最优化:建模、算法与理论(基础知识
最优化:建模、算法与理论
目前在学习 最优化:建模、算法与理论这本书,来此记录一下,顺便做一些笔记,在其中我也会加一些自己的理解,尽量写的不会那么的条条框框(当然最基础的还是要有)
全文28365字,累死了
第二章 基础知识
2.1 范数
2.1.1 向量范数
定义2.1(范数)称一个从向量空间Rn到实数域R的非负函数||·||为范数,如果他满足:
(1)正定性:对于所有的 v ∈ R n v{\in}R^n v∈Rn,有 ∣ ∣ v ∣ ∣ > = 0 ||v|| >= 0 ∣∣v∣∣>=0,且 ∣ ∣ v ∣ ∣ = 0 ||v|| = 0 ∣∣v∣∣=0 当且仅当 v = 0 v=0 v=0
(2)齐次性:对于所有的 v ∈ R n v{\in}R^n v∈Rn和 α ∈ R {\alpha}{\in}R α∈R,有 ∣ ∣ α v ∣ ∣ ||{\alpha}v|| ∣∣αv∣∣= ∣ α ∣ |{\alpha}| ∣α∣ ∣ ∣ v ∣ ∣ ||v|| ∣∣v∣∣
(3)三角不等式:对于所有的 v , w ∈ R n v,w{\in}R^n v,w∈Rn,有 ∣ ∣ v + w ∣ ∣ < = ∣ ∣ v ∣ ∣ + ∣ ∣ w ∣ ∣ ||v+w|| <= ||v|| + ||w|| ∣∣v+w∣∣<=∣∣v∣∣+∣∣w∣∣
最常用的向量范数为lp范数(p >= 1)
∣ ∣ v ∣ ∣ p = ( ∣ v 1 ∣ p + ∣ v 2 ∣ p + … + ∣ v n ∣ p ) 1 / p ||v||_{p} = (|v_{1}|^p + |v_{2}|^p + \ldots + |v_{n}|^p)^{1/p} ∣∣v∣∣p=(∣v1∣p+∣v2∣p+…+∣vn∣p)1/p
显而易见,高数应该都学过,如果 p = ∞ p={\infty} p=∞,那么 l ∞ l_\infty l∞范数定义为 ∣ ∣ v ∣ ∣ ∞ = m a x ∣ v i ∣ ||v||_\infty = max|v_i| ∣∣v∣∣∞=max∣vi∣
记住 p = 1 , 2 , ∞ p = 1,2,{\infty} p=1,2,∞的时候最重要,有时候我们会忽略 l 2 l_2 l2范数的角标
也会遇到由正定矩阵 A A A诱导的范数,即 ∣ ∣ x ∣ ∣ A = x T A x ||x||_A = \sqrt{x^TAx} ∣∣x∣∣A=xTAx
对于 l 2 l_2 l2范数,有常用的柯西不等式,设 a , b ∈ R n a,b{\in}R^n a,b∈Rn,则
∣ a T b ∣ < = ∣ ∣ a ∣ ∣ 2 ∣ ∣ b ∣ ∣ 2 |a^Tb|<=||a||_2||b||_2 ∣aTb∣<=∣∣a∣∣2∣∣b∣∣2
等号成立当且仅当a与b线性相关
2.1.2 矩阵范数
矩阵范数首先也一样要满足那三个特性啦,就是要满足正定性,齐次性,三角不等式,常用的就是 l 1 , l 2 l_1,l_2 l1,l2范数,当 p = 1 p = 1 p=1时,矩阵 A ∈ R m ∗ n A{\in}R^{m*n} A∈Rm∗n的范数定义
∣ ∣ A ∣ ∣ 1 = ∑ i = 1 m ∑ j = 1 n ∣ a i j ∣ ||A||_1={\sum_{i=1}^m}{\sum_{j=1}^n}|a_{ij}| ∣∣A∣∣1=i=1∑mj=1∑n∣aij∣
当 p = 2 p=2 p=2时,也叫矩阵的Frobenius范数(F范数),记为 ∣ ∣ A ∣ ∣ F ||A||_F ∣∣A∣∣F,其实就是所有元素的平方和然后开根号,具体定义如下
∣ ∣ A ∣ ∣ F = T r ( A A T ) = ∑ i , j a i j 2 ||A||_F=\sqrt{Tr(AA^T)}=\sqrt{\sum_{i,j}a_{ij}^2} ∣∣A∣∣F=Tr(AAT)=i,j∑aij2
这里的 T r Tr Tr表示方阵X的迹(这个大家应该都知道吧,我把百度的解释搬过来—在线性代数中,一个n×n矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)),矩阵的F范数具有正交不变性。
正交不变性呢就是说对于正交矩阵 U ∈ R m ∗ n , V ∈ R m ∗ n U{\in}R^{m*n},V{\in}R^{m*n} U∈Rm∗n,V∈Rm∗n,我们有
∣ ∣ U A F ∣ ∣ F 2 = ∣ ∣ A ∣ ∣ F 2 ||UAF||_F^2=||A||_F^2 ∣∣UAF∣∣F2=∣∣A∣∣F2
具体的推导我这里就不写了哈,打公式太麻烦了哈哈,感兴趣的可以看这本书的第24页或者来找我^^
矩阵范数也可以由向量范数给诱导出来,一般称这种算数为诱导范数,感觉用的不是很多,这里先不扩展开了
除了上诉的1范数,2范数,另一个常用的矩阵范数是核范数,给定矩阵 A ∈ R m ∗ n A{\in}R^{m*n} A∈Rm∗n,核范数定义为
∣ ∣ A ∣ ∣ ∗ = ∑ i = 1 r σ i ||A||_*=\sum_{i=1}^r{\sigma}_i ∣∣A∣∣∗=i=1∑rσi
其中 σ i , i = 1 , 2 , . . . , r {\sigma}_i,i=1,2,...,r σi,i=1,2,...,r为 A A A的所有非0奇异值, r = r a n k ( A ) r=rank(A) r=rank(A),类似于向量的 l 1 l_1 l1范数可以保稀疏性,我们也通常通过限制矩阵的核范数来保证矩阵的低秩性。
2.1.3 矩阵内积
内积一般用来表征两个矩阵之间的夹角,一个常用的内积—Frobenius内积, m ∗ n m*n m∗n的矩阵 A A A和 B B B的Frobenius内积定义为
< A , B > = T r ( A B T ) = ∑ i = 1 m ∑ j = 1 n a i j b i j
其实就是两个矩阵一一对应元素相乘
同样的,我们也有矩阵范数对应的柯西不等式,设 A , B ∈ R m ∗ n A,B{\in}R^{m*n} A,B∈Rm∗n,则
∣ < A , B > ∣ < = ∣ ∣ A ∣ ∣ F ∣ ∣ B ∣ ∣ F |
等号成立当且仅当A和B线性相关
2.2 导数
2.2.1 梯度与海瑟矩阵
梯度的定义(这玩意应该是我之前好像都没见到过的):给定函数 f : R n → R f:R^n{\rightarrow}R f:Rn→R,且 f f f在点 x x x的一个邻域内有意义,若存在向量 g ∈ R n g{\in}R^n g∈Rn满足
lim p → 0 f ( x + p ) − f ( x ) − g T p ∣ ∣ p ∣ ∣ = 0 \lim_{p{\rightarrow}0}\frac{f(x+p)-f(x)-g^Tp}{||p||}=0 p→0lim∣∣p∣∣f(x+p)−f(x)−gTp=0
就称 f f f在点 x x x处可微,此时 g g g称为 f f f在点 x x x处的梯度,记作 ∇ f ( x ) {\nabla}f(x) ∇f(x),如果对区域D上的每一个点 x x x都有 ∇ f ( x ) {\nabla}f(x) ∇f(x)存在,则称 f f f在D上可微
然后呢,这其中经过一系列的推导,就可以得到我们耳熟能详的梯度公式
∇ f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , . . . , ∂ f ( x ) ∂ x m ] T {\nabla}f(x)=\left[ \begin{matrix} {\frac{{\partial}f(x)}{{\partial}x_1}} ,{\frac{{\partial}f(x)}{{\partial}x_2}} ,...,{\frac{{\partial}f(x)}{{\partial}x_m}} \end{matrix} \right]^T ∇f(x)=[∂x1∂f(x),∂x2∂f(x),...,∂xm∂f(x)]T
对于多元函数,我们可以定义其海瑟矩阵:如果函数 f ( x ) : R n → R f(x):R^n{\rightarrow}R f(x):Rn→R在点 x x x处的二阶偏导数 ∂ 2 f ( x ) ∂ x i ∂ x j i , j = 1 , 2 , . . . , n \frac{{\partial}^2f(x)}{{\partial}x_i{\partial}x_j}i,j=1,2,...,n ∂xi∂xj∂2f(x)i,j=1,2,...,n都存在,则
∇ 2 f ( x ) = [ ∂ 2 f ( x ) ∂ x 1 2 ∂ 2 f ( x ) ∂ x 1 ∂ x 2 ⋯ ∂ 2 f ( x ) ∂ x 1 ∂ x n ∂ 2 f ( x ) ∂ x 2 ∂ x 1 ∂ 2 f ( x ) ∂ x 2 2 ⋯ ∂ 2 f ( x ) ∂ x 2 ∂ x n ⋮ ⋮ ⋮ ∂ 2 f ( x ) ∂ x n ∂ x 1 ∂ 2 f ( x ) ∂ x n ∂ x 2 ⋯ ∂ 2 f ( x ) ∂ x n 2 ] {\nabla}^2f(x)=\left[ \begin{matrix} \frac{{\partial}^2f(x)}{{\partial}x_1^2} & \frac{{\partial}^2f(x)}{{\partial}x_1{\partial}x_2} & \cdots& \frac{{\partial}^2f(x)}{{\partial}x_1{\partial}x_n}\\ \frac{{\partial}^2f(x)}{{\partial}x_2{\partial}x_1} &\frac{{\partial}^2f(x)}{{\partial}x_2^2} & \cdots & \frac{{\partial}^2f(x)}{{\partial}x_2{\partial}x_n} \\ \vdots & \vdots & &\vdots\\ \frac{{\partial}^2f(x)}{{\partial}x_n{\partial}x_1} &\frac{{\partial}^2f(x)}{{\partial}x_n{\partial}x_2} & \cdots &\frac{{\partial}^2f(x)}{{\partial}x_n^2} \end{matrix} \right] ∇2f(x)= ∂x12∂2f(x)∂x2∂x1∂2f(x)⋮∂xn∂x1∂2f(x)∂x1∂x2∂2f(x)∂x22∂2f(x)⋮∂xn∂x2∂2f(x)⋯⋯⋯∂x1∂xn∂2f(x)∂x2∂xn∂2f(x)⋮∂xn2∂2f(x)
