ShardingSphere-JDBC(一)分库分表实战.md
本文主要分享了基于Spring Boot + Druid + MyBatis + ShardingSphere-JDBC的分库分表和读写分离案例,项目中示例代码见地址 分库分表.
一、ShardingSphere-JDBC介绍
1、ShardingSphere
实际上 ShardingSphere 包含3个部分:ShardingSphere-JDBC、 ShardingSphere-Proxy、 ShardingSphere-Sidecar。
- ShardingSphere-JDBC 采⽤⽆中⼼化架构,适⽤于 Java 开发的⾼性能的轻量级 OLTP(关系型数据库) 应⽤;
- ShardingSphere-Proxy 提供静态⼊口以及异构语⾔的⽀持,适⽤于 OLAP 应⽤(侧重于查询和决策,一般用于数据仓库)以及对分⽚数据库 进⾏管理和运维的场景。
比较合适的架构为JDBC 和Proxy混布架构:
2、ShardingSphere-JDBC
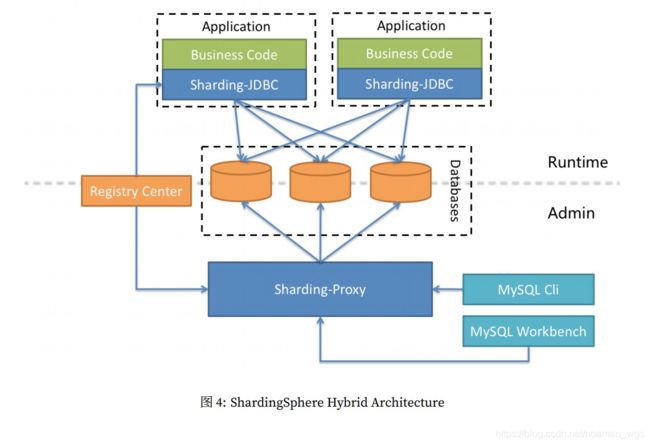
ShardingSphere-JDBC是轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使⽤客⼾端直连数据库,以 jar 包形式 提供服务,⽆需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingSphere-JDBC的架构图如下:

其中,ShardingSphere-JDBC的分片策略配置有:
- 数据源分⽚策略(分库):对应于 DatabaseShardingStrategy。⽤于配置数据被分配的⽬标数据源
- 表分⽚策略(分表):对应于 TableShardingStrategy。⽤于配置数据被分配的⽬标表,该⽬标表存在与该数据的⽬标数据源内,故表分⽚策略是依赖与数据源分⽚策略的结果的。
二、ShardingSphere-JDBC快速入门
下面主要介绍ShardingSphere-JDBC的数据分片和读写分离的功能实现。
1、数据分片(分库分表)
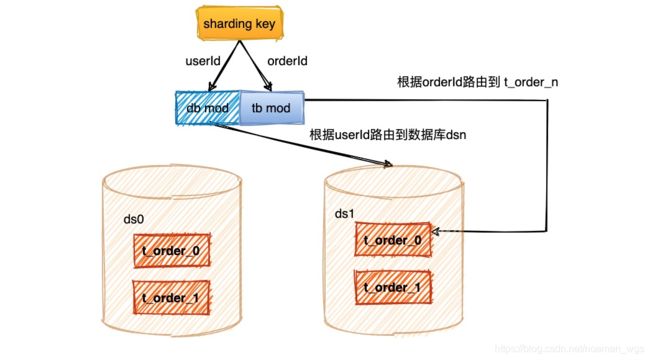
本文使用2库4表来模拟分库分表过程,首先根据userId 取模来决定路由到哪个库;然后根据订单id取模来决定路由到哪张表。模型如下:
2.1、引⼊ 核心的maven 依赖
<dependency>
<groupId>io.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>${sharding-jdbc-version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.mybatis.spring.bootgroupId>
<artifactId>mybatis-spring-boot-starterartifactId>
<version>${mybatis-spring-boot-starter-version}version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>${druid-version}version>
dependency>
2.2 、建立两个order库,分别为库order0和order1,每个库中有2张表:t_order_0和t_order_1,共2库4表来模拟分库分表过程。建表DML语句见项目工程中路径 resouces/scripts/t_order.sql.
