面经八股汇总
一、BN和LN的异同
1、batchnorm 和layernorm 一般分别用于cv、nlp领域
2、bn把一个batch中同一通道的所有特征视为一个分布,并将其标准化,意味着不同图片的同一通道的特征是可以比较的。
3、LN是把一个样本的所有词义向量视为一个分布,有几个句子就有几个分布,并将其标准化
Ⅰ延申
BN LN IN GN的差异解释

Ⅱ LN 的作用
首先,任何norm的意义都是为了让使用norm的网络的输入的数据分布变得更好,也就是转换为标准正态分布,数值进入敏感度区域,以缓解梯度消失。同时这也意味着舍弃了除此维度之外其它维度的其他信息!
二、正负样本不平衡,还有什么解决方案
https://zhuanlan.zhihu.com/p/554625711
从几个方面去思考:数据(欠采样、过采样、将多数样本聚类后使用类中心作为新样本)+模型(使用其它模型,比如决策树、SVM、集成学习)+loss损失 +评价指标(使用recall、precision、F1-score)
决策树往往在类别不均衡数据上表现不错,使用基于类变量的划分规则去创建分类数,因此可以强制将不同类别的样本分开
另一方面,可以换一个完全不同的角度看待问题,把它看作异常检测问题,重点在于为其中一类进行建模。
三、swin_transformer相比vit的改进
四、multi-crop推理阶段细节,是以过程时间消耗为代价换取精度提升吗
五、项目中遇到什么难点,又是如何解决的?(重点:框架)
https://mp.weixin.qq.com/s/o5JrdrKSPgeTX8vIiZJyAw
DAAR法则
–(除了前面提到的这一项目本身数据场景存在数据量少、样本不平衡等复杂问题)
1、首先,当时被推荐承接这一项目时,手上还有其它工作任务待解决,需要并行处理多项工作。其次,在具体实现所提二次调优方案时,遇到了过拟合问题 测试精度上限遇到瓶颈,项目整体时间紧,难度大。
2、首先,我和需求单位进行会议讨论:明确核心需求是什么,同时打好预防针,上线时间紧,如果没有方法如期上线,会制定备选方案(更换评价指标、要求精度下限的调整等)。其次,由于缺乏经验,我也向具有相关经验的同事寻求建议和一些注意事项,从中:数据清洗+swin_transformer
另外,在开始并行工作之前,我会根据任务难度以及完成时间要求 梳理各项工作的优先级,合理分配时间,保证短期工作效益最大化。
**定位问题: 确定数据:训练和测试数据分布一致,网络收敛:训练网络正常收敛,不存在过拟合后,
观察badcase信息,并进行CAM可视化,发现有效边缘被裁剪、且个例丰富性不足,使得无效区域被错判为高信息增益**。
3、在技术实现过程中:一开始尝试对齐随机裁剪,效果不及,之后采用multi-crop策略,描述+实现细节
4、提升0.8-1%左右。完成模型成功部署上线,甲方在实测数据中的测试精度达到95%,满足机审需求
六、为什么用softmax之类的,不用mse 均方误差损失等?
首先列出两种损失的公式,从反向传播的角度由链式法则,推导出导数表达式,然后发现mse会携带 deta’(z),因为导数sigmoid 在输出接近 0 和 1 的时候是非常小的,故导致在使用最小均方差Loss时,模型参数w会学习的非常慢。而使用交叉熵Loss则没有这个问题。为了更快的学习速度,分类问题一般采用交叉熵损失函数。
七、yolov检测版本的比对 与 改进
(详见文档表格)
八、如果有很长、很小、或者很宽的目标,应该如何处理目标尺度大小不一的情况,小目标不好检测,有试过其它方法吗?
小目标不好检测的两大原因:1)数据集中包含小目标的图片比较少,导致模型在训练的时候会偏向medium和large的目标。2)小目标的面积太小了,导致包含目标的anchor比较少,这也意味着小目标被检测出的概率变小。
改进:1、过采样 2、copy pasting 在保证不影响其他物体的基础上 ,增加小物体在图片中出现的次数,将其在图片中复制多份。3、FPN 4、anchor size的设置要合适 5、对于分辨率很低的小目标,可以对其所在的proposal进行超分辨,提升小目标的特征质量,更有利于小目标的检测 6、多尺度学习:通过多尺度可以将下采样前的特征保留,尽量保留小目标 7、SPP 模块。增加感受野,对小目标有效果,SPP size 的设置解决输入 feature map 的size 可能效果更好。
九、python内存管理机制
https://pythonjishu.com/ozxwrmlywrldtfk/ 引用计数、垃圾回收、内存池
十、梯度爆炸梯度消失的解决方法(本质都是因为梯度反向传播中的连乘效应)
1、pre-training +fine-tunning
2、梯度剪切:对梯度设定阈值
3、权重正则化。常见 L1 L2
4、选择relu等梯度大部分落在常数的激活函数
5、BN
6、残差
7、LSTM中的 门
十一、量化部署—参考美团yolov6的量化部署实战
yolov6是美团发布的一款开源的面向工业应用的2D目标检测模型,主要特点是速度快、精度高、部署友好,在美团众多视觉业务场景中都有着广泛的应用。
难点:yolov6采用了多分支的重参数化技巧,现有的训练后量化方法(PTQ)不能很好地应对多分支结构带来的剧烈变动的数值范围,导致量化后精度严重损失,另外如何针对多分支结构设计量化感知训练(QAT)也面临巨大挑战。
1、RepOpt 重参数优化器解决重参数化结构的量化问题
通过梯度掩码的方式在网络训练反向传播的过程中加入先验
2、基于量化敏感度分析的部分量化:一种使网络中的部分量化敏感层恢复浮点计算,来快速恢复量化模型精度的方法。
具体地,需要对网络中每一层都进行量化敏感度分析,如每次只对一层进行量化,获取该层的激活数据后计算敏感度数值。
3、基于通道蒸馏的量化感知训练:在训练过程中对卷积等算子加入伪量化操作,使得网络参数能更好适应量化带来的信息损失。具体地:这种方法的缺陷是特征图中的每个 pixel 对蒸馏的损失贡献相同。我们采用了每通道分布蒸馏 [6],即让 student 输出的每个通道的分布拟合 teacher 输出的每个通道的分布
(附录:自蒸馏:在SDA中,我们首先计算出过去K个time step参数的平均值作为Teacher Model。在SDV中,我们将过去K个time step的参数视为K个Teacher Model。)
十二、大华(电话二面):只是看一遍 不理解 还是记不住
1、伯努利分布和泊松分布
伯努利分布可以用于抛硬币:只有两种可能的结果且每次成功的概率都是一样的
泊松分布表示一个事件在特定时间内可能发生的次数,回答问题(排队理论)“在给定的一段时间内可能多少顾客排队
2、PCA和LDA
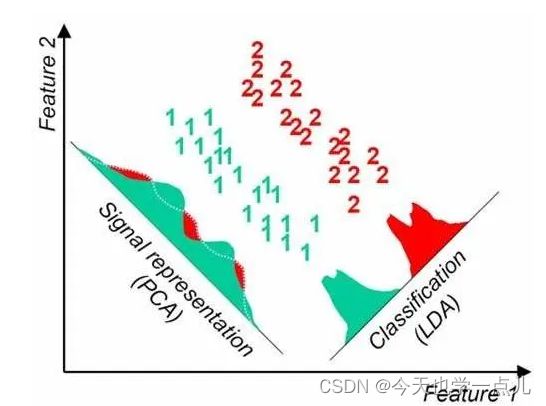
principal component analysis & linear discriminant analysis
主成分分析是无监督的:本质是向量换基,目标是使用另一组基去重新描述得到的数据空间。(通过对投影的距离方差的运用将降维问题转换为求最值问题)
线性判别分析是监督的,数据集的每个样本是考虑类别输出的:本质是“投影后类内方差最小,类间方差最大”
异同点:降维时均使用了矩阵特征分解的思想;都假设数据符合高斯分布
区别在于 PCA希望降维之后方差尽可能大;LDA最多降到类别数K-1的维数,PCA无限制;LDA选择分类性能最好的投影方向,PCA选择样本点投影具有最大方差的方向。
3、增量学习的方法:注册
4、部署
5、平面上三个点:如何预测:线性回归
6、逻辑回归:
详见B站 或者https://blog.csdn.net/weixin_60737527/article/details/124141293
十三、百度三面(综合面)
1、优点和缺点
对于优点:

缺点尽量只谈 技能素质 不涉及动机素质(价值观这些),比如


2、课题项目是自己实验吗 还是与其他有合作?
微型合成孔径雷达系统是与长沙瑞相感知电子技术有限公司合作,共同研制。(原国防科大多名教授组建)
另外,项目依托西安电子科技大学雷达信号处理国家重点实验室,其中 机载和星载合成孔径雷达实验数据完备,设施齐全。基于依托单位的支持,项目组开展研究工作所需的场地、工具等条件都已落实到位。
3、所做项目的背景 介绍
4、实习的这一项目 所提升的效果 具体是多少,从人审到机审,减少了多少人力消耗、时长,带来多少性能提升
?项目背景到底是啥 为啥不提前提示,为啥上传有违规 一个季度的图片是几十万级别 但实际推理应该是一波一波吗 还是一张一张的? 那到底多少量级?
—推理时,1w数据里随机挑100张,其中25张门店关闭 夹杂拍摄不全等其它问题,送入模型后precision和recal达标,准确率97%。
—在线
人审:每人平均300张/天,一周是1500张,机审:两串行模型 一天不到 即可完成。
5、职业规划(我不是海投,而是特意投递给贵公司,公司的行业、文化、工作,都是我喜欢的。)
https://mp.weixin.qq.com/s/-q0VFh7ZBq3J2d2PK-ZFcQ

----上面第三条 3-5年,在专业 综合素养都符合公司要求情况下,有能力去搭建一套算法架构,主要是想深耕这个领域,争取早日成为一位行业内专家,切实在实际应用领域解决问题和难点,为公司做出更大的贡献。
十四、关于目标检测
1)狭长目标—可旋转bonding box、手工设计anchors
2)FPN中:融合的方式是:通过1x1卷积调整通道数,然后直接add。之后进行3x3卷积操作,目的是消除上采样的混叠效应
十五、