系统数据导出优化
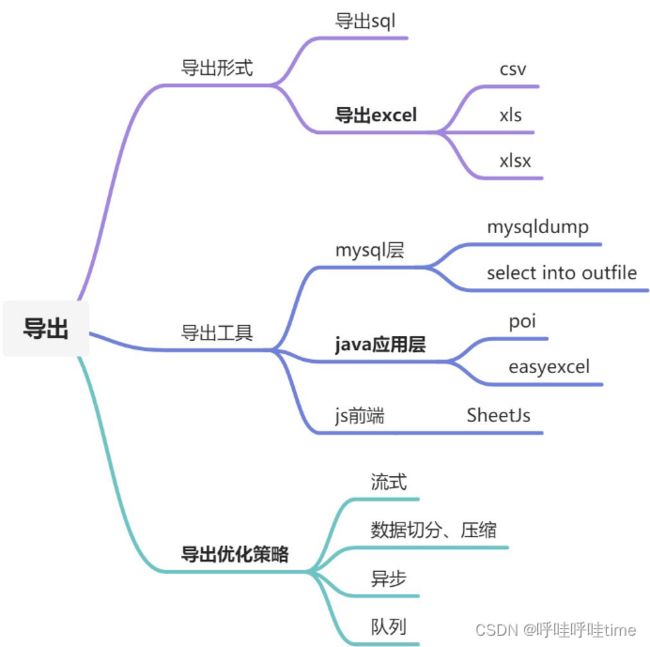
概述
线上系统出现文件无法成功导出,或者导出导致虚拟机崩溃等情况。为保证系统稳定和功能正常,需对导出功能做一轮整体优化,以及整理一些可进一步优化的点。
初始导出流程如下
原因分析
1、业务数据处理异常
出现比较少,测试的正常操作难以提前发现,系统运行过程中,产生了特定数据可能就会出现的bug
2、数据量大导致内存溢出
目前系统最大数据量导出为单表3百万行,60列,全部加载到内存中极易导致OOM
3、并发操作导致内存溢出
与2中类似,实质还是数据量大的问题。由于是并行处理,因此同时存在CPU瓶颈问题。
解决方案
针对上述问题,在java应用层做了一些优化措施。对于业务处理异常,跟踪log能够比较快速的定位问题和解决。本质还是数据的输入规范问题,由于产生的数据不符合预期而导致的bug,可适当增加数据输入校验,或数据库表字段约束。在此不详谈。主要讨论大数据量和并发导致的问题解决。
直接的原因是虚拟机堆无剩余空间分配给程序即将加载的全部数据
具体措施:
方案1:物理机内存足够的情况下,可适当调大最大虚拟机堆空间,如增加启动参数-Xmx100G
优点:操作简单直接,在最大数据有一定预期的时候能够应付大部分情况。
缺点:对物理机配置要求较高,超过虚拟堆最大值的数据量依然无法处理
方案2:数据化整为零,分批处理
优点:无论多大数量级数据都可以处理
缺点:需要对整个导出流程的步骤进行调整适配,存在一定复杂度
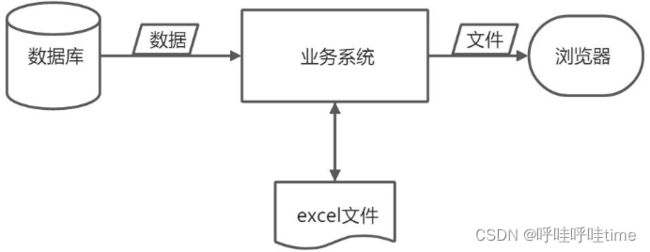
综合考虑,选择方案2,因此以数据流向来对整个流程进行梳理优化
流程环节改进
数据库到应用程序
有两种策略:
- 分页,主要采用limit方式
- 流式处理
考虑到分页在数据量较大时,后续分页查询较慢,舍弃,选择流式处理
如下使用的是应用层jdbcTemplate的流式处理方案,对结果集的逐行处理,避免内存溢出
public void query(PreparedStatementCreator psc, RowCallbackHandler rch) throws DataAccessException {
query(psc, new RowCallbackHandlerResultSetExtractor(rch));
}
mybatis同样可以实现,但由于目前使用的系统使用mybatis版本较低不支持,而升级代价较大,暂未修改
应用程序到文件
文件类型
- xls是Microsoft Excel2007前excel的文件存储格式,实现原理是基于微软的ole db是微软com组件的一种实现,本质上也是一个微型数据库,由于微软的东西很多不开源,另外也已经被淘汰,了解它的细节意义不大,底层的编程都是基于微软的com组件去开发的。
- xlsx是Microsoft Excel2007后excel的文件存储格式,实现是基于openXml和zip技术。这种存储简单,安全传输方便,同时处理数据也变的简单。
- csv 我们可以理解为纯文本文件,可以被excel打开。他的格式非常简单,解析起来和解析文本文件一样。
一般业务数据导出选择xlsx
excel的sheet存在一个行数上限值,超过该值的数据需要分sheet甚至分不同excel文件导出
.xls格式excel建议:每个sheet写入60000条数据,每个excel写入300000条数据,即5个sheet
private void updateContext(EasyExportContext context) {
int fileIdx = context.rowIdx/MAX_PER_FILE;
int sheetIdx = (context.rowIdx%MAX_PER_FILE)/MAX_PER_SHEET;
if (fileIdx > context.fileIdx) {
context.excelWriter.finish();
String fileName = context.fileNameOrg+"_"+(fileIdx+1)+".xls";
context.fileList.add(fileName);
context.excelWriter = EasyExcel.write(WebConstant.THREAD_TOB_EXPORT_URL + fileName, context.clazz).build();
context.writeSheet = EasyExcel.writerSheet(0, "" + 0).build();
context.fileIdx = fileIdx;
context.sheetIdx = 0;
} else if (sheetIdx > context.sheetIdx) {
context.writeSheet = EasyExcel.writerSheet(sheetIdx, "" + sheetIdx).build();