2.3、使用mybatis自动生成工具生成mapper接口和xml文件:
- OrderMapper.xml
- OrderMapper.java
2.4、ShardingSphere-JDBC配置(重点):application-sharding.yml
(1)首先配置数据源:order0,order1,这两个数据源就对应两个数据库名称;
(2)然后配置两个数据源的druid连接池参数;
(3)配置分库和分表规则:分库按照user_id进行分片,分库规则order$->{user_id % 2}表示user_id % 2 == 0 时路由到 order0库,user_id % 2 == 1时路由到order1库;
分表按照order_id进行分片,分表规则t_order_$->{order_id % 2}表示 order_id % 2 == 0 时路由到 t_order_0表,order_id % 2 == 1时路由到t_order_1表;
# Druid连接池参数配置
initialSize: 5 # 初始化大小,最小,最大
minIdle: 5 # 最小连接池数量
maxIdle: 100 # 最大连接池数量
maxActive: 20 # 配置获取连接等待超时的时间
maxWait: 60000 # 检测连接是否有效的sql
timeBetweenEvictionRunsMillis: 60000 # 配置间隔多久才进行一次检测,关闭的空闲连接,单位是毫秒
minEvictableIdleTimeMillis: 300000 # 连接在池中最小生存的时间,单位是毫秒
# sharding-jdbc数据源分片配置
sharding:
jdbc:
# 数据源名称,多数据源以逗号分隔
datasource:
names: order0,order1
# 配置数据源Druid连接池参数
order0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.176.50:3306/order0?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8
username: root
password: *****
initialSize: ${initialSize}
minIdle: ${minIdle}
maxActive: ${maxActive}
maxWait: ${maxWait}
validationQuery: SELECT 1 FROM DUAL
timeBetweenEvictionRunsMillis: ${timeBetweenEvictionRunsMillis}
minEvictableIdleTimeMillis: ${minEvictableIdleTimeMillis}
order1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://114.215.176.50:3306/order1?useUnicode=true&characterEncoding=utf8&useSSL=true&serverTimezone=GMT%2B8
username: root
password: ****
initialSize: ${initialSize}
minIdle: ${minIdle}