成为 f f f在点 x x x处的海瑟矩阵
当 ∇ 2 f ( x ) {\nabla}^2f(x) ∇2f(x)在区域D上每个点 x x x都存在,就称 f f f在D上二阶可微,若他在D上还连续,可以证明此时的海瑟矩阵是一个对称矩阵
当 f : R n → R m f:R^n{\rightarrow}R^m f:Rn→Rm是向量值函数时,我们可以定义他的雅可比矩阵 J ( x ) ∈ R m ∗ n J(x){\in}R^{m*n} J(x)∈Rm∗n,他的第i行分量 f i ( x ) f_i(x) fi(x)梯度的转置,即
J ( x ) = [ ∂ f 1 ( x ) ∂ x 1 ∂ f 1 ( x ) ∂ x 2 ⋯ ∂ f 1 ( x ) ∂ x n ∂ f 2 ( x ) ∂ x 1 ∂ f 2 ( x ) ∂ x 2 ⋯ ∂ f 2 ( x ) ∂ x n ⋮ ⋮ ⋮ ∂ f m ( x ) ∂ x 1 ∂ f m ( x ) ∂ x 2 ⋯ ∂ f m ( x ) ∂ x n ] J(x)=\left[ \begin{matrix} \frac{{\partial}f_1(x)}{{\partial}x_1} & \frac{{\partial}f_1(x)}{{\partial}x_2} & \cdots& \frac{{\partial}f_1(x)}{{\partial}x_n}\\ \frac{{\partial}f_2(x)}{{\partial}x_1} & \frac{{\partial}f_2(x)}{{\partial}x_2} & \cdots& \frac{{\partial}f_2(x)}{{\partial}x_n}\\ \vdots & \vdots & &\vdots\\ \frac{{\partial}f_m(x)}{{\partial}x_1} & \frac{{\partial}f_m(x)}{{\partial}x_2} & \cdots& \frac{{\partial}f_m(x)}{{\partial}x_n} \end{matrix} \right] J(x)= ∂x1∂f1(x)∂x1∂f2(x)⋮∂x1∂fm(x)∂x2∂f1(x)∂x2∂f2(x)⋮∂x2∂fm(x)⋯⋯⋯∂xn∂f1(x)∂xn∂f2(x)⋮∂xn∂fm(x)
容易看出,梯度 ∇ f ( x ) {\nabla}f(x) ∇f(x)的雅可比矩阵就是f(x)的海瑟矩阵
类似于一元函数的泰勒展开,对于多元函数,这里也不加证明的给出泰勒展开
设 f : R n → R f:R^n{\rightarrow}R f:Rn→R是连续可微的, p ∈ R n p{\in}R^n p∈Rn,那么
f ( x + p ) = f ( x ) + ∇ ( x + t p ) T p f(x+p)=f(x)+{\nabla}(x+tp)^Tp f(x+p)=f(x)+∇(x+tp)Tp
其中 0 < t < 1 0
f ( x + p ) = f ( x ) + ∇ f ( x ) T p + 1 2 p T ∇ 2 f ( x + t p ) p f(x+p)=f(x)+{\nabla}f(x)^Tp+\frac{1}{2}p^T{\nabla}^2f(x+tp)p f(x+p)=f(x)+∇f(x)Tp+21pT∇2f(x+tp)p
其中 0 < t < 1 0
最后呢这一章还介绍了一类特殊的可微函数-----梯度利普希茨连续的函数,这类函数在很多优化算法收敛性证明中起着关键作用
梯度利普希茨连续定义:给定可微函数 f f f,若存在 L > 0 L>0 L>0,对任意 x , y ∈ d o m f x,y{\in}domf x,y∈domf有( d o m f domf domf就是 f f f的定义域)
∣ ∣ ∇ f ( x ) − ∇ f ( y ) ∣ ∣ ≤ L ∣ ∣ x − y ∣ ∣ ||{\nabla}f(x)-{\nabla}f(y)||{\le}L||x-y|| ∣∣∇f(x)−∇f(y)∣∣≤L∣∣x−y∣∣
则称 f f f是梯度利普希茨连续的,相应利普希茨常数为 L L L,有时候也会称为 L L L-光滑,或者梯度 L L L-利普希茨连续
梯度利普希茨连续表明, ∇ f ( x ) {\nabla}f(x) ∇f(x)的变化可以被自变量 x x x的变化所控制,满足该性质的函数有很多很好的性质, 一个重要的性质就是具有二次上界
具体证明我这里我就不再过多阐述了,有二次上界就是说 f ( x ) f(x) f(x)可以被一个二次函数上界所控制,即要求说 f ( x ) f(x) f(x)的增长速度不超过二次
还有一个推论就是说,如果 f f f是梯度利普希茨连续的,且有一个全局最小点 x ∗ x^* x∗,我们可以利用二次上界来估计 f ( x ) − f ( x ∗ ) f(x)-f(x^*) f(x)−f(x∗)的大小,其中 x x x可以是定义域中任意一点
1 2 L ∣ ∣ ∇ f ( x ) ∣ ∣ 2 ≤ f ( x ) − f ( x ∗ ) \frac{1}{2L}||{\nabla}f(x)||^2{\le}f(x)-f(x^*) 2L1∣∣∇f(x)∣∣2≤f(x)−f(x∗)
具体的证明我这里就不写了哈,想知道的可以百度或者我们讨论一下
2.2.2 矩阵变量函数的导数
多元函数梯度的定义也可以推广到变量是矩阵的情况,以 m ∗ n m*n m∗n矩阵 X X X为自变量的函数 f ( X ) f(X) f(X),若存在矩阵 G ∈ R m ∗ n G{\in}R^{m*n} G∈Rm∗n满足
lim V → 0 f ( X + V ) − f ( X ) − < G , V > ∣ ∣ V ∣ ∣ = 0 \lim_{V{\rightarrow}0}\frac{f(X+V)-f(X)-
其中 ∣ ∣ ⋅ ∣ ∣ ||·|| ∣∣⋅∣∣是任意矩阵范数,就称矩阵向量函数 f f f在 X X X处 F r a ˊ c h e t Fr\acute{a}chet Fraˊchet可微,就称G为 f f f在 F r a ˊ c h e t Fr\acute{a}chet Fraˊchet可微意义下的梯度,其实矩阵变量函数 f ( X ) f(X) f(X)的梯度也可以用其偏导数表示为
∇ f ( x ) = [ ∂ f ∂ x 11 ∂ f ∂ x 12 ⋯ ∂ f ∂ x 1 n ∂ f ∂ x 21 ∂ f ∂ x 22 ⋯ ∂ f ∂ x 2 n ⋮ ⋮ ⋮ ∂ f ∂ x m 1 ∂ f ∂ x m 2 ⋯ ∂ f ∂ x m n ] {\nabla}f(x)=\left[ \begin{matrix} \frac{{\partial}f}{{\partial}x_{11}} & \frac{{\partial}f}{{\partial}x_{12}} & \cdots& \frac{{\partial}f}{{\partial}x_{1n}}\\ \frac{{\partial}f}{{\partial}x_{21}} & \frac{{\partial}f}{{\partial}x_{22}} & \cdots& \frac{{\partial}f}{{\partial}x_{2n}}\\ \vdots & \vdots & &\vdots\\ \frac{{\partial}f}{{\partial}x_{m1}} & \frac{{\partial}f}{{\partial}x_{m2}} & \cdots& \frac{{\partial}f}{{\partial}x_{mn}} \end{matrix} \right] ∇f(x)= ∂x11∂f∂x21∂f⋮∂xm1∂f∂x12∂f∂x22∂f⋮∂xm2∂f⋯⋯⋯∂x1n∂f∂x2n∂f⋮∂xmn∂f
F r a ˊ c h e t Fr\acute{a}chet Fraˊchet可微的定义和使用往往比较繁琐,为此还有另一种定义----- G a ^ t e a u x G\hat{a}teaux Ga^teaux可微
定义:设 f ( X ) f(X) f(X)为矩阵变量函数,如果存在矩阵 G ∈ R m ∗ n G{\in}R^{m*n} G∈Rm∗n对任意方向 V ∈ R m ∗ n V{\in}R^{m*n} V∈Rm∗n满足
lim t → 0 f ( X + t V ) − f ( X ) − t < G , V > t = 0 \lim_{t{\rightarrow}0}\frac{f(X+tV)-f(X)-t
则称 f f f关于 X X X是 G a ^ t e a u x G\hat{a}teaux Ga^teaux的,就称G为 f f f在 G a ^ t e a u x G\hat{a}teaux Ga^teaux可微意义下的梯度
若 F r a ˊ c h e t Fr\acute{a}chet Fraˊchet可微可以推出 G a ^ t e a u x G\hat{a}teaux Ga^teaux可微,反之则不可以,但这本书讨论的函数基本都是 F r a ˊ c h e t Fr\acute{a}chet Fraˊchet可微的,所以我们目前无需讨论,大家了解一下就好了~,统一将矩阵变量函数 f ( X ) f(X) f(X)的导数记为 ∂ f ∂ X \frac{{\partial}f}{{\partial}X} ∂X∂f或者 ∇ f ( X ) {\nabla}f(X) ∇f(X)
举个例子把,免得大家不知道有什么用
考虑线性函数: f ( X ) = T r ( A X T B ) f(X)=Tr(AX^TB) f(X)=Tr(AXTB),其中 A ∈ R p ∗ n , B ∈ R m ∗ p , X ∈ R m ∗ n A{\in}R^{p*n},B{\in}R^{m*p},X{\in}R^{m*n} A∈Rp∗n,B∈Rm∗p,X∈Rm∗n对任意方向 V ∈ R m ∗ n V{\in}R^{m*n} V∈Rm∗n以及 t ∈ R t{\in}R t∈R,有