context.sheetIdx = sheetIdx;
}
}
poi
poi是java操作excel的一个主要工具库,并在版本更新中做了许多优化,如xlsx底层使用xml存储,占用内存会比较大,在3.8版本之后,提供了SXSSFWorkbook来优化写性能。其原理是可以定义一个window size(默认100),生成Excel期间只在内存维持window size那么多的行数Row,超时window size时会把之前行Row写到一个临时文件并且remove释放掉,这样就可以达到释放内存的效果。 SXSSFSheet在创建Row时会判断并刷盘、释放超过window size的Row。
POI没有像XLSX那样对XLS的写做出性能的优化,原因是:
- 官方认为XLS的不像XLSX那样占内存
- XLS一个Sheet最多也只能有65535行数据
POI对导入分为3种模式,用户模式User Model,事件模式Event Model,还有Event User Model。
- 用户模式(User Model)就类似于dom方式的解析,是一种high level api,给人快速、方便开发用的。缺点是一次性将文件读入内存,构建一颗Dom树。并且在POI对Excel的抽象中,每一行,每一个单元格都是一个对象。当文件大,数据量多的时候对内存的占用可想而知。 用户模式就是类似用 WorkbookFactory.create(inputStream),poi 会把整个文件一次性解析,生成全部的Sheet,Row,Cell以及对象,如果导入文件数据量大的话,也很可能会导致OOM。
- 事件模式(Event Model)就是SAX解析。Event Model使用的方式是边读取边解析,并且不会将这些数据封装成Row,Cell这样的对象。而都只是普通的数字或者是字符串。并且这些解析出来的对象是不需要一直驻留在内存中,而是解析完使用后就可以回收。所以相比于User Model,Event Model更节省内存,效率也更。但是作为代价,相比User Model功能更少,门槛也要高一些。我们需要去学习Excel存储数据的各个Xml中每个标签,标签中的属性的含义,然后对解析代码进行设计。
- User Event Model也是采用流式解析,但是不同于Event Model,POI基于Event Model为我们封装了一层。我们不再面对Element的事件编程,而是面向StartRow,EndRow,Cell等事件编程。而提供的数据,也不再像之前是原始数据,而是全部格式化好,方便开发者开箱即用。大大简化了我们的开发效率。
easyexcel
EasyExcel是阿里巴巴开源的库,底层基于poi,主要解决了poi框架使用复杂,sax解析模式不容易操作,数据量大起来容易OOM,解决了POI并发的bug。主要解决方式:通过解压文件的方式加载,一行一行的加载,并且抛弃样式字体等不重要的数据,降低内存的占用。
EasyExcel优势
- 注解式自定义操作。
- 输入输出简单,提供输入输出过程的接口
- 支持一定程度的单元格合并等灵活化操作
excel与类映射,靠注解实现
@Data
@ColumnWidth(25)
public class CardExport {
@ExcelProperty("编号")
private String id;
@ExcelProperty("接入电话")
private String phone;
@ExcelProperty("ICCID")
private String iccidMark;
@ExcelProperty("IMEI")
private String imei;
@ExcelProperty("开卡公司")
private String accountName;
}
- @ExcelProperty 指定当前字段对应excel中的那一列。可以根据名字或者Index去匹配。当然也可以不写,默认第一个字段就是index=0,以此类推。千万注意,要么全部不写,要么全部用index,要么全部用名字去匹配。千万别三个混着用,除非你非常了解源代码中三个混着用怎么去排序的。
- @ExcelIgnore 默认所有字段都会和excel去匹配,加了这个注解会忽略该字段
- @DateTimeFormat 日期转换,用String去接收excel日期格式的数据会调用这个注解。里面的value参照java.text.SimpleDateFormat
- @NumberFormat 数字转换,用String去接收excel数字格式的数据会调用这个注解。里面的value参照java.text.DecimalFormat
- @ExcelIgnoreUnannotated默认不加ExcelProperty 的注解的都会参与读写,加了不会参与
读Excel
/**
* 最简单的读
