保姆级 Keras 实现 Faster R-CNN 二
保姆级 Keras 实现 Faster R-CNN 二
- 一. VOC 数据集
-
- 1. 数据下载与结构
- 2. 修改数据路径与结构
- 3. 读取数据路径函数
- 二. IoU (Intersection over Union)
-
- 1. 如何判断 anchor box 是不是目标?
- 2. 如何用代码计算 IoU?
- 3. 如何生成 anchor box?
- 三. 代码下载
上一篇文章 中我们实现了 RPN 网络模型, 但仅是实现了网络结构, 如果要进行训练的话, 数据要怎么处理呢?
一. VOC 数据集
1. 数据下载与结构
要训练一个有监督模型, 我们需要输入x 和标签 y, 还要定义损失函数. x 和 y 从哪里来? 如果你有时间和精力的话, 你自己标注, 标注方法前面已经讲过了. 如果你想用现成的数据集, 那我们就以 VOC2007 为例, 这个比较小, 下载也快, 打开的网站上也有 VOC2012, 使用方法也和 VOC2007 一样

下载完成解压后, Train/Validation Data (439 MB) 里面有 5 个文件夹
这些文件夹是什么意思呢?
- Annotations: 数据的标注, 里面全是 xml 文件, 文件名称和 JPEGImages 里面图像名称是对应的
- ImageSets: 训练集, 验证集, 测试集 对应的图片名称, 这里我们不用, 用自己的方式划分
- JPEGImages: 原始图像, 名称就是 xml 文件中的 filename, 也是和 xml 文件名一样, 训练和验证的图像都在这个文件夹中
- SegmentationClass: 语义分割的标注, 这里不用管
- SegmentationObject: 实例分割的标注, 这里不用管
我们再来看一下标注的信息

<annotation>
<folder>VOC2007folder>
<filename>000012.jpgfilename>
<source>
<database>The VOC2007 Databasedatabase>
<annotation>PASCAL VOC2007annotation>
<image>flickrimage>
<flickrid>207539885flickrid>
source>
<owner>
<flickrid>KevBowflickrid>
<name>?name>
owner>
<size>
<width>500width>
<height>333height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>carname>
<pose>Rearpose>
<truncated>0truncated>
<difficult>0difficult>
<bndbox>
<xmin>156xmin>
<ymin>97ymin>
<xmax>351xmax>
<ymax>270ymax>
bndbox>
object>
annotation>
上面的标注有用的信息是 filename, object 中的 name 和 bndbox 4 个坐标值 (xmin, ymin, xmax, ymax), 有多个物体的话, 上面的几个有用信息就会重复出现. 标注的文件是 xml 文件, 和 json 大同小异
2. 修改数据路径与结构
如何把这些数据输入网络里进行训练或者预测呢? 需要把图像和标签转换成网络能接受的格式, 一个是训练图像, 一个是标签, 这两个是成对输入的, 这里我新建一个文件夹, 取名为 data_set, 再将 Annotations 中标签文件和 JPEGImages 中的图像复制到 data_set 文件夹中, 方便处理. 我的目录是 data_set, 在工程目录中, 所以 上一篇文章 中的配置参数中的 data_set 用的就是相对路径
3. 读取数据路径函数
开始之前我们先来搞个函数, 方便后面调用. 功能就是把 data_set 中的文件列出来, 划分成训练集, 验证集与测试集, 划分方式按我们的思路来
# 取得图像和标注文件路径
# data_set_path: 数据集所在路径
# split_rate: 这些文件中用于训练, 验证, 测试所占的比例
# 如果为 None, 则不区分, 直接返回全部
# 如果只写一个小数, 如 0.8, 则表示 80% 为训练集, 20% 为验证集, 没有测试集
# 如果是一个 tuple 或 list, 只有一个元素的话, 同上面的一个小数的情况
# shuffle_enable: 是否要打乱顺序
# 返回训练集, 验证集和验证集路径列表
def get_data_set(data_set_path, split_rate = (0.7, 0.2, 0.1), shuffle_enable = True):
data_set = []
files = os.listdir(data_set_path)
for f in files:
ext = osp.splitext(f)[1]
if ext in (".jpg", ".png", ".bmp"):
img_path = osp.join(data_set_path, f)
ann_type = "" # 标注文件类型
ann_path = img_path.replace(ext, ".json")
if osp.exists(ann_path):
ann_type = "json"
else:
ann_path = img_path.replace(ext, ".xml")
