Spark基础学习——RDD算子
一、RDD算子
Spark提供了丰富的用于操作RDD的方法,这些方法被称为算子。一个创建完成的RDD只支持两种算子:转化算子和行动算子。
二、准备
(一)准备数据文件
1.在 /home 目录下创建 words.txt 文件,在文件中写入一段数据

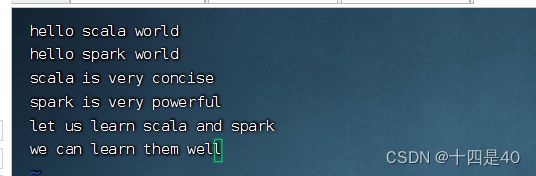
2.将 words.txt上传到HDFS系统的 /park 目录里 (创建/park命令:hdfs dfs -mkdir /park)
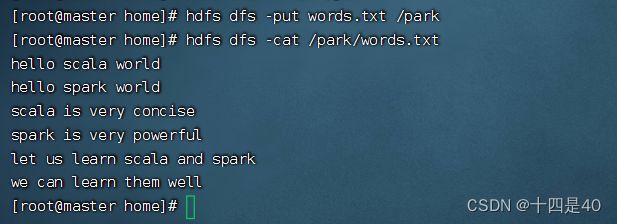
命令:hdfs dfs -put words.txt /park
3.查看HDFS系统 /park/words.txt内容
命令:hdfs dfs -cat /park/words.txt
(二)启动Spark Shell
1.启动HDFS服务
命令:start-dfs.sh
2.启动Spark服务
进入Spark的sbin目录执行命令:./start-all.sh
3.启动Spark
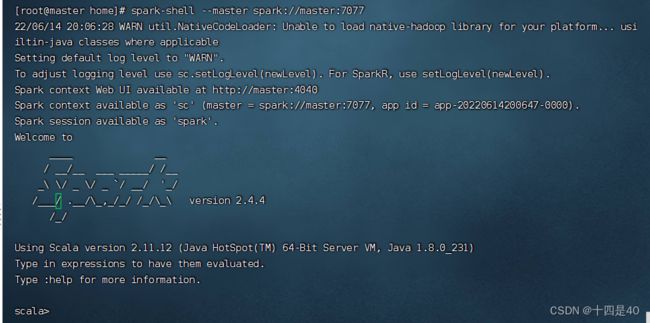
执行名命令: spark-shell --master spark://master:7077
三、转化算子
转化算子负责对RDD中的数据进行计算并转化为新的RDD。Spark中的所有转化算子都是惰性的,因为它们不会立即计算结果,而只是记住对某个RDD的具体操作过程,直到遇到行动算子才会与行动算子一起执行。
(一)映射算子——map()
1.映射算子功能
map()是一种转化算子,它接收一个函数作为参数,并把这个函数应用于RDD的每个元素,最后将函数的返回结果作为结果RDD中对应元素的值。
2.映射算子案例
预备工作:创建一个RDD - rdd1
执行命令:val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6))

任务1、将rdd1每个元素翻倍得到rdd2
对rdd1应用map()算子,将rdd1中的每个元素平方并返回一个名为rdd2的新RDD

利用神奇占位符_可以写得更简洁

若需要查看计算结果,则可使用行动算子collect()。(collect是采集或收集之意)