maxActive: ${maxActive}
maxWait: ${maxWait}
validationQuery: SELECT 1 FROM DUAL
timeBetweenEvictionRunsMillis: ${timeBetweenEvictionRunsMillis}
minEvictableIdleTimeMillis: ${minEvictableIdleTimeMillis}
# 默认数据源
config:
sharding:
default-data-source-name: order0
# 分库分表配置:根据user_id取模分库,根据order_id取模分表
## 分库配置,按user_id取模运算,奇数在order1库,偶数在order0库
default-database-strategy:
inline:
sharding-column: user_id
algorithm-expression: order$->{user_id % 2}
## 分表规则配置:按order_id取模运算,奇数在t_order_1表;偶数在t_order_0表
tables:
t_order:
actual-data-nodes: order$->{0..1}.t_order_$->{0..1}
table-strategy:
inline:
sharding-column: order_id
algorithm-expression: t_order_$->{order_id % 2}
2.5 application.yml
spring:
application:
name: sharding-jdbc-demo
profiles:
include: sharding
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
2.6. 测试类中OrderTestCreateUtilTest使用了OrderTestCreateUtil类中提供的测试方法initOrder。
当执行initOrder()方法时,可以发现 userId1 = 111111L 的订单都在 order1库中,其中订单尾号为奇数的在t_order_0表中,其余的在t_order_1表中。
同理, userId1 = 222222L 的订单都在 order1库中;
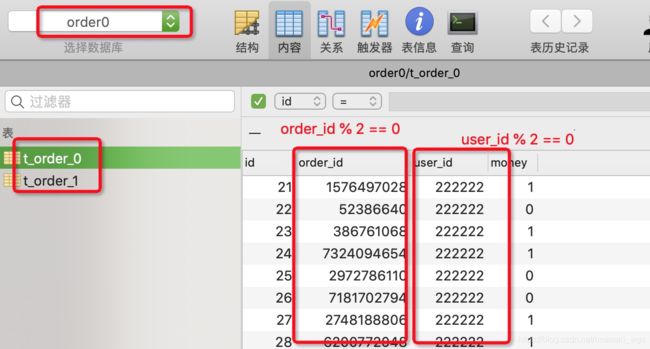
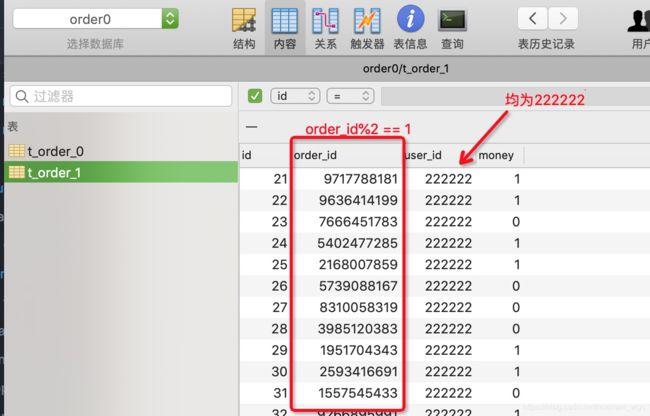
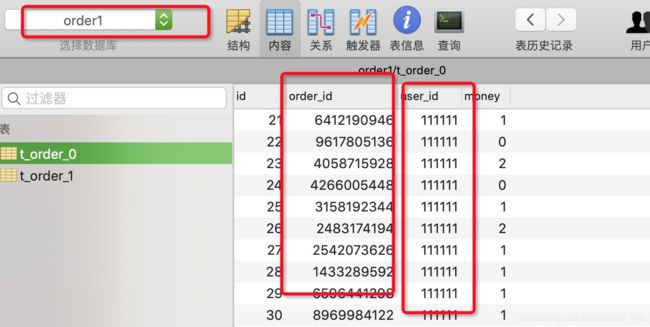
当然,查询数据时分库分表规则也一样,可以自行验证。
2、读写分离
ShardingSphere-JDBC目前仅支持单主多从的架构,添加、更新、删除使用单主库;而查询可以使用多从库,可以通过负载均衡算法决定路由到不同库。
读写分离架构可以提升架构读写性能,但是同时会带来主从延时问题。
代码略。
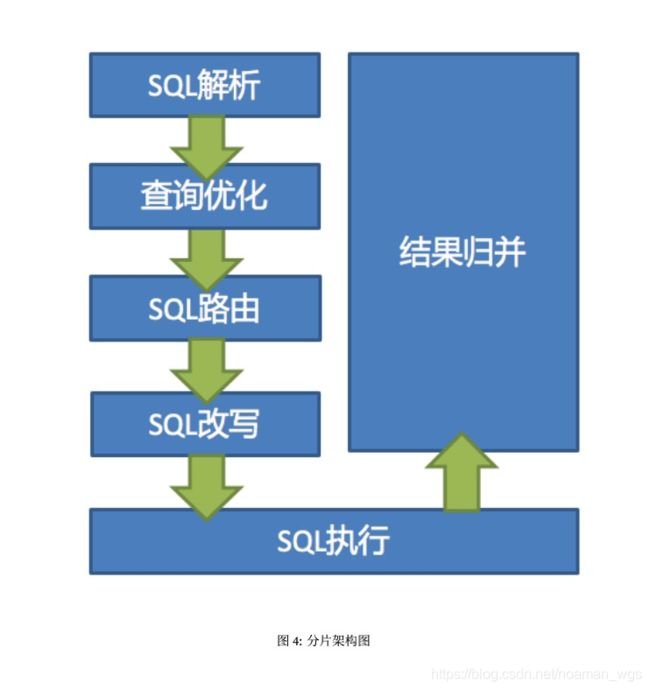
三、ShardingSphere-JDBC分库分表原理
ShardingSphere-JDBC分库分表的核心过程是: SQL 解析 => 执⾏器优化 => SQL 路由 => SQL 改写 => SQL 执⾏ => 结果归并的流程组成。