ElasticSearch 完全基础总结
目录
-
- 安装
-
- 目录
- 下载地址
- 应用场景介绍
- 安装 ElasticSearch
-
- 解压
- 配置JAVA环境
- 调整Linux 系统相关参数
- 创建用户
- ElasticSearch 配置
-
- 端口修改
- JVM 配置
- 应用配置
-
- URL的访问控制
- 自动创建索引配置
- 日志配置
-
- JSON 格式日志
- 远程恢复设置
- 高级远程恢复设置
- 启动
- Elasticsearch启动标志
- 安装ElasticSearch head
- 逻辑设计
-
- 文档
- 类型
- 索引
- Rest请求
-
-
- 回复结构
- curl
- JSON 复合查询 (增删改查)
-
- REST 方法说明
- 集群状态查询
-
- 检查集群健康状态
- 检查集群节点
- 检查集群中的索引信息
- 查询
-
- 过滤路径
- 开启查询trace
- 展开设置
- 查询索引名称携带的时间范围
- Body体查询索引下所有文档
- URL形式搜索API
- terms 精准查询
- 匹配查询
- 查询排序
- 修改日志级别
- mapping
- 过滤器
- bool
- 聚集
-
- 度量聚集
- 桶聚集
- 多桶聚集
- 分页
- 排序
- 过滤返回字段
- 删除文档
- 创建索引
- 删除索引
- 关闭索引
- 文档查询
-
- 查询文档
- 创建文档
- 更新文档
- 删除文档
- 批量操作
- 分析文本
- setting
- Fielddata
-
- 预加载 fielddata
- 全局序号(Global Ordinals)
- 预构建全局序号(Eager global ordinals)
- 可携带参数说明
- 特殊字段和占位符(预定义字段)
-
- 搜索的基本模块:
- 预定义字段
-
- 相关性搜索
-
- 打分机制
-
- TF-IDF
-
- 词频
- 逆文档词频
- 评分公式
- boosting
- Explain
- 再评分
- function_score 定制得分
- weight 函数
- field_value_factor 修改得分
-
- modifier 参数
- 脚本
- 随机
- 衰减得分
-
- 配置
- 请求示例
- 其他打分方法
-
- 全局配置
- 文档
-
- 基本读模型
- CURD
-
- 添加文档
- id自动生成
- 路由
- 嵌套关系
- 父子关系
- 对象
- 反规范化
- 集群
-
- 分片
- 副本
- 监控
-
- 查看集群健康状态
- 查看集群节点信息
- 停用节点
- _cat api
- 增加别名
- 分词器
-
- 分词过滤器
- N 元语法
- 配置
安装
本文讨论的都是ElasticSearch 7.0版本
目录
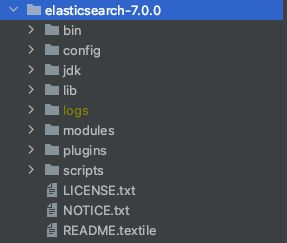
主要子文件夹简单介绍如下:
· bin:存放执行文件,例如启动脚本、密钥工具等。
· config:Elasticsearch所有的配置文件都在这个目录下。
· data:默认的索引数据存储位置,实际中一般需要自行更改。
· logs:默认的日志存放位置,实际中一般需要自行更改。
下载地址
ElasticSearch 7.0
ElasticSearch Head
上述ElasticSearch 7.0 是ElasticSearch的安装包,ElasticSearch Head 是ElasticSearch的操作工具。如果不习惯使用head可以使用kibana来操作管理es。
应用场景介绍
· 您经营一家网上商店,允许您的客户搜索您销售的产品。在这种情况下,您可以使用Elasticsearch存储整个产品目录和库存,并为他们提供搜索和搜索词自动补全功能。
· 您希望收集日志或事务数据,并且希望分析这些数据以发现其中的趋势、统计特性、摘要或反常现象。在这种情况下,您可以使用Logstash(Elastic Stack的一个组件)来收集、聚合和分析您的数据,然后使用Logstash将经过处理的数据导入Elasticsearch。一旦数据进入Elasticsearch,您就可以通过搜索和聚合来挖掘您感兴趣的任何信息。
· 您运行一个价格警报平台,它允许为对价格敏感的客户制定一个规则,例如,“我有兴趣购买特定的电子小工具,如果小工具的价格在下个月内低于任何供应商的某个价格,我希望得到通知”。在这种情况下,您可以获取供应商价格,将其推送到Elasticsearch,并使用其反向搜索(过滤,也就是范围查询)功能根据客户查询匹配价格变动,最终在找到匹配项后将警报推送给客户。
· 您有分析或商业智能需求,并且希望可以对大量数据(数百万或数十亿条记录)进行快速研究、分析、可视化并提出特定的问题。在这种情况下,您可以使用Elasticsearch来存储数据,然后使用Kibana(Elastic Stack的一部分)来构建自定义仪表盘(dashboard),以可视化对您重要的数据维度。此外,还可以使用Elasticsearch聚合功能对数据执行复杂的查询。
安装 ElasticSearch
解压
下载好文件之后,解压到相应目录。
配置JAVA环境
vi /etc/profile
# 在末尾添加如下内容,JAVA_HOME的值改成上一步解压得到的实际目录:
export JAVA_HOME=/opt/java/jdk1.8.0_18
export JRE_HOME=$ {JAVA_HOME}/jre
export CLASSPATH=.:$ {JAVA_HOME}/lib:$ {JRE_HOME}/lib:$ CLASSPATH
export JAVA_PATH=$ {JAVA_HOME}/bin:$ {JRE_HOME}/bin
export PATH=$ PATH:$ {JAVA_PATH}
# 刷新配置
source/etc/profile
# 验证
java -version
调整Linux 系统相关参数
①修改最大文件数和锁内存限制,打开文件/etc/security/limits.conf,增加或修改如下选项(elastic代表启动Elasticsearch集群的用户):
elastic - hard nproc unlimited
elastic - soft nproc unlimited
elastic - nofile 262144
elastic - memlock unlimited
elastic - fsize unlimited
elastic - as unlimited
②更改一个进程能拥有的最大内存区域限制,编辑(swappiness禁用交换区)/etc/sysctl.conf文件,新增或修改如下内容,保存后,执行sysctl-p。
vm.max_map_count=262144
vm.swappiness=1
③修改用户最大线程数,编辑/etc/security/limits.d/90-nproc.conf文件,增加或修改如下内容:
*soft nproc unlimited
root soft nproc unlimited
创建用户
es 不支持root用户启动
useradd elasticsearch
ElasticSearch 配置
Elasticsearch的配置文件都位于config目录中。其中有三个主要的配置文件:
· elasticsearch.yml是用于配置Elasticsearch的最主要的配置文件。
· jvm.options用于配置Elasticsearch JVM设置。
· log4j2.properties用于配置Elasticsearch日志记录的属性。
端口修改
默认是9200端口,可以在config/elasticsearch.yml中进行修改
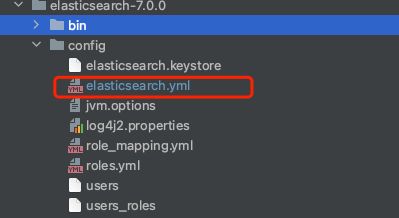
http.port: 9200
action.auto_create_index: true # 默认为true,是否自动创建索引,
JVM 配置
修改jvm.options,主要修改-Xms4g和-Xmx4g这两个参数就可以了,这个文件就是JVM的配置文件。
设置Java虚拟机选项的另一种机制是通过ES_JAVA_OPTS环境变量:
export ES_JAVA_OPTS="$ES_JAVA_OPTS-Djava.io.tmpdir=/path/to/temp/dir"
./bin/elasticsearch
此外,一些其他Java程序支持JAVA_OPTS环境变量,但这不是JVM中内置的机制,而是相关生态系统中的约定。但是,不推荐使用这个环境变量,更佳的方式是通过jvm.options文件或环境变量ES_JAVA_OPTS设置JVM选项。
应用配置
elasticsearch.yml
#各台必须设置成一样,Elasticsearch就是靠这个来识别集群的
cluster.name:elasticsearch-dev
#每个节点起一个名字,也可以不设置,采用默认
node.name:es1
transport.tcp.port:9300
http.port:9200
#下面两行就是对应的数据和日志的目录,最好提前建好
path.data:/opt/Elasticsearch/data
path.logs:/opt/Elasticsearch/logs
node.master:true
node.data:true
http.enabled:true
bootstrap.mlockall:true
discovery.zen.ping.unicast.hosts:
["10.202.259.2","10.202.259.3","10.202.259.4"]
discovery.zen.minimum_master_nodes:1
http.cors.enabled:true
http.cors.allow-origin:"*"
#以下centos6需设为false,因为Centos6不支持SecComp
bootstrap.memory_lock:false
bootstrap.system_call_filter:false
环境变量替换
node.name: $ {HOSTNAME}
network.host: $ {ES_NETWORK_HOST}
URL的访问控制
rest.action.multi.allow_explicit_index:false
默认值为true,但当设置为false时,Elasticsearch将拒绝请求主体中指定了显式索引的请求。
自动创建索引配置
自动创建索引由action.auto_create_index设置控制。此设置默认为true,这意味着索引总是自动创建的。也可以设置只有匹配特定模式的索引才允许自动创建索引,方法是将此设置的值更改为这些匹配模式的逗号分隔列表。还可以通过在列表中的模式前面加上+或-,明确地允许和禁止使用它。最后,通过将此设置更改为false,可以完全禁用它。

