windows10上搭建caffe以及踩到的坑
对动作捕捉的几篇论文感兴趣,想复现一下,需要caffe环境就折腾了下!转模型需要python 2.7环境,我顺便也弄了!!!
1. 环境
Windows10
RTX2080TI 11G
Anaconda Python2.7
visual studio 2013
cuda 11.1
cudnn 8.2.0
cmake 3.26.1
git
2. 具体步骤
2.1 安装cuda和cudnn
略 这部分看其他博客
cuda_11.1.0_456.43_win10.exe
cudnn-11.3-windows-x64-v8.2.0.53.zip
2.2 安装caffe
1.下载源码
git clone https://github.com/BVLC/caffe.git
cd caffe
git checkout windows
2.修改build_win.cmd 这一步决定着后面能不能编译成功
path/caffe/scripts/build_win.cmd
a.需要确定visual studio的版本
MSVC版本号对应关系 我在这边踩了坑,因为我看的那个博客这边弄错了。这个链接没问题。MSVC_VERSION = 12表示VS2013,MSVC_VERSION = 14表示VS2015
b.确定GPU的显卡架构 架构表 一定要看

下面开始修改文件:
1.修改caffe源码中./scripts/build_win.cmd


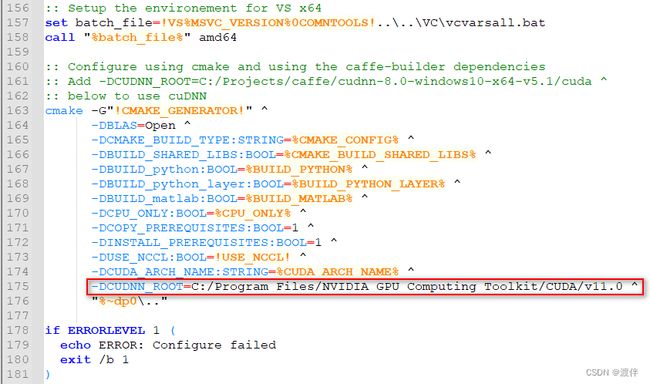
修改caffe源码中./cmake/Cuda.cmake:


我的显卡是2080ti,对应着75,我只要保证有75就行!

这里的80需要根据我的显卡情况改成75



这里面是一定要改的,不然找不到cudnn!因为caffe之类的代码很久不更新了,只支持到了使用cudnn7.x,在使用了cudnn8的环境下编译caffe时,会在src/caffe/layers/cudnn_conv_layer.cpp等文件里出错!
报错信息是这样的:
error: identifier "CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT" is undefined
error: identifier "cudnnGetConvolutionForwardAlgorithm" is undefined
这是因为cudnn8里没有cudnnGetConvolutionForwardAlgorithm()这个函数了,改成了cudnnGetConvolutionForwardAlgorithm_v7(),也没了CUDNN_CONVOLUTION_FWD_SPECIFY_WORKSPACE_LIMIT这个宏定义,这些都是API不兼容,但是NVIDIA声明cudnn8不支持了,caffe的代码也没人去更新了,所以不能指望NVIDIA或者berkeley,只能自行修改。将cudnn_conv_layer.cpp文件替换成如下:
#ifdef USE_CUDNN
#include 在命令行窗口运行 scripts/build_win.cmd,会下载libraries_v120_x64_py27_1.1.0.tar.bz2文件,最好挂个梯子,我这边下的很快。这个文件是caffe相关的依赖库,此过程中编译的时候会报一个boost相关的错误,对C:\Users\qiao\.caffe\dependencies\libraries_v120_x64_py27_1.1.0\libraries\include\boost-1_61\boost\config\compiler路径下的 nvcc.hpp 作如下修改,因为RTX2080ti的编译器nvcc版本大于7.5:

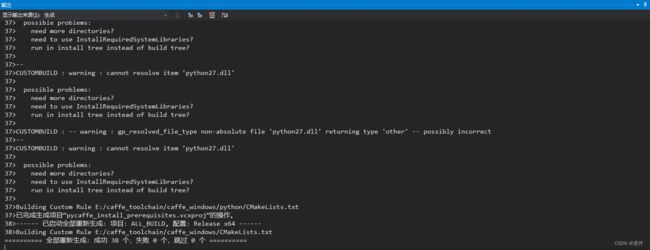
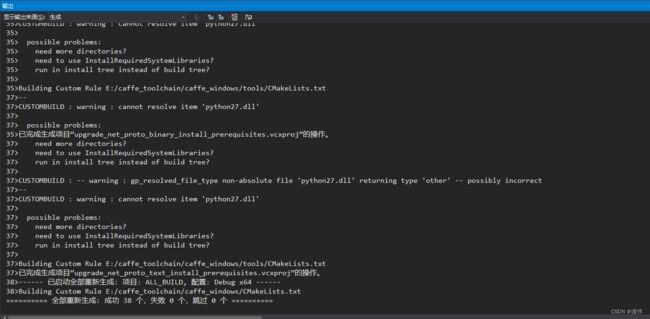
之后删除之前编译的build文件夹,重新编译一次,编译过程中会出现较多警告可以不用理会,稍等一段时间后,最终会出现:

最后在build文件夹下找到Caffe.sln文件,用VS2013打开,然后右键ALL_BUILD进行生成,等几分钟后编译完,
release版本
debug版本
将caffe源码下中python中的caffe文件夹粘贴到上面配置的python路径中D:\Anaconda3\envs\pycaffe27\Lib\site-packages再将E:\caffe\build\install\bin路径添加到环境变量中,在终端中测试一下caffe命令是否正常,然后pip安装一些必要的库
pip install numpy scipy protobuf six scikit-image pyyaml pydotplus graphviz
最后打开python,测试一下

参考文献:
Windows10 下RTX30系列Caffe安装教程
Windows10下搭建caffe过程记录