深度学习中的Tensor 数据格式(N,C,H,W)
文章目录
- 深度学习中的Tensor 数据格式(N,C,H,W)
-
- 1、深度学习框架中的图像格式
-
- 1.1、4DTensor格式
- 1.2、5DTensor格式
- 1.3、ND格式
- 2、数据格式
- 3、物理存储
-
- 3.1、NCHW
- 3.2、NHWC
- 3.3、CHWN:
- 3.4、Strides
- 3.5、Blocked layout
- 3.6、zero_padding
- 4、RGB图像数据举例
- 5、不同框架的支持
深度学习中的Tensor 数据格式(N,C,H,W)
参考:
- Intel Math Kernel Library for Deep Neural Networks (Intel MKL-DNN)
- 数据格式- 图解NCHW与NHWC数据格式
- NCHW-NHWC-NC/32HW32
1、深度学习框架中的图像格式
1.1、4DTensor格式
4DTensor格式:使用4D张量描述符来定义具有4个字母的2D图像批处理的格式
- 数据布局由二维图像的四个字母表示:
- N:Batch,批处理大小,表示一个batch中的图像数量
- C:Channel,通道数,表示一张图像中的通道数
- H:Height,高度,表示图像垂直维度的像素数
- W:Width,宽度,表示图像水平维度的像素数
- 常用的4-D tensor 格式为:
- NCHW
- NHWC
- CHWN
- NC/32HW32
1.2、5DTensor格式
5D Tensor 格式:使用5个字母描述的3D图像批处理格式
- 数据布局由三位图像的5个字母表示:
- N:批处理大小
- C:channel,通道数
- D:深度,表示图像Z维度的特征图数目
- H:高度
- W:深度
1.3、ND格式
Numpy Ndarray: Numpy 最重要的一个特点是其N维数组对象ndarry,它是一系列同类型数据的集合,以0下标为开始进行集合中元素的索引。
tensor 和 ndarray 具有很高的相似性,并且二者相互转化需要的开销很小。但是由于 ndarray 出现时间较早,相比于 tensor 有更多更简便的方法,因此在某些时候 tensor 无法实现某些功能,可以将tensor 抓换为 ndarray 格式进行处理后,再转化为 tensor 格式。
pytorch tensor 数据和 numpy ndarray 数据格式相互转换
import numpy as np
# numpy to tensor
a = np.ones([2,3]) # [[1.,1.,1.],[1.,1.,1.]]
b = torch.from_numpy(a) # tensor([[1.,1.,1.],[1.,1.,1.]],dtype=torch.float64)
# tensor to numpy
a[0,1]=100 # [[1.,100.,1.],[1.,1.,1.]]
# 注意:转换后的 tensor 与 numpy 指向同一个地址,所以,对一方的改变,另一方也会随之改变
print(b) # tensor([[1.,100.,1.],[1.,1.,1.]],dtype=torch.float64)
c = b.numpy() # [[1.,100.,1.],[1.,1.,1.]]
2、数据格式
考虑4-D tensor数据格式,其中N=2,C=16,H=5,W=4,对应数据格式表示为

图中红色标注的数值就是数据里每个元素的数值:value(n,c,h,w) = n x CHW + c x HW + h x W + w
计算机中的数据是按照 1D 格式来存储的,要将 4D-tensor 映射到 1D memory中,要将 n,c,h,w 作为输入得到对应 value 值得位置(offset)
3、物理存储
不同的存储形式映射如下图所示:

3.1、NCHW
数据跳转:
- 先取W方向得一行数据,从左向右
- 然后H方向,从上向下
- 之后C方向(in depth)
- 最后N方向,从batch 中的一张图片(n=0) 跳转到下一张(n=1)
最终序列化出的1D数据为:000(W方向)001 002 003,(H方向)004 005 … 019, (C方向)020 … 318 319 , (N方向)320 321 …
offset_functoin: offset_nchw(n,c,h,w) = n x CHW + c x HW + h x W + w
【注意】这里为了方便说明,offset 和 value 值相等。
3.2、NHWC
数据跳转:先取C方向数据;然后W方向,然后H方向,最后N方向
最终序列化出的1D数据为:000(C方向)020 … 300, (W 方向)001 021 … 303, (H方向)004 … 319, (N方向)320 340 …
offset_function: offset_nhwc(n,c,h,w) = n x HWC + h x WC + w x C + c
3.3、CHWN:
数据跳转:先取N方向数据,然后W方向,然后H方向,然后C 方向
最终序列化出的1D数据为:000(N方向) 320,(W方向)001 321…(H方向)004 324 …019 339, (C 方向)020 340 …
offset_function: offset_chwn(n,c,h,w) = c x HWN + h x WN + w x N + n
3.4、Strides
上面的例子中数据是 packed 的,即表示像素之间是 dense 的。有时数据在memory 中不是连续存储的,例如有时需要选取较大的tensor 中的一个 sub-tensor 工作。有时需要人为的让数据不连续存储。
下图显示了以行为主格式保存的,大小为行 x 列的 2D 矩阵的简化情况,其中行具有一些 non-trivial (非平凡, 即不等于列数)步幅。

