cs231n assignment 2 q3 dropout
文章目录
- 嫌啰嗦直接看源码
- Q3 Dropout
-
- dropout_forward
-
- 题面
- 解析
- 代码
- 输出
- dropout_backward
-
- 题面
- 代码
- 输出
- 修改fc_net
-
- 题面
- 解析
- 代码
-
- loss函数
- 输出
嫌啰嗦直接看源码
Q3 Dropout
这部分的理论知识,其实在课程中已经讲的比较清晰明了,因此我这里不在赘述相关的知识点,又不懂得地方多看几次课应该能看明白
他主要是会在训练模型的时候随机丢弃一些神经元,但是在使用模型的时候保持不变,这就是dropout干的事情
dropout_forward
题面

解析
训练时随机丢弃神经元,test时保持不变,就这么简单
代码
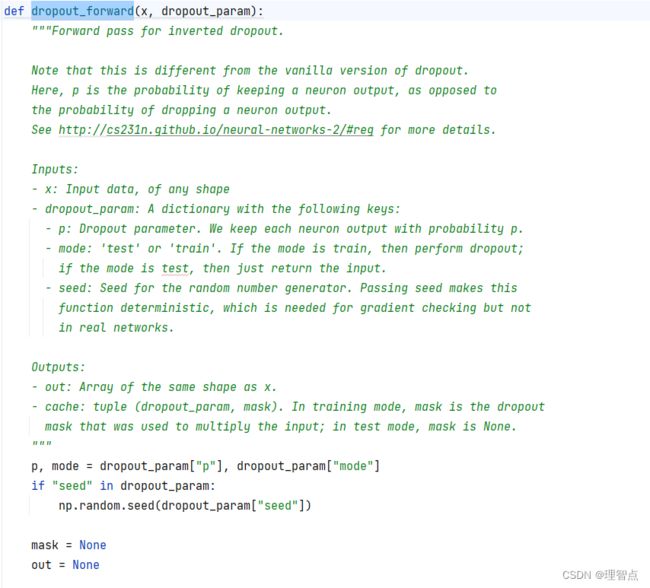
def dropout_forward(x, dropout_param):
"""Forward pass for inverted dropout.
Note that this is different from the vanilla version of dropout.
Here, p is the probability of keeping a neuron output, as opposed to
the probability of dropping a neuron output.
See http://cs231n.github.io/neural-networks-2/#reg for more details.
Inputs:
- x: Input data, of any shape
- dropout_param: A dictionary with the following keys:
- p: Dropout parameter. We keep each neuron output with probability p.
- mode: 'test' or 'train'. If the mode is train, then perform dropout;
if the mode is test, then just return the input.
- seed: Seed for the random number generator. Passing seed makes this
function deterministic, which is needed for gradient checking but not
in real networks.
Outputs:
- out: Array of the same shape as x.
- cache: tuple (dropout_param, mask). In training mode, mask is the dropout
mask that was used to multiply the input; in test mode, mask is None.
"""
p, mode = dropout_param["p"], dropout_param["mode"]
if "seed" in dropout_param:
np.random.seed(dropout_param["seed"])
mask = None
out = None
if mode == "train":
#######################################################################
# TODO: Implement training phase forward pass for inverted dropout. #
# Store the dropout mask in the mask variable. #
#######################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
mask = (np.random.rand(*x.shape) < p) / p # 生成mask
out = x * mask # dropout操作
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#######################################################################
# END OF YOUR CODE #
#######################################################################
elif mode == "test":
#######################################################################
