JDK源码解析(集合)--ArrayList与LinkedList区别
《JDK源码解析(集合)--ArrayList与LinkedList区别》首发橙寂博客转发请加此提示
JDK源码解析(集合)--ArrayList与LinkedList区别
ArrayList和LinkedList 讲解
ArrayList和LinkedList是许多人在使用Jdk中时最常用的两个集合类型,在很多面试的时候很多面试官会去问你,ArrayList和LinkedList有啥区别。很多人可能看过不少面试宝典:ArrayList底层是数组,查找速度快,删除慢,线程不安全LinkedList是基于链表,查找慢,删除快,线程不安全。但是你真正懂了嘛?本文带你深入解析下,这两个源码的原理。
ArrayList详解
- ArrayList的基本属性
//数据存储数组
transient Object[] elementData;
//elementData中的元素个数
private int size;
transient关键字表示修饰的属性不在被序列化。ArrayList继承了java.io.Serializable接口,即采用了Java默认的序列化机制如果。但是elementDatatransient关键字。如果要在网络中传输一定要支持序列化.所以翻了一下源码果然。ArrayList自己实现了序列化方法。
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i 0) {
// be like clone(), allocate array based upon size not capacity
int capacity = calculateCapacity(elementData, size);
SharedSecrets.getJavaOISAccess().checkArray(s, Object[].class, capacity);
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i - ArrayList的构造方法
在平常的使用中我们一般是下面两种方法创建
创建方式
List strList = new ArrayList();
List strList2 = new ArrayList(2);
构造方法
/**
*根据指定的容量来创建对象数组
*注:推荐使用这种,给定一个值。因为扩容的消耗是很大的.
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 默认的构造方法。创建一个空的对象数组
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
- ArrayList的添加方法
//添加对象
public boolean add(E e) {
//这个方法检查容量,如果容量不够就扩容 看后面的源码
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
//在指定位置添加对象
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
//把index后的所有元素都往后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
//扩容方法
private void ensureExplicitCapacity(int minCapacity) {
//记录是否添加或者删除
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//扩大1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//使用Arrays的copy方法扩容并拷贝数组
//所以前面我说创建集合时要指定大小
elementData = Arrays.copyOf(elementData, newCapacity);
}
批量添加
public boolean addAll(Collection c) {
//把集合转换成数组
Object[] a = c.toArray();
//获取数组长度
int numNew = a.length;
//检查并扩容
ensureCapacityInternal(size + numNew); // Increments modCount
//拷贝a数组
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
- ArrayList的删除方法
//删除指定位置
public E remove(int index) {
//检查inde是否超过最大容量
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//index后的全往前移
//这里使用的是jdk自带的copy方法原理是一样的
//所以删除的速度是耗时的
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
//删除指定元素
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
- ArrayList的修改方法
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
- ArrayList的查找方法
public E get(int index) {
//检查index是否超出容量
rangeCheck(index);
return elementData(index);
}
ArrayList总结
-
ArrayList线程不安全因为ArrayList中所有方法都没有加锁. -
ArrayList基于数组实现存储,按道理说,支持无限扩容。每次扩容增加1.5倍 -