禁用操作:

打开自动创建索引:

索引操作还接受一个op_type参数,它可以用来强制create操作,允许put-if-absent的行为。使用create时,如果索引中已存在具有该ID的文档,则索引操作将失败。
可以这样来理解,当索引文档时,如果带有&op_type=true参数,明确指明是创建文档,如果文档存在就报错。默认情况下,当文档存在时直接覆盖。
日志配置
Elasticsearch使用log4j2进行日志记录。可以使用log4j2.properties文件配置log4j2。Elasticsearch公开了三个属性:${sys:es.logs.base_path}、${sys:es.logs.cluster_name}和${sys:es.logs.node_name},可以在配置文件中引用这些属性来确定日志文件的位置。属性${sys:es.logs.base_path}将解析为日志目录,${sys:es.logs.cluster_name}将解析为集群名称(在默认配置中用作日志文件名的前缀),而${sys:es.logs.node_name}将解析为节点名称(如果显式设置了节点名称)。
例如,如果日志目录(path.logs在elasticsearch.yml中定义)是/var/log/elasticsearch,并且集群名称为production,那么 s y s : e s . l o g s . b a s e p a t h 将解析为 / v a r / l o g / E l a s t i c s e a r c h , {sys:es.logs.base_path}将解析为/var/log/Elasticsearch, sys:es.logs.basepath将解析为/var/log/Elasticsearch,{sys:es.logs.base_path} s y s : f i l e . s e p a r a t o r {sys:file.separator} sys:file.separator{sys:es.logs.cluster_name}.log会解析为/var/log/Elasticsearch/production.log。
JSON 格式日志
appender.rolling.layout.type=ESJsonLayout
appender.rolling.layout.type_name=server
远程恢复设置
ccr.indices.recovery.max_bytes_per_sec
限制每个节点上的入站和出站远程恢复总流量。由于此限制适用于每个节点,但可能有许多节点同时执行远程恢复,因此远程恢复字节总数可能远远高于此限制。如果将此限制设置得太高,则存在这样的风险:正在进行的远程恢复将消耗过多的带宽(或其他资源),这可能会导致集群不稳定。此设置同时用于主集群和备用集群。例如,如果在主集群上设置为20MB,主集群将仅向备用集群每秒发送20MB,即使备用集群正在请求并可以每秒接受60MB。默认为40MB。
高级远程恢复设置
1 ccr.indices.recovery.max_concurrent_file_chunks?
2 ccr.indices.recovery.chunk_size
3 ccr.indices.recovery.recovery_activity_timeout
4 ccr.indices.recovery.internal_action_timeout
第1行,用来控制每次恢复可并行发送的文件块请求数。由于多个远程恢复可能已经并行运行,因此增加此专家级设置只在单个分片的远程恢复未达到由ccr.indexs.recovery.max_bytes_per_sec配置的入站和出站远程恢复总流量的情况下有帮助。默认值为5,最大允许值为10。
第2行,控制跟踪程序在文件传输过程中请求的块大小,默认为1MB。
第3行,控制恢复活动的超时,此超时主要应用于主集群。主集群必须在内存中打开资源,以便在恢复过程中向备用集群提供数据。如果主集群在这段时间内没有收到备用集群的恢复请求,那么它将关闭资源。默认为60s。
第4行,控制远程恢复过程中单个网络请求的超时,单个动作超时可能会使恢复失败。默认为60s。
启动
输入命令启动elasticsearch
cd elasticsearch-7.0.0 && sh elasticsearch -d
Elasticsearch启动标志
访问localhost:9200?pretty 出现下面放回即可。
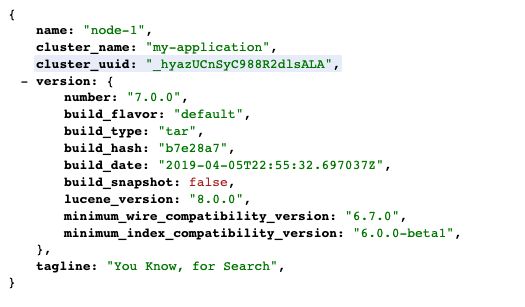
安装ElasticSearch head
前置环境
- node
进入到head根目录运行npm install然后执行npm run start。
访问 http://localhost:9100/

逻辑设计
以下没有特殊说明默认都是ElasticSearch 7.0版本的适配
文档
文档是索引和搜索数据的最小单位,文档具有 自我包含、层次、灵活的结构三种特性。ElasticSearch中文档是无模式的,也就是说并非所有的文档都需要拥有相同的字段。
类型
elasticsearch在7.x版本中移除了type
类型只提供逻辑上的分离。所有文档无论何种类型,都是存储在属于相同分片的同一组文件中。一份分片就是一个Lucene 的索引,类型的名称是Lucene索引中一个字段,所有映射的所有字段都是Lucene索引中的字段。
类型是ElasticSearch的一层抽象,单不属于lucene。索引中拥有不同类型的文档。Elasticsearch负责分离这些文档,例如,在某个类型中搜索时, Elasticsearch会过滤出属于那个类型的文档设置。
这种方法产生了一个问题:当多个类型中出现相同的字段名称时,两个同名的字段应该有同样的设置。否则,Elasticsearch将很难辨别你所指的是两个字段中的哪一个。最后,两个字段都是属于同 一个Lucene索引l。例如,如果在分组和活动文档中都有一个name字段,两中都应该是字符串类型, 不能一个是字符串而另一个是整数类型。在实际使用中,这种问题很少见,但是还是需要记住这一点 防止意外发生。
核心类型:
| 核心类型 | 说明 | 取值示例 |
|---|---|---|
| text | 字符串类型 | “allens”, “澄风” |
| number/long/float/double | 数值 | 17 |
| bool | 布尔类型 | true/false |
| date | 时间 | 2020-10-25 19:00:00 |
date 类型用于存储日期和时间。它是这样运作的:通常提供一个表示日期的字符串,例如2013-12-25T09:00:00。然后,Elasticsearch解析这个字符串,然后将其作为1ong的数值存入Lucene的索引。该1ong型数值是从1970年1月1日00:00:00UTC(UNIX纪元)到所提供的时间之间已经过去的毫秒数。
索引
索引(index)是具有某种相似特性的文档集合。例如,可以有存储客户数据的索引,存储产品目录的索引,以及存储订单数据的索引。索引由一个名称(必须全部是小写)标识,当对其中的文档执行索引、搜索、更新和删除操作时,该名称指向这个特定的索引。
在单个集群中,可以定义任意多个索引。
Rest请求
使用API执行的操作如下:
· 检查集群、节点和索引的运行状况、状态和统计信息。
· 管理集群、节点和索引数据和元数据。
· 对索引执行CRUD(创建、读取、更新和删除)和搜索操作。
· 执行高级搜索操作,如分页、排序、过滤、脚本、聚合和其他操作。