# TODO: Implement the test phase forward pass for inverted dropout. #
#######################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = x # 测试阶段不做任何操作
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#######################################################################
# END OF YOUR CODE #
#######################################################################
cache = (dropout_param, mask)
out = out.astype(x.dtype, copy=False)
return out, cache
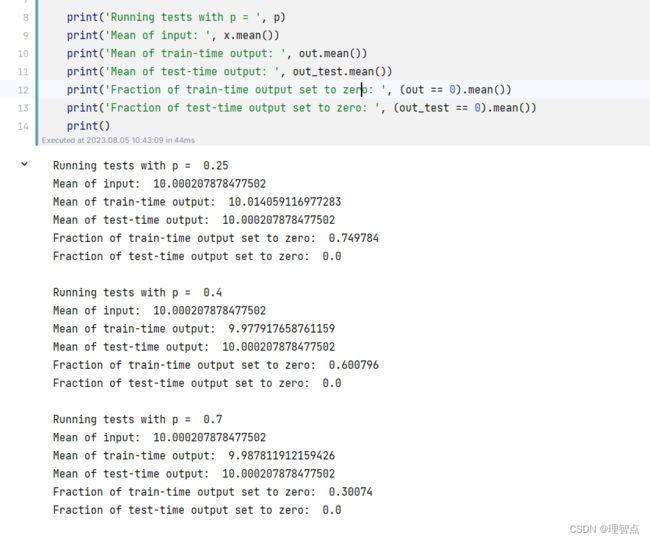
输出
dropout_backward
题面
代码
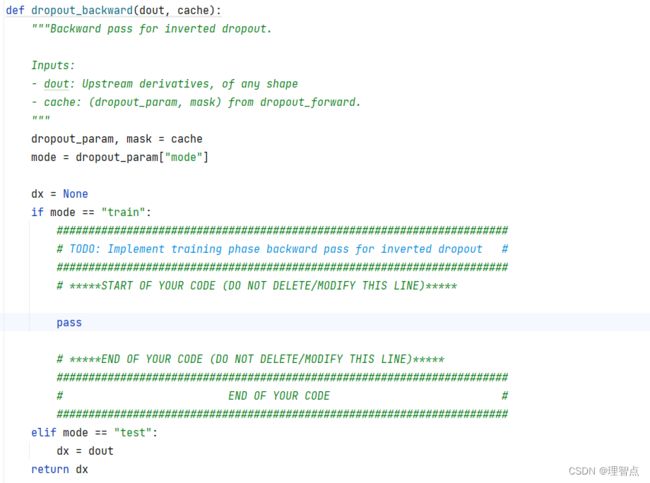
def dropout_backward(dout, cache):
"""Backward pass for inverted dropout.
Inputs:
- dout: Upstream derivatives, of any shape
- cache: (dropout_param, mask) from dropout_forward.
"""
dropout_param, mask = cache
mode = dropout_param["mode"]
dx = None
if mode == "train":
#######################################################################
# TODO: Implement training phase backward pass for inverted dropout #
#######################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dx = dout * mask
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
#######################################################################
# END OF YOUR CODE #
#######################################################################
elif mode == "test":
dx = dout
return dx
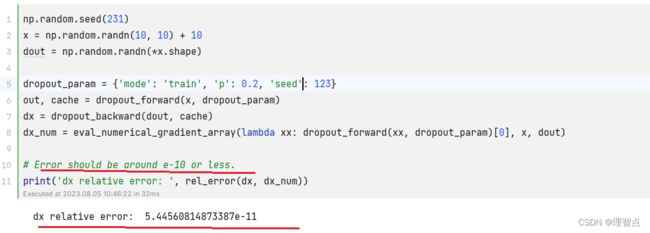
输出
修改fc_net
题面

解析
就是加了一层dropout层在最后
代码
loss函数
def loss(self, X, y=None):
"""Compute loss and gradient for the fully connected net.
Inputs:
- X: Array of input data of shape (N, d_1, ..., d_k)
- y: Array of labels, of shape (N,). y[i] gives the label for X[i].
Returns:
If y is None, then run a test-time forward pass of the model and return:
- scores: Array of shape (N, C) giving classification scores, where
scores[i, c] is the classification score for X[i] and class c.
If y is not None, then run a training-time forward and backward pass and
return a tuple of:
- loss: Scalar value giving the loss
- grads: Dictionary with the same keys as self.params, mapping parameter
names to gradients of the loss with respect to those parameters.
"""
X = X.astype(self.dtype)
mode = "test" if y is None else "train"
