002_韦东山嵌入式Linux应用开发基础_实操碰到的问题集锦
嵌入式Linux应用开发基础_韦东山教程思考笔记
配合《嵌入式Linux应用开发完全手册V5.1_IMX6ULL_Pro开发板》
文件目录
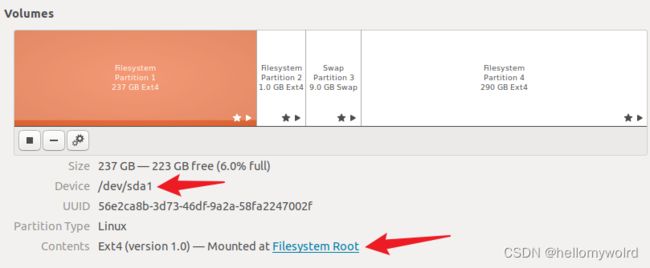
访问根/目录下,Filesystem Root目录中的文件的时候, 其实是在访问/dev/sda1,即磁盘的第一个分区,因为这个分区挂载在那个目录下面,当给这个目录挂载新的磁盘分区的时候,这个目录下的old文件不可见,因为old文件存放在之前那个分区sda1中。

- bin和sbin目录中存放命令,也就是app
- usr目录下的一系列目录中的文件存放非开机启动必须的app文件
- 以上app文件需要用到库文件,存放在根目录下的lib目录和usr下的lib目录
- [[003_Linux文件目录#^7d52df|dev]]目录下存放一些硬件信息
- home目录下每一个文件对应一个用户
- proc和sys挂载某些虚拟文件系统,对于这个虚拟文件系统没有真实的存储设备,可以访问一些内核的信息,例如由内核提供的process进程
Path路径
其实和windows的添加环境变量类似,当用户在桌面添加一个hello.c的文件的时候,直接在终端执行,shell是找不到的,shell只会去设置好的路径中寻找有没有这个可执行文件,因此home/book/Desktop这个路径并不会被搜索到,因此需要添加这个book路径
cd /home/book 第一个/代表根目录,如果要在当前目录下查找,不要加第一个/
权限属性

(上图中,普通用户无法修改hello文件的用户和所属的用户组)
- 用户: Linux是多用户多任务的系统,每个用户都有自己的个人隐私,这就是用户的作用。
- 用户组: Linux是多用户多任务的系统,你想和你团队合作者一起分享某些文件,非团队的用户不能看你分享的文件,这就是用户组的作用。(一个用户可以有多个用户组)
- 其他用户: Linux是多用户多任务的系统,例如一个人陌生人(其他用户)想要进入你家(用户组),你(用户)肯定不会让他进来,也肯定不会把你的隐私(用户拥有的文件)给他看。
- sudo 命令可以临时切换升级为root权限
注:root身份是拥有至高无上的权利的,不管有没有设置权限,root身份的用户都可以进行各种操作。所以如果不需要使用root至高无上的权利时,最好不要以root的身份去进行操作,万一输错代码把系统文件删了你就凉凉了。(不过你可以设置一个快照来恢复原来的系统)
网络配置及git_clone使用
NAT网卡
(Network Address Translation)
Ubuntu访问外网的时候,通过NAT网卡把请求发给windows虚拟网卡(可以在windows网络连接中查看是否有这个虚拟网卡),windows的虚拟网卡去访问外网,外网先发给windows,再由windows转发给ubuntu。(windows和ubuntu可以互ping)

git clone下载时候一直refused,连接这个ip端口一直失败,在关闭代理后重启ubuntu后可以正常clone下载。
ubuntu中解决Failed to connect to 127.0.0.1 port xxxxx: Connection refused_为什么乌班图进http://127.0.0.1进不去_Deep In 的博客-CSDN博客
那么为什么取消代理就可以下载了呢?
什么是 http 代理,为什么需要 http 代理 - 知乎 (zhihu.com)
USB桥接网卡
既给windows使用,也给ubuntu使用,使用桥接网卡时,Ubuntu就是使用一个真实的网卡:开发板的网线也连接 到这个真实的网卡上,这样Ubuntu、开发板就可以用过这个网卡互 .