* 1. 创建excel对应的实体对象 参照{@link DemoData}
*
2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link DemoDataListener}
*
3. 直接读即可
*/
@Test
public void simpleRead() {
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 这里 需要指定读用哪个class去读,然后读取第一个sheet 文件流会自动关闭
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
写Excel
/**
* 最简单的写
* 1. 创建excel对应的实体对象 参照{@link com.alibaba.easyexcel.test.demo.write.DemoData}
*
2. 直接写即可
*/
@Test
public void simpleWrite() {
String fileName = TestFileUtil.getPath() + "write" + System.currentTimeMillis() + ".xlsx";
// 这里 需要指定写用哪个class去读,然后写到第一个sheet,名字为模板 然后文件流会自动关闭
// 如果这里想使用03 则 传入excelType参数即可
EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}
web上传、下载
/**
* 文件下载(失败了会返回一个有部分数据的Excel)
* 1. 创建excel对应的实体对象 参照{@link DownloadData}
* 2. 设置返回的 参数
* 3. 直接写,这里注意,finish的时候会自动关闭OutputStream,当然你外面再关闭流问题不大
*/
@GetMapping("download")
public void download(HttpServletResponse response) throws IOException {
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
// 这里URLEncoder.encode可以防止中文乱码
String fileName = URLEncoder.encode("测试", "UTF-8").replaceAll("\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=utf-8''" + fileName + ".xlsx");
EasyExcel.write(response.getOutputStream(), DownloadData.class).sheet("模板").doWrite(data());
}
/**
* 文件上传
* 1. 创建excel对应的实体对象 参照{@link UploadData}
*
2. 由于默认一行行的读取excel,所以需要创建excel一行一行的回调监听器,参照{@link UploadDataListener}
*
3. 直接读即可
*/
@PostMapping("upload")
@ResponseBody
public String upload(MultipartFile file) throws IOException {
EasyExcel.read(file.getInputStream(), UploadData.class, new UploadDataListener(uploadDAO)).sheet().doRead();
return "success";
}
文件到客户端
应用程序读取文件,传输给用户,为流式传输,不会占用过多内存,一般不会导致OOM
体验优化
当一个操作需要很长时间响应时,体验会很差,导出也是如此,下面讨论如何避免用户长时间的等待。主要从两个方面:缩短时间、异步导出
缩短时间
要缩短时间就要分析在哪一块花费的时间过长,做针对性的优化,通常瓶颈在下面两个地方
- 数据库sql查询慢
- 网络传输慢
其他如内存不够频繁gc,cpu性能不足等目前看相较之下影响比较小,暂不考虑。
数据库层面的优化也就是sql调优和库表结构优化,sql一般需要走索引,不需要的字段不要查。
网络层面优化,通过公式
数据量/带宽=传输时间
可知:减小数据量,增大带宽即可缩短传输时间
带宽优化增强:
1、数据流转尽量全部在局域网之中
2、使用OSS等云产品提供给用户下载导出文件
减小数据量:
文件压缩后传输,用户侧解压
异步导出
即在后台静默导出,导出完成通知给客户,如下。
优化后架构:

文件压缩
if (context.fileList.size() > 1) {
//压缩文件
