读FFA-net: Feature Fusion Attention Network for Single Image Dehazing
学习目标:
- FFA-Net: Feature Fusion Attention Network for Single Image Dehazing(特征融合注意网络)
- 代码部分本周还没有来得及,下周会争取复现出来
个人体会:
本文的特色就是使用了PA和CA,对不同通道和不同像素做不同处理,虽然本文的实现过程懂了,但是实现去雾的原理不懂,不明白为什么经过一些的卷积操作,残差链接就实现了图像去雾
知识点:
- 图片评价指标
图像评价指标:PSNR和SSIM
PSNR越高,图像和原图越接近
SSIM一般取值范围:0-1,值越大,质量越好。 - 深度学习损失函数
- 自制力机制
- 残差连接
- 常用的激励函数
- 全局平均池化:global average pooling和average pooling的区别是pooling时所采用的窗口区域大小,global average pooling的窗口大小就是整个feature map的大小,对整个feature map求一个平均值,假设有10个特征层,送入gap,仍然得到10层特征,只不过每层特征的大小为1*1。
内容解读:
1. 摘要:
在本文中,我们提出了一种端到端的特征融合注意力网络(FFA-Net)来直接恢复无雾图片。 FFA-Net 架构由三个关键组件组成:
1)一种新颖的特征注意(FA)模块将通道注意与像素注意机制相结合,考虑到
不同的通道特征包含完全不同的加权信息和雾度分布不均匀不同的图像像素。FA 对不同的特征和像素进行不平等的处理,这为处理提供了额外的灵活性具有不同类型的信息,扩展了 CNN 的表示能力。
2)一个基本的块结构包括局部残差学习和特征注意,局部残差学习允许不太重要的信息,例如要绕过的薄雾区或低频多个局部残差连接,让主网架构专注于更有效的信息。
3)基于注意力的不同层次的特征融合(FFA)结构,特征权重从特征注意力(FA)模块中自适应学习,赋予重要特征更多的权重。这种结构还可以保留浅层的信息,并将其传递到深层。
实验结果表明,我们提出的 FFA 网络在数量和数量上都大大超过了以前最先进的单图像去雾方法。定性地,从在 SOTS 室内测试数据集上为 30.23db 到 35.77db。
2.简介
本文提出了一种新的用于单图像去叠的端到端特征融合网络(简称FFA网络)。以前基于CNN的图像去叠网络对通道和像素特征的处理是一样的,但是薄雾在图像中的分布是不均匀的,薄雾的权重应该与厚雾区域像素的权重明显不同。此外,DCP还发现,在至少一个颜色(RGB)通道中,一些像素具有非常低的强度是非常常见的,这进一步说明了不同的通道特征具有完全不同的加权信息。如果我们对它一视同仁,它将花费大量资源对不重要的信息进行不必要的计算,网络将缺乏覆盖所有像素和通道的能力。最后,它将极大地限制网络的表示。自注意机制(Xu等人。2015年)(V aswani等人。2017年)(Wang等人。2018)在神经网络的设计中得到了广泛的应用,对网络的性能起到了重要的作用。灵感来源于作品(Zhang等人。2018),我们进一步设计了一个新颖的功能关注(FA)模块。FA模块在信道和像素特征上分别结合了信道注意和像素注意。FA不平等地处理不同的特征和像素,这可以在处理不同类型的信息时提供额外的灵活性。