lim t → 0 f ( X + t V ) − f ( X ) t = lim t → 0 T r ( A ( X + t V ) T B − T r ( A X T B ) ) t \lim_{t{\rightarrow}0}\frac{f(X+tV)-f(X)}{t}=\lim_{t{\rightarrow}0}\frac{Tr(A(X+tV)^TB-Tr(AX^TB))}{t} t→0limtf(X+tV)−f(X)=t→0limtTr(A(X+tV)TB−Tr(AXTB))
= T r ( A V T B ) = < B A , V > =Tr(AV^TB)=
所以, ∇ f ( X ) = B A {\nabla}f(X)=BA ∇f(X)=BA
我学到这里时候会有一个疑问,就是 T r ( A V T B ) = < B A , V > Tr(AV^TB)=
我们知道, T r ( A V T B ) = T r ( B A V T ) Tr(AV^TB)=Tr(BAV^T) Tr(AVTB)=Tr(BAVT)这个是迹的基本性质, B A BA BA和 V V V都是 m ∗ n m*n m∗n的,那么这时候又有一个性质,假设C和D是相同规模的矩阵,那么 T r ( A T B ) = < A , B > Tr(A^TB)=
我这里是参考知乎jordi的,这是他的一个关于3*3矩阵的推导
链接:https://www.zhihu.com/question/274052744/answer/1521521561

那么这样就可以推出 T r ( A V T B ) = T r ( V T , B A ) = < B A , V > Tr(AV^TB)=Tr(V^T,BA)=
2.2.3 自动微分
自动微分是使用计算机导数的算法,在神经网络中,我们通过前向传播的方式将输入数据 a a a转化为 y ^ \hat{y} y^,也就是将输入数据 a a a作为初始信息,将其传递到隐藏层的每个神经元,处理后输出得到 y ^ \hat{y} y^。
通过比较输出得到 y ^ \hat{y} y^与真实标签y,可以定义一个损失函数 f ( x ) f(x) f(x),其中 x x x表示所有神经元对饮的参数集合, f ( x ) f(x) f(x)一般是多个函数复合的形式,为了找到最优的参数,我们需要通过优化算法来调整 x x x使得 f ( x ) f(x) f(x)达到最小,因此,对神经元参数 x x x的计算是不可避免的
这一块就是讲了一个神经网络的前向传播和后向求导,自动微分有两种方式,前向模式和后向模式,前向模式就是变传播变求导,后向模式就是前传播再一层层求导,很显然现在大家学的都是后向模式这种的吧,因为他复杂度更低,计算代价小
2.3 广义实值函数
数学分析的课程中我们学习了函数的基本概念,函数是从向量空间 R n R^n Rn到数据域 R R R的映射,而在最优化领域,经常涉及到对某个函数的某一个变量取inf(sup)操作,这导致函数的取值可能为无穷,为了能更方便的描述优化问题,我们需要对函数的定义进行某种扩展。
那么 what is 广义实值函数呢?
令 R ˉ = R ⋃ ∞ \bar{R}=R{\bigcup}{\infty} Rˉ=R⋃∞为广义实数空间,则映射 f : R n → R ˉ f:R^n{\rightarrow}\bar{R} f:Rn→Rˉ称为广义实值函数,可以看到,就是值域多了两个特殊的值,正负无穷
2.3.1 适当函数
适当函数:给定广义实值函数 f f f和非空集合 X X X,如果存在 x ∈ X x{\in}X x∈X使得 f ( x ) < + ∞ f(x)<+{\infty} f(x)<+∞,并且对任意的 x ∈ X x{\in}X x∈X,都有 f ( x ) > − ∞ f(x)>-{\infty} f(x)>−∞,那么称函数 f f f关于集合 X X X是适当的
总结一下,就是说适当函数 f f f呢,至少有一处的取值不为正无穷,以及处处取值不为负无穷。对于最优化问题,适当函数可以帮助我们去掉一些不感兴趣的函数,从一个比较合理的函数类去考虑问题。这应该很好理解,我们加入讨论一个min问题,他至少有个取值不能为正无穷吧,要不然怎么取min,然后处处取值不能为负无穷,要不讨论有啥意义对吧?
我们约定,若本书无特殊说明,定理中所讨论的函数均为适当函数
对于适当函数 f f f,规定其定义域
d o m f = { x ∣ f ( x ) < + ∞ } domf=\{x|f(x)<+{\infty}\} domf={x∣f(x)<+∞}
因为对于适当函数的最小值肯定不可能在正无穷处取到^^
2.3.2 闭函数
闭函数是另一类重要的广义实值函数,闭函数可以看作是连续函数的一种推广
在说闭函数之前,我们先引入一些基本概念:
1.下水平集
下水平集是描述实值函数取值的一个重要概念:为此有如下定义
( α \alpha α-下水平集)对于广义实值函数: f : R n → R ˉ f:R^n{\rightarrow}\bar{R} f:Rn→Rˉ
C α = { x ∣ f ( x ) ≤ α } C_{\alpha}=\{x|f(x)\le{\alpha}\} Cα={x∣f(x)≤α}
称为 f f f的 α \alpha α-下水平集
就是取值不能超过 α \alpha α嘛,若 C α C_{\alpha} Cα非空,我们知道 f ( x ) f(x) f(x)的全局最小点一定落在 C α C_{\alpha} Cα中,无需考虑之外的点
2.上方图
上方图是从集合的角度来描述一个函数的具体性质,有如下定义:
对于广义实值函数 f : R n → R ˉ f:R^n{\rightarrow}\bar{R} f:Rn→Rˉ
e p i f = { ( x , t ) ∈ R n + 1 ∣ f ( x ) ≤ t } epif=\{(x,t){\in}R^{n+1}|f(x){\le}t\} epif={(x,t)∈Rn+1∣f(x)≤t}

说人话就是函数 f f f上方的东西小于等于t(t取任意值), f f f的很多性质都可以通过 e p i f epif epif得到,可以通过 e p i f epif epif的一些性质 f f f的性质
3.闭函数、下半连续函数
闭函数:设 f : R n → R ˉ f:R^n{\rightarrow}\bar{R} f:Rn→Rˉ为广义实值函数,若 e p i f epif epif为闭集,则称 f f f为闭函数
下半连续函数:设广义实值函数 f : R n → R ˉ f:R^n{\rightarrow}\bar{R} f:Rn→Rˉ,若对任意的 x ∈ R n x{\in}R^n x∈Rn,有
lim inf y → x f ( y ) ≥ f ( x ) \liminf_{y{\rightarrow}x} f(y)\ge{f(x)} y→xliminff(y)≥f(x)
则 f ( x ) f(x) f(x)为下半连续函数
我觉得如果不懂这个下极限的话,直接看文字会好得多
其实就是在 x 0 x_0 x0处的邻域处,如果 f( x 0 x_0 x0) 减去一个正的微小值,从而可以恒小于该邻域的所有 f ( x ) f(x) f(x),则称在该间断点处有下半连续性。
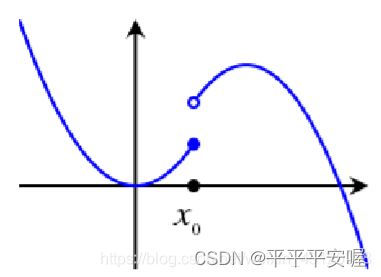
如果是下图这样的

你的 x 0 x_0 x0再往左边取哪怕一点点,都会骤降,就达不到 x 0 x_0 x0的邻域中的 x x x比 f ( x 0 ) − ε f(x_0)-{\varepsilon} f(x0)−ε大,而如果是第一张图,我们可以保证 x 0 x_0 x0的左边不会骤降,差不多就是这个意思
设广义实值函数 f : R n → R ˉ f:R^n{\rightarrow}\bar{R} f:Rn→Rˉ。则以下命题等价:
(1) f ( x ) f(x) f(x)的任意 α \alpha α-下水平集都是闭集
(2) f ( x ) f(x) f(x)是下半连续的
(3) f ( x ) f(x) f(x)是闭函数
具体证明我就不在这细细展开了,同理,想知道可以和我探讨或者自行谷歌~
闭集: 如果对任意收敛序列,最终收敛到的点都在集合内,那么集合是闭的
我们可以看到,其实闭函数和下半连续函数可以等价,以后往往只会出现一种定义
闭(下半连续)函数间的简单运算会保持原有性质
(1)加法,若 f f f和 g g g均为适当的闭函数,并且 d o m f ⋂ d o m g ≠ ∅ domf {\bigcap}domg{\neq}∅ domf⋂domg=∅则 f + g f+g f+g也是闭函数,说是适当是避免出现未定式的情况,也就是负无穷+正无穷
(2)仿射映射的复合,若 f f f为闭函数,则 f ( A x + b ) f(Ax+b) f(Ax+b)也为闭函数
(3)取上确界,若每一个函数 f α f_{\alpha} fα均为闭函数,则 s u p α f α ( x ) sup_{\alpha}f_{\alpha}(x) supαfα(x)也为闭函数。
2.4 凸集
2.4.1 凸集的相关定义
说实话凸集这个之前说的一直都有听说,但是具体的定义我一直没有搞明白,现在学一下~
对于 R n R^n Rn中的两个点 x 1 ≠ x 2 x_1{\neq}x2 x1=x2,形如
y = θ x 1 + ( 1 − θ ) x 2 y={\theta}x_1+(1-{\theta})x_2 y=θx1+(1−θ)x2
的点形成了过点 x 1 x_1 x1和 x 2 x_2 x2的直线,当 0 ≤ θ ≤ 1 0{\le}{\theta}{\le}1 0≤θ≤1时,这样的点形成了连接点 x 1 x_1 x1与 x 2 x_2 x2的线段
我们定义:如果过集合 C C C中任意两点的直线都在 C C C内,则称 C C C为仿射集,即
x 1 , x 2 ∈ C ⟶ θ x 1 + ( 1 − θ ) x 2 ∈ C , ∀ θ ∈ R x_1,x_2{\in}C{\longrightarrow}{\theta}x_1+(1-{\theta})x_2{\in}C,{\forall}{\theta}{\in}R x1,x2∈C⟶θx1+(1−θ)x2∈C,∀θ∈R
很明显可以看出,线性方程组 A x = b Ax=b Ax=b的解集是仿射集,反之,任意仿射集都可以表示成一个线性方程组的解集
那么,凸集是定义是什么呢?