String zipName = DateUtil.getYMDHMSFormatter()+"_"+(int)((Math.random()*9+1)*100000)+".zip";
List<File> srcFiles = new ArrayList<>();
for (String name : context.fileList) {
srcFiles.add(new File(WebConstant.THREAD_TOB_EXPORT_URL + name));
}
logger.info("{}开始压缩", taskId);
long startTime = System.currentTimeMillis();
try {
ZipUtil.zip(srcFiles, new File(WebConstant.THREAD_TOB_EXPORT_URL + zipName));
} catch (Exception e) {
logger.error("{}压缩异常", taskId);
throw new RuntimeException(e);
}
long endTime = System.currentTimeMillis();
logger.info("{}结束压缩,耗时:{}s", taskId, (endTime-startTime)/1000);
//删除多余文件
for (String name : context.fileList) {
new File(WebConstant.THREAD_TOB_EXPORT_URL + name).delete();
}
msg.setFileName(zipName);
}
上传OSS
public static String localFirstUpload(String path, String fileName, String bucket, boolean isInternalNet) throws Exception {
// 创建OSSClient实例。
if (localFirstClient == null) {
String endPoint = END_POINT;
if (isInternalNet) {
endPoint = LOCAL_END_POINT;
}
localFirstClient = new OSSClientBuilder().build(endPoint, ACCESS_KEY, SECRET_KEY);
}
InputStream inputStream = new FileInputStream(path);
// 依次填写Bucket名称(例如examplebucket)和Object完整路径(例如exampledir/exampleobject.txt)。Object完整路径中不能包含Bucket名称。
localFirstClient.putObject(bucket, fileName, inputStream);
return "https://"+bucket+".oss-cn-hangzhou.aliyuncs.com/"+fileName;
}
解决并发问题
1、异步
增加任务状态表,处理完成时更新,并提供下载地址
2、排队
将后来的导出任务线程阻塞,并控制并发量,等待优先任务处理完,再处理后续任务,目前是通过Semaphore实现最大并行导出数量
private static final Semaphore LIMIT_THREAD = new Semaphore(TASK_NUM);
public void doExport() {
try {
LIMIT_THREAD.acquire();
} catch (InterruptedException e) {
throw new RuntimeException("导出人数过多,请稍后再试");
}
try {
//处理业务代码
} catch (RuntimeException e) {
throw e;
} finally {
LIMIT_THREAD.release();
}
}
其他建议:增加导出进度状态、完全异步导出
优点:
无需占用线程资源
可检测重复导出,重复导出只导一次
系统重启后可恢复
其他导出方式
前端生成excel
sheetJs介绍
读取:
function handleFile(e) {
var files = e.target.files, f = files[0];
var reader = new FileReader();
reader.onload = function(e) {
var workbook = XLSX.read(e.target.result);
/* DO SOMETHING WITH workbook HERE */
};
reader.readAsArrayBuffer(f);
}
input_dom_element.addEventListener('change', handleFile, false);