(二)过滤算子 - filter()
1、过滤算子功能
filter(func):通过函数func对源RDD的每个元素进行过滤,并返回一个新RDD,一般而言,新RDD元素个数会少于原RDD。
2、过滤算子案例
任务1、过滤出列表中的偶数
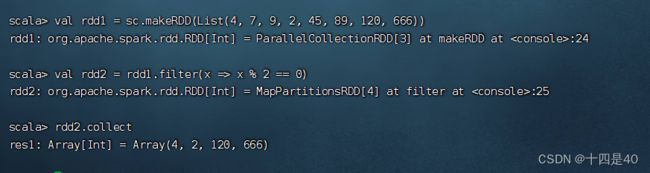
基于列表创建RDD,然后利用过滤算子得到偶数构成的新RDD
基于列表创建 rdd1 :val rdd1 = sc.makeRDD(List(4, 7, 9, 2, 45, 89, 120, 666))
然后利用过滤算子得到偶数构成的 rdd2 :val rdd2 = rdd1.filter(x => x % 2 == 0)
任务2、过滤出文件中包含spark的行
查看源文件/park/words.txt内容
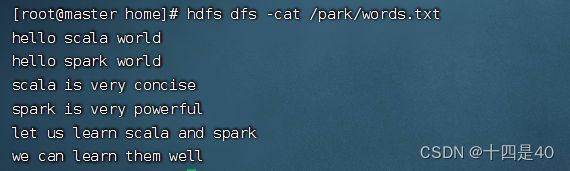
执行命令: val lines= sc.textFile("hdfs://master:9000/park/words.txt"),读取文件 /park/words.txt生成RDD - lines

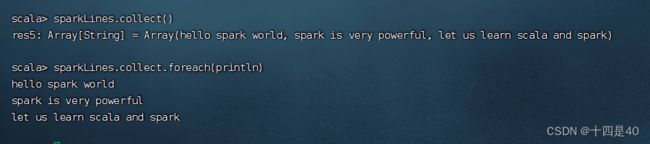
执行命令:val sparkLines = lines.filter(_.contains("spark")),过滤包含spark的行生成RDD - sparkLines

执行命令:sparkLines.collect(),查看sparkLines内容,可以采用遍历算子,分行输出内容
(三)扁平映射算子 - flatMap()
1、扁平映射算子功能
flatMap()算子与map()算子类似,但是每个传入给函数func的RDD元素会返回0到多个元素,最终会将返回的所有元素合并到一个RDD。
2、扁平映射算子案例
任务1、统计文件中单词个数
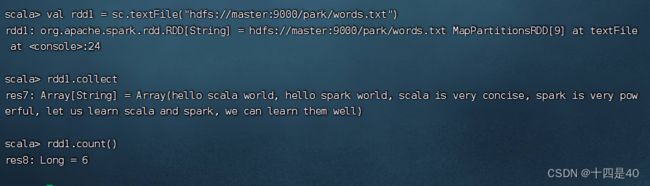
读取文件,生成RDD - rdd1,查看其内容和元素个数
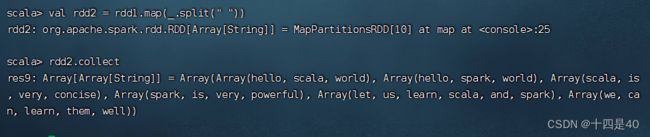
对于rdd1按空格拆分,做映射,生成新RDD - rdd2
对于rdd1按空格拆分,做扁平映射,生成新RDD - rdd3

大家可以看到,经过扁平映射,生成的RDD是一个单词构成一个元素,而rdd1是6行单词构成6个元素
执行命令:rdd3.count(),即可知单词个数

(四)按键归约算子 - reduceByKey()
1、按键归约算子功能
reduceByKey()算子的作用对像是元素为(key,value)形式(Scala元组)的RDD,使用该算子可以将相同key的元素聚集到一起,最终把所有相同key的元素合并成一个元素。该元素的key不变,value可以聚合成一个列表或者进行求和等操作。最终返回的RDD的元素类型和原有类型保持一致。
2、按键归约算子案例
任务1、在Spark Shell里计算学生总分
成绩表,包含四个字段(姓名、语文、数学、英语),只有三条记录
创建成绩列表scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内
进入 :paste模式,执行如下命令:
val scores = List(("张钦林",78),("张钦林",90),("张钦林",76),
("陈燕文",95),("陈燕文",88),("陈燕文",98),
("卢志刚",78),("卢志刚",80),("卢志刚",60))
val rdd1 = sc.makeRDD(scores)
val rdd2 = rdd1.reduceByKey((x,y)=>x+y)
rdd2.collect.foreach(println)