凸集:如果连接集合 C C C中任意两点的线段都在 C C C内,则称 C C C为凸集,即
x 1 , x 2 ∈ C ⟶ θ x 1 + ( 1 − θ ) x 2 ∈ C , ∀ 0 ≤ θ ≤ 1 x_1,x_2{\in}C{\longrightarrow}{\theta}x_1+(1-{\theta})x_2{\in}C,{\forall}0{\le}{\theta}{\le}1 x1,x2∈C⟶θx1+(1−θ)x2∈C,∀0≤θ≤1
可以看到凸集就是仿射集的直线变成线段了而已,仿射集都是凸集
从凸集我们可以引出凸组合和凸包的概念,形如
x = θ 1 x 1 + θ 2 x 2 + ⋯ + θ k x k x={\theta}_1x_1+{\theta}_2x_2+\cdots+{\theta}_kx_k x=θ1x1+θ2x2+⋯+θkxk
1 = θ 1 + θ 2 + ⋯ + θ k , θ i ≥ 0 , i = 1 , 2 , ⋯ , k 1={\theta}_1+{\theta}_2+\cdots+{\theta}_k,{\theta}_i{\ge}0,i=1,2,\cdots,k 1=θ1+θ2+⋯+θk,θi≥0,i=1,2,⋯,k
的点称为 x 1 , x 2 , ⋯ , x k x_1,x_2,\cdots,x_k x1,x2,⋯,xk的凸组合,集合 S S S中点所有的凸组合构成的集合称为 S S S的凸包,记作 c o n v S conv S convS,简而言之, c o n v S convS convS是包含 S S S的最小的凸集
若在凸组合的定义中去掉 θ i ≥ 0 {\theta}_i{\ge}0 θi≥0的限制,我们可以得到仿射包的概念
仿射包:设 S S S为 R n R^n Rn的子集,称如下集合为S的仿射包:
{ x ∣ x = x = θ 1 x 1 + θ 2 x 2 + ⋯ + θ k x k , x 1 , x 2 , ⋯ , x k ∈ S , θ 1 + θ 2 + ⋯ + θ k = 1 } \{x|x=x={\theta}_1x_1+{\theta}_2x_2+\cdots+{\theta}_kx_k, x_1,x_2,\cdots,x_k{\in}S,{\theta} _1+{\theta}_2+\cdots+{\theta}_k=1\} {x∣x=x=θ1x1+θ2x2+⋯+θkxk,x1,x2,⋯,xk∈S,θ1+θ2+⋯+θk=1}
记为 a f f i n e S affineS affineS
 fangshebao
fangshebao
一般而言,一个集合的仿射包实际上是包含该集合的最小的仿射集
形如
x = θ 1 x 1 + θ 2 x 2 , θ 1 > 0 , θ 2 > 0 x={\theta}_1x_1+{\theta}_2x_2,{\theta}_1>0,{\theta}_2>0 x=θ1x1+θ2x2,θ1>0,θ2>0
的点称为点 x 1 , x 2 x_1,x_2 x1,x2的锥组合,若集合 S S S的任意点的锥组合都在 S S S中,则称S为凸锥
2.4.2 重要的凸集
1.超平面和半空间
任取非零向量 a a a,形如 { x ∣ a T x = b } \{x|a^Tx=b\} {x∣aTx=b}的集合称为超平面,形如 { x ∣ a T x ≤ b } \{x|a^Tx{\le}b\} {x∣aTx≤b}的集合称为半空间, a a a是对应的超平面和半空间的法向量,一个超平面将 R n R^n Rn分为两个半空间,容易看出,超平面是仿射集和凸集,半空间是凸集但不是仿射集(这个如果理解了仿射集和凸集的概念应该很好理解)

2.球、椭球、锥
球和椭球也是常见的凸集,球我们这里就不多介绍了
形如
{ x ∣ ( x − x c ) T P − 1 ( x − x ) c ) ≤ 1 } \{x|(x-x_c)^TP^{-1}(x-x)_c){\le}1\} {x∣(x−xc)TP−1(x−x)c)≤1}
的集合称为椭球,其中P对称正定,椭球的另一种表示为 { x c + A u ∣ ∣ u 2 ∣ ∣ ≤ 1 } \{x_c+Au||u_2||{\le}1\} {xc+Au∣∣u2∣∣≤1},A为非奇异的方阵
另外,我们称集合
{ ( x , t ) ∣ ∣ ∣ x ∣ ∣ ≤ t } \{(x,t)|||x||{\le}t\} {(x,t)∣∣∣x∣∣≤t}
为范数锥,欧几里得范数锥也称为二次锥,范数锥是凸集
别忘了 t t t也是变量噢,看这个图应该就很好理解范数锥了

知乎链接:https://zhuanlan.zhihu.com/p/126072881
3.多面体
我们把满足线性等式和不等式组的点的集合称为多面体,即
{ x ∣ A x ≤ b , C x = d } \{x|Ax{\le}b,Cx=d\} {x∣Ax≤b,Cx=d}
多面体是有限个半空间和超平面的交集,所以是凸集
4.(半)正定锥
这个我直接把书上的先贴过来把,我目前也不太懂,就不能细说

2.4.3 保凸的运算
证明一个集合是凸集有两种方式,第一种就是利用定义
x 1 , x 2 ∈ C , 0 ≤ θ ≤ 1 ⟶ θ x 1 + ( 1 − θ x 2 ) ∈ C x_1,x_2{\in}C,0{\le}{\theta}{\le}1{\longrightarrow}{\theta}x_1+(1-{\theta}x_2){\in}C x1,x2∈C,0≤θ≤1⟶θx1+(1−θx2)∈C来证明集合 C C C是凸集。
第二种方法就是说明集合C可以由简单的凸集(刚刚说的超平面、半空间,范数球等)经过保凸的运算得到。
定理1:任意多个凸集的交为凸集
定理2:设 f : R n → R m f:R^n{\rightarrow}R^m f:Rn→Rm是仿射变换( f ( x ) = A x + b , A ∈ R m ∗ n , b ∈ R n f(x)=Ax+b,A{\in}R^{m*n},b{\in}R^n f(x)=Ax+b,A∈Rm∗n,b∈Rn),则
(1)凸集在 f f f下的像是凸集:
S 是凸集 → f ( S ) → { f ( x ) ∣ x ∈ S } 是凸集 S是凸集{\rightarrow}f(S){\rightarrow}\{f(x)|x{\in}S\}是凸集 S是凸集→f(S)→{f(x)∣x∈S}是凸集
(2)凸集在 f f f下的原像是凸集
C 是凸集 → f − 1 ( C ) → { x ∈ R n ∣ f ( x ) ∈ C } 是凸集 C是凸集{\rightarrow}f^{-1}(C){\rightarrow}\{x{\in}R^n|f(x){\in}C\}是凸集 C是凸集→f−1(C)→{x∈Rn∣f(x)∈C}是凸集
就是经过缩放、平移或者投像仍是凸集
2.4.4 分离超平面定理
这是一个凸集的重要性质,即可以用超平面分离不相交的凸集,最基本的结果是分离超平面定理和支撑超平面定理
分离超平面定理:如果C和D是不相交的两个凸集,则存在非零向量 a a a和常熟 b b b,使得
a T x ≤ b , ∀ x ∈ C , 且 a T x ≥ b , ∀ x ∈ D a^Tx{\le}b,{\forall}x{\in}C,且a^Tx{\ge}b,{\forall}x{\in}D aTx≤b,∀x∈C,且aTx≥b,∀x∈D
即超平面 { x ∣ a T x = b } \{x|a^Tx=b\} {x∣aTx=b}分离了 C C C和 D D D

严格分离定理:即上述成立严格不等号,具体我就不展开了
支撑超平面:给定集合 C C C及其边界上一点 x 0 x_0 x0,如果 a ≠ 0 a{\neq}0 a=0满足 a T x ≤ a T x 0 , ∀ x ∈ C a^Tx{\le}a^Tx_0,{\forall}x{\in}C aTx≤aTx0,∀x∈C,那么称集合
{ x ∣ a T x = a T x 0 } \{x|a^Tx=a^T{x_0}\} {x∣aTx=aTx0}
为 C C C在边界点 x 0 x_0 x0处的支撑超平面
从几何上来说,此超平面与集合 C C C在点 x 0 x_0 x0处相切
支撑超平面定理:如果C是凸集,则在C的任意边界点处都存在支撑超平面
这个定理其实有非常强的几何直观,就是给定一个平面后,可以把凸集边界上的任意一点当成支撑点将凸集放在该平面上,其他形状的集合一般没有这个性质。
2.5 凸函数
凸函数这个大家肯定都有听过吧,下面我们来看看他具体的定义(目前我也不太了解)
2.5.1 凸函数的定义
凸函数:设函数 f f f为适当函数,如果 d o m f domf domf是凸集,且
f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) f({\theta}x+(1-{\theta})y){\le}{\theta}f(x)+(1-{\theta})f(y) f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)
对于所有的 x , y ∈ d o m f , 0 ≤ θ ≤ 1 x,y{\in}domf,0{\le}{\theta}{\le}1 x,y∈domf,0≤θ≤1都成立,都称 f f f是凸函数
直观的来说,连接凸函数的图像上任意两点的线段都在函数图像上方
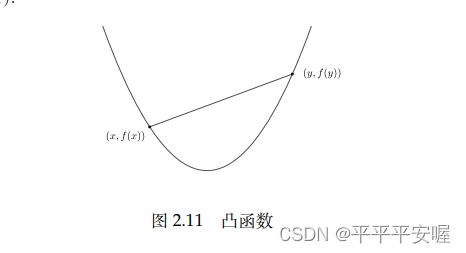