XLSX.utils.sheet_to_json(ws);
下载:
/* bookType can be any supported output type */
var wopts = { bookType:'xlsx', bookSST:false, type:'array' };
var wbout = XLSX.write(workbook,wopts);
/* the saveAs call downloads a file on the local machine */
saveAs(new Blob([wbout],{type:"application/octet-stream"}), "test.xlsx");
前端处理架构
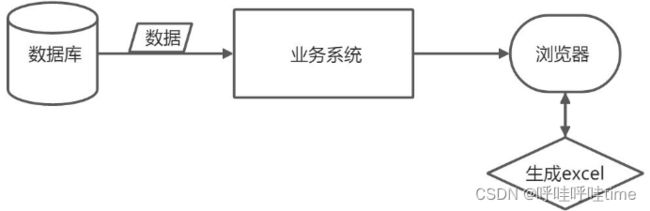
优点:
后端无需额外提供导出接口,直接复用列表查询接口
可直接使用前端编码映射
部分性能消耗转移到客户端,减少服务器压力
数据库工具导出

navicat
mysqldump
mysqldump 命令是数据库导出中使用最频繁的一个工具,它可将数据库中的数据备份成已 *.sql 结尾的文本文件,表结构和数据都会存储在其中。mysqldump 命令的原理也很简单,它先把需要备份的表结构查询出来,然后生成一个 CREATE TABLE ‘table’ 语句,最后将表中所有记录转化成一条INSERT语句。可以把它理解为一个批量导出导入脚本。数据导入时,按照规范语句导入数据,大幅减少奇怪的未知错误出现。
mysqldump 的基本命令:
$ mysqldump -u username -p database_name > data-dump.sql
- username 是数据库的登录名
- database_name 是需要导出的数据库名称
- data-dump.sql 是文件输出目录的文件
输入数据库账号的密码执行命令,如果执行过程中,没有任何错误,那么命令行不会有任何输出。
mysqldump 也可以分表备份,比较常见的场景有
# 备份单个库
$ mysqldump -uroot -p -R -E --single-transactio --databases [database_one] > database_one.sql
# 备份部分表
$ mysqldump -uroot -p --single-transaction [database_one] [table_one] [table_two] > database_table12.sql
# 排除某些表
$ mysqldump -uroot -p [database_one] --ignore-table=[database_one.table_one] --ignore-table=[database_one.table_two] > database_one.sql
# 只备份结构
$ mysqldump -uroot -p [database_one] --no-data > [database_one.defs].sql
# 只备份数据
$ mysqldump -uroot -p [database_one] --no-create-info > [database_one.data].sql
into outfile
使用 into outfile 命令导出 MySQL数据至 CSV / Excel
select * from users into outfile '/var/lib/mysql-files/users.csv' FIELDS TERMINATED BY ',';
FIELDS TERMINATED BY ‘,’ 表示数据以 ','进行分隔。
导出后会显示成功提示,CD 到导出目录可看到 CSV 文件已导出。
提示:into outfile 常见报错
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statement
这是因为MySQL 配置了–secure-file-priv 限制了导出文件的存放位置。可以使用以下命令来查看具体配置信息
show global variables like '%secure_file_priv%';
secure_file_priv 为 NULL 时,表示不允许导入或导出。 secure_file_priv 为路径时(/var/lib/mysql-files/ )时,表示只允许在路径目录中执行。 secure_file_priv 没有值时,表示可在任意目录的导入导出。可以 my.cnf 或 my.ini配置以下语句,重启 MySQL server 即可
secure_file_priv=''
优点:
简洁,直接
脱离原系统,与业务系统耦合小
缺点:
如果业务人员不熟悉sql和数据库结构及编码,就会大大增加开发人员工作量