ResNet(He et al. 2016)的出现使得训练非常深的网络成为可能。 我们采用跳跃连接的思想和注意机制,设计了一个由多个局部残差学习跳跃连接和特征注意组成的基本块。 一方面,局部残差学习允许通过多个局部残差学习绕过薄雾区域的信息和低频信息,使主网络学习到更多有用的信息。 通道注意力进一步提高了 FFA-Net 的能力
随着网络的不断深入,浅层特征信息往往难以保存。为了识别和融合不同层次的特征,U-Net(Ronneberger、Fischer和Brox,2015)和其他网络努力整合浅层和深层信息。同样,我们提出了一种基于注意力的特征融合结构(FFA),这种结构可以保留浅层信息并将其传递到深层。最重要的是,FFA网络在将所有特征输入特征融合模块之前,对不同层次的特征赋予不同的权值,权值是通过对FA模块的自适应学习获得的。它比那些直接指定重量的要好得多。
为了评价不同图像去噪网络的性能,常用峰值信噪比(PSNR)和结构相似性指数(SSIM)来量化去噪图像的恢复质量。对于人的主观评价,我们还提供了大量的网络输出。我们在广泛使用的去叠基准数据集RESIDE上验证了FFA网络的有效性(Li等人。2018年)。将PSNR和SSIM度量与以前的最新方法进行了比较。实验表明,FFA网络在定性和定量上都大大优于以往的方法。此外,我们还进行了大量的烧蚀实验,证明我们的FFA网络的关键部件具有优异的性能。总的来说,我们的贡献是以下四点:
- 提出了一种新的用于单图像去叠的端到端特征融合注意网络FFA网。FFA网在很大程度上超越了以往最先进的图像去叠方法,尤其在雾度大、纹理细节丰富的区域表现尤为突出。如图1和图8所示,我们在恢复图像细节和颜色保真度方面也具有强大的优势。
- 我们提出了一种新的特征注意(FA)模块,它结合了通道注意和像素注意机制。该模块在处理不同类型的信息时提供了额外的灵活性,更加关注浓雾的像素和更重要的信道信息。
- 我们提出了一个由局部剩余学习和特征注意(FA)组成的基本块,局部剩余学习允许通过多跳连接绕过薄雾区域和低频信息,特征注意(FA)进一步提高了FFA网络的容量。
- 我们提出了一种基于注意力的特征融合(FFA)结构,这种结构可以保留浅层信息并将其传递到深层。此外,它不仅能融合所有特征,而且能自适应地学习不同层次特征信息的不同权重。最后,与其他特征融合方法相比,该方法取得了更好的性能。
3.网络结构
在这一部分中,我们主要介绍了我们的特征融合注意力网络FFA-Net。如图,FFA网络的输入是一个模糊的图像,它被传递到一个浅层特征提取部分,然后被输入到N个具有多跳连接的群结构中,然后通过我们提出的特征注意模块将N个群结构的输出特征融合在一起,这些特征最终传递到重构部分和全局残差学习结构,从而得到无雾输出。此外,每一组结构都将B个基本块结构与局部剩余学习相结合,每一个基本块都结合了跳跃连接和特征注意(FA)模块。FA是由通道注意和像素注意组成的注意机制结构。
FFA-Net网络结构图
3.1 FA
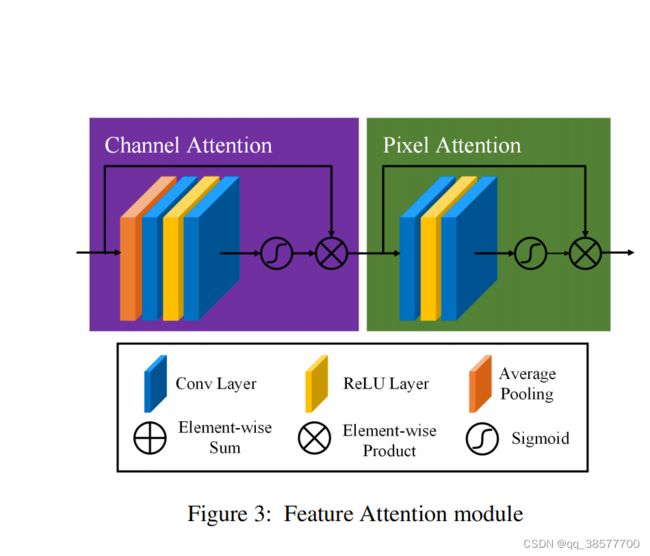
本文提出的特征注意由通道注意和像素注意组成,这可以在处理不同类型的信息时提供额外的灵活性。
FA不平等地处理不同的特征和像素区域,这可以在处理不同类型的信息时提供额外的灵活性,并且可以扩展CNNs的表示能力。关键的一步是如何为每个通道和像素特征生成不同的权重。我们的解决方案如下。
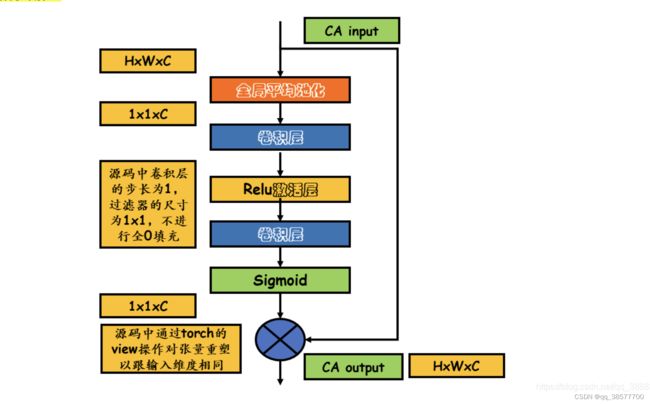
3.1.1Channel Attention (CA)
