R语言常用数学函数
目录
1.+ - * / ^
2.%/%和%%
3.ceiling,floor,round
4.signif,trunc,zapsamll
5.max,min,mean,pmax,pmin
6.range和sum
7.prod
8.cumsum,cumprod,cummax,cummin
9.sort
10. approx
11.approx fun
12.diff
13.sign
14.var和sd
15.median
16.IQR
17.ave
18.fivenum
19.mad
20.quantile
21.stem
22.一维优化与求根
23.常用数学函数
24.高级数学函数
1.+ - * / ^
1.5 + 2.3 - 0.6 + 2.1*1.2 - 1.5/0.5 + 2^3
## [1] 10.72
#可以用圆括号改变优先级
1.5 + 2.3 - (0.6 + 2.1)*1.2 - 1.5/0.5 + 2^3
## [1] 5.562.%/%和%%
5 %/% 3
## [1] 1
5 %% 3
## [1] 2
5.1 %/% 2.5
## [1] 2
5.1 %% 2.5
## [1] 0.13.ceiling,floor,round
#"ceiling"函数将输入的数字向上取整,返回大于或等于输入值的最小整数。
ceiling(3.14) # 输出 4
ceiling(-2.5) # 输出 -2
#"floor"函数将输入的数字向下取整,返回小于或等于输入值的最大整数。
floor(3.14) # 输出 3
floor(-2.5) # 输出 -3
#"round"函数将输入的数字四舍五入为最接近的整数。
round(3.14) # 输出 3
round(-2.5) # 输出 -2
#round第二个参数,指定要保留的位数
round(3.14159, 2)将返回保留两位小数的结果:3.144.signif,trunc,zapsamll
#signif函数用于保留指定有效数字位数
#它将输入的数字四舍五入到指定位数,并返回结果
signif(3.14159, 3) # 输出 3.14
signif(1234.5678, 2) # 输出 1200
#trunc函数截断(向零取整)输入的数字,即将小数部分去掉
trunc(3.14) # 输出 3
trunc(-2.5) # 输出 -2
#zapsmall函数用于移除非常接近零的小数误差
#它将输入的数字中非常小的值替换为零
zapsmall(1e-10) # 输出 0
zapsmall(0.000000001) # 输出 0
5.max,min,mean,pmax,pmin
#max函数用于计算一组数中的最大值
#它接受多个参数或一个向量作为输入,并返回其中的最大值。
max(2, 5, 1) # 输出 5
max(c(4, 6, 3)) # 输出 6
#min函数用于计算一组数中的最小值
#它接受多个参数或一个向量作为输入,并返回其中的最小值。
min(2, 5, 1) # 输出 1
min(c(4, 6, 3)) # 输出 3
# 计算向量的平均值
x <- c(1, 2, 3, 4, 5)
avg <- mean(x)
print(avg)
#输出 [1] 3
#pmax函数用于逐个比较两个或多个向量中的相应元素
#并返回对应位置上的最大值向量
pmax(c(1, 3, 5), c(2, 4, 6)) # 输出 2 4 6
pmax(c(1, 3, 5), c(2, 4, 6), c(0, 8, 7)) # 输出 2 8 7
#pmin函数用于逐个比较两个或多个向量中的相应元素
#并返回对应位置上的最小值向量
pmin(c(1, 3, 5), c(2, 4, 6)) # 输出 1 3 5
pmin(c(1, 3, 5), c(2, 4, 6), c(0, 8, 7)) # 输出 0 3 5
6.range和sum
#返回一个包含最小值和最大值的长度为2的向量
range(c(2, 5, 1)) # 输出 1 5
range(1:10) # 输出 1 10
#sum函数用于计算给定向量或数值序列的总和
#它接受一个向量作为输入,并返回所有元素的累加和
sum(c(2, 5, 1)) # 输出 8
sum(1:10) # 输出 55
7.prod
#prod是用于计算一组数的乘积的函数
prod(c(2, 3, 4)) # 输出 24,即 2 * 3 * 4
#如果向量中存在0,则结果将始终为0
prod(c(2, 0, 4)) # 输出 0,因为存在0
#同样,如果向量中有任何非数值(例如字符或缺失值)
则结果将为NA(不可用)
prod(c(2, "a", 4)) # 输出 NA,因为存在非数值元素
8.cumsum,cumprod,cummax,cummin
#cumsum函数用于计算给定向量或数值序列中元素的累积和
cumsum(c(2, 3, 4))
# 输出 2 5 9,即 2, 2+3, 2+3+4
#cumprod函数用于计算给定向量或数值序列中元素的累积乘积
cumprod(c(2, 3, 4))
# 输出 2 6 24,即 2, 2*3, 2*3*4
#cummax函数用于计算给定向量或数值序列中元素的累积最大值
cummax(c(2, 3, 4, 1, 5))
# 输出 2 3 4 4 5,即 2, max(2,3), max(2,3,4), max(2,3,4,1), max(2,3,4,5)
#cummin函数用于计算给定向量或数值序列中元素的累积最小值
cummin(c(2, 3, 4, 1, 5))
# 输出 2 2 2 1 1,即 2, min(2,3), min(2,3,4), min(2,3,4,1),min(2,3,4,1,5)
9.sort
(1)对向量排序
sort(c(3, 1, 4, 2)) # 输出 1 2 3 4
(2) 降序排序
sort(c(3, 1, 4, 2), decreasing = TRUE) # 输出 4 3 2 1
(3) 对数据框按照某列进行排序
df <- data.frame(x = c(3, 1, 4, 2), y = c("A", "B", "C", "D"))
sorted_df$x # 获取排序后的 x 列
sorted_df$y # 获取排序后的 y 列
sorted_df[1, ] # 获取排序后的第一行数据
(4) 降序排序
sorted_df <- df[order(df$x, decreasing = TRUE), ] # 按 x 列降序排序
10. approx
#approx函数用于执行线性插值或平滑插值
approx(x, y = NULL, xout, method = "linear", rule = 2, f = 0, ties = mean)
常用参数
x:输入变量的向量。y:输出变量的向量。当进行插值时,需要提供此参数。xout:用于进行估计或插值的输出变量的取值点。这是一个可选的参数。method:指定插值方法,默认为"linear"(线性插值)。还可以选择"constant"(常数插值)或"spline"(样条插值)等。rule:在估计或插值点不在输入变量范围内时的处理规则。它控制如何对缺失值或超出范围的值进行处理。默认为2,表示生成具有最小相对误差的结果。f:自定义函数,用于在估计或插值点上执行特定的计算。ties:用于处理在估计或插值点存在多个匹配的情况下如何处理。
"ordered":根据输入变量x的顺序,按照与估计或插值点最接近的方式处理匹配值。默认情况下,ties参数设置为"mean"。"mean":将匹配值的平均值作为结果。如果有多个匹配值,将它们的平均值用于计算结果。"min":选择匹配值中的最小值作为结果。"max":选择匹配值中的最大值作为结果。
# 创建输入数据
x <- c(1, 2, 4, 5) # 输入变量 x
y <- c(3, 6, 2, 8) # 输出变量 y
# 进行线性插值
interp <- approx(x, y, xout = seq(min(x), max(x), by = 0.1))
# 输出结果
print(interp)