ArrayList使用add(int index,element e)时,会把index的元素都后移一位 -
ArrayListremove(index)删除方法时,会把index的原素都往前移一位.并把最后一位置为null使Gc回收。 -
ArrayListremove(index)不需要遍历数组,remove(Object o)需要。
接下来看LinkedList的源码并与指之对比
LinkedList详解
- LinkedList的基本属性
//元素的个数
transient int size = 0;
//头元素
transient Node first;
//尾元素
transient Node last;
private static class Node {
//具体数据
E item;
//下一个node的地址
Node next;
//node的上一个
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node是LinkedList里的数据存储一个链表数据结构,LinkedList是基于双向链表实现的。
- LinkedList的添加逻辑
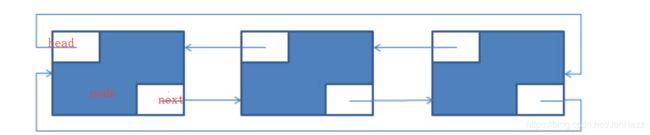
先看懂添加图,再去看代码会清晰很多。
public boolean add(E e) {
//把新添加的元素放在后面
linkLast(e);
return true;
}
//linkLast的逻辑
void linkLast(E e) {
//获取当前最后的指针
final Node l = last;
//把最后的指针指向newNode的pre,next指向null
final Node newNode = new Node<>(l, e, null);
last = newNode;
//如果是初次添加那么把first指向newNode
if (l == null)
first = newNode;
else
//否则把前一个的next指向新的newNode
l.next = newNode;
size++;
modCount++;
}
//node的构造函数
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
LinkedList的删除逻辑
- 删除图片展示
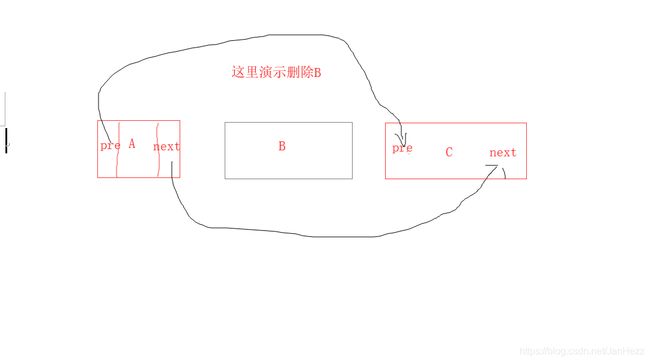
由图中可知,一开始A是指向B,B指向C。这时我们需要把B删除那么。我们就得把A直接指向C。先看懂图再去看代码。
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//解除链接
//这个是删除的逻辑
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
//如果上一个为空,给first赋值
if (prev == null) {
first = next;
} else {
//把前一个的下一个节点指向被删除节点下一个的节点
prev.next = next;
x.prev = null;
}
//如果下一个为空,给last复制
if (next == null) {
last = prev;
} else {
//下一个节点的前节点指向被删除节点的前节点
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
//这个是删除首个
public E pop() {
return removeFirst();
}
LinkedList的查找逻辑
//查找首个
public E peek() {
final Node f = first;
return (f == null) ? null : f.item;
}
//查找首个,并删除首个
public E poll() {
final Node f = first;
return (f == null) ? null : unlinkFirst(f);
}
LinkedList总结
-
LinkedList线程不安全因为LinkedList中所有方法都没有加锁. -
LinkedList基于链表实现存储,按道理说,是没有限制的 -
LinkedList使用add(element e)时,添加时只需要把指针换一下就行了 -
LinkedListremove(element e)删除方法时,只需要改变pre跟next的指针就行,所以LinkedList的删除速度更快 -
LinkedListget(index)查找时,需要做循环.所以查找速度慢。
总结
LinkedList与ArrayList最大的区别是他们的存储的数据结构不同。ArrayList基于数组,LinkedList基于列表。所以导致他们有一些区别。很显然,数组查找速度是比链表块的,因为数组有索引能直接定位到,删除LinkedList要快,因为链表的删除,只要改变指针地址就好了。在多线程这一块这两个集合类都是不支持的,线程都不安全。
`.
-
LinkedList基于链表实现存储,按道理说,是没有限制的 -
LinkedList使用add(element e)时,添加时只需要把指针换一下就行了 -
LinkedListremove(element e)删除方法时,只需要改变pre跟next的指针就行,所以LinkedList的删除速度更快 -
LinkedListget(index)查找时,需要做循环.所以查找速度慢。
总结
LinkedList与ArrayList最大的区别是他们的存储的数据结构不同。ArrayList基于数组,LinkedList基于列表。所以导致他们有一些区别。很显然,数组查找速度是比链表块的,因为数组有索引能直接定位到,删除LinkedList要快,因为链表的删除,只要改变指针地址就好了。在多线程这一块这两个集合类都是不支持的,线程都不安全。