回复结构
第2行,took表示Elasticsearch执行搜索所用的时间,单位是ms。
第3行,timed_out用来指示搜索是否超时。
第4行,_shards指示搜索了多少分片,以及搜索成功和失败的分片的计数。
第10行,hits用来实际搜索结果集。
第11行,hits.total是包含与搜索条件匹配的文档总数信息的对象。
第12行,hits.total.value表示总命中计数的值(必须在hits.total.relation上下文中解释)。
第13行,确切来说,默认情况下,hits.total.value是不确切的命中计数,在这种情况下,当hits.total.relation的值是eq时,hits.total.value的值是准确计数。当hits.total.relation的值是gte时,hits.total.value的值是不准确的。
第16行,hits.hits是存储搜索结果的实际数组(默认为前10个文档)。
第35行,hits.sort表示结果排序键(如果请求中没有指定,则默认按分数排序)。
hits.total的准确性由请求参数
track_total_hits控制,当设置为true时,请求将准确跟踪总命中数(“relation”:“eq”)。它默认为10000,这意味着总命中数精确跟踪多达10000个文档,当结果集大于10000时,hits.total.value的值将是10000,也就是不准确的。可以通过将track_total_hits显式设置为true强制进行精确计数,但这会增大集群资源的开销。
curl
curl -XGET① “http://localhost:9200?pretty②” -d “{“field”:“value”}”
① -X的参数是HTTP方法,GET、POST、PUT、DELETE等等,默认是-XGET。
②如果没有指定协议默认是http
例子:
- curl -XPUT ‘localhost:9200/item/group/1?pretty’ -d ‘{“name”: “”}’
旧版es插入索引 - curl -XPUT ‘localhost:9200/item’
创建索引 - curl -XPUT ‘localhost:9200/item/_doc/1’ -d ‘{“name”:“xxx”}’
往索引中插入文档,在7.x版本中使用 - curl “localhost:9200/get-together,other-index/_search?q=es&pretty”
- curl ‘localhost:9200/get-together/group/search?pretty’-d ’ ‘
{"query": {"query string":{ "query":"elasticsearch"}}}’
字符串内容是"elasticsearch"。可能看上去这样输入elasticsearch过于公式化,但这是因为JSON提供更多选项而不仅仅是URI请求。 - curl ‘localhost:9200/get-together/_doc/1?pretty’ 查询一个具体的文档
JSON 复合查询 (增删改查)
REST 方法说明
- POST 更新 (如果文档没收手动传id使用post添加文档会自动创建id),也可以做查询操作
- GET 主要做查询
- PUT 增加
- DELETE 删除
集群状态查询
检查集群健康状态
curl-X GET"localhost:9200/_cat/health?v"
集群的健康状态有绿色(green)、黄色(yellow),红色(red)三种:
· 绿色:一切正常(集群功能全部可用)。
· 黄色:所有数据都可用,但某些副本尚未分配(集群完全正常工作)。
· 红色:由于某些原因,某些数据不可用(集群只有部分功能正常工作)。
检查集群节点
GET/_cat/nodes?v
检查集群中的索引信息
GET/_cat/indices?v
查询
- 所有REST API参数(请求参数和JSON主体)都支持布尔值false和true,所有其他值都将引发错误。
- 所有REST API都支持以字符串的形式提供数字参数。
过滤路径
- 想要看到的字段
GET/bank/_search?q=*&sort=account_number:asc&pretty&&filter_path=took,hits.hits._id,
hits.hits._score
可以在URL上指定参数filter_path来确定当前请求需要的数据以减少返回响应信息。
- 过滤排除字段
GET/_cluster/state?filter_path=metadata.indices.*.state,-metadata.indices.logstash-*
- 指定原始字段
GET/_search?filter_path=hits.hits._source&_source=title&sort=rating:desc
开启查询trace
POST/bank/_search?size=surprise_me&error_trace=true
展开设置
GET bank/_settings?flat_settings=true

查询索引名称携带的时间范围
![]()
Body体查询索引下所有文档
http://localhost:9200/product/_search/
{
"query": {
"match_all": {}
},
"sort": [
"account_number": { "order": "asc"}
],
"from": 10,
"size": 20,
"_source": ["account_number", "balance"]
}
_source 返回源中指定的几个字段
from offset 从第多少条开始
size 分页大小
URL形式搜索API
执行搜索有两种基本方法:一种是通过REST请求URI发送搜索参数,另一种是通过REST请求主体(body形式)发送搜索参数。请求主体方法表现形式更强大,用更可读的JSON格式定义搜索。现在尝试一个请求URI方法的示例,但在本书的其余部分中,将专门使用请求主体方法。
GET/bank/_search?q=*&sort=account_number:asc&pretty
terms 精准查询
term是代表完全匹配,即不进行分词器分析,文档中必须包含整个搜索的词汇
如果想在字段中只查询name字段值中是否匹配:

进一步优化查询,因为是精准查询,不需要查询进行评分计算,只希望对文档进行包括或排除的计算,所以我们会使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分。推荐如下查询:
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"biz_id" : "1909190023901225"
}
}
}
}
}
terms多值情况:
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"biz_id" : ["1909190023901225","e1909190111365113"]
}
}
}
}
}
terms多个字段
{
"query": [{
"term": {
"biz_id": "1909190023901225"
}
}, {
"term": {
"name": "zhangsan"
}
}]
}
还可以在查询字符串中指定字段和操作符:
"query": "name:elasticsearch AND name:san AND name:fran"
term 查询
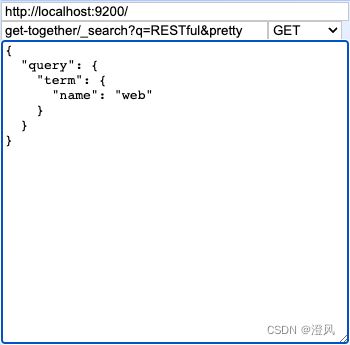
过滤字段

匹配查询
进行full text search或者exact value(非string字段或not_analyzed的字段),进行匹配,会对要查询的内容进行分词。
如es中存的merchant_id的值为"2500,2501,2502",按照逗号分词。match匹配时查询参数值param=“2500,2502”,会对param进行分词,分为2500和2502,对merchant_id的值进行匹配,默认是是or,即或者的关系,匹配任意一个分词,就返回数据结果
POST
{
"query": {
"match": {
"merchant_id": "2500,2502"
}
},
"sort": [
{
"trade_finished_time": {
"order": "desc"
}
}
]
}
match_all
{ “match_all”: {}} 匹配所有的, 当不给查询条件时,默认全查,匹配所有字段。
POST
{
"query": {
"match_all": {}
}
}
multi_match
POST
{
"query":{
"multi_match":{
"query":"2501",
"fields":["merchant_id","_id"]
}
}
}
在在fields中,按brandName(品牌名)、sortName(分类名)、productName(商品名)productKeyword(商品关键字),搜索“牛仔 弹力”关键词,brandName源值、拼音值、关键字值都是100分,sortName源值、拼音值80分,productName源值60分,productKeyword值20分,分值由高到低优先级搜索
{
"query": {
"multi_match": {
"query": "牛仔 弹力",
"fields": [
"brandName^100",
"brandName.brandName_pinyin^100",
"brandName.brandName_keyword^100",
"sortName^80",
"sortName.sortName_pinyin^80",
"productName^60",
"productKeyword^20"
],
"type": <multi-match-type>,
"operator": "AND"
}
}
}
match_phrase
match_phrase查询分析文本,并从分析文本中创建短语查询。
类似 match 查询, match_phrase 查询首先将查询字符串解析成一个词项列表,然后对这些词项进行搜索,但只保留那些包含全部搜索词项,且位置与搜索词项相同的文档。
即对给定的短语完整查询匹配,搜索到的结果集都必须包含给定的查询词组
如下,查询 quick brown、quick brown fox、 brown fox可以查询到,quick fox 查询不到
{
"query": {
"match_phrase": {
"title": "quick brown fox"
}
}
}
如下, 查询 a,b,a和b之间隔3个字符可以查询到,隔不是3个查询不到
{
"query":{
"match_phrase" :{
"query":"a,b",
"slop":3
}
}
}
match_phrase_prefix
左前缀匹配,类似sql中的 like ‘zhang%’
如查询姓张的同学有哪些,zhang san,zhang san feng,都能返回结果集
{
"query": {
"match_phrase_prefix": {
"name": "zhang"
}
}
}
查询排序
查询商户ID为3582,订单号为360102199003072618,按时间范围过滤,按下单时间倒序,每次查询100条。
{
"query": {
"bool": {
"must": [{
"term": {
"merchant_id": "3582"
}
}, {
"term": {
"order_num": "360102199003072618"
}
}],
"filter": [{
"range": {
"order_time": {
"from": "2019-11-01T17:00:00+08:00",
"to": "2019-11-01T20:00:00+08:00"
}
}
}]
}
},
"size": 100,
"sort": [{
"order_time": "desc"
}]
}
修改日志级别
PUT /_cluster/settings
{
"transient": {
"" : ""
}
}
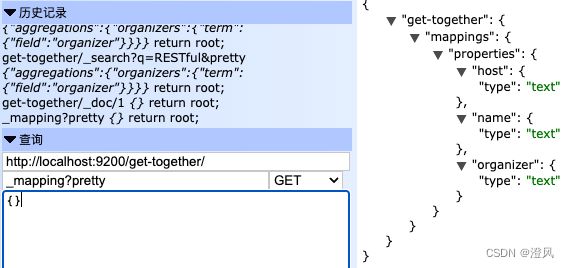
mapping
查询mapping定义
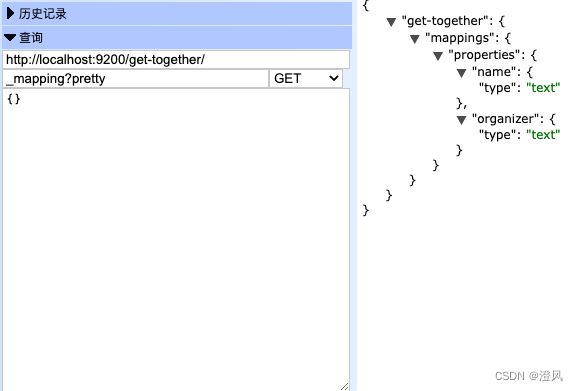
合并Elastic Mapping

