利用pyspark实现spark编程之数据去重及筛选
利用pyspark实现spark编程之数据去重
数据源文件

#zuoye1
# 初始化SparkContext
from pyspark import SparkContext
sc = SparkContext('local', 'remdup')
# 加载两个文件A和B
lines1 = sc.textFile("/usr/local/hadoop/A.txt")
lines2 = sc.textFile("/usr/local/hadoop/B.txt")
# 合并两个文件的内容
lines = lines1.union(lines2)
# 去重操作
distinct_lines = lines.distinct()
# 排序操作
res = distinct_lines.sortBy(lambda x: x)
# 将结果写入result文件中,repartition(1)的作用是让结果合并到一个文件中,不加的话会结果写入到两个文件
res.repartition(1).saveAsTextFile("/usr/local/hadoop/file.txt")
2 在Spark中编程,筛选出消费水平在900以上的顾客信息
首先将txt文件转为DATAFrame格式,然后再利用相关语法输出消费水平900以上的顾客信息
第一个输出为转换为dataframe形式后的文本
第二个输出为消费水平大于900的顾客信息
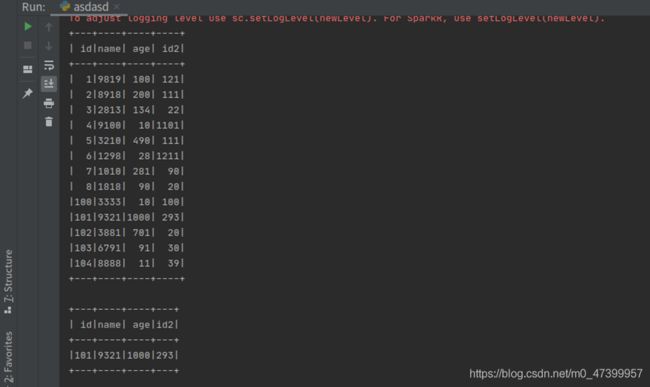
#zuoye2
from pyspark.sql import SparkSession, Row
spark = SparkSession.builder.appName('employee').getOrCreate()
sc = spark.sparkContext
lines = sc.textFile('/usr/local/hadoop/1.txt')
result1 = lines.filter(lambda line: (len(line.strip()) > 0))
result2 = result1.map(lambda x: x.split(','))
# 将RDD转换成DataFrame
item = result2.map(lambda x: Row(id=x[0], name=x[1], age=x[2],id2=x[3]))
df = spark.createDataFrame(item)
df.show()
df.filter(df.age>900).show()
3 在Spark中编程,对口袋妖怪数据进行分析
1). 统计输出各不同种类的妖怪数量(只考虑“种类1”属性)
2). 统计输出各不同种类的妖怪数量(同时考虑“种类1”和“种类2”属性)
3). 统计输出各不同种类中,五维属性总和大于370的妖怪的数量(同时考虑“种类1”和“种类2”属性)
#zuoye3
from pyspark.sql import SparkSession, Row
spark = SparkSession.builder.appName('employee').getOrCreate()
sc = spark.sparkContext
lines = sc.textFile('/usr/local/hadoop/pokeman.txt')
result1 = lines.filter(lambda line: (len(line.strip()) > 0))
result2 = result1.map(lambda x: x.split(' '))
# 将RDD转换成DataFrame
item = result2.map(lambda x: Row(id=x[0], name=x[1], kind1=x[2],kind2=x[3],ps=x[4],ag=x[5],dsf=x[6],mag=x[7],mdf=x[8],speed=x[9],alg=x[10],leg=x[11]))
df = spark.createDataFrame(item)
df.groupby('kind1').count().show(200)#1
df.groupby('kind1','kind2').count().show(200)#2
bf=df.filter((df.ag+df.dsf+df.mag+df.mdf+df.speed)>370)
bf.groupby('kind1','kind2').count().show(200)#3