# Set train/test mode for batchnorm params and dropout param since they
# behave differently during training and testing.
if self.use_dropout:
self.dropout_param["mode"] = mode
if self.normalization == "batchnorm":
for bn_param in self.bn_params:
bn_param["mode"] = mode
scores = None
############################################################################
# TODO: Implement the forward pass for the fully connected net, computing #
# the class scores for X and storing them in the scores variable. #
# #
# When using dropout, you'll need to pass self.dropout_param to each #
# dropout forward pass. #
# #
# When using batch normalization, you'll need to pass self.bn_params[0] to #
# the forward pass for the first batch normalization layer, pass #
# self.bn_params[1] to the forward pass for the second batch normalization #
# layer, etc. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 我们网络的结果是这样的 {affine - [batch/layer norm] - relu - [dropout]} x (L - 1) - affine - softmax
# 用一个变量保存上一层的输出
layer_input = X
caches = {}
# 对前面 L - 1层进行操作,因为最后一层的操作和前面的不一样
for i in range(1, self.num_layers):
W = self.params['W' + str(i)]
b = self.params['b' + str(i)]
if self.normalization == 'batchnorm':
gamma = self.params['gamma' + str(i)]
beta = self.params['beta' + str(i)]
layer_input, caches['layer' + str(i)] = affine_bn_relu_forward(layer_input, W, b, gamma, beta, self.bn_params[i - 1])
else:
layer_input, caches['layer' + str(i)] = affine_relu_forward(layer_input, W, b)
if self.use_dropout: # 如果使用dropout
layer_input, caches['dropout' + str(i)] = dropout_forward(layer_input, self.dropout_param)
# 最后一层的操作
W = self.params['W' + str(self.num_layers)]
b = self.params['b' + str(self.num_layers)]
scores, affine_cache = affine_forward(layer_input, W, b)
caches['layer' + str(self.num_layers)] = affine_cache
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
# If test mode return early.
if mode == "test":
return scores
loss, grads = 0.0, {}
############################################################################
# TODO: Implement the backward pass for the fully connected net. Store the #
# loss in the loss variable and gradients in the grads dictionary. Compute #
# data loss using softmax, and make sure that grads[k] holds the gradients #
# for self.params[k]. Don't forget to add L2 regularization! #
# #
# When using batch/layer normalization, you don't need to regularize the #
# scale and shift parameters. #
# #
# NOTE: To ensure that your implementation matches ours and you pass the #
# automated tests, make sure that your L2 regularization includes a factor #
# of 0.5 to simplify the expression for the gradient. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 计算loss
loss, dscores = softmax_loss(scores, y)
# 先计算最后一层的梯度
dx, dw, db = affine_backward(dscores, caches['layer' + str(self.num_layers)])
grads['W' + str(self.num_layers)] = dw + self.reg * self.params['W' + str(self.num_layers)]
grads['b' + str(self.num_layers)] = db
for i in range(self.num_layers - 1, 0, -1):
if self.use_dropout: # dropout层的梯度
dx = dropout_backward(dx, caches['dropout' + str(i)])
if self.normalization == 'batchnorm':
dx, dw, db, dgamma, dbeta = affine_bn_relu_backward(dx, caches['layer' + str(i)])
grads['gamma' + str(i)] = dgamma
grads['beta' + str(i)] = dbeta
else:
dx, dw, db = affine_relu_backward(dx, caches['layer' + str(i)])
grads['W' + str(i)] = dw + self.reg * self.params['W' + str(i)]
grads['b' + str(i)] = db
# 加上正则化项
for i in range(1, self.num_layers + 1):
W = self.params['W' + str(i)]
loss += 0.5 * self.reg * np.sum(W * W)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
输出
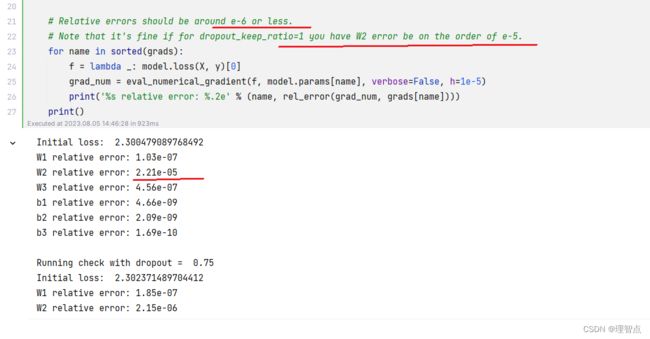
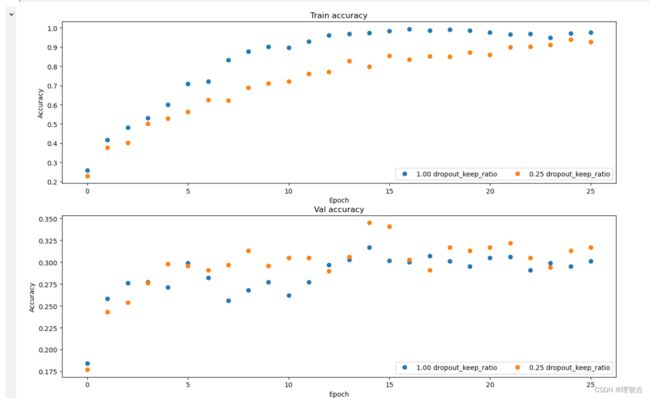
可以看出不使用dropout的模型有点过拟合了