这里会合并新加入的字段到mapping中
是否使用索引
-XPUT
{
"properties": {
"some": {
"type": "text",
"index": true # false 不适用索引
}
}
}
默认情况下,index被设置为analyzed,并产生了之前看到的行为:分析器将所有字符转为小写,并将字符串分解为单词。当期望每个单词完整匹配时,请使用这种选项。举个例子,如果用户搜索“elasticsearch”,他们希望在结果列表里看到“Late Night with Elasticsearch”。
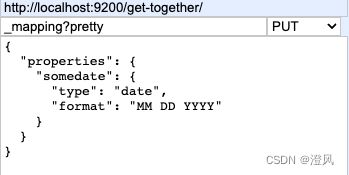
将index设置为not_analyzed,将会产生相反的行为:分析过程被略过,整个字符串被当作单独的词条进行索引。当进行精准的匹配时,请使用这个选项,如搜索标签。你可能希望“big data”出现在搜索“big data”的结果中,而不是出现在搜索“data”的结果中。同样,对于多数的词条计数聚集,也需要这个。如果想知道最常出现的标签,可能需要“big data”作为一整个词条统计,而不是“big”和“data”分开统计。第7章将探讨聚集。
如果将index设置为no,索引就被略过了,也没有词条产生,因此无法在那个字段上进行搜索。当无须在这个字段上搜索时,这个选项节省了存储空间,也缩短了索引和搜索的时间。例如,可以存储活动的评论。尽管存储和展示这些评论是很有价值的,但是可能并不需要搜索它们。在这种情况下,关闭那个字段的索引,使得索引的过程更快,并节省了存储空间。
date
数组

使用include_in_all的选项,将赋予你更高的灵活性。灵活性不仅体现在空间存储上,同样体现在查询的表现方式上。如果一次搜索在没有指定字段的情形下运行,Elasticsearch只会匹配all所包含的字段。
过滤器
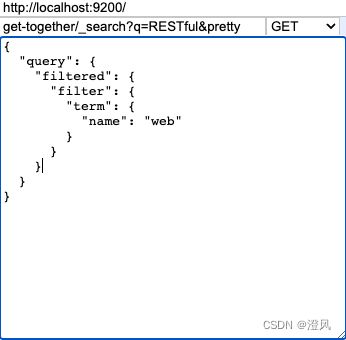
过滤查询已被弃用,并在ES 5.0中删除。
可以使用bool / must / filter查询

"bool" : {
"must" : [],//与 AND 等价。
"should" : [],//与 NOT 等价
"must_not" : [],//与 OR 等价
"filter": //不会参与评分
}
bool

GET /bank/_sarch
{
"query": {
"bool": {
"must": [
{
"match": {
"address": "mill"
}
}
],
"must_not": [
{"match": {"state": "ID"}}
],
"filter": {"range": {"balance": {"gte": 20000, "lte": 30000}}}
}
}
}
查询和过滤在功能上是相同的,只不过过滤不计算相似度得分,性能更高。
must 中必须所有条件都成立才能被查询到
should 只要其中一个为真即可
must_not 字面意思
聚集
Elasticsearch聚集查询
Elasticsearch聚合 之 Terms
聚集分为:度量聚集和桶聚集
按年龄段(20~29岁、30~39岁和40~49岁)进行分组,然后再按性别(gender.keyword)分组,最后得到每个年龄段每个性别的账户平均余额
{
"aggs": {
"group_by_age": {
"range": {
"field": "age",
"ranges": [
{
"from": 20,
"to": 30
},
{
"from": 30,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_gender": {
"terms": {
"field": "gender.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
}
}
度量聚集

获取活动参与者数量的统计数据

桶聚集
如果使用SQL语言类比,桶型聚集与SQL语句中的group by子句极为相似。桶型聚集(Bucket Aggregation)是Elasticsearch官方对这种聚集的叫法,它起的作用是根据条件对文档进行分组。读者可以将这里的桶理理解为分组的容器,每个桶都与一个分组标准相关联,满足这个分组标准的文档会落入桶中。所以在默认情况下,桶型聚集会根据分组标准返回所有分组,同时还会通过doc_count字段返回每一桶中的文档数量。
由于单纯使用桶型聚集只返回桶内文档数量,意义并不大,所以多数情况下都是将桶型聚集与指标聚集以父子关系的形式组合在一起使用。桶型聚集作为父聚集起到分组的作用,而指标聚集则以子聚集的形式出现在桶型聚集中,起到分组统计的作用。比如将用户按性别分组,然后统计他们的平均年龄。
按返回桶的数量来看,桶型聚集可以分为单桶聚集和多桶聚集。在多桶聚集中,有些桶的数量是固定的,而有些桶的数量则是在运算时动态决定。由于桶型聚集基本都是将所有桶一次返回,而如果在一个聚集中返回了过多的桶会影响性能,所以单个请求允许返回的最大桶数受search.max_bucket参数限制。这个参数在7.0之前的版本中默认值为-1,代表没有上限。但在Elasticsearch版本7中,这个参数的默认值已经更改为10000。所以在做桶型聚集时要先做好数据验证,防止桶数量过多影响性能。
多桶聚集
- terms
- range
- histogram

