Scrapy框架之itemPipline的实战案例
itemPipline 主要是处理数据,他里面提供了很多处理数据的类,比如数据验证,文件储存,图片储存,去重等。
下面进行实战案例演示: 这样是爬取当当网搜索的python图书数据
网址:python-当当网
1.先创建项目,进入项目
scrapy startproject dangdang
cd dangdang
目录结构:

2.创建爬虫文件,这时候spiders文件夹里,会多一个dang.py文件,这就是爬虫文件的第一个入口,
scrapy genspider dang search.dangdang.com 在这里编写数据解析函数
在这里编写数据解析函数
3.然后还要去ltems.py文件里,定义需要获取的数据
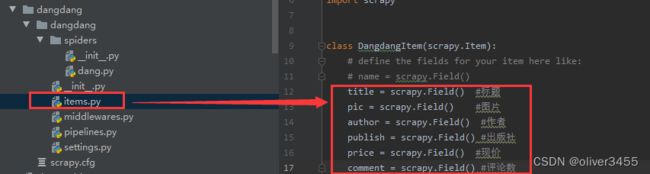
4. 再去dang,py里封装,最后还要记得扔回items里,这样就等于丢回给了框架的引芯,然后去了piplines类中

在setting中启用piplines类,

这时就可以在piplines.py类中,对数据做一些处理,比如把评论的个数,用正则提取出数字,把价格也提取出数字,不要¥符,然后过滤数据的操作也都可以在这个文件中操作。
原本输出的是这样的
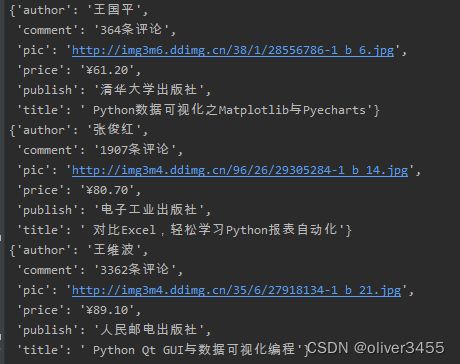
piplines.py

5. 然后在piplines.py文件中,增加数据库操作,把数据保存到数据库和把图片保存在本地
首先要在数据库里创建表和字段,注意下面那个不是单引号,是反单引号
CREATE TABLE `dangdang` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`title` VARCHAR(255) DEFAULT NULL,
`author` VARCHAR(32) DEFAULT NULL,
`price` DOUBLE(6,2) DEFAULT NULL,
`publish` VARCHAR(32) DEFAULT NULL,
`comment` INT(10) UNSIGNED DEFAULT NULL,
`pic` VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8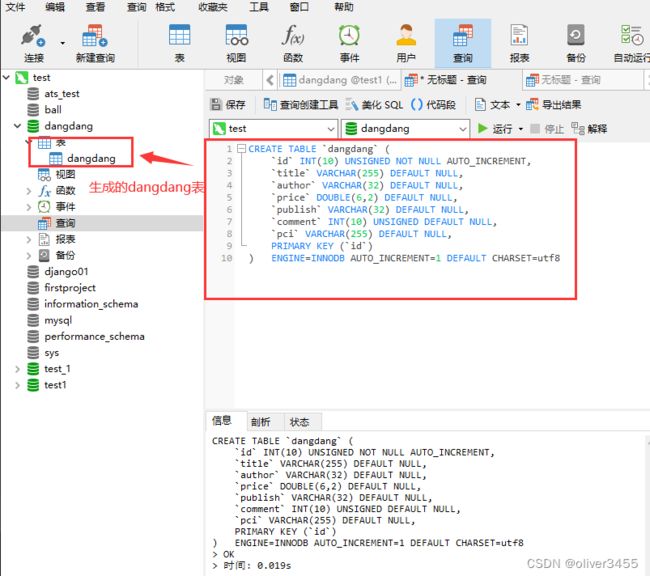
这时还要在setting.py里配置数据库信息,同时在 ITEM_PIPELINES里启用数据库
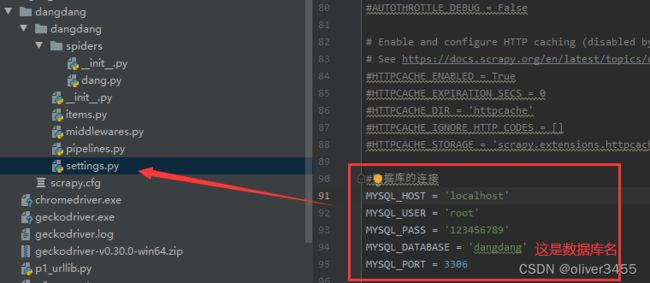

然后在piplines.py里操作数据库,建立几个方法,连接数据库,关闭数据库,写入数据库

这时就能看到数据库的结果

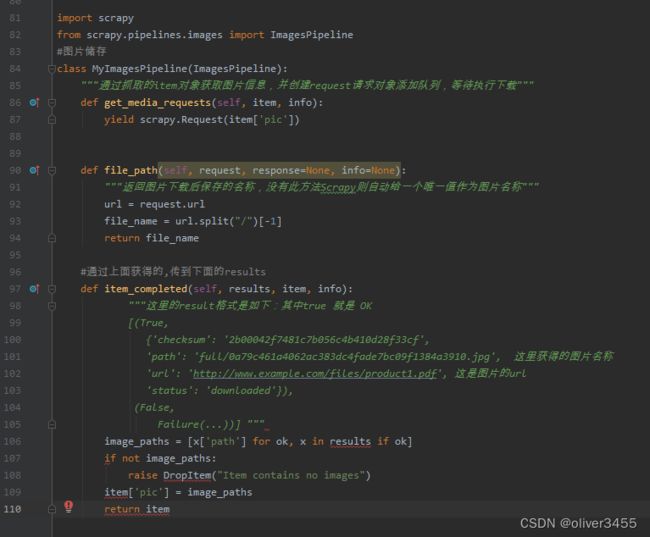
接下来,再把图片保存到本地文件夹,重新创建一个类,但是要继承ImagePipline类
在setting里启用图片存储的类,同时在setting里配置存储的路径


在piplines.py里编写,图片储存代码
然后再运行爬虫文件:scrapy crawl dang
如果本地没有保存到图片,可能是没有Pillow模块,因为在调用图片类时,会用到Pillow模块。
=======================================================================
以上是采集一页的数据,下面介绍采集多页数据,这个是在spiders文件夹里的爬虫类文件dang.py里写
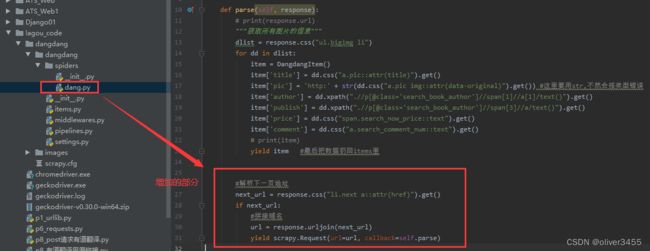
同时这个是框架,默认是多并发的,为了防止反扒,要改setting文件,并发数量和间隔时间都要改下

以上就是爬取的当当网图书,下一次将介绍,用scrapy框架和redis数据库,分布式爬取。
如有想获得代码的同学,可以给我留言。看到就会回复