if osp.exists(ann_path):
ann_type = "xml"
if "" == ann_type:
continue
data_set.append((img_path, ann_path, ann_type))
if shuffle_enable:
shuffle(data_set)
if None == split_rate:
return data_set
total_num = len(data_set)
if isinstance(split_rate, float) or 1 == len(split_rate):
if isinstance(split_rate, float):
split_rate = [split_rate]
train_pos = int(total_num * split_rate[0])
train_set = data_set[: train_pos]
valid_set = data_set[train_pos: ]
return train_set, valid_set
elif isinstance(split_rate, tuple) or isinstance(split_rate, list):
list_len = len(split_rate)
assert(list_len > 1)
train_pos = int(total_num * split_rate[0])
valid_pos = int(total_num * (split_rate[0] + split_rate[1]))
train_set = data_set[0: train_pos]
valid_set = data_set[train_pos: valid_pos]
test_set = data_set[valid_pos: ]
return train_set, valid_set, test_set
get_data_set 语法不复杂, 就没有过多的注释. 函数的作用就是把每个图像和标注文件路径变成一个 tuple, 放到一个 list 中, 顺便划分训练集, 验证集和测试集. 标签的文件类型可以是 xml 或者 json, 调用方式如下
# 取得目录
# DATA_PATH 在配置参数中
train_set, valid_set, test_set = get_data_set(DATA_PATH, split_rate = (0.8, 0.1, 0.1))
print("Total number:", len(train_set) + len(valid_set) + len(test_set),
" Train number:", len(train_set),
" Valid number:", len(valid_set),
" Test number:", len(test_set))
# 输出第一个元素
print("First element:", train_set[0])
输出如下
Total number: 5011 Train number: 4008 Valid number: 501 Test number: 502
First element: ('data_set\\005773.jpg', 'data_set\\005773.xml', 'xml')
二. IoU (Intersection over Union)
RPN 的作用是自动选出一些可能是目标的区域, 是一个有监督型模型, 所以我们要有数据和标签, 输入数据简单, 就是图像. 那标签是什么? 标签就当然是标注的数据了, 只是你现在困惑的是怎么把标签和图像对应起来. 因为一个图像里面可能会有多个目标, 而且有分类的标签和回归的标签(暂时不讲, 因为我们的重点现在是分类). 作为入门的一些教程都只有一个标签, 多个标签一下子就让你找不着北
1. 如何判断 anchor box 是不是目标?
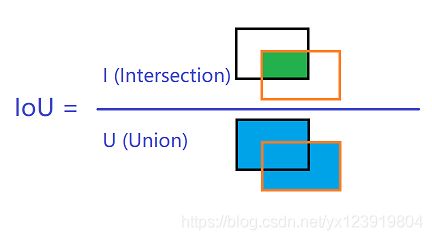
这里就要用到 IoU 的概念了. 还记得在特征图上的一个点对应 k 个 anchor 吗? 这些 anchor 会对应原图上的一个矩形: anchor box, 把 anchor box 和 ground truth 进行比较, 再用一些指标去判断是不是目标. 不用猜你都知道这个指示就是 IoU. 定义如下, 就是绿色面积 / 蓝色面积
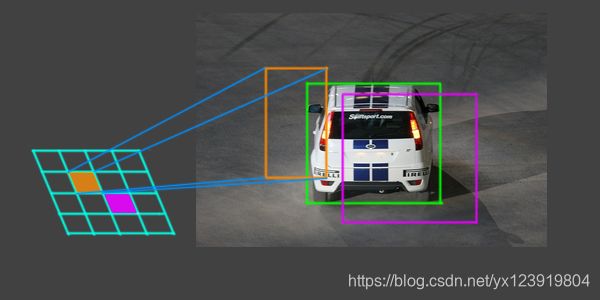
在上图中, 特征图上的一个点的 anchor 映射回原图有一个矩形位置, 如橙色和紫色两个矩形, 绿色是标注的 ground truth. 橙色的矩形和绿色的矩形重叠部分比较小, 所以认为这个 anchor 是背景. 而紫色矩形和绿色矩形重叠分部较多, 可以认为是目标. 那重叠多少来区分呢? 有两个规则
- 与任意的 ground truth IoU ≥ 0.7 是目标, IoU ≤ 0.3 是背景, 0.3 < IoU < 0.7 这部分不用管, 不参加训练
- 如果其中一个 ground truth 没有任何一个 anchor box 与之 IoU ≥ 0.7, 那与之 IoU 最大的那个 anchor box 也算目标, 也就是正样本, 这一规则防止第一条中一些 ground truth 没有正样本可用, 比如 ground truth 尺寸为 64×64, 我们使用的 anchor box 最小是 128×128, 所以只使用第一条将不会有正样本生成
2. 如何用代码计算 IoU?