分页
GET
[index]/_search?from=10&size=10
POST
[index]/_search
{
"query": {"match_all": {}},
"from": 10,
"size": 10
}
排序
GET
[index]/_search?sort=date:asc
POST
[index]/_search
{
"query": {"match_all": {}},
"sort": [
{"created_on": "asc"}, // 先按照创建时间来排序
{"name": "desc"}, // 然后按照名称来排序
{"_score"} // 最终按照相关性得分来排序
]
}
过滤返回字段
POST/GET
[index]/_search?pretty
{
"query": {"match_all": {}},
"_source":["name", "date"]
}
# 过滤
POST/GET
[index]/_search?pretty
{
"query": {"match_all": {}},
"_source":[
"include": ["location.*", "date"],
"exclude": ["location.geolocation"]
]
}
删除文档
有几种方式移除单个文档,这里讨论主要的几个。
- 通过ID删除单个文档。如果只有一篇文档要删除,而且你知道它的ID,这样做非常 不错。
- 在单个请求中删除多篇文档。如果有多篇文档需要删除,可以在一个批量请求中一次性 删除它们,这样比每次只删除一篇文档更快。
- 删除映射类型,包括其中的文档。这样的操作会高效地搜索并删除该类型中所索引的全 部文档,也包括映射本身。
- 删除匹配某个查询的所有文档。这和删除映射类型相似,内部运行一个查询,并识别需 要删除的文档。只有在这里可以指定任何想要的查询,然后删除匹配的文档。
创建索引
PUT/customer?pretty
GET/_cat/indices?v
第一个命令使用PUT方法创建名为customer的索引。在调用的末尾附加pretty命令,就可以打印友好JSON响应。
第二个命令的结果告诉用户,现在有一个名为customer的索引,它有一个分片和一个副本(默认值),其中包含零个文档。
删除索引
curl -X DELETE http://localhost:9200/xxxIndex
关闭索引
一旦索引被关闭,它在Elasticsearch内存中唯一的痕迹是其元数据。如果有足够的的磁盘空间,关闭缩影要比删除索引更好。关闭他们会让你非常安心,永远可以重新打开被关闭的索引。
文档查询
查询文档
GET/customer/_doc/1?pretty
创建文档
put /customer/_doc/1?pretty
{
"name": "John Doe"
}
索引时,ID部分是可选的。如果没有指定,Elasticsearch将生成一个随机ID,然后使用它为文档编制索引。Elasticsearch生成的实际ID(或在前面的示例中显式指定的任何内容)作为索引API调用的一部分返回。
更新文档
post /customer/_update/1?pretty
{
"doc": {"name": "xxxx", "age": 100}
}
脚本执行更新
使用简单的脚本执行更新。下面示例使用脚本将年龄增加5
post /customer/_update/1?pretty
{
"script": "ctx._source.age+=5"
}
Elasticsearch除了能够索引和替换文档外,还可以更新文档。Elasticsearch实际上并不是进行就地更新,每当进行更新时,Elasticsearch会删除旧文档,然后索引一个新文档,但这对用户来说是一次调用。实际上Elasticsearch的数据存储结构决定了其不能像关系数据库那样进行字段级的更新,所有的更新都是先删除旧文档,再插入一条新文档,但这个过程对用户来说是透明的。
删除文档
DELETE /customer/_doc/2?pretty
批量操作
调用在一个批量操作中索引两个文档(ID 1-John Doe和ID 2-Jane Doe)
POST/customer/_bulk?pretty
{"index":{"_id":"1"}}
{"name":"John Doe"}
{"index":{"_id":"2"}}
{"name":"Jane Doe"}
更新第一个文档(ID为1),然后在一个批量操作中删除第二个文档(ID为2)
POST/customer/_bulk?pretty
{"update":{"_id":"1"}}
{"doc":{"name":"John Doe becomes Jane Doe"}}
{"delete":{"_id":"2"}}
分析文本
使用标准分词器
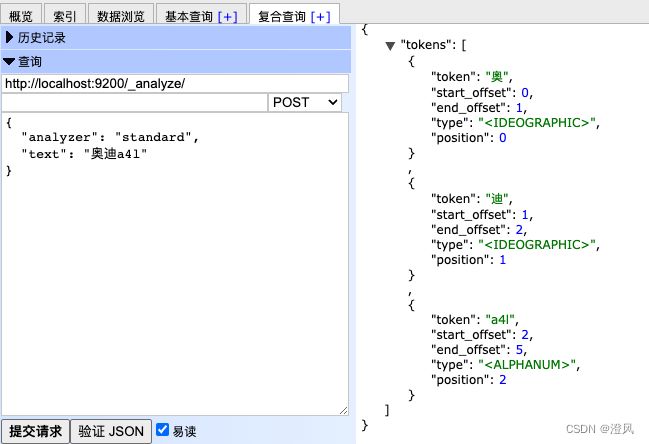
使用IK分词器
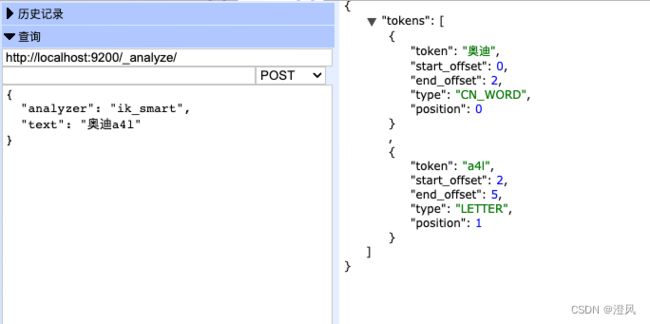
setting
获取索引setting,下面是配置信息
curl -XGET "http://localhost:9200/xxxIndex/_settings"
{
"mess1":{
"settings":{
"index":{
"number_of_shards":"1",
"provided_name":"mess1",
"creation_date":"1656573019168",
"analysis":{
"filter":{
"my-synonym-filter":{
"type":"synonym",
"expand":"true",
"synonyms":[
"automobile=>car"
]
}
},
"analyzer":{
"synonyms":{
"filter":[
"my-synonym-filter"
],
"type":"custom",
"tokenizer":"ik_smart"
}
}
},
"number_of_replicas":"1",
"uuid":"K4W3bOfpTaWt1f1iDFCUAg",
"version":{
"created":"7000099"
}
}
}
}
}
settings部分主要包括:分片数,副本数,刷新间隔,分析器
PUT index_test
{
"settings":{
// 设置索引分片数,默认为1,只能在创建索引时设置,之后任何时候都不能修改
"number_of_shards": 3,
// 设置索引分片副本数,默认为1,之后可以任意修改
"number_of_replicas": 1,
// 刷新间隔,默认1s,近实时,文档从索引到可以被检索中间间隔就是这个值
"refresh_interval": "1s",
// 分析器
"analysis":{
"analyzer":{
// 自定义分析器
"ik_pinyin_analyzer":{
"type":"custom",
"char_filter":[
"emoticons"
],
"tokenizer":"ik_max_word",
"filter":[
"pinyin_filter"
]
}
},
// 字符过滤器
"char_filter":{
"emoticons":{
"type":"mapping",
"mappings":[
":) => _happy_",
":( => _sad_"
]
}
},
// 分词器
"tokenizer":{
"punctuation":{
"type":"pattern",
"pattern":"[ .,!?]"
}
},
// token过滤器
"filter":{
"pinyin_filter":{
"type":"pinyin",
"keep_original":true
}
}
}
}
}
当索引处于打开状态时,无法更新索引的设置。需要关闭索引并更新设置并打开索引。
Fielddata
预加载 fielddata
Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
对于小索引段来说,这个过程的需要的时间可以忽略。但如果我们有一些 5 GB 的索引段,并希望加载 10 GB 的 fielddata 到内存中,这个过程可能会要数十秒。 已经习惯亚秒响应的用户很难会接受停顿数秒卡着没反应的网站。
有三种方式可以解决这个延时高峰:
- 预加载 fielddata
- 预加载全局序号
- 缓存预热
所有的变化都基于同一概念:预加载 fielddata ,这样在用户进行搜索时就不会碰到延迟高峰。
预加载 fielddata(Eagerly Loading Fielddata)
第一个工具称为 预加载 (与默认的 延迟加载相对)。随着新分段的创建(通过刷新、写入或合并等方式), 启动字段预加载可以使那些对搜索不可见的分段里的 fielddata 提前 加载。
这就意味着首次命中分段的查询不需要促发 fielddata 的加载,因为 fielddata 已经被载入到内存。避免了用户遇到搜索卡顿的情形。
预加载是按字段启用的,所以我们可以控制具体哪个字段可以预先加载:
PUT /music/_mapping/_song
{
"tags": {
"type": "string",
"fielddata": {
"loading" : "eager"
}
}
}
设置 fielddata.loading: eager 可以告诉 Elasticsearch 预先将此字段的内容载入内存中。
Fielddata 的载入可以使用 update-mapping API 对已有字段设置 lazy 或 eager 两种模式。
预加载只是简单的将载入 fielddata 的代价转移到索引刷新的时候,而不是查询时,从而大大提高了搜索体验。
体积大的索引段会比体积小的索引段需要更长的刷新时间。通常,体积大的索引段是由那些已经对查询可见的小分段合并而成的,所以较慢的刷新时间也不是很重要。
全局序号(Global Ordinals)
有种可以用来降低字符串 fielddata 内存使用的技术叫做 序号 。
设想我们有十亿文档,每个文档都有自己的 status 状态字段,状态总共有三种: status_pending 、 status_published 、 status_deleted 。如果我们为每个文档都保留其状态的完整字符串形式,那么每个文档就需要使用 14 到 16 字节,或总共 15 GB。
取而代之的是我们可以指定三个不同的字符串,对其排序、编号:0,1,2。
| Ordinal | Term |
|---|---|
| 0 | status_deleted |
| 1 | status_pending |
| 2 | status_published |
序号字符串在序号列表中只存储一次,每个文档只要使用数值编号的序号来替代它原始的值。
| Doc | Ordinal |
|---|---|
| 0 | 1 # pending |
| 1 | 1 # pending |
| 2 | 2 # published |
| 3 | 0 # deleted |
这样可以将内存使用从 15 GB 降到 1 GB 以下!
但这里有个问题,记得 fielddata 是按分 段 来缓存的。如果一个分段只包含两个状态( status_deleted 和 status_published )。那么结果中的序号(0 和 1)就会与包含所有三个状态的分段不一样。
如果我们尝试对 status 字段运行 terms 聚合,我们需要对实际字符串的值进行聚合,也就是说我们需要识别所有分段中相同的值。一个简单粗暴的方式就是对每个分段执行聚合操作,返回每个分段的字符串值,再将它们归纳得出完整的结果。 尽管这样做可行,但会很慢而且大量消耗 CPU。
取而代之的是使用一个被称为 全局序号 的结构。 全局序号是一个构建在 fielddata 之上的数据结构,它只占用少量内存。唯一值是 跨所有分段 识别的,然后将它们存入一个序号列表中,正如我们描述过的那样。
现在, terms 聚合可以对全局序号进行聚合操作,将序号转换成真实字符串值的过程只会在聚合结束时发生一次。这会将聚合(和排序)的性能提高三到四倍。
构建全局序号(Building global ordinals)
当然,天下没有免费的晚餐。 全局序号分布在索引的所有段中,所以如果新增或删除一个分段时,需要对全局序号进行重建。 重建需要读取每个分段的每个唯一项,基数越高(即存在更多的唯一项)这个过程会越长。
全局序号是构建在内存 fielddata 和 doc values 之上的。实际上,它们正是 doc values 性能表现不错的一个主要原因。
和 fielddata 加载一样,全局序号默认也是延迟构建的。首个需要访问索引内 fielddata 的请求会促发全局序号的构建。由于字段的基数不同,这会导致给用户带来显著延迟这一糟糕结果。一旦全局序号发生重建,仍会使用旧的全局序号,直到索引中的分段产生变化:在刷新、写入或合并之后。
预构建全局序号(Eager global ordinals)
单个字符串字段 可以通过配置预先构建全局序号:
PUT /music/_mapping/_song
{
"song_title": {
"type": "string",
"fielddata": {
"loading" : "eager_global_ordinals"
}
}
}
设置 eager_global_ordinals 也暗示着 fielddata 是预加载的。
正如 fielddata 的预加载一样,预构建全局序号发生在新分段对于搜索可见之前。
序号的构建只被应用于字符串。数值信息(integers(整数)、geopoints(地理经纬度)、dates(日期)等等)不需要使用序号映射,因为这些值自己本质上就是序号映射。
因此,我们只能为字符串字段预构建其全局序号。
也可以对 Doc values 进行全局序号预构建:
PUT /music/_mapping/_song
{
"song_title": {
"type": "string",
"doc_values": true,
"fielddata": {
"loading" : "eager_global_ordinals"
}
}
}
这种情况下,fielddata 没有载入到内存中,而是 doc values 被载入到文件系统缓存中。
与 fielddata 预加载不一样,预建全局序号会对数据的 实时性 产生影响,构建一个高基数的全局序号会使一个刷新延时数秒。 选择在于是每次刷新时付出代价,还是在刷新后的第一次查询时。如果经常索引而查询较少,那么在查询时付出代价要比每次刷新时要好。如果写大于读,那么在选择在查询时重建全局序号将会是一个更好的选择。
针对实际场景优化全局序号的重建频次。如果我们有高基数字段需要花数秒钟重建,增加 refresh_interval 的刷新的时间从而可以使我们的全局序号保留更长的有效期,这也会节省 CPU 资源,因为我们重建的频次下降了。
索引预热器(Index Warmers)
最后我们谈谈 索引预热器 。预热器早于 fielddata 预加载和全局序号预加载之前出现,它们仍然有其存在的理由。一个索引预热器允许我们指定一个查询和聚合须要在新分片对于搜索可见之前执行。 这个想法是通过预先填充或 预热缓存 让用户永远无法遇到延迟的波峰。
原来,预热器最重要的用法是确保 fielddata 被预先加载,因为这通常是最耗时的一步。现在可以通过前面讨论的那些技术来更好的控制它,但是预热器还是可以用来预建过滤器缓存,当然我们也还是能选择用它来预加载 fielddata。
让我们注册一个预热器然后解释发生了什么:
PUT /music/_warmer/warmer_1
{
"query" : {
"bool" : {
"filter" : {
"bool": {
"should": [
{ "term": { "tag": "rock" }},
{ "term": { "tag": "hiphop" }},
{ "term": { "tag": "electronics" }}
]
}
}
}
},
"aggs" : {
"price" : {
"histogram" : {
"field" : "price",
"interval" : 10
}
}
}
}
预热器被关联到索引( music )上,使用接入口 _warmer 以及 ID ( warmer_1 )。
为三种最受欢迎的曲风预建过滤器缓存。
字段 price 的 fielddata 和全局序号会被预加载。
预热器是根据具体索引注册的, 每个预热器都有唯一的 ID ,因为每个索引可能有多个预热器。
然后我们可以指定查询,任何查询。它可以包括查询、过滤器、聚合、排序值、脚本,任何有效的查询表达式都毫不夸张。 这里的目的是想注册那些可以代表用户产生流量压力的查询,从而将合适的内容载入缓存。
当新建一个分段时,Elasticsearch 将会执行注册在预热器中的查询。执行这些查询会强制加载缓存,只有在所有预热器执行完,这个分段才会对搜索可见。
与预加载类似,预热器只是将冷缓存的代价转移到刷新的时候。当注册预热器时,做出明智的决定十分重要。 为了确保每个缓存都被读入,我们 可以 加入上千的预热器,但这也会使新分段对于搜索可见的时间急剧上升。
实际中,我们会选择少量代表大多数用户的查询,然后注册它们。
可携带参数说明
pretty 格式化返回结果
timeout 指定超时时间,如果超时了返回结果中timeout为true,默认情况下搜索永远不会超时
- elasticsearch在7.x版本中移除了type
- 到了6.X就彻底移除string,现在都采用text