相应的,我们也有凹函数,若 − f -f −f是凸函数,则称 f f f是凸函数。只要改变一下符号,很多凸函数的性质都可以用在凹函数上。
另外,如果 d o m f domf domf是凸集,且
f ( θ x + ( 1 − θ ) y ) < θ f ( x ) + ( 1 − θ ) f ( y ) f({\theta}x+(1-{\theta})y)<{\theta}f(x)+(1-{\theta})f(y) f(θx+(1−θ)y)<θf(x)+(1−θ)f(y)
对于所有的 x , y ∈ d o m f , x ≠ y , 0 ≤ θ ≤ 1 x,y{\in}domf,x{\neq}y,0{\le}{\theta}{\le}1 x,y∈domf,x=y,0≤θ≤1都成立,则称 f f f是严格凸函数
还有另一类常用的凸函数,强凸函数
强凸函数,若存在常数 m > 0 m>0 m>0,使得
g ( x ) = f ( x ) − m 2 ∣ ∣ x ∣ ∣ 2 g(x)=f(x)-\frac{m}{2}||x||^2 g(x)=f(x)−2m∣∣x∣∣2
为凸函数,则称 f ( x ) f(x) f(x)为强凸函数,其中 m m m为强凸函数,也可以称为m-强凸函数
将 g ( x ) g(x) g(x)应用到凸函数的定义里面去,我们可以得到
若存在常数 m > 0 m>0 m>0,使得对任意 x , y ∈ d o m f , 0 < θ < 1 x,y{\in}domf,0<{\theta}<1 x,y∈domf,0<θ<1,有
f ( θ x + ( 1 − θ ) y ) ≤ θ f ( x ) + ( 1 − θ ) f ( y ) − m 2 θ ( 1 − θ ) ∣ ∣ x − y ∣ ∣ 2 f({\theta}x+(1-{\theta})y){\le}{\theta}f(x)+(1-{\theta})f(y)-\frac{m}{2}{\theta}(1-{\theta})||x-y||^2 f(θx+(1−θ)y)≤θf(x)+(1−θ)f(y)−2mθ(1−θ)∣∣x−y∣∣2
则称 f ( x ) f(x) f(x)为强凸函数,其中 m m m为强凸参数
从这两个定义我们可以看出来:
(1)强凸函数减去一个正定二次函数仍然是凸的
(2)强凸函数一定是严格凸函数, m = 0 m=0 m=0时退化为凸函数

一个重要的定理:设 f f f是强凸函数且存在最小值,则他的最小值点唯一
具体证明用反证法就好了,蛮简单的,假设有两个最小值点 x , y x,y x,y,然后代入强凸函数的定义里去
要注意的是, f f f存在最小值是前提,否则强凸函数的全局最小点不一定存在
2.5.2 凸函数判定定理
凸函数一个最基本的判定方法是,先将其限制在任意直线上,然后判断对应的一维函数是否是凸的
定理1: f ( x ) f(x) f(x)是凸函数当且仅当对任意的 x ∈ d o m f , v ∈ R n , g : R → R x{\in}domf,v{\in}R^n,g:R{\rightarrow}R x∈domf,v∈Rn,g:R→R,
g ( t ) = f ( x + t v ) , d o m g = { t ∣ x + t v ∈ d o m f } g(t)=f(x+tv), domg=\{t|x+tv{\in}domf\} g(t)=f(x+tv),domg={t∣x+tv∈domf}
是凸函数
具体证明说难也不难说简单也不简单,想弄明白的百度或者来和我探讨一下哈(我是看了大概二十分钟半小时才看懂TT)
这里先给出一些实际中经常遇到的一些凸(凹)函数吧
(1)指数函数: e a x , a , x ∈ R e^{ax},a,x{\in}R eax,a,x∈R是凸函数
(2)幂函数: x a ( x > 0 ) x^a(x>0) xa(x>0),当 α ≥ 1 \alpha{\ge}1 α≥1或 α ≤ 0 {\alpha}{\le}0 α≤0时为凸函数
(3)负熵: x l n x ( x > 0 ) xlnx(x>0) xlnx(x>0)是凸函数
(4)所有范数都是凸函数(向量和矩阵版本)
又来一个判断的定理2:对于定义在凸集上的可微函数 f f f, f f f是凸函数当且仅当
f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) , ∀ x , y ∈ d o m f f(y){\ge}f(x)+{\nabla}f(x)^T(y-x),{\forall}x,y{\in}dom f f(y)≥f(x)+∇f(x)T(y−x),∀x,y∈domf
具体证明的话同上说法,这个证明相对来说简单一点
这个定理说明可微凸函数 f f f的图形始终在任一点切线的上方,因此,用可微凸函数 f f f在任意一点的一阶近似可以得到 f f f的一个全局下界

定理3:梯度单调性,设 f f f为可微函数,则 f f f为凸函数当且仅当 d o m f domf domf为凸集且 ∇ f {\nabla}f ∇f为单调映射,即:
( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) ≥ 0 , ∀ x , y ∈ d o m f ({\nabla}f(x)-{\nabla}f(y))^T(x-y){\ge}0,{\forall}x,y{\in}domf (∇f(x)−∇f(y))T(x−y)≥0,∀x,y∈domf
具体证明也不说咯
推论:设 f f f为可微函数,且 d o m f domf domf是凸集,则
(1) f f f是严格凸函数当且仅当
( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) > 0 , ∀ x , y ∈ d o m f ({\nabla}f(x)-{\nabla}f(y))^T(x-y)>0,{\forall}x,y{\in}domf (∇f(x)−∇f(y))T(x−y)>0,∀x,y∈domf
(2) f f f是m-强凸函数当且仅当
( ∇ f ( x ) − ∇ f ( y ) ) T ( x − y ) ≥ m ∣ ∣ x − y ∣ ∣ 2 , ∀ x , y ∈ d o m f ({\nabla}f(x)-{\nabla}f(y))^T(x-y){\ge}m||x-y||^2,{\forall}x,y{\in}domf (∇f(x)−∇f(y))T(x−y)≥m∣∣x−y∣∣2,∀x,y∈domf
进一步的,如果函数二阶连续可微,我们可以得到下面的二阶条件
定理:
设 f f f为定义在凸集上的二阶连续可微函数,则 f f f是凸函数当且仅当
∇ 2 f ( x ) ≥ 0 , ∀ x ∈ d o m f {\nabla^2f(x){\ge}0},{\forall}x{\in}domf ∇2f(x)≥0,∀x∈domf
如果 ∇ 2 f ( x ) > 0 , ∀ x ∈ d o m f {\nabla}^2f(x)>0,{\forall}x{\in}domf ∇2f(x)>0,∀x∈domf,则 f h fh fh是严格凸函数
这个数分也有学,蛮好用的,当函数二阶连续可微时,用这个通常更方便些
2.5.3 保凸的运算
先总结一下之前证明一个函数是凸函数的三个方法:
(1)一是利用定义去验证凸性,通常将函数限制在一条直线上
(2)二是利用一阶条件,二阶条件证明函数的凸性
(3)三是直接研究 f f f的上方图 e p i f epif epif
现在 f f f可以由简单的凸函数通过一些保凸的运算得到
定理:
(1)若 f f f是凸函数,则 α f {\alpha}f αf是凸函数,其中 α ≥ 0 {\alpha}{\ge}0 α≥0
(2)若 f 1 , f 2 f_1,f_2 f1,f2是凸函数,则 f 1 + f 2 f_1+f_2 f1+f2是凸函数
(3)若 f f f是凸函数,则 f ( A x + b ) f(Ax+b) f(Ax+b)是凸函数
(4)若 f 1 , f 2 , . . . , f m f_1,f_2,...,f_m f1,f2,...,fm是凸函数,则 f ( x ) = m a x { f 1 ( x ) , f 2 ( x ) , . . . , f m ( x ) } f(x)=max\{f_1(x),f_2(x),...,f_m(x)\} f(x)=max{f1(x),f2(x),...,fm(x)}是凸函数
(5)若对每个 y ∈ A , f ( x , y ) y{\in}A,f(x,y) y∈A,f(x,y)关于 x x x是凸函数,则
g ( x ) = s u p y ∈ A f ( x , y ) g(x)={sup}_{y{\in}A}f(x,y) g(x)=supy∈Af(x,y)
是凸函数
(6)给定函数 g : R n → R , h : R → R g:R^n{\rightarrow}R,h:R{\rightarrow}R g:Rn→R,h:R→R,令 f ( x ) = h ( g ( x ) ) f(x)=h(g(x)) f(x)=h(g(x))若 g g g是凸函数, h h h是凸函数且单调不减,那么 f f f是凸函数,若 g g g是凹函数, h h h是凸函数且单调不增,那么 f f f是凸函数
(7)给定函数 g : R n → R k , h : R k → R g:R^n{\rightarrow}R^k,h:R^k{\rightarrow}R g:Rn→Rk,h:Rk→R,
