20230215小结
1 t-sne 原理:利用两个向量之间的欧式距离转化成条件概率分布,可以把高维度的数据转化为低维度(1000,64)-》(1000,2),原先每个样本有64维度,转化为2维
2 swin-transformer:
主要贡献:1 vit 是把16X16个像素点打包成一个patch,比如图像224X224的,就会有196XC个patch,对patch做MSLP,计算量很大,vit还有一个缺点,就是对多尺度的物体效果不好
比如说:一个街景图中,近处的人比远处的人要大,但是vit的,输出永远不会变,这就有可能出问题
为了解决这个问题,swin-transformer,是要把4X4打包成一个patch,但是这样计算量更大,所以它是在窗口内做自注意力,在每个stage会有一个类似池化的merge,就是把相邻连个patch
合并成一个,再利用1X1卷积,改变通道数,这样每个stage输出的特征图都不一样,对多尺度的比较友好
窗口自注意力分为两步,固定和滑动,窗口大小7X7,总共才64个窗口,计算一次,但是这样窗口之前就被割裂了,为了引入跨窗口连接,应用了循环移位技术
3 Actionclip:
1 输入是[B,3,224,224],使用16X16的卷积核滑窗,变为[B,768,14,14] ->换维度并合并为[B,196,768] 在增加位置编码在cat上classToken->[B,197,768]
2 经过Transformer Layer X 12 最终输出为[B,T,512]
3 在经过prompt模块处理:其实就是先生成一个contex table [77,512](API:torch.nn.Eembeding(77,512)),代表有72个词,每个词512维向量,然后从里面去前四个,总共去Batchsize 个
4 然后原始输入x=x+第三步的编码(感觉),在经过一个transformer,在接一个全连接层去平均,输出预测值,使用交叉熵
4 熵、交叉熵、KL散度
信息量的衡量:大概率事件信息量很小,小概率事件信息量很大
熵:对于不确定事件信息的度量, 一般熵越大系统越不稳定
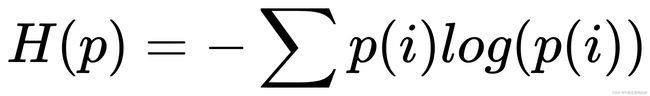
交叉熵:事先不知道真是lable,只知道预测lable ,可以通过给出预测概率的分布来估计真实预测 公式:一般在机器学习中P(i)为0或者1,如果预测出来的概率分布和真实的概率 接近,交叉熵越小

KL散度:来衡量两个分布之间的差异,比如交叉熵-熵 公式:
