linux负载(load)问题详解 + 压测命令集

本文主要帮助理解 CPU 相关的性能指标,常见的 CPU 性能问题以及解决方案梳理。
原文地址:https://zhuanlan.zhihu.com/p/180402964
系统平均负载
简介
系统平均负载:是处于可运行或不可中断状态的平均进程数。
可运行进程:使用 CPU 或等待使用 CPU 的进程
不可中断状态进程:正在等待某些 IO 访问,一般是和硬件交互,不可被打断(不可被打断的原因是为了保护系统数据一致,防止数据读取错误)
查看系统平均负载
首先top命令查看进程运行状态,如下:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10760 user 20 0 3061604 84832 5956 S 82.4 0.6 126:47.61 Process
29424 user 20 0 54060 2668 1360 R 17.6 0.0 0:00.03 **top**程序状态Status进程可运行状态为R,不可中断运行为D(后续讲解 top 时会详细说明)
top查看系统平均负载:
top - 13:09:42 up 888 days, 21:32, 8 users, load average: 19.95, 14.71, 14.01
Tasks: 642 total, 2 running, 640 sleeping, 0 stopped, 0 zombie
%Cpu0 : 37.5 us, 27.6 sy, 0.0 ni, 30.9 id, 0.0 wa, 0.0 hi, 3.6 si, 0.3 st
%Cpu1 : 34.1 us, 31.5 sy, 0.0 ni, 34.1 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st
...
KiB Mem : 14108016 total, 2919496 free, 6220236 used, 4968284 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6654506 avail Mem这里的load average就表示系统最近 1 分钟、5 分钟、15 分钟的系统瓶颈负载。
uptime查看系统瓶颈负载
[root /home/user]# uptime
13:11:01 up 888 days, 21:33, 8 users, load average: 17.20, 14.85, 14.10查看 CPU 核信息
系统平均负载和 CPU 核数密切相关,我们可以通过以下命令查看当前机器 CPU 信息:
lscpu查看 CPU 信息:
[root@Tencent-SNG /home/user_00]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
...
L1d cache: 32K
L1i cache: 32K
L2 cache: 4096K
NUMA node0 CPU(s): 0-7 // NUMA架构信息cat /proc/cpuinfo查看每个 CPU 核的信息:
processor : 7 // 核编号7
vendor_id : GenuineIntel
cpu family : 6
model : 6
...系统平均负载升高的原因
一般来说,系统平均负载升高意味着 CPU 使用率上升。但是他们没有必然联系,CPU 密集型计算任务较多一般系统平均负载会上升,但是如果 IO 密集型任务较多也会导致系统平均负载升高但是此时的 CPU 使用率不一定高,可能很低因为很多进程都处于不可中断状态,等待 CPU 调度也会升高系统平均负载。
所以假如我们系统平均负载很高,但是 CPU 使用率不是很高,则需要考虑是否系统遇到了 IO 瓶颈,应该优化 IO 读写速度。
所以系统是否遇到 CPU 瓶颈需要结合 CPU 使用率,系统瓶颈负载一起查看(当然还有其他指标需要对比查看,下面继续讲解)
案例问题排查
stress是一个施加系统压力和压力测试系统的工具,我们可以使用stress工具压测试 CPU,以便方便我们定位和排查 CPU 问题。
yum install stress // 安装stress工具stress 命令使用
// --cpu 8:8个进程不停的执行sqrt()计算操作
// --io 4:4个进程不同的执行sync()io操作(刷盘)
// --vm 2:2个进程不停的执行malloc()内存申请操作
// --vm-bytes 128M:限制1个执行malloc的进程申请内存大小
stress --cpu 8 --io 4 --vm 2 --vm-bytes 128M --timeout 10s我们这里主要验证 CPU、IO、进程数过多的问题
CPU 问题排查
使用stress -c 1模拟 CPU 高负载情况,然后使用如下命令观察负载变化情况:
uptime:使用uptime查看此时系统负载:
# -d 参数表示高亮显示变化的区域
$ watch -d uptime
... load average: 1.00, 0.75, 0.39mpstat:使用mpstat -P ALL 1则可以查看每一秒的 CPU 每一核变化信息,整体和top类似,好处是可以把每一秒(自定义)的数据输出方便观察数据的变化,最终输出平均数据:
13:14:53 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
13:14:58 all 12.89 0.00 0.18 0.00 0.00 0.03 0.00 0.00 0.00 86.91
13:14:58 0 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
13:14:58 1 0.40 0.00 0.20 0.00 0.00 0.20 0.00 0.00 0.00 99.20由以上输出可以得出结论,当前系统负载升高,并且其中 1 个核跑满主要在执行用户态任务,此时大多数属于业务工作。所以此时需要查哪个进程导致单核 CPU 跑满:
pidstat:使用pidstat -u 1则是每隔 1 秒输出当前系统进程、CPU 数据:
13:18:00 UID PID %usr %system %guest %CPU CPU Command
13:18:01 0 1 1.00 0.00 0.00 1.00 4 systemd
13:18:01 0 3150617 100.00 0.00 0.00 100.00 0 stress
...top:当然最方便的还是使用top命令查看负载情况:
top - 13:19:06 up 125 days, 20:01, 3 users, load average: 0.99, 0.63, 0.42
Tasks: 223 total, 2 running, 221 sleeping, 0 stopped, 0 zombie
%Cpu(s): 14.5 us, 0.3 sy, 0.0 ni, 85.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 16166056 total, 3118532 free, 9550108 used, 3497416 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 6447640 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3150617 root 20 0 10384 120 0 R 100.0 0.0 4:36.89 stress此时可以看到是stress占用了很高的 CPU。
IO 问题排查
我们使用stress -i 1来模拟 IO 瓶颈问题,即死循环执行 sync 刷盘操作: uptime:使用uptime查看此时系统负载:
$ watch -d uptime
..., load average: 1.06, 0.58, 0.37mpstat:查看此时 IO 消耗,但是实际上我们发现这里 CPU 基本都消耗在了 sys 即系统消耗上。
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 0.33 0.00 12.64 0.13 0.00 0.00 0.00 0.00 0.00 86.90
Average: 0 0.00 0.00 99.00 1.00 0.00 0.00 0.00 0.00 0.00 0.00
Average: 1 0.00 0.00 0.33 0.00 0.00 0.00 0.00 0.00 0.00 99.67IO 无法升高的问题:
iowait 无法升高的问题,是因为案例中 stress 使用的是 sync()系统调用,它的作用是刷新缓冲区内存到磁盘中。对于新安装的虚拟机,缓冲区可能比较小,无法产生大的 IO 压力,这样大部分就都是系统调用的消耗了。所以,你会看到只有系统 CPU 使用率升高。解决方法是使用 stress 的下一代 stress-ng,它支持更丰富的选项,比如stress-ng -i 1 --hdd 1 --timeout 600(--hdd 表示读写临时文件)。
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 0.25 0.00 0.44 26.22 0.00 0.00 0.00 0.00 0.00 73.09
Average: 0 0.00 0.00 1.02 98.98 0.00 0.00 0.00 0.00 0.00 0.00pidstat:同上(略)
可以看出 CPU 的 IO 升高导致系统平均负载升高。我们使用pidstat查找具体是哪个进程导致 IO 升高的。
top:这里使用 top 依旧是最方面的查看综合参数,可以得出stress是导致 IO 升高的元凶。
pidstat 没有 iowait 选项:可能是 CentOS 默认的sysstat太老导致,需要升级到 11.5.5 之后的版本才可用。
进程数过多问题排查
进程数过多这个问题比较特殊,如果系统运行了很多进程超出了 CPU 运行能,就会出现等待 CPU 的进程。 使用stress -c 24来模拟执行 24 个进程(我的 CPU 是 8 核) uptime:使用uptime查看此时系统负载:
$ watch -d uptime
..., load average: 18.50, 7.13, 2.84mpstat:同上(略)
pidstat:同上(略)
可以观察到此时的系统处理严重过载的状态,平均负载高达 18.50。
top:我们还可以使用top命令查看此时Running状态的进程数,这个数量很多就表示系统正在运行、等待运行的进程过多。
总结
通过以上问题现象及解决思路可以总结出:
平均负载高有可能是 CPU 密集型进程导致的
平均负载高并不一定代表 CPU 使用率高,还有可能是 I/O 更繁忙了
当发现负载高的时候,你可以使用 mpstat、pidstat 等工具,辅助分析负载的来源
总结工具:mpstat、pidstat、top和uptime
CPU 上下文切换
CPU 上下文:CPU 执行每个任务都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好 CPU 寄存器和程序计数器(Program Counter,PC)包括 CPU 寄存器在内都被称为 CPU 上下文。
CPU 上下文切换:CPU 上下文切换,就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
CPU 上下文切换:分为进程上下文切换、线程上下文切换以及中断上下文切换。
进程上下文切换
从用户态切换到内核态需要通过系统调用来完成,这里就会发生进程上下文切换(特权模式切换),当切换回用户态同样发生上下文切换。
一般每次上下文切换都需要几十纳秒到数微秒的 CPU 时间,如果切换较多还是很容易导致 CPU 时间的浪费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,这里同样会导致系统平均负载升高。
Linux 为每个 CPU 维护一个就绪队列,将 R 状态进程按照优先级和等待 CPU 时间排序,选择最需要的 CPU 进程执行。这里运行进程就涉及了进程上下文切换的时机:
进程时间片耗尽、。
进程在系统资源不足(内存不足)。
进程主动sleep。
有优先级更高的进程执行。
硬中断发生。
线程上下文切换
线程和进程:
当进程只有一个线程时,可以认为进程就等于线程。
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
所以线程上下文切换包括了 2 种情况:
不同进程的线程,这种情况等同于进程切换。
通进程的线程切换,只需要切换线程私有数据、寄存器等不共享数据。
中断上下文切换
中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
对同一个 CPU 来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
查看系统上下文切换
vmstat:工具可以查看系统的内存、CPU 上下文切换以及中断次数:
// 每隔1秒输出
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
3 0 0 157256 3241604 5144444 0 0 20 0 26503 33960 18 7 75 0 0
17 0 0 159984 3241708 5144452 0 0 12 0 29560 37696 15 10 75 0 0
6 0 0 162044 3241816 5144456 0 0 8 120 30683 38861 17 10 73 0 0cs:则为每秒的上下文切换次数。
in:则为每秒的中断次数。
r:就绪队列长度,正在运行或等待 CPU 的进程。
b:不可中断睡眠状态的进程数,例如正在和硬件交互。
pidstat:使用pidstat -w选项查看具体进程的上下文切换次数:
$ pidstat -w -p 3217281 1
10:19:13 UID PID cswch/s nvcswch/s Command
10:19:14 0 3217281 0.00 18.00 stress
10:19:15 0 3217281 0.00 18.00 stress
10:19:16 0 3217281 0.00 28.71 stress其中cswch/s和nvcswch/s表示自愿上下文切换和非自愿上下文切换。
自愿上下文切换:是指进程无法获取所需资源,导致的上下文切换。比如说, I/O、内存等系统资源不足时,就会发生自愿上下文切换。
非自愿上下文切换:则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢 CPU 时,就容易发生非自愿上下文切换
案例问题排查
这里我们使用sysbench工具模拟上下文切换问题。
先使用vmstat 1查看当前上下文切换信息:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 514540 3364828 5323356 0 0 10 16 0 0 4 1 95 0 0
1 0 0 514316 3364932 5323408 0 0 8 0 27900 34809 17 10 73 0 0
1 0 0 507036 3365008 5323500 0 0 8 0 23750 30058 19 9 72 0 0然后使用sysbench --threads=64 --max-time=300 threads run模拟 64 个线程执行任务,此时我们再次vmstat 1查看上下文切换信息:
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 318792 3385728 5474272 0 0 10 16 0 0 4 1 95 0 0
1 0 0 307492 3385756 5474316 0 0 8 0 15710 20569 20 8 72 0 0
1 0 0 330032 3385824 5474376 0 0 8 16 21573 26844 19 9 72 0 0
2 0 0 321264 3385876 5474396 0 0 12 0 21218 26100 20 7 73 0 0
6 0 0 320172 3385932 5474440 0 0 12 0 19363 23969 19 8 73 0 0
14 0 0 323488 3385980 5474828 0 0 64 788 111647 3745536 24 61 15 0 0
14 0 0 323576 3386028 5474856 0 0 8 0 118383 4317546 25 64 11 0 0
16 0 0 315560 3386100 5475056 0 0 8 16 115253 4553099 22 68 9 0 0我们可以明显的观察到:
当前 cs、in 此时剧增。
sy+us 的 CPU 占用超过 90%。
r 就绪队列长度达到 16 个超过了 CPU 核心数 8 个。
分析 cs 上下文切换问题
我们使用pidstat查看当前 CPU 信息和具体的进程上下文切换信息:
// -w表示查看进程切换信息,-u查看CPU信息,-t查看线程切换信息
$ pidstat -w -u -t 1
10:35:01 UID PID %usr %system %guest %CPU CPU Command
10:35:02 0 3383478 67.33 100.00 0.00 100.00 1 sysbench
10:35:01 UID PID cswch/s nvcswch/s Command
10:45:39 0 3509357 - 1.00 0.00 kworker/2:2
10:45:39 0 - 3509357 1.00 0.00 |__kworker/2:2
10:45:39 0 - 3509702 38478.00 45587.00 |__sysbench
10:45:39 0 - 3509703 39913.00 41565.00 |__sysbench所以我们可以看到大量的sysbench线程存在很多的上下文切换。
分析 in 中断问题
我们可以查看系统的watch -d cat /proc/softirqs以及watch -d cat /proc/interrupts来查看系统的软中断和硬中断(内核中断)。我们这里主要观察/proc/interrupts即可。
$ watch -d cat /proc/interrupts
RES: 900997016 912023527 904378994 902594579 899800739 897500263 895024925 895452133 Rescheduling interrupts这里明显看出重调度中断(RES)增多,这个中断表示唤醒空闲状态 CPU 来调度新任务执行,
总结
自愿上下文切换变多了,说明进程都在等待资源,有可能发生了 I/O 等其他问题。
非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢 CPU,说明 CPU 的确成了瓶颈。
中断次数变多了,说明 CPU 被中断处理程序占用,还需要通过查看/proc/interrupts文件来分析具体的中断类型。
CPU 使用率
除了系统负载、上下文切换信息,最直观的 CPU 问题指标就是 CPU 使用率信息。Linux 通过/proc虚拟文件系统向用户控件提供系统内部状态信息,其中/proc/stat则是 CPU 和任务信息统计。
$ cat /proc/stat | grep cpu
cpu 6392076667 1160 3371352191 52468445328 3266914 37086 36028236 20721765 0 0
cpu0 889532957 175 493755012 6424323330 2180394 37079 17095455 3852990 0 0
...这里每一列的含义如下:
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
system(通常缩写为 sys),代表内核态 CPU 时间。
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。
iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。
softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的 CPU 时间。
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
这里我们可以使用top、ps、pidstat等工具方便的查询这些数据,可以很方便的看到 CPU 使用率很高的进程,这里我们可以通过这些工具初步定为,但是具体的问题原因还需要其他方法继续查找。
这里我们可以使用perf top方便查看热点数据,也可以使用perf record可以将当前数据保存起来方便后续使用perf report查看。
CPU 使用率问题排查
这里总结一下 CPU 使用率问题及排查思路:
用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
CPU 问题排查套路
CPU 使用率
CPU 使用率主要包含以下几个方面:
用户 CPU 使用率,包括用户态 CPU 使用率(user)和低优先级用户态 CPU 使用率(nice),表示 CPU 在用户态运行的时间百分比。用户 CPU 使用率高,通常说明有应用程序比较繁忙。
系统 CPU 使用率,表示 CPU 在内核态运行的时间百分比(不包括中断)。系统 CPU 使用率高,说明内核比较繁忙。
等待 I/O 的 CPU 使用率,通常也称为 iowait,表示等待 I/O 的时间百分比。iowait 高,通常说明系统与硬件设备的 I/O 交互时间比较长。
软中断和硬中断的 CPU 使用率,分别表示内核调用软中断处理程序、硬中断处理程序的时间百分比。它们的使用率高,通常说明系统发生了大量的中断。
除在虚拟化环境中会用到的窃取 CPU 使用率(steal)和客户 CPU 使用率(guest),分别表示被其他虚拟机占用的 CPU 时间百分比,和运行客户虚拟机的 CPU 时间百分比。
平均负载
反应了系统的整体负载情况,可以查看过去 1 分钟、过去 5 分钟和过去 15 分钟的平均负载。
上下文切换
上下文切换主要关注 2 项指标:
无法获取资源而导致的自愿上下文切换。
被系统强制调度导致的非自愿上下文切换。
CPU 缓存命中率
CPU 的访问速度远大于内存访问,这样在 CPU 访问内存时不可避免的要等待内存响应。为了协调 2 者的速度差距出现了 CPU 缓存(多级缓存)。 如果 CPU 缓存命中率越高则性能会更好,我们可以使用以下工具查看 CPU 缓存命中率,工具地址、项目地址 perf-tools
# ./cachestat -t
Counting cache functions... Output every 1 seconds.
TIME HITS MISSES DIRTIES RATIO BUFFERS_MB CACHE_MB
08:28:57 415 0 0 100.0% 1 191
08:28:58 411 0 0 100.0% 1 191
08:28:59 362 97 0 78.9% 0 8
08:29:00 411 0 0 100.0% 0 9
08:29:01 775 20489 0 3.6% 0 89
08:29:02 411 0 0 100.0% 0 89
08:29:03 6069 0 0 100.0% 0 89
08:29:04 15249 0 0 100.0% 0 89
08:29:05 411 0 0 100.0% 0 89
08:29:06 411 0 0 100.0% 0 89
08:29:07 411 0 3 100.0% 0 89
[...]总结
通过性能指标查工具(CPU 相关)
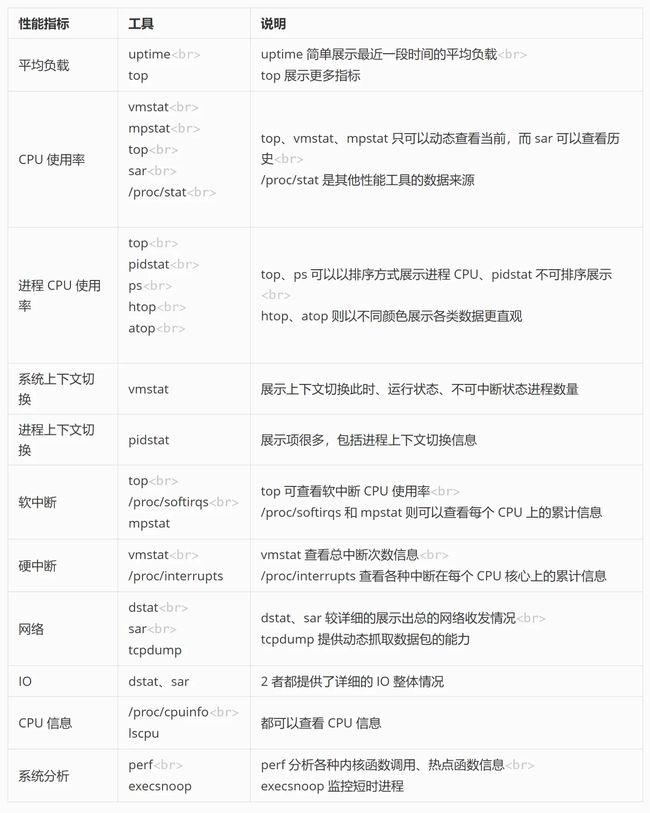
性能指标工具说明平均负载uptime
topuptime 简单展示最近一段时间的平均负载
top 展示更多指标CPU 使用率vmstat
mpstat
top
sar
/proc/stat
top、vmstat、mpstat 只可以动态查看当前,而 sar 可以查看历史
/proc/stat 是其他性能工具的数据来源进程 CPU 使用率top
pidstat
ps
htop
atop
top、ps 可以以排序方式展示进程 CPU、pidstat 不可排序展示
htop、atop 则以不同颜色展示各类数据更直观系统上下文切换vmstat展示上下文切换此时、运行状态、不可中断状态进程数量进程上下文切换pidstat展示项很多,包括进程上下文切换信息软中断top
/proc/softirqs
mpstattop 可查看软中断 CPU 使用率
/proc/softirqs 和 mpstat 则可以查看每个 CPU 上的累计信息硬中断vmstat
/proc/interruptsvmstat 查看总中断次数信息
/proc/interrupts 查看各种中断在每个 CPU 核心上的累计信息网络dstat
sar
tcpdumpdstat、sar 较详细的展示出总的网络收发情况
tcpdump 提供动态抓取数据包的能力IOdstat、sar2 者都提供了详细的 IO 整体情况CPU 信息/proc/cpuinfo
lscpu都可以查看 CPU 信息系统分析perf
execsnoopperf 分析各种内核函数调用、热点函数信息
execsnoop 监控短时进程
根据工具查性能指标(CPU 相关)
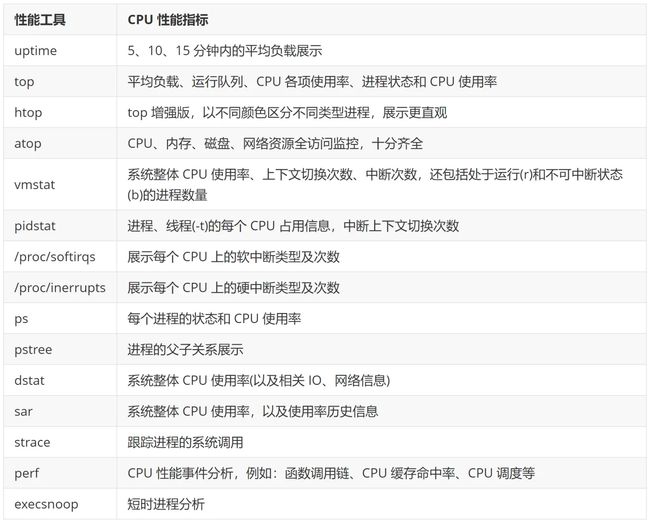
性能工具CPU 性能指标uptime5、10、15 分钟内的平均负载展示top平均负载、运行队列、CPU 各项使用率、进程状态和 CPU 使用率htoptop 增强版,以不同颜色区分不同类型进程,展示更直观atopCPU、内存、磁盘、网络资源全访问监控,十分齐全vmstat系统整体 CPU 使用率、上下文切换次数、中断次数,还包括处于运行(r)和不可中断状态(b)的进程数量pidstat进程、线程(-t)的每个 CPU 占用信息,中断上下文切换次数/proc/softirqs展示每个 CPU 上的软中断类型及次数/proc/inerrupts展示每个 CPU 上的硬中断类型及次数ps每个进程的状态和 CPU 使用率pstree进程的父子关系展示dstat系统整体 CPU 使用率(以及相关 IO、网络信息)sar系统整体 CPU 使用率,以及使用率历史信息strace跟踪进程的系统调用perfCPU 性能事件分析,例如:函数调用链、CPU 缓存命中率、CPU 调度等execsnoop短时进程分析