f ( x ) = h ( g ( x ) ) = h ( g 1 ( x ) , g 2 ( x ) , . . . , g k ( x ) ) f(x)=h(g(x))=h(g_1(x),g_2(x),...,g_k(x)) f(x)=h(g(x))=h(g1(x),g2(x),...,gk(x))
若 g i g_i gi是凸函数, h h h是凸函数且关于每个分量单调不减,那么 f f f是凸函数,若 g i g_i gi是凹函数, h h h是凸函数且单调不增,那么 f f f是凸函数
(8)若 f ( x , y ) f(x,y) f(x,y)关于 ( x , y ) (x,y) (x,y)整体是凸函数, C C C是凸集,则
g ( x ) = i n f y ∈ C f ( x , y ) g(x)=inf_{y{\in}C}f(x,y) g(x)=infy∈Cf(x,y)
是凸函数
(9)定义函数 f : R n → R f:R^n{\rightarrow}R f:Rn→R的透视函数 g : R n ∗ R → R g:R^n*R{\rightarrow}R g:Rn∗R→R
g ( x , t ) = t f ( x t ) , d o m g = { ( x , t ) ∣ x t ∈ d o m f , t > 0 } g(x,t)=tf(\frac{x}{t}),domg=\{{(x,t)}|\frac{x}{t}{\in}domf,t>0\} g(x,t)=tf(tx),domg={(x,t)∣tx∈domf,t>0}
若f是凸函数,则g是凸函数
2.5.4 凸函数的性质
1.连续性
首先先说明,前面的任何定理或者证明都没有说明凸函数是连续函数,但下面这个定理说明凸函数在定义域中内点是连续的
定理:设 f : R n → ( − ∞ , + ∞ ) f:R^n{\rightarrow}(-{\infty},+{\infty}) f:Rn→(−∞,+∞)为凸函数,对任一点 x 0 ∈ i n t d o m f x_0{\in}intdomf x0∈intdomf,有 f f f在 x 0 x_0 x0处连续,这里 i n t d o m f intdomf intdomf表示定义域 d o m f domf domf的内点
内点定义:这个点存在一个领域全含于定义域

推论:设 f ( x ) f(x) f(x)是凸函数,且 d o m f domf domf是开集,则 f ( x ) f(x) f(x)在 d o m f domf domf上是连续的
原因是很简单,开集内的点都是内点
2.凸下水平集
凸函数的所有下水平集都是凸集,即有如下结果
设 f ( x ) f(x) f(x)是凸函数,则 f ( x ) f(x) f(x)所有的 α {\alpha} α-下水平集 C α C_{\alpha} Cα为凸集
到此为了复习一下前面的内容,证明一下
设 x 1 . x 2 ∈ C α x_1.x_2{\in}C_{\alpha} x1.x2∈Cα,对任意的 θ ∈ ( 0 , 1 ) {\theta}{\in}(0,1) θ∈(0,1),首先根据 f ( x ) f(x) f(x)的凸性我们有
f ( θ x 1 + ( 1 − θ ) x 2 ) ≤ θ f ( x 1 ) + ( 1 − θ ) f ( x 2 ) ≤ θ α + ( 1 − θ ) α = α f({\theta}x_1+(1-{\theta})x_2){\le}{\theta}f(x_1)+(1-{\theta})f(x_2){\le}{\theta}{\alpha}+(1-{\theta}){\alpha}={\alpha} f(θx1+(1−θ)x2)≤θf(x1)+(1−θ)f(x2)≤θα+(1−θ)α=α
这样就能证毕了,还不懂的可以翻回去看看
3.二次下界
强凸函数具有二次下界的性质
(二次下界)设 f ( x ) f(x) f(x)是参数为 m m m的可微强凸函数,则如下不等式成立:
f ( y ) ≥ f ( x ) + ∇ f ( x ) T ( y − x ) + m 2 ∣ ∣ y − x ∣ ∣ 2 , ∀ x , y ∈ d o m f f(y){\ge}f(x)+{\nabla}f(x)^T(y-x)+{\frac{m}{2}}||y-x||^2,{\forall}x,y{\in}domf f(y)≥f(x)+∇f(x)T(y−x)+2m∣∣y−x∣∣2,∀x,y∈domf
这里证明就不给出了,利用二次下界容易推出可微强凸函数的下水平集都是有界的
推论:设 f f f为可微强凸函数,则 f f f的所有 α {\alpha} α-下水平集有界
2.6 共轭函数
2.6.1 共轭函数的定义和例子
共轭函数是凸分析中的一个重要概念
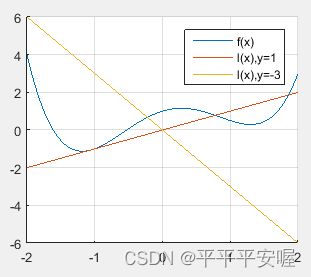
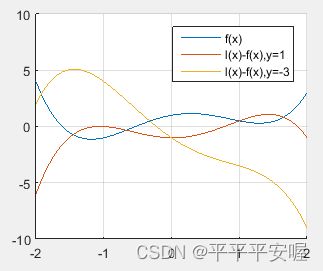
共轭函数定义:任一适当函数 f f f的共轭函数定义为
f ∗ ( y ) ≤ s u p { y T x − f ( x ) } , x ∈ d o m f f^*(y){\le}sup\{y^Tx-f(x)\},x{\in}domf f∗(y)≤sup{yTx−f(x)},x∈domf
简单点来说就是线性函数 y T x y^Tx yTx与f(x)的最大差值
对于每一个y,我们看图应该就很好明白了
设 f f f为 R R R上的适当函数,对任何函数 f f f都可以定义共轭函数,共轭函数 f ∗ f^* f∗恒为凸函数
借用一下知乎上对共轭函数的作用的说明

对于共轭函数,我们有以下重要的不等式
Fenchel不等式
f ( x ) + f ∗ ( y ) ≥ x T y f(x)+f^*(y){\ge}x^Ty f(x)+f∗(y)≥xTy
以下我们给出一些常见函数的共轭函数
1.二次函数
考虑二次函数
f ( x ) = 1 2 x T A x + b T x + c f(x)=\frac{1}{2}x^TAx+b^Tx+c f(x)=21xTAx+bTx+c
(1)强凸情形( A > 0 A>0 A>0):
f ∗ ( y ) = 1 2 ( y − b ) T A − 1 ( y − b ) − c f^*(y)=\frac{1}{2}(y-b)^TA^{-1}(y-b)-c f∗(y)=21(y−b)TA−1(y−b)−c
(2)一般凸情形( A ≥ 0 A{\ge}0 A≥0):
f ∗ ( y ) = 1 2 ( y − b ) T A + ( y − b ) − c , d o m f ∗ = R ( A ) + b f^*(y)=\frac{1}{2}(y-b)^TA^+(y-b)-c,domf^*=R(A)+b f∗(y)=21(y−b)TA+(y−b)−c,domf∗=R(A)+b
这里R(A)为A的像空间
像空间就是值域,这个 A + A^+ A+是什么意思我还没搞明白
2.凸集的示性函数
给定凸集C,其示性函数为
I C ( x ) = { 0 x ∈ C + ∞ x ∉ C I_C(x)= \begin{cases} 0& \text{x$\in$C}\\ +{\infty}& \text{x$\notin$C} \end{cases} IC(x)={0+∞x∈Cx∈/C
可知对应的共轭函数为
I c ∗ ( y ) = s u p x { y T x − I C ( x ) } = s u p x ∈ C y T x I_c^*(y)=sup_x\{y^Tx-I_C(x)\}=sup_{x{\in}C}y^Tx Ic∗(y)=supx{yTx−IC(x)}=supx∈CyTx
这里 I C ∗ I_C^* IC∗又称为凸集 C C C的支撑函数
3.范数
范数的共轭函数为其单位对偶范数球的示性函数,即若 f ( x ) = ∣ ∣ x ∣ ∣ f(x)=||x|| f(x)=∣∣x∣∣,则
f ∗ ( x ) = { 0 ∣ ∣ y ∣ ∣ ∗ ≤ 1 + ∞ ∣ ∣ y ∣ ∣ ∗ > 1 f^*(x)= \begin{cases} 0& \text{{$||y||_*$}$\le$1}\\ +{\infty}& \text{{$||y||_*$}$>$1} \end{cases} f∗(x)={0+∞∣∣y∣∣∗≤1∣∣y∣∣∗>1

2.6.2 二次共轭函数
(二次共轭函数)任一函数 f f f的二次共轭函数定义为
f ∗ ∗ ( x ) = s u p y ∈ d o m f ∗ s u p { x T y − f ∗ ( y ) } f^{**}(x)=sup_{y{\in}domf^*}sup\{x^Ty-f^*(y)\} f∗∗(x)=supy∈domf∗sup{xTy−f∗(y)}
显然 f ∗ ∗ f^{**} f∗∗恒为闭凸函数(虽然我也不知道哪里显然了),由Fenchel不等式可知
f ∗ ∗ ( x ) ≤ f ( x ) , ∀ x f^{**}(x){\le}f(x),{\forall}x f∗∗(x)≤f(x),∀x
或等价的, e p i f = e p i f ∗ ∗ epif=epif^{**} epif=epif∗∗
定理:若 f f f为闭凸函数,则
f ∗ ∗ ( x ) = f ( x ) , ∀ x f^{**}(x)=f(x),{\forall}x f∗∗(x)=f(x),∀x
或等价的, e p i f = e p i f ∗ ∗ epif=epif^{**} epif=epif∗∗
具体的证明这里就不过多阐述了
2.7 次梯度