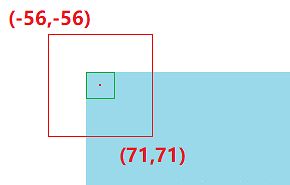
你要知道 Feature Map 上的点如何 映射 回原图上, 在 VGG16 中, 卷积层有做 Padding, 所以不改变大小, 改变大小的是 Pooling, 一共使用了 4 次, 因为最后一个 Pooling 没有使用. 所以图像行数和列数都变为原来的 1 / 16. 又因为特征图上的点是 anchor box 的中心坐标, 映射回原图就指向一个原图的 感受野. 这个感受野有多大呢? 16×16. 所以特征图上的 (0, 0) 就映射到原图的 (0, 0, 15, 15) 这个区域. 现在我们分别把 k 个 anchor box 依次套上去, anchor box 中心就是感受野的中心. 靠边的 anchor box 会有一个问题, 当坐标 (0, 0) 映射到原图 (0, 0, 15, 15) 区域时, anchor box 坐标就会出现负数. 比如 128×128 时坐标就是 (-56, -56, 71, 71), 那这样的 anchor box 是超过了图像范围的, 有两个处理方式, 一是直接舍去, 二是截断成 (0, 0, 71, 71). 论文中讲的是训练阶段舍去不用, 预测时才截断
好了, 又差不多该上代码了
# 计算 IoU
# anchor_box 坐标格式为 (x1, y1, x2, y2)
# 交集
# a1: anchor_box1 a2: anchor_box2
def intersection(a1, a2):
x = max(a1[0], a2[0])
y = max(a1[1], a2[1])
w = min(a1[2], a2[2]) - x
h = min(a1[3], a2[3]) - y
if w < 0 or h < 0:
return 0
return w * h
# 并集 a1: anchor_box1 a2: anchor_box2
def union(a1, a2):
area_1 = (a1[2] - a1[0]) * (a1[3] - a1[1])
area_2 = (a2[2] - a2[0]) * (a2[3] - a2[1])
area_union = area_1 + area_2 - intersection(a1, a2)
return area_union
# IoU
def get_iou(a1, a2):
# 防止 left < right 或者 top < bottom
if a1[2] < a1[0]:
a1[2], a1[0] = a1[0], a1[2]
if a1[3] < a1[1]:
a1[3], a1[1] = a1[1], a1[3]
if a2[2] < a2[0]:
a2[2], a2[0] = a2[0], a2[2]
if a2[3] < a2[1]:
a2[3], a2[1] = a2[1], a2[3]
area_i = float(intersection(a1, a2))
area_u = float(union(a1, a2))
if area_u <= 0:
return 0
return area_i / area_u
随便测试一下
# 测试 IoU
a = (8, 8, 32, 64)
b = (3, 3, 32, 65)
print("iou(a, b) =", get_iou(a, b))
iou(a, b) = 0.7474972187166311
3. 如何生成 anchor box?