11.approx fun
# 自定义函数
my_fun <- function(x, y) {
return(x^2 + y)
}
# 创建输入数据
x <- c(1, 2, 4, 5)
y <- c(3, 6, 2, 8)
# 使用自定义函数进行插值
interp <- approx(x, y, xout = seq(min(x), max(x), by = 0.1), f = my_fun)
# 输出结果
print(interp)

12.diff
#diff函数用于计算向量或时间序列的差分
#对于长度为 n 的向量,diff函数将返回一个长度为 n-1 的向量
#其中第 i 个元素是原始向量中第 (i+1) 个元素减去第 i 个元素的结果。
vec <- c(2, 6, 5, 8, 3)
diff_vec <- diff(vec)
print(diff_vec)
#输出 [1] 4 -1 3 -5
13.sign
sign函数用于返回给定数值的符号
- 如果输入值大于0,则返回1。
- 如果输入值等于0,则返回0。
- 如果输入值小于0,则返回-1。
num <- -5
sign_num <- sign(num)
print(sign_num)
#输出 [1] -1
#因为-5是一个负数
14.var和sd
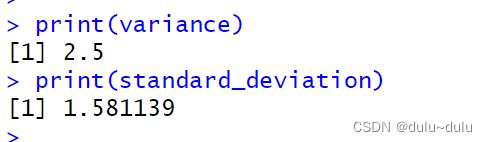
# 计算向量的方差和标准差
x <- c(1, 2, 3, 4, 5)
variance <- var(x)
standard_deviation <- sd(x)
print(variance)
print(standard_deviation)
15.median
# 计算向量的中位数
x <- c(1, 2, 3, 4, 5)
median_value <- median(x)
print(median_value)
#输出 [1] 3
16.IQR
# 计算向量的四分位距
x <- c(1, 2, 3, 4, 5)
iqr_value <- IQR(x)
print(iqr_value)
#输出 [1] 217.ave
用于根据某个变量对向量或数据框进行分组,并对每个组应用函数
# 创建一个数据框
df <- data.frame(
name = c("Alice", "Bob", "Alice", "Charlie", "Charlie", "Bob"),
score = c(85, 90, 92, 78, 80, 88)
)
# 对数据框中的 score 列按 name 分组,计算每个组的平均值
average_scores <- ave(df$score, df$name, FUN = mean)
print(average_scores)

18.fivenum
# 计算向量的五数概括统计量
#包括最小值、下四分位数、中位数、上四分位数和最大值
x <- c(1, 2, 3, 4, 5)
fivenum_values <- fivenum(x)
print(fivenum_values)