windows和Ubuntu都可以ping这个真实的网卡
repo脚本工具
Repo是谷歌用Python脚本写的调用git的一个脚本,可以实现管理多个git库。repo呢,其实说来,就是很多个git clone 的集成,如果有一个工程,有一百个git,你下载下来,按逻辑是敲一百次git clone xxxx,下载下来。但是使用repo呢,只需要敲一次,喝喝茶,等待下载完成就可以了。
Linux源码阅读

sdk文件下载下来后复制到windows中,用sourceinsight阅读,sourceinsight要add all,添加所有的文件,包含top level的文件和所有的sub子文件;最后同步所有的文件,所谓同步文件,就是解析源码,生成函数生成变量的数据库,以后就可以点击某个函数快速跳转到定义的地方。
SourceInsight快捷键
NFS协议(mount挂载)
使用这个协议(Net FileSystem),通过网络去访问别的电脑,比如ubuntu系统的某个目录。
- 基于安全考虑,不能访问ubuntu任何一个文件,因此要在ubuntu里面打开权限,
/etc/exports, 其中指定了有哪些目录的开放权限可供访问的 - 开启NFS服务,以后开发板可以来连接,进行文件操作
- mount, 开发板的目录要挂载到本地的某一个目录,
在串口开发板上执行下面命令
mount -t nfs -o nolock,vers=3 192.168.5.11:/home/book/nfs_rootfs /mnt
注释:mount命令,-t(type), -o(option) ,挂载ubuntu的主机的/home/book/nfs_rootfs目录,挂载到开发板的mnt目录。此后ubuntu主机的的这个目录中删改文件,可以在Linux开发板的 /mnt目录中同步删改, 反之亦然,非常方便。
当然也可以用Filezilla软件来传输文件,但是使用NFS依旧是主流的方式
第一个应用程序,hello.c
arm工具链安装在ubuntu里面,不同的开发板需要不同的工具链来生成执行文件,在ubuntu里面先用arm工具链生成执行文件,再通过nfs协议同步挂载到 Linux开发板的 nfs目录里执行
/*****************************Ubuntu***********************************/
book@100ask:~/nfs_rootfs$ arm-buildroot-linux-gnueabihf-gcc -o hello hello.c
book@100ask:~/nfs_rootfs$ ls
1.txt 2.txt hello hello.c
/****************************Linux开发板*******************************/
[root@100ask:/mnt]# ./hello
Hello, world!
第一个驱动程序
驱动程序中的文件来自于内核,依赖于内核,必须有内核的源码且内核必须配置编译完成。
比如驱动程序中这样包含头文件:#include ,其中的 asm 是
一个链接文件,指向 asm-arm 或 asm-mips,这需要先配置、编译内核才会生成
asm 这个链接文件,
为何要编译查看完全手册的,第三篇,5.1
步骤
- 配置编译:内核、设备树、驱动
- make 100ask_imx6ull_defconfig 配置内核,指定这个内核是给arm还是-86等别的架构的板子编译的
- make zImage -j4 编译内核
- make dtbs 编译设备树
- make modules 把内核模块驱动程序编译出来
- 把1中编译的东西烧入板子
1. uname -a 查看开发板当前内核版本
2. cp /mnt/zImage /boot 更新内核 到boot
3. cp /mnt/100ask_imx6ull-14x14.dtb /boot 更新设备树
4. cp /mnt/lib/modules /lib -rfd 更新模块
1. r递归;f强制;d原来是链接文件复制的时候也作为链接文件可以节省空间
5. sync 同步,拷贝成功后这些文件可能还在内存中,需要同步命令把文件强制刷到flash上去 - 编译、测试编写的驱动程序
- 驱动程序先上传到Ubuntu
- vi Makefile 内要指定用哪个内核源码目录,路径
KERN_DIR = /home/book/100ask_roc-rk3399-pc/linux-4.4- make 指令,编译驱动
insmod hello_drv.ko安装相应的驱动模块- 有些开发板打开了或者禁止了printk信息,导致你看到的实验现象可能不一样
- echo “1 4 1 7” > /proc/sys/kernel/printk ,禁止
- echo “7 4 1 7” > /proc/sys/kernel/printk , 使能
- lsmod 查看是否安装成功
应用开发基础
Gcc编译器使用