{
"took":383, // es花费了多久进行处理请求,时间单位ms
"timed_out":false, // 是否请求超时
"_shards":{ // 分片
"total":1, // 总共有1个分片
"successful":1,
"skipped":0,
"failed":0
},
"hits":{ // 命中
"total":{ // 命中统计
"value":1, // 命中了一个doc
"relation":"eq"
},
"max_score":0.29161495, // 匹配分数
"hits":[
{
"_index":"get-together",
"_type":"_doc",
"_id":"1",
"_score":0.29161495,
"_source":{
"organizer":1,
"name":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。"
}
}
]
}
}
定义搜索返回的文档得分,是该文档和给定搜索条件的相关性衡量。得分默认是通过TF-DF(词频-逆文档频率)算法进行计算的。词频意味着对于搜索的每个词条(单词),其在某篇文档中出现的次数越多则该文档的得分就越高。逆文档频率味着如果该词条在整个文档集合中出现 在越少的文档中则该文档得分越高,原因是我们会认为词条和这篇文档的相关度更高。如果词条经常在 其他文档中出现,它可能就是一个常见词,相关性更低。
当一个节点宕机而且一份分片无法回复搜索请求的时候会发生下面图述的流程。
特殊字段和占位符(预定义字段)
搜索的基本模块:
querysize代表返回文档的数量from用于分页,和from一起是一个。- _source 指定_source字段如何返回
- sort 默认排序是基于文档的得分
预定义字段
_all 表示全部索引
curl 'localhost:9200/_all/_search?q=es&pretty'
_source 如果不需要指定返回哪些字段可以通过_source进行指定返回