2.7.1 次梯度的定义
前面介绍了可微函数的梯度,但是对于一般的函数,之前定义的梯度不一定存在,对于凸函数,类比梯度的一阶性质,我们可以引入次梯度的概念
(次梯度)设 f f f为适当凸函数, x x x为定义域 d o m f domf domf中的一点 ,若向量 g ∈ R n g{\in}R^n g∈Rn满足
f ( y ) ≥ f ( x ) + g T ( y − x ) , ∀ y ∈ d o m f f(y){\ge}f(x)+g^T(y-x),{\forall}y{\in}domf f(y)≥f(x)+gT(y−x),∀y∈domf
则称 g g g为函数 f f f在点 x x x处的一个次梯度,进一步的,称集合
∂ f ( x ) = { g ∣ g ∈ R n , f ( y ) ≥ f ( x ) + g T ( y − x ) , ∀ y ∈ d o m f } {\partial}f(x)=\{g|g{\in}R^n,f(y){\ge}f(x)+g^T(y-x),{\forall}y{\in}domf\} ∂f(x)={g∣g∈Rn,f(y)≥f(x)+gT(y−x),∀y∈domf}
为 f f f在点 x x x处的次微分

可以看出,次梯度实际上借鉴了凸函数判定定理的一阶条件,定义次梯度的初衷之一也是希望他具有类似于梯度的一些性质
从次梯度的定义可以直接推出,若 g g g是 f ( x ) f(x) f(x)在 x 0 x_0 x0处的次梯度,则函数
l ( x ) = f ( x 0 ) + g T ( x − x 0 ) l(x)=f(x_0)+g^T(x-x_0) l(x)=f(x0)+gT(x−x0)
为凸函数 f ( x ) f(x) f(x)的一个全局下界,此外,次梯度 g g g可以诱导出上方图 e p i f epif epif在点 ( x , f ( x ) ) (x,f(x)) (x,f(x))处的一个支撑超平面
接下来一个问题就是,次梯度在什么条件下是存在的?实际上对一般凸函数 f f f而言, f f f未必在所有的点处都存在次梯度,但对于定义域中的内点, f f f在其上的次梯度总是存在的
定理:设 f f f为凸函数, d o m f domf domf为其定义域,如果 x ∈ i n t d o m f x{\in}intdomf x∈intdomf,则 ∂ f ( x ) {\partial}f(x) ∂f(x)是非空的
次梯度呢你可以理解成用于处理在某些点上不可微的函数。在这种情况下,我们可以计算次梯度的集合,表示函数在该点的所有可能梯度范围。
2.7.2 次梯度的性质
凸函数 f ( x ) f(x) f(x)的次梯度和次微分有许多有用的性质,下面的定理说明次微分 ∂ f ( x ) {\partial}f(x) ∂f(x)在一定条件下分别为闭凸集合非空有界集
(定理)设 f f f是凸函数, ∂ f ( x ) {\partial}f(x) ∂f(x)有如下性质:
(1)对任何 x ∈ d o m f x{\in}domf x∈domf, ∂ f ( x ) {\partial}f(x) ∂f(x)是一个闭凸集(可能是空集)
(2)如果 x ∈ i n t d o m f x{\in}intdomf x∈intdomf,则 ∂ f ( x ) {\partial}f(x) ∂f(x)为非空有界集
PS:闭集:一个包含其所有极限点的集合(一个补集为开集的集合)
证明此处略
当凸函数 f ( x ) f(x) f(x)在某点处可微时, ∇ f ( x ) {\nabla}f(x) ∇f(x)就是 f ( x ) f(x) f(x)在该点处唯一的次梯度
即设 f ( x ) f(x) f(x)在 x 0 ∈ i n t d o m f x_0{\in}intdomf x0∈intdomf处可微,则
∂ f ( x 0 ) = { ∇ f ( x 0 ) } {\partial}f(x_0)=\{{\nabla}f(x_0)\} ∂f(x0)={∇f(x0)}
定理(次梯度的单调性):设 f : R n → R f:R^n{\rightarrow}R f:Rn→R为凸函数, x , y ∈ d o m f x,y{\in}domf x,y∈domf,则
( u − v ) T ( x − y ) ≥ 0 (u-v)^T(x-y){\ge}0 (u−v)T(x−y)≥0
其中 u ∈ ∂ f ( x ) , v ∈ ∂ f ( y ) u{\in}{\partial}f(x),v{\in}{\partial}f(y) u∈∂f(x),v∈∂f(y)
这个证明还蛮好证的
对于闭凸函数(即凸下半连续函数),次梯度还有某种连续性
定理:设 f ( x ) f(x) f(x)是闭凸函数且 ∂ f ( x ) {\partial}f(x) ∂f(x)在点 x x x附近存在且非空,若序列 x k → x ˉ x^k{\rightarrow}\bar{x} xk→xˉ, g k ∈ ∂ f ( x k ) g^k{\in}{\partial}f(x^k) gk∈∂f(xk)为 f ( x ) f(x) f(x)在点 x k x^k xk处的次梯度,且 g k → g ˉ g^k{\rightarrow}\bar{g} gk→gˉ,则 g ˉ ∈ ∂ f ( x ˉ ) \bar{g}{\in}{\partial}f(\bar{x}) gˉ∈∂f(xˉ)
证明有用到那个连续性,这里略
2.7.3 凸函数的方向导数
在数分中,我们知道方向导数的概念,设 f f f为适当函数,给定点 x 0 x_0 x0以及方向 d ∈ R n d{\in}R^n d∈Rn,方向导数(若存在)定义为
lim t ↓ 0 ϕ ( t ) = lim t ↓ 0 f ( x 0 + t d ) − f ( x 0 ) t \lim_{t{\downarrow}0}\phi(t)=\lim_{t{\downarrow}0}\frac{f(x_0+td)-f(x_0)}{t} t↓0limϕ(t)=t↓0limtf(x0+td)−f(x0)
其中 t ↓ 0 t{\downarrow}0 t↓0表示 t t t单调下降趋于0,对于凸函数 f ( x ) f(x) f(x),易知 ϕ ( t ) {\phi(t)} ϕ(t)在 ( 0 , + ∞ ) (0,+{\infty}) (0,+∞)上是单调不减的,上述此时极限总是存在(可以为无穷),所以凸函数总是可以定义方向导数
定义(方向导数):对于凸函数 f f f,给定点 x 0 ∈ d o m f x_0{\in}domf x0∈domf以及方向 d ∈ R n d{\in}R^n d∈Rn,其方向导数定义为
∂ f ( x 0 ; d ) = inf t > 0 f ( x 0 + t d ) − f ( x 0 ) t {\partial}f(x_0;d)=\inf_{t>0}\frac{f(x_0+td)-f(x_0)}{t} ∂f(x0;d)=t>0inftf(x0+td)−f(x0)
方向导数可能是正负无穷,但在定义域的内点处方向导数是有限的
即设 f ( x ) f(x) f(x)为凸函数, x 0 ∈ i n t d o m f x_0{\in}intdomf x0∈intdomf,则对任意 d ∈ R n , ∂ f ( x 0 ; d ) d{\in}R^n,{\partial}f(x_0;d) d∈Rn,∂f(x0;d)有限
凸函数的方向导数和次梯度之间有很强的联系,以下结果表明,凸函数 f ( x ) f(x) f(x)关于 d d d的方向导数 ∂ f ( x ; d ) {\partial}f(x;d) ∂f(x;d)正是 f f f在点 x x x处的所有次梯度与 d d d的内积的最大值
定理:设 f : R n → ( − ∞ , + ∞ ] f:R^n{\rightarrow}(-{\infty},+{\infty}] f:Rn→(−∞,+∞]为凸函数,点 x 0 ∈ i n t d o m f x_0{\in}intdomf x0∈intdomf, d d d为 R n R^n Rn中任一方向,则
∂ f ( x 0 ; d ) = max g ∈ ∂ f ( x 0 ) g T d {\partial}f(x_0;d)=\max_{g{\in}{\partial}f(x_0)}g^Td ∂f(x0;d)=g∈∂f(x0)maxgTd
以上定理可对一般的 x ∈ d o m f x{\in}domf x∈domf作如下推广
定理:设 f f f为适当凸函数,且在 x 0 x_0 x0处次微分不为空集,则对任意 d ∈ R n d{\in}R^n d∈Rn有
∂ f ( x 0 ; d ) = sup g ∈ ∂ f ( x 0 ) g T d {\partial}f(x_0;d)=\sup_{g{\in}{\partial}f(x_0)}g^Td ∂f(x0;d)=g∈∂f(x0)supgTd
当 ∂ f ( x 0 ; d ) {\partial}f(x_0;d) ∂f(x0;d)不为无穷时,上确界可以取到
2.7.4 次梯度的计算规则
如何计算一个不可微凸函数的次梯度在优化算法设计中是很重要的一个问题,如果根据定义去计算次梯度的话一般来说比较繁琐,我们来介绍一些次梯度的计算规则,本小节讨论的都默认 x ∈ i n t d o m f x{\in}intdomf x∈intdomf
1.基本规则
我们首先不加证明的给出一些计算次梯度(次微分)的基本规则