CPU 问题排查方向
有了以上性能工具,在实际遇到问题时我们并不可能全部性能工具跑一遍,这样效率也太低了,所以这里可以先运行几个常用的工具 top、vmstat、pidstat 分析系统大概的运行情况然后在具体定位原因。
top 系统CPU => vmstat 上下文切换次数 => pidstat 非自愿上下文切换次数 => 各类进程分析工具(perf strace ps execsnoop pstack)
top 用户CPU => pidstat 用户CPU => 一般是CPU计算型任务
top 僵尸进程 => 各类进程分析工具(perf strace ps execsnoop pstack)
top 平均负载 => vmstat 运行状态进程数 => pidstat 用户CPU => 各类进程分析工具(perf strace ps execsnoop pstack)
top 等待IO CPU => vmstat 不可中断状态进程数 => IO分析工具(dstat、sar -d)
top 硬中断 => vmstat 中断次数 => 查看具体中断类型(/proc/interrupts)
top 软中断 => 查看具体中断类型(/proc/softirqs) => 网络分析工具(sar -n、tcpdump) 或者 SCHED(pidstat 非自愿上下文切换)CPU 问题优化方向
性能优化往往是多方面的,CPU、内存、网络等都是有关联的,这里暂且给出 CPU 优化的思路,以供参考。
程序优化
基本优化:程序逻辑的优化比如减少循环次数、减少内存分配,减少递归等等。
编译器优化:开启编译器优化选项例如gcc -O2对程序代码优化。
算法优化:降低苏研发复杂度,例如使用nlogn的排序算法,使用logn的查找算法等。
异步处理:例如把轮询改为通知方式
多线程代替多进程:某些场景下多线程可以代替多进程,因为上下文切换成本较低
缓存:包括多级缓存的使用(略)加快数据访问
系统优化
CPU 绑定:绑定到一个或多个 CPU 上,可以提高 CPU 缓存命中率,减少跨 CPU 调度带来的上下文切换问题
CPU 独占:跟 CPU 绑定类似,进一步将 CPU 分组,并通过 CPU 亲和性机制为其分配进程。
优先级调整:使用 nice 调整进程的优先级,适当降低非核心应用的优先级,增高核心应用的优先级,可以确保核心应用得到优先处理。
为进程设置资源限制:使用 Linux cgroups 来设置进程的 CPU 使用上限,可以防止由于某个应用自身的问题,而耗尽系统资源。
NUMA 优化:支持 NUMA 的处理器会被划分为多个 Node,每个 Node 有本地的内存空间,这样 CPU 可以直接访问本地空间内存。
中断负载均衡:无论是软中断还是硬中断,它们的中断处理程序都可能会耗费大量的 CPU。开启 irqbalance 服务或者配置 smp_affinity,就可以把中断处理过程自动负载均衡到多个 CPU 上。
参考
极客时间:Linux 性能优化实战
更多干货尽在腾讯技术,官方微信/QQ交流群已建立,交流讨论可加:Journeylife1900、711094866(备注腾讯技术) 。
推荐阅读
Linux CPU性能优化方法
在Linux系统中,由于成本的限制,往往会存在资源上的不足,例如 CPU、内存、网络、IO 性能。本文,就对 Linux 进程和 CPU 的原理进行分析,总结出 CPU 性能优化的方法。 1. 分析手段 在理解…
point...发表于linux...

Linux性能优化-CPU性能优化思路
linux发表于linux...
Linux性能优化-CPU性能优化思路
关于这个,我觉得这篇文章写得很详细,转载记录一下: CPU性能指标CPU使用率 1.CPU使用率描述了非空闲时间占总CPU时间的百分比,根据CPU上运行任务的不同,又被分为用户CPU,系统CPU,等待I…
FreeR...发表于Linux...
Linux性能优化之CPU优化
Linux 的性能进行监测,以下是 VPSee 常用的工具: 工具 简单介绍 top 查看进程活动状态以及一些系统状况 vmstat 查看系统状态、硬件和系统信息等 iostat 查看CPU 负载,硬盘状况 sar 综合…
linux...发表于linux...