_index
_doc
_ttl
_uid _id和_type字段组成
相关性搜索
打分机制
一开始的时候,仅仅以二元的方式来考虑文档和查询的匹配可能也是有意义的,也就是“是的,匹配了”或“不,没有匹配”。尽管如此,考虑文档的相关性(relevancy)匹配可能是更加合理的。在用户可以说出一个文档是否匹配(二元方式)之前,如果能够说出对于某个查询而言,文档A比文档B更优,那么就更为精确了。例如,当使用最喜欢的搜索引擎来搜索“elasticsearch”
的时候,如果系统告诉你一个特定的页面因为包含这个词条而命中,那么这一点是远远不够的。相反地,你希望结果是根据最佳相关性来排序的。
确定文档和查询有多么相关的过程被称为打分(scoring)。尽管精确地理解Elasticsearch是如何计算文档得分这一点并不是必需的,但是对于如何使用Elasticsearch而言,它仍然是非常有帮助的。
TF-IDF
一个词条在某个文档出现的次数越多他就越相关,如果该词条在不同文档出现次数越多他就越不相关。
词频
一个词条在文本中出现的次数
逆文档词频
如果一个分词在不同文档中出现的次数越多,它就越不重要。
评分公式
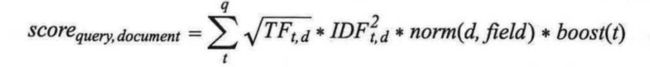
给定查询q和文档d,其得分是查询中每个词条的得分总和。而每个词条的得分是该词在文档d中的词频平方根,乘以该词逆文档频率的平方和,乘以该文档字段的归一化因子,衬衣盖茨的提升权重。
说起来太绕口了!别担心,使用Elasticsearch时没有必要记住这个公式。在这里提供这个公式,只是让用户理解这个公式是如何计算的。核心部分是理解某个词条的词频和逆文档频率是如何影响文档的得分,以及它们是如何在整体上决定Elasticsearch索引中一篇文档的得分。
词条的词频越高,得分越高;相似地,索引中词条越罕见,逆文档频率越高。尽管 TF-IDF的介绍已经结束了,Lucene默认评分功能的介绍却并没有结束。还有两点没有提及:调和因子和查询标准化。调和因子考虑了搜索过多少文档以及发现了多少词条。查询标准化是试图让不同查询的结果具有可比性。显然这是很困难的,而且实际上也不应该比较不同查询所产生的得分。这种默认的打分方法是TF-IDF和向量空间模型(vector space model)的结合。
如果用户对此很感兴趣,推荐你查阅 Lucene 文档中 org.apache.lucene.search.
similarities.TFIDFSimilarity Java类的 Javadoc。
词条的词频越高,得分越高;相似地,索引中词条越罕见,逆文档频率越高。尽管 TF-IDF的介绍已经结束了,Lucene默认评分功能的介绍却并没有结束。还有两点没有提及:调和因子和查询标准化。调和因子考虑了搜索过多少文档以及发现了多少词条。查询标准化是试图让不同查询的结果具有可比性。显然这是很困难的,而且实际上也不应该比较不同查询所产生的得分。这种默认的打分方法是TF-IDF和向量空间模型(vector space model)的结合。
如果用户对此很感兴趣,推荐你查阅 Lucene文档中org.apache.lucene.search.
similarities.TFIDFSimilarity Java类的Javadoc。
boosting
http://localhost:9200/get-together/_search
POST
{
"query": {
"bool": {
"should": [
{
"match": {
"name": {
"query": "elasticsearch big data",
"boost": 2.5
}
}
}
]
}
}
}


Explain

再评分
function_score 定制得分
weight 函数


field_value_factor 修改得分

modifier 参数
log/log1p/log2p/ln1p/ln2p/square/sqrt/reciprocal
脚本

随机

衰减得分
配置
请求示例

其他打分方法
Okapi BM25

关于BM25的完整评分公式的内容超出了本书的讨论范围。 BM25有3种主要的设置,即k1、b和discount overlaps。
- k1和b是数值的设置,用于调整得分是如何计算的。
- k1控制对于得分而言词频(词条出现在文档里的频繁程度,或者是之前章节提到的T℉) 的重要性。
- b是介于0到1之间的数值,它控制了文档篇幅对于得分的影响程度。
- 默认情况下,k1被设置为1.2,而b被设置为0.75。
- discount overlaps的设置可以用于告知Elasticsearch,在某个字段中,多个分词出 现在同一个位置,是否应该影响长度的标准化。默认值是true。
全局配置
index.similarity.default.type: BM25
文档
Elasticsearch中的每个索引操作首先使用路由(通常基于文档ID)解析到一个复制组。一旦确定了复制组,该操作将在内部转发到该组的当前primary。primary负责验证操作并将其转发到其他replica。由于replica可以离线,因此不需要primary复制到所有replica。相反,Elasticsearch维护一个应该完成接收操作的replica列表,此列表称为同步副本组,由主节点维护。顾名思义,这些是一组“好”的分片拷贝,保证已经处理了所有的索引和删除操作,这些操作已经被用户确认。primary负责维护这个不变量,因此必须将所有操作复制到这个同步副本组中的每个replica。
primary遵循以下基本流程:
①验证传入操作,如果结构无效则拒绝该操作。例如,向一个数字字段传输一个对象类型。
②在本地执行操作,即索引或删除相关文档。这还将验证字段的内容,并在需要时拒绝。例如,关键字值对于Lucene中的索引而言太长了。
③将操作转发到当前同步副本组中的每个replica,如果有多个replica,这是并行完成的。
④一旦所有replica都成功地执行了操作并对primary作出了响应,primary就确认完成了请求并返回给用户。
基本读模型
Elasticsearch中的读取可以是非常轻量的按ID查找,也可以是一个具有复杂聚合的繁重搜索请求,这些聚合需要非常大的CPU能力。主备(primary-backup)模型的一个优点是它保持所有的分片(primary和replica)是等同的。因此,单个同步拷贝(称之为相关分片组)就足以满足读取请求。
当节点接收到读取请求时,该节点负责将其转发到保存相关分片的节点整理响应,并向客户机返回结果。该节点被称为该请求的协调节点。基本流程如下:
①将读取请求解析到相关分片组。注意,由于大多数搜索将被发送到一个或多个索引,所以它们通常需要从多个分片中读取,每个分片表示数据的不同子集。
②从同步副本组中选择一个相关shard的活动分片。这可以是primary,也可以是replica。默认情况下,Elasticsearch只需在分片之间循环搜索。
③向所选分片发送读取请求。
④将结果整合。请注意,在按ID查找的情况下,只有一个分片是相关的,可以跳过此步骤。
CURD
添加文档
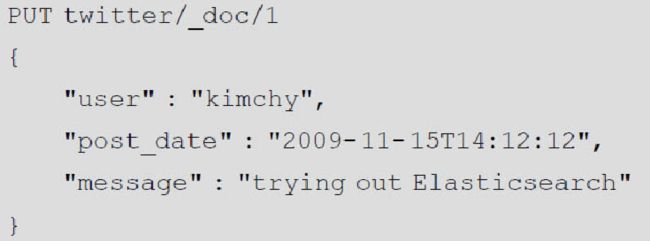
结果为:

· _shards:头提供有关索引操作的复制过程的信息。
· total:指示索引操作应在多少个分片(主primary和replica)上执行。
· successful:指示索引操作成功执行的分片数。
· failed:包含错误信息。
默认情况下,当索引操作成功返回时,有可能一些replica还没有开始或完成,因为只要primary成功执行,就会返回,这种行为可以调整。其实这样做的目的是快速响应,一般的场景并不需要等待所有分片都完成索引操作再返回,除非对数据安全要求极高的场景。
id自动生成
不指定id进行创建文档,默认自动会创建文档id。
路由
默认情况下,数据存放到哪个分片,通过使用文档ID值的哈希值来控制。对于更显式的控制,可以传递哈希函数的种子值。
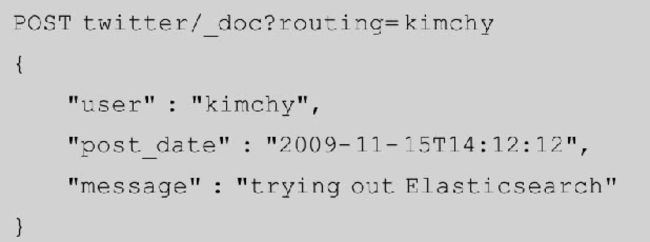
在设置显式mapping时,可以选择使用_routing字段从文档本身提取路由值。如果定义了mapping的_routing值并将其设置为必需,则如果没有提供可提取路由值,索引操作将失败。
嵌套关系
父子关系
父-子关系文档 在实质上类似于 nested model :允许将一个对象实体和另外一个对象实体关联起来。而这两种类型的主要区别是:在 nested objects 文档中,所有对象都是在同一个文档中,而在父-子关系文档中,父对象和子对象都是完全独立的文档。
父-子关系的主要作用是允许把一个 type 的文档和另外一个 type 的文档关联起来,构成一对多的关系:一个父文档可以对应多个子文档 。与 nested objects 相比,父-子关系的主要优势有:
更新父文档时,不会重新索引子文档。
创建,修改或删除子文档时,不会影响父文档或其他子文档。这一点在这种场景下尤其有用:子文档数量较多,并且子文档创建和修改的频率高时。
子文档可以作为搜索结果独立返回。
Elasticsearch 维护了一个父文档和子文档的映射关系,得益于这个映射,父-子文档关联查询操作非常快。但是这个映射也对父-子文档关系有个限制条件:父文档和其所有子文档,都必须要存储在同一个分片中。
父-子文档ID映射存储在 Doc Values 中。当映射完全在内存中时, Doc Values 提供对映射的快速处理能力,另一方面当映射非常大时,可以通过溢出到磁盘提供足够的扩展能力
ElasticSearch | 文档的父子关系
Nested 对象 vs 父子文档
| 特点场景 | Nested Object | Parent / Child |
|---|---|---|
| 优点 | 文档存储在一起,读取性能好 | 父子文档可以独立更新 |
| 缺点 | 更新嵌套的子文档时,需要更新整个文档 | 需要额外的内存维护关系,读取性能相对较差 |
| 适用场景 | 子文档偶尔更新, 以查询为主 | 子文档更新频繁 |
对象
Elasticsearch实战学习笔记(八) Elasticsearch文档间的关系
反规范化
集群
分片
索引可能会存储大量数据,这些数据可能会超出单个节点的硬件限制。例如,占用1TB磁盘空间的10亿个文档的单个索引可能超出单个节点的磁盘容量,或者速度太慢,无法满足搜索请求的性能要求。
为了解决这个问题,Elasticsearch提供了将索引水平切分为多段(称为分片,shard)的能力。创建索引时,只需定义所需的分片数量。每个分片本身就是一个具有完全功能的独立“索引”,可以分布在集群中的任何节点上。
一个索引被分为5分主分片和5个副本分片
默认情况下,当索引一篇文档的时候,系统首先根据文档ID的散列值选择一个主分片,并将文档发送到该主分片。这份主分片可能位于另一个节点,就像下图节点2上的主分片,不过对于应用程序这一点是透明的。
副本分片可以在运行的时候进行添加和移除,而主分片不可以。
可以在任何时候改变每个分片的副本分片的数量,因为副本分片总是可以被创建和移除。这并不适用于索引划分为主分片的数量,在创建索引之前,你必须决定主分片的数量。
请记住,过少的分片将限制可扩展性,但是过多的分片会影响性能。默认设置的5份是一个不错的开始。第9章全部讨论扩展性,你将学习到更多。我们也会解释如何动态地添加和移除副本分片。
副本
在随时可能发生故障的网络或云环境中,如果某个分片或节点以某种方式脱机或因何种原因丢失,则强烈建议用户使用故障转移机制。为此,Elasticsearch提出了将索引分片复制一个或多个拷贝,称为副本(replica)。
副本很重要,主要有两个原因:
· 副本在分片或节点发生故障时提供高可用性。因此,需要注意的是,副本永远不会分配到复制它的原始主分片所在的节点上。也就是分片和对应的副本不可在同一节点上。这很容易理解,如果副本和分片在同一节点上,当机器发生故障时会同时丢失,起不到容错的作用。
· 通过副本机制,可以提高搜索性能和水平扩展吞吐量,因为可以在所有副本上并行执行搜索。
总之,每个索引可以分割成多个分片。每个分片可以有零个或多个副本。
监控
查看集群健康状态

查看集群节点信息
http://localhost:9200/_cluster/state/master_node,nodes/
停用节点

_cat api
增加别名
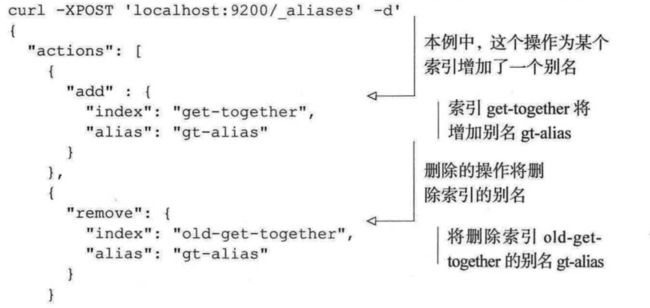

分词器
- 标准分词器
standard - 简单分词器(simple analyzer)
- 空白分词器
- 停用分词器
- 关键词分词器
最好将index指定为not_analyzed - 模式分词器
- UAX URL 电子邮件分词器
uax_url_email - 路径层次分词器
- IK 分词器,支持中文
分词过滤器
分词过滤器
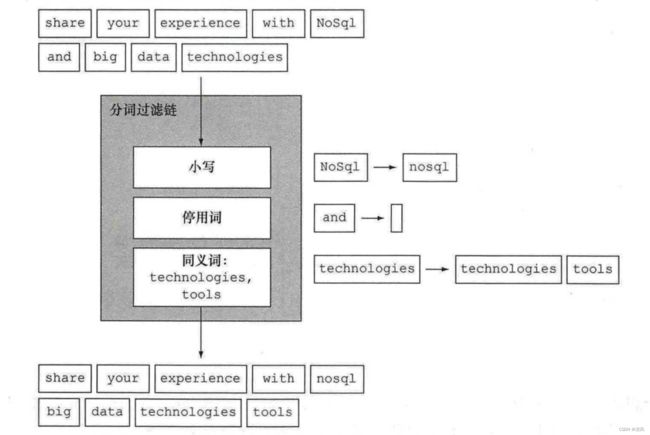
- 标准分词过滤器
- 小写分词过滤器
- 长度分词过滤器
- 停用分词过滤器
- 截断分词过滤器、修建分词过滤器、限制分词数量过滤器
- 颠倒分词过滤器
- 唯一分词过滤器
- ASCII 折叠分词过滤器
- 同义词分词过滤器
可以配置同义词取代分词也可以使用过滤器将synonym分词额外添加到分词集合中。
PUT
http://localhost:9200/mess1/
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"synonyms": {
"type": "custom",
"tokenizer": "ik_smart",
"filter": [
"my-synonym-filter"
]
}
},
"filter": {
"my-synonym-filter": {
"type": "synonym",
"expand": true,
"synonyms": [
"automobile=>car"
]
}
}
}
}
}
}
N 元语法
N元语法(ngram)和侧边N元语法(edge ngram)是Elasticsearch中两个更为独特的分词。N元语法是将一个单词切分为多个子单词。N元语法和侧边N元语法过滤器允许用户指定 min gram和max_gram设置。这些设置控制单词被切分为分词的数量。这一点可能让人有些费 解,所以来看一个例子。假设你想使用N元语法分析器来分析单词“spaghetti’”,以最简单的例 子开始,1-grams(也被称为一元语法)。
- 一元语法过滤器
- 二元语法过滤器
- 三元语法过滤器
- 设置min_gram和max_gram
- 侧边N元语法过滤器

测试
curl -XPOST 'localhost:9200/xxxxIndex/_analyze?analayzer=ng1' -d 'spaghetti'
- 滑动串口分词过滤器
配置
action.destructive_requires_name: false # 拒绝索引名称中的通配符