(1)可微凸函数:设 f f f为凸函数,若 f f f在点 x x x处可微,则 ∂ f ( x ) = { ∇ f ( x ) } {\partial}f(x)=\{{\nabla}f(x)\} ∂f(x)={∇f(x)}
(2)凸函数的非负线性组合:设 f 1 , f 2 f_1,f_2 f1,f2为凸函数,且满足
i n t d o m f ! ∩ i n t d o m f 2 ≠ ∅ intdomf_!{\cap}intdomf_2{\not=}{\varnothing} intdomf!∩intdomf2=∅
而 x ∈ i n t d o m f ! ∩ i n t d o m f 2 x{\in}intdomf_!{\cap}intdomf_2 x∈intdomf!∩intdomf2,若
f ( x ) = α 1 f 1 ( x ) + α 2 f 2 ( x ) , α 1 , α 2 ≥ 0 f(x)={\alpha}_1f_1(x)+{\alpha}_2f_2(x),{\alpha}_1,{\alpha}_2{\ge}0 f(x)=α1f1(x)+α2f2(x),α1,α2≥0
则 f ( x ) f(x) f(x)的次微分
∂ f ( x ) = α 1 ∂ f 1 ( x ) + α 2 ∂ f 2 ( x ) {\partial}f(x)={\alpha}_1{\partial}f_1(x)+{\alpha}_2{\partial}f_2(x) ∂f(x)=α1∂f1(x)+α2∂f2(x)
(3)线性变量替换:设 h h h为适当函数,并且函数 f f f满足
f ( x ) = h ( A x + b ) , ∀ x ∈ R m f(x)=h(Ax+b),{\forall}x{\in}R^m f(x)=h(Ax+b),∀x∈Rm
其中 A ∈ R n ∗ m , b ∈ R n A{\in}R^{n*m},b{\in}R^n A∈Rn∗m,b∈Rn,若存在 x ∗ ∈ R m x^*{\in}R^m x∗∈Rm,使得 A x ∗ + b ∈ i n t d o m h Ax^*+b{\in}intdomh Ax∗+b∈intdomh,则
∂ f ( x ) = A T ∂ h ( A x + b ) , ∀ x ∈ i n t d o m f {\partial}f(x)=A^T{\partial}h(Ax+b),{\forall}x{\in}intdomf ∂f(x)=AT∂h(Ax+b),∀x∈intdomf
2.两个函数之和的次梯度
以下的 M o r e a u − R o c k a f e l l a r Moreau-Rockafellar Moreau−Rockafellar定理给出两个凸函数之和的次微分的计算方法
定理(Moreau-Rockafellar):设 f 1 , f 2 : R n → ( − ∞ , + ∞ ] f_1,f_2:R^n{\rightarrow}(-{\infty},+{\infty}] f1,f2:Rn→(−∞,+∞]是两个凸函数,则对任意的 x 0 ∈ R n x_0{\in}R^n x0∈Rn,
∂ f 1 ( x 0 ) + ∂ f 2 ( x 0 ) ⊆ ∂ ( f 1 + f 2 ) ( x 0 ) {\partial}f_1(x_0)+{\partial}f_2(x_0){\subseteq}{\partial}(f_1+f_2)(x_0) ∂f1(x0)+∂f2(x0)⊆∂(f1+f2)(x0)
进一步的,若 i n t d o m f 1 ∩ i n t d o m f 2 ≠ ∅ intdomf_1{\cap}intdomf_2{\not=}{\varnothing} intdomf1∩intdomf2=∅,则对任意的 x 0 ∈ R n x_0{\in}R^n x0∈Rn
∂ ( f 1 + f 2 ) ( x 0 ) = ∂ f 1 ( x 0 ) + ∂ f 2 ( x 0 ) {\partial}(f_1+f_2)(x_0)={\partial}f_1(x_0)+{\partial}f_2(x_0) ∂(f1+f2)(x0)=∂f1(x0)+∂f2(x0)
证明略
3.函数族的上确界
容易验证一族凸函数的上确界函数扔是凸函数,我们有如下重要结果:
定理(Dubovitskii-Milyutin)设 f 1 , f 2 , ⋯ , f m : R n → ( − ∞ , + ∞ ] f_1,f_2,\cdots,f_m:R^n{\rightarrow}(-{\infty},+{\infty}] f1,f2,⋯,fm:Rn→(−∞,+∞]均为凸函数,令
f ( x ) = m a x { f 1 ( x ) , f 2 ( x ) , ⋯ , f m ( x ) } , ∀ x ∈ R n f(x)=max\{f_1(x),f_2(x),\cdots,f_m(x)\},{\forall}x{\in}R^n f(x)=max{f1(x),f2(x),⋯,fm(x)},∀x∈Rn
对 x 0 ∈ ∩ i = 1 m i n t d o m f i x_0{\in}{\cap_{i=1}^m}intdomf_i x0∈∩i=1mintdomfi,定义 I ( x 0 ) = { i ∣ f i ( x 0 ) = f ( x 0 ) } I(x_0)=\{i|f_i(x_0)=f(x_0)\} I(x0)={i∣fi(x0)=f(x0)},则
∂ f ( x 0 ) = c o n v ∪ i ∈ I ( x 0 ) ∂ f i ( x 0 ) {\partial}f(x_0)=conv{\cup}_{i{\in}I(x_0)}{\partial}f_i(x_0) ∂f(x0)=conv∪i∈I(x0)∂fi(x0)
具体证明略,这里也许会不太明白conv是什么,如下

4. 固定分量的函数极小值
设 h : R n ∗ R m → ( − ∞ , + ∞ ] h:R^n*R^m{\rightarrow}(-{\infty},+{\infty}] h:Rn∗Rm→(−∞,+∞]是关于 ( x , y ) (x,y) (x,y)的凸函数,则 f ( x ) = inf y h ( x , y ) f(x)=\inf_yh(x,y) f(x)=infyh(x,y)是关于 x ∈ R n x{\in}R^n x∈Rn的凸函数,以下结果可以用于求解 f f f在点 x x x处的一个次梯度
定理:考虑函数
f ( x ) = inf y h ( x , y ) f(x)=\inf_yh(x,y) f(x)=yinfh(x,y)
其中
h : R n ∗ R m → ( − ∞ , + ∞ ] h:R^n*R^m{\rightarrow}(-{\infty},+{\infty}] h:Rn∗Rm→(−∞,+∞]
是关于 ( x , y ) (x,y) (x,y)的凸函数,对 x ^ ∈ R n \hat{x}{\in}R^n x^∈Rn,设 y ^ ∈ R m {\hat{y}{\in}R^m} y^∈Rm满足 h ( x ^ , y ^ ) = f ( x ^ ) h({\hat{x}},{\hat{y}})=f(\hat{x}) h(x^,y^)=f(x^),且存在 g ∈ R n g{\in}R^n g∈Rn使得 ( g , 0 ) ∈ ∂ f ( x ^ ) (g,0){\in}{\partial}f(\hat{x}) (g,0)∈∂f(x^),则 g ∈ ∂ f ( x ^ ) g{\in}{\partial}f(\hat{x}) g∈∂f(x^)
说实话这几个东西都挺抽象的,后面配点练习去做可能就好很多
5.复合函数
对于复合函数的次梯度,我们有如下链式法则
定理:设 f 1 , f 2 , ⋯ , f m : R n → ( − ∞ , + ∞ ] f_1,f_2,\cdots,f_m:R^n{\rightarrow}(-{\infty},+{\infty}] f1,f2,⋯,fm:Rn→(−∞,+∞]为m个凸函数, h : R m → ( − ∞ , + ∞ ] h:R^m{\rightarrow}(-{\infty},+{\infty}] h:Rm→(−∞,+∞]为关于各分量单调递增的凸函数,令
f ( x ) = h ( f 1 ( x ) , f 2 ( x ) , ⋯ , f m ( x ) ) f(x)=h(f_1(x),f_2(x),\cdots,f_m(x)) f(x)=h(f1(x),f2(x),⋯,fm(x))
设 z = ( z 1 , z 2 , ⋯ , z m ) ∈ ∂ h ( f 1 ( x ^ ) , f 2 ( x ^ ) , ⋯ , f m ( x ^ ) ) z=(z_1,z_2,\cdots,z_m){\in}{\partial}h(f_1(\hat{x}),f_2(\hat{x}),\cdots,f_m(\hat{x})) z=(z1,z2,⋯,zm)∈∂h(f1(x^),f2(x^),⋯,fm(x^)),以及 g 1 ∈ ∂ f i ( x ^ ) g_1{\in}{\partial}f_i(\hat{x}) g1∈∂fi(x^),则
g = z 1 g 1 , z 2 g 2 , ⋯ , z m g m ∈ ∂ f ( x ^ ) g=z_1g_1,z_2g_2,\cdots,z_mg_m{\in}{\partial}f(\hat{x}) g=z1g1,z2g2,⋯,zmgm∈∂f(x^)
就是 g g g为 f f f在点 x ^ \hat{x}