offset_function:offset(n,c,h,w) = n x stride_n + c x stride_c + h x stride_h + w x stride_w
注意,NCHW,NHWC,CHWN 格式都是 strides格式的特殊情况,如 NCHW 格式:
stride_n = CHW , stride_c = HW , stride_h = W, stride_w=1
3.5、Blocked layout
简单的layout便于灵活的数据使用,因此大多数框架和应用使用NCHW 或 NHWC layout。但是数据的应用场景不同,这些布局对应性能方面可能不是最优的。
为了实现更好的矢量化和缓存重用,Intel MKL-DNN 引入了 blocked layout,将一个或多个维度拆分成固定大小的块,如nChw8c、nChw16c 格式等。
如 nChw8c 格式,只有 channel 维度被分块,block size 为 8
offset_funciont :
offset_nChw8c(n,c,h,w) = n x CHW
+ (c / 8) x HW x 8
+ h x W x 8
+ w x 8 + c % 8
注意:8个channels 的block 在 memory 中是连续存储的。逐个像素地覆盖空间域。然后下一个 slice 覆盖随后的 8个channels(即从 c=0…7 移动到 c=8…15)。一旦覆盖了所有 channel blocks,就会出现 batch 中的下一个图像。
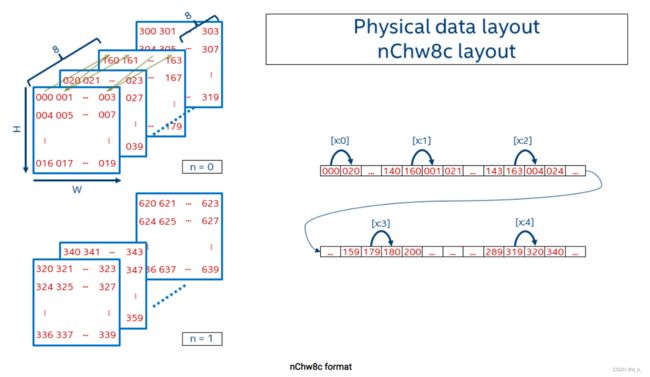
【注意】格式中使用小写和大写字母来却分块(如8c) 和 剩余的维度(C=channels/8)
3.6、zero_padding
**如果channels 不是8(或16)的整数倍 ,如channels=17—— zero padding **
方法:将 channels 数目向上取整为 block size 的整数倍,将padding tiles 的数值置为0( 24 = div_up(17,8) * 8 )。之后卷积之类的操作对向上取整的channels 进行操作( zero padding 不改变结果)。
支持任意数量的channels,并且几乎不改变 kernels。对zero padding 的额外计算开销忽略不计。
zero padding 的图示如下图所示:

4、RGB图像数据举例
表达 RGB 彩色图像时,一个像素的RGB值用3个数值表示,对应channel为3。假定N=1,则NCHW、NHWC数据格式可以存储为:

NCHW格式:
- 先在一个channel面上把W方向、H方向上元素存储起来 —— R
- 然后在另一个 channel 面上把W方向、H方向上元素存储起来 —— G
- 最后一个 channel 面上把W方向、H方向上元素存储起来 —— B
NHWC 格式:
- 先把3个channel 上第一个位置的元素存储起来 —— 一个像素的RGB
- 然后在 W方向上、H方向上依次将所有位置的元素存储起来 —— RGBRGBRGB…,即顺序地将每个像素的RGB数值存储起来
5、不同框架的支持
目前的主流ML 框架对 NCHW 和 NHWC 数据格式做了支持,有些框架可以支持两种且用户未作设置时有一个缺省值:
- TensorFlow:默认NHWC,GPU也支持 NCHW
- Caffe:NCHW
- PyTorch:NCHW