GNU CC(简称为Gcc)是GNU项目中符合ANSI C标准的编译系统,能够编译用C、C++和Object C等语言编写的程序。Gcc不仅功能强大,而且可以编译如C、C++、Object C、Java、Fortran、Pascal、Modula-3和Ada等多种语言,而且Gcc又是一个交叉平台编译器,它能够在当前CPU平台上为多种不同体系结构的硬件平台开发软件,因此尤其适合在嵌入式领域的开发编译。
不错的GCC入门网站GCC编译器30分钟入门教程 (biancheng.net)
完整GCC_v7.5.0 在线文档 gcc.pdf (gnu.org)
gcc -o test main.c sub.c可以一起编译并且链接为一个test应用程序,但是缺点就是改动一个.c文件就需要全部重新编译,浪费时间,所以文件数量很多的时候可以分开编译,最后统一链接- <.h>会去工具链里默认的指定的路径目录里查找头文件,".h"去当前目录下查找

- 静态库和动态库都是动静态库, 本质是可执行程序的“半成品”,制作一些可执行文件如果经常调用某些相同程序,就可以把这个程序汇编成.o目标文件打包成库
- 链接和运行是不同的概念,他们去查找的路径也不同
Makefile
- 当依赖文件比目标文件新,则执行
参考文档:
- 百度搜"anu make 于凤昌"
- 官方文档: http://www.gnu.org/software/make/manual/
- 如果想深入, 可以学习韦东山的第3期视频项目1,第1课第4节 数码相框_编写通用的Makefile_P
003 Makefile实例改进: 支持头文件依赖a;添加CFLAGS;编写裸板Makefile
4.自动生成头文件.h依赖,可以参考这篇文章 Linux Makefile 生成 *.d 依赖文件以及 gcc -M -MF -MP 等相关选项说明_
核心规则
- 目标:依赖1,依赖2…
- [TAB] 命令(command),这个很重要,如果文本中有tab键但是没有写命令会导致运行失效
- 当“目标文件”不存在,或者,某个依赖文件比目标文件新,则执行命令
- make指令,会执行makefile中的第一个目标,[TAB]以左,冒号左边的就是目标
Makefile经常用到的指令
| 功能 | 指令 | 扩展 |
|---|---|---|
| 表示所有依赖文件 | $^ | |
| 表示第1个依赖文件 | $< | |
| 表示一个规则中的目标 | $@ | |
| 变量通配符 | % | |
| 假象文件,不会额外判断是否存在某文件 | .PHONY: | |
| 在make执行时打印出自己预设的内容 | (@)echo | echo的使用 |
| 注释命令 | # | |
| 延时变量1 | immediate = deferred | |
| 延时变量2,且必须是第一次被定义 | immediate ?= deferred | |
| 即时变量, | immediate := immediate | |
| 附加,即时or延时取决于前面的定义 | immediate += immediate | |
| 显示makefile文件执行的进程 | echo | |
| for each var in list, change it to text | $(foreach var,list,text) | foreach使用 |
| 在text中取出符合patten格式的值 | $(filter pattern…,text) | |
| 在text中取出不符合patten格式的值 | $(filter-out pattern…,text) | |
| 以 pattern 这个格式,去寻找存在的文件,返回存在文件的名字。 | $(wildcard pattern) | |
| patsubst 函数是从text里面取出每一个值,如果这个符合 pattern 格式,把它替换成 replacement 格式 | $(patsubst pattern,replacement,text) | |
文件IO
在LINUX系统中,一切都是文件
特殊文件
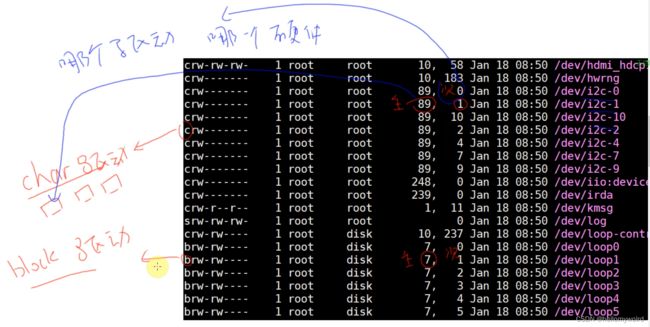
/dev/xxx这些文件称为设备节点,我们open, read, write这些节点的时候操作的是硬件,通过驱动程序去访问到硬件- 下图是执行命令
ls /dev/ -l,查看dev下的所有文件 - 可以看出,在LINUX内核中有两类驱动程序,一种是char驱动,另一种是block驱动,主设备号确定用哪个驱动,次设备号确定这个驱动中操作哪个硬件
显示文字
| 编码格式 | 内存 | 细分具体编码 | 存在的问题 |
|---|---|---|---|
| ASCII | 1字节,实际只有7位 | 能表达的内容太少 | |
| ANSI | 对于 ASCII 字符仍使用一个字节来表示(BIT7 是 0),对于非ASCII 字符一般使用 2 个字节来表示,非 ASCII 字符的数值 BIT7 都是 1 | GB2312,BIG5 | 会出现同一个数值对应不同字符 |
| UNICODE | 2~3字节 | UTF-16 LE/BE,UTF8 | |
