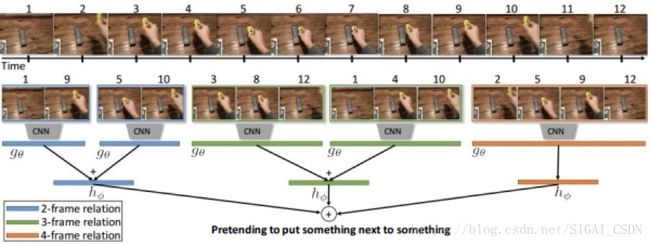
由图可知,对每段区间的视频帧学习特征,找到帧在时间维度上的关系。