这是 Faster R-CNN 难点之一, Feature Map 假设是 m×n, 那就会产生 m×n×k 个 anchor box, 所以 anchor box 生成函数需要的参数就有 Feature Map 的尺寸, 还有原图到 Feature Map 缩小的倍数, 当然还有 anchor box 的尺寸和长宽比例. 分两步走, 第一步先生成 k 个基础的 anchor box
# 生成基础的 k 个 anchor box
def create_base_anchors(size = ANCHOR_SIZE, ratios = ANCHOR_RATIO):
anchors = []
for r in ratios:
# 各种比例下的边长
side_1 = [round((x * x * r) ** 0.5) for x in size]
side_2 = [round(s / r) for s in side_1]
# print(side_1, side_2)
# 组合各种边长
for i in range(len(size)):
anchors.append((-side_1[i] // 2, -side_2[i] // 2, side_1[i] // 2, side_2[i] // 2))
return anchors
打印出来看一下
# 测试基础 anchor box
base_anchors = create_base_anchors()
for a in base_anchors:
print(a, " w =", a[2] - a[0], "h =", a[3] - a[1])
打印结果如下, 正好满足各种比例和尺寸
(-23, -45, 22, 45) w = 45 h = 90
(-46, -91, 45, 91) w = 91 h = 182
(-91, -181, 90, 181) w = 181 h = 362
(-32, -32, 32, 32) w = 64 h = 64
(-64, -64, 64, 64) w = 128 h = 128
(-128, -128, 128, 128) w = 256 h = 256
(-46, -23, 45, 23) w = 91 h = 46
(-91, -45, 90, 45) w = 181 h = 90
(-181, -91, 181, 90) w = 362 h = 181
那这 k 种组合的 anchor box 怎么用呢, 我们还要把这些 box 套到原图上去, 为每一个 anchor 位置生成对应的 k 个 anchor box, 只需要将上面的基础 anchor box 的坐标加上感受野中心坐标就可以了
不过还差一个函数, 用于缩放图像, 因为训练集中的图像大小不一, 所以要将其最短边都统一到相同的尺寸, 论文中是 600. 这样比较能符合各种 anchor box 的尺度, 而我设置的配置参中这个参数是 300, 所以与之配套的 anchor box 的尺寸分别 64, 128, 256
# 图像缩放函数
# 返回缩放后的图像和缩放比例
def new_size_image(image, short_size = SHORT_SIZE):
img_shape = list(image.shape)
scale = 1.0
if img_shape[0] < img_shape[1]:
scale = short_size / img_shape[0]
img_shape[0] = short_size
img_shape[1] = round(img_shape[1] * scale)
else:
scale = short_size / img_shape[1]
img_shape[1] = short_size
img_shape[0] = round(img_shape[0] * scale)
new_image = cv.resize(image, (img_shape[1], img_shape[0]), interpolation = cv.INTER_LINEAR)
return new_image, scale
现在就可以在原图上生成 anchor box 了
# 在原图上生成训练的 anchor box
# feature_size: 特征图尺寸
# anchors: k 个基础 anchor box 坐标
# stride: 图像到特征图缩小倍数
def create_train_anchors(feature_size, base_anchors, stride = FEATURE_STRIDE):
anchors = []
for r in range(feature_size[0]): # 行
for c in range(feature_size[1]): # 列
for a in base_anchors:
anchors.append([c * stride + stride // 2 + a[0],
r * stride + stride // 2 + a[1],
c * stride + stride // 2 + a[2],
r * stride + stride // 2 + a[3]])
return anchors
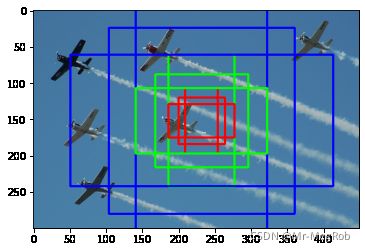
接下来测试函数是否正确, 我只选了一个中心点来画, 要不是整个图都画满了. 注意 idx 是随机显示的序号, 后面的函数还会用到
# 测试 create_train_anchors 并画到图像上
idx = random.randint(0, len(train_set)) # 随机显示序号, 这个序号后面还会用到
print("test image index:", idx)
print("test image info:", train_set[idx])
image = cv.imread(train_set[idx][0]) # train_path 由 get_data_set 函数得来的
image, scale = new_size_image(image, SHORT_SIZE) # 缩放到统一尺寸
feature_size = (image.shape[0] // FEATURE_STRIDE, image.shape[1] // FEATURE_STRIDE)
print("image_size:", image.shape, "feature_size:", feature_size)
# 取得每一个 anchor box
anchors = create_train_anchors(feature_size, base_anchors, FEATURE_STRIDE)
print("anchor num:", len(anchors))
# 选一个靠中心点的位置画 k 个 anchor box
center = ((feature_size[0] // 2) * feature_size[1] + feature_size[1] // 2) * len(base_anchors)
# 画框颜色
colors = ((0, 0, 255), (0, 255, 0), (255, 0, 0))
img_copy = image.copy()
for i, a in enumerate(anchors[center: center + len(base_anchors)]):
cv.rectangle(img_copy, (a[0], a[1]), (a[2], a[3]), colors[i % 3], 2)
plt.figure("anchor_box", figsize = (8, 4))
plt.imshow(img_copy[..., : : -1]) # 这里的通道要反过来显示才正常
plt.show()
test image index: 1024
test image info: ('data_set\\007152.jpg', 'data_set\\007152.xml', 'xml')
image_size: (300, 449, 3) feature_size: (18, 28)
anchor num: 4536
三. 代码下载
示例代码可下载 Jupyter Notebook 示例代码
上一篇: 保姆级 Keras 实现 Faster R-CNN 一
下一篇: 保姆级 Keras 实现 Faster R-CNN 三