| UTF-16 LE/BE | 小字节序和大字节序都是2字节 | 表示的字符数量有限、对于 ASCII 字符有空间浪费、如果文件中有某个字节丢失,这会使得后面所有字符都因为错位而无法显示 | |
| UTF-8 | 非 ASCII 字符,每一个字节的高位都自带长度信息 | 完美 | |
交叉编译程序
交叉编译详解_ Crifan Li
注:需上科学
- 头文件和库文件都可以自己指定位置,一般在include和各种lib目录中,板子中也是一样,但是板子中一般不需要头文件
- 运行时不需要头文件,所以头文件不用放到板子上
- 因为编译器处理 C 文件时,首先读到的是 include 头文件包含语句,然后,将那个头文件里的内容原封不动地复制到当前 C 文件。
- 参考一篇写头文件用处的文章:如果没有头文件,C/C++ 的世界将会怎样
第一步
echo 'main(){}'| arm-buildroot-linux-gnueabihf-gcc -E -v -
- 建立一个main函数传给后面的编译工具链,它就会去寻找系统目录下的头文件和库文件
- 实际会去搜索好几个目录,在这些目录中你挑一个目录,之后把编译出来的头文件和库文件放进你自己挑的目录中就可以了
- 头文件中我们经常用到
- 挑选库文件目录的时候,可以去挑一个带有
libc.so的
第二步
./configure--host=arm-buildroot-linux-gnueabihf--prefix=$PWD/tmp ^e473ff
- 这只是配置命令,执行之后再make, 最后make install
- host ,代表我编译出来的程序运行于哪个主机,这个主机是arm,linux
- prefix, 指向当前目录下的tmp目录,执行make install时,会把头文件和库文件放入这个目录
- make, 编译程序、库、文档等
- make install:安装已经编译好的程序。复制文件树中到文件到指定的位置。这一步之后才会会把头文件和库文件放入tmp目录
第三步
cp -rf */......cp -drf */......全部拷贝,包括也会拷贝文件的链接形式,从而避免可能造成的内存浪费- 把tmp目录下的include和lib目录强制拷贝到第一步中挑选的系统目录
使用freetype显示文字
单个字体
对于ANSI-GB2312编码的c文件,编译时不指定 -finput-charset,就会使用默认的UNICODE-utf-8来解析c文件,并试图转换为wchar_t
因此,在源代码中以GB2312还是UTF8来表示都没有关系,当生成可执行程序时,在wchar_t类型的字符串里面保存的一定是UNICODE的值
触摸屏
测试tslib步骤及实操碰到的问题与解决方案
功能:帮助数据传输不稳定的触摸屏过滤掉跳动的输出
交叉编译tslib【基于IMX6ULL开发板】
- 解压缩tslib压缩包
- 解压缩后看文件夹里面有没有configure文件,有的话就用万能命令
./configure --host=arm-linux-gnueabihf --prefix=/- 问题1:为什么要指定prefix的目录?
- make 编译
从Makefile中读取指令,然后编译,他通过借助 Makefile 里面编写的编译规范进行自动化的调用 gcc 、ld 以及运行某些需要的程序进行编译的程序,会生成动态库、可执行文件等。 - make installDESTDIR=$PWD/tmp
- 问题2:为什么要指定DESTDIR的目录?—DESTDIR是“destination direction”目标路径
- 确保TS_CONF,这个预先设定的配置参数文件,在/etc/ts.conf这个目录下面
- 把编译出来的头文件和库文件放到工具链的默认目录中,这样之后再编译其他应用程序的时候就不用指定头文件目录和库文件目录了
- 问题1,2的解释网址推荐(我看完之后暂时还是不太懂,还需深入理解)
DESTDIR和make前缀 - 问答 - 腾讯云开发者社区-腾讯云 (tencent.com)
DESTDIR: GNU Make中的默认约定_coroutines的博客-CSDN博客
单板上编译测试tslib中碰到的问题
- 执行ts_print_mt, 一直提示-bash: /bin/ts print mt: cannot execute binary file: Exec format error
- 解放方法:ubuntu中make distclean, 然后 rm -rf tmp/, 然后跟着完全手册重新来一遍,八成是交叉工具链用错了吧,
- 第二次执行ts_print_mt,提示ts_test No raw modules loaded…
- 解决方法:单板上mnt目录中,去tslib-1.21/tmp/lib目录下,
cp ./ts /lib -rf,把ts复制到/lib目录下
- 解决方法:单板上mnt目录中,去tslib-1.21/tmp/lib目录下,
- 退出默认的qt gui程序,mv /etc/init.d/S07hmi /root,找不到S07hmi
- 你进开发板的 /etc/init.d目录看看,烧录过新系统需要移除两个GUI,S05lvgl和S99myirhmi2, 然后reboot重启单板,完美实现!