通道注意主要关注不同的频道特征对于DCP具有完全不同的加权信息。首先,利用全局平均池化将通道全局空间信息转化为通道描述符。
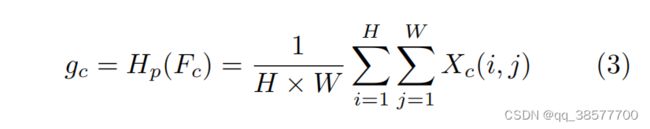
其中Xc(i,j)表示第c个通道Xc位置(i,j)的值,Hpis是全局池函数。特征图的形状由C×H×W变为C×1×1。为了得到不同通道的权值,特征通过两个卷积层和sigmoid,ReLu激活函数后
CAc = σ(Conv(δ(Conv(gc))))
其中,σ是sigmoid函数,δ是ReLu函数。最后,我们将输入fc与信道CAc的权值相乘。
CA详解
3.1.2 Pixel Attention (PA)
考虑到不同图像像素上的雾度分布不均匀,本文提出了一个像素注意(Pixel Attention,PA)模块,使网络更加关注信息特征,如浓密的雾度像素和高频图像区域
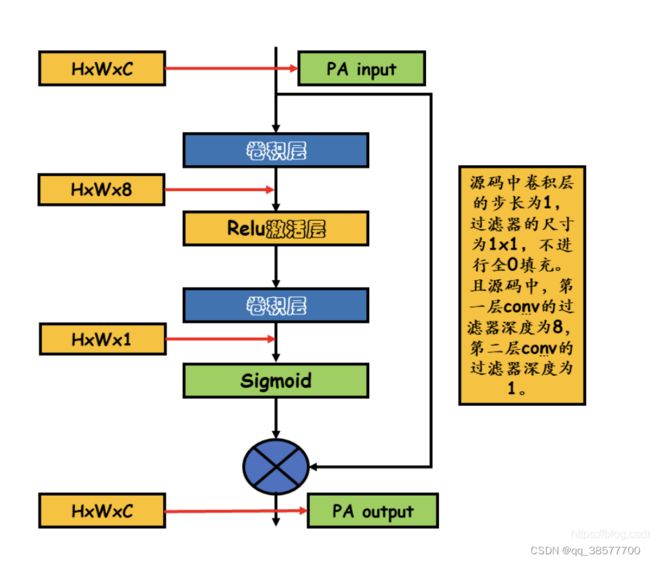
这个我个人的理解是用Relu激活层去掉不合适的数据,在用sigmoid相当于做权重分配 最后运用残差连接就可以达到目的 (不知道对不对)
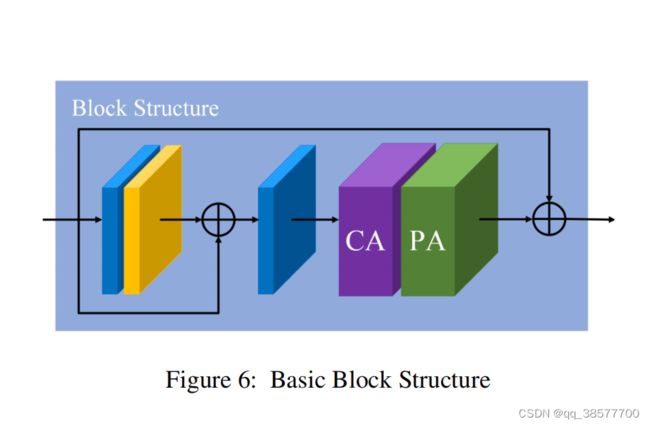
3.2 Basic Block Structure
基本块结构如图所示,基本块结构由局部剩余学习和特征注意(FA)模块组成,局部剩余学习(local residual learning)允许通过多个局部剩余连接绕过薄雾或低频区域等不太重要的信息,而主网络则注重有效的信息。实验结果表明,其结构可以进一步提高网络性能和训练的稳定性
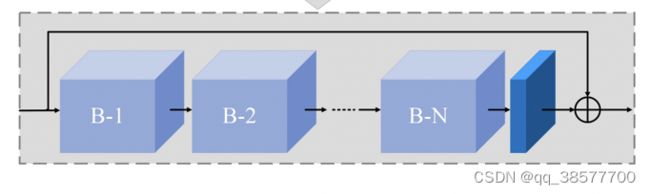
3.3 Group Architecture and Global Residual Learning
组架构(Group Architecture)结合了B基本块结构(B Basic Block Structure) 和 跳过连接模块(skip connection)。连续的B块增加了FFA网络的深度和表现力。skip connection解决了FFA -Net训练困难的问题。在FFA网络的最后,使用两层卷积网络实现和一个长全局残差学习模块添加了恢复部分。最后,恢复了想要的无雾图像。(不太懂)
3.4 Feature Fusion Attention
如上所述,首先将G个群结构输出的所有特征图在通道方向上连接起来。此外,我们通过乘以由特征注意(FA)机制获得的自适应学习权重来融合特征。由此,我们可以保留低层的信息并将其传递到深层,由于权重机制的存在,使得FFA网络更加关注厚雾区、高频纹理和色彩保真度等有效信息
4 损失函数
均方误差(mean squared error,MSE)或 L2损失是目前应用最广泛的单图像去雾的损失函数。然而Lim等人指出,在PSNR和SSIM指标方面,许多使用L1损失的图像恢复任务训练取得了比L2损失更好的性能。遵循同样的策略,本文默认采用简单的L1损失。尽管许多去雾算法也使用感知损失( perceptual loss)和GAN损失,但我们选择了去优化L1损失。
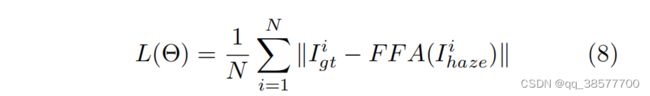
Θ 表示FFA-Net的参数 Igt 表示真实标签, Ihaze 表示输入。

5 实现细节
群结构G的个数是3。在每个组结构中,我们将基本块结构数设置为B=19。除信道关注度为1×1外,所有卷积层滤波器的大小均为3×3。除频道注意模块外,所有功能图都保持大小不变。每个组结构输出64个筛选器