19.mad
# 计算向量的绝对中位差
x <- c(1, 2, 3, 4, 5)
mad_value <- mad(x)
print(mad_value)

20.quantile
# 计算向量的分位数
x <- c(1, 2, 3, 4, 5)
# 计算四分位数
quartiles <- quantile(x, probs = c(0.25, 0.5, 0.75))
print(quartiles)

21.stem
# 创建茎叶图
x <- c(12, 23, 34, 45, 56, 67, 78, 89, 90)
stem(x)

22.一维优化与求根
(1)optimize
optimize()函数用于在给定区间内寻找一个函数的最小值或最大值。
#optimize(f, interval, maximum = FALSE, tol = .Machine$double.eps^0.25)
#f 是要最小化或最大化的函数;
#interval 是定义函数的有效区间。
#maximum:一个逻辑值,用于指定是寻找最小值还是最大值。默认为 FALSE,表示寻找最小值。
#tol:一个数值,表示收敛容差(convergence tolerance)。默认值为 .Machine$double.eps^0.25,使用机器精度的推荐容差。
f <- function(x) x^2 - 4 * x + 3
result <- optimize(f, c(0, 5))
print(result$minimum) # 输出函数的最小值
#输出 [1] 2
(2)uniroot
uniroot()函数用于在给定区间内寻找一个函数的根
#uniroot(f, interval)
#f 是要寻找根的函数;interval 是定义函数的有效区间
f <- function(x) x^3 - 2 * x - 5
result <- uniroot(f, c(1, 3))
print(result$root) # 输出函数的根
#输出 [1] 2.094526(3)polyroot
polyroot()函数用于找到多项式函数的所有根
# polyroot(coeffs)
#coeffs 是一个包含多项式系数的向量
coeffs <- c(1, -5, 4)
roots <- polyroot(coeffs)
print(roots) # 输出多项式函数的所有根
#输出 [1] 4+0i 1+0i
23.常用数学函数
#abs:获取数值的绝对值
abs(-5) # 输出 5
abs(3.14) # 输出 3.14
#sqrt:计算数值的平方根
sqrt(9) # 输出 3
sqrt(2) # 输出 1.414213
#sin:正弦
sin(x)
#cos:余弦
cos(x)
#tan:正切
tan(x)
#asin:反正弦
asin(x)
#acos:反余弦
acos(x)
#atan:反正切
atan(x)
#atan2:给定y和x坐标的反正切
atan2(y,x)
#sinh:双曲正弦值
sinh(x)
#cosh:双曲余弦值
cosh(x)
#tanh:双曲正弦值
tanh(x)
#ashih:反双曲正弦值
ashih(x)
#acosh:反双曲余弦值
acosh(x)
#atanh:反双曲正切值
atanh(x)
24.高级数学函数
#beta函数:计算两个参数的Beta函数值
beta(x,y)
#lbeta函数:计算两个参数的Beta函数的自然对数
lbeta(x,y)
#gamma函数:计算给定参数的伽玛函数值
gamma(x)
#lgamma函数:计算给定参数的伽玛函数的自然对数
lgamma(x)
#digamma函数:计算给定参数的Ψ函数值(第一类对数勒让德函数)
digamma(x)
#digamma函数:计算给定参数的Ψ函数值(第一类对数勒让德函数)
trigamma(x)
#tetragamma函数:计算给定参数的Ψ函数的二阶导数值(第三类对数勒让德函数)
tetragamma(x)
#pentagamma函数:计算给定参数的Ψ函数的三阶导数值(第四类对数勒让德函数)
pentagamma(x)
#choose函数:计算组合数
choose(n,k)
#lchoose函数:计算组合数的自然对数
lchoose(n,k)
#fft函数:执行快速傅里叶变换(FFT),将信号从时域转换为频域。
fft(x)
#mvfft函数:执行多维傅里叶变换。
mvfft(x)
#convolve函数:计算两个向量的卷积(线性卷积)。
convolve(x, y)
#polyroot函数:找到多项式的根。
polyroot(p)
#polyroot函数:找到多项式的根。
poly(x,degree)
#spline函数:执行样条插值,生成平滑插值曲线。
spline(x, y, xout)
#splinefun函数:生成根据样条插值生成的函数。
splinefun(x,y)
参数 x:输入值。参数 nu:阶数。
#besselI函数:计算修正的贝塞尔函数I。
besselI(x, nu)
#besselK函数:计算修正的贝塞尔函数K。
besselK(x,nu)
#besselJ函数:计算贝塞尔函数J。
besselJ(x, nu)
#besselY函数:计算贝塞尔函数Y。
besselY(x, nu)
#gammaCody函数:计算递归修正伽玛函数。
gammaCody(x)
#deriv函数:对简单表达式进行符号微分或算法微分。
deriv(expr, name)
如有新学习的知识会补充,如有错误或遗漏请大佬们不吝赐教!!