redis五种数据类型对应的底层数据结构
redis五种数据类型对应的底层数据结构
- redis的五种数据类型
- redis核心对象redisObject
-
- type数据类型
- encoding编码类型
- ptr指针
- redis五种数据类型对应的底层数据结构
-
- String字符串类型
-
- SDS
- hash哈希类型
-
- ziplist压缩列表
- hashtable哈希表
- list列表类型
-
- ziplist压缩列表
- linkedlist、quicklist
- set集合类型
-
- intset整数集合
- hashtable哈希表
- zset有序集合类型
-
- ziplist压缩列表
- skiplist跳跃表
redis是一种非关系型key-value内存数据库。
redis的五种数据类型
字符串:string;
哈希(也叫哈希表、字典,下文中统一称为哈希。):hash;
列表:list;
集合:set;
有序集合:sorted set。
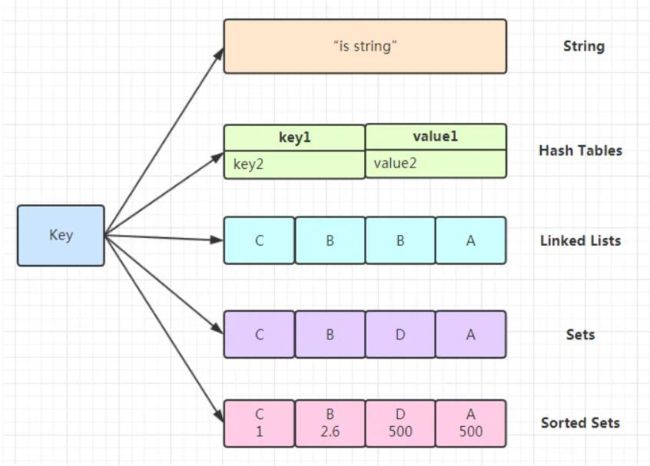
这里的数据类型是针对于value来说的,key全是字符串类型。
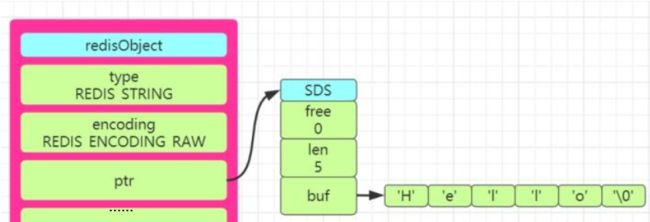
redis的这些数据类型在底层都是使用核心对象redisObject表示的。
redis核心对象redisObject
redisObject对象有以下属性:
type、encoding、ptr、其它信息。
type数据类型
对应的是value五种数据类型。
字符串:REDIS_STRING;
哈希:REDIS_HASH;
列表:REDIS_LIST;
集合:REDIS_SET;
有序集合:REDIS_ZSET。
encoding编码类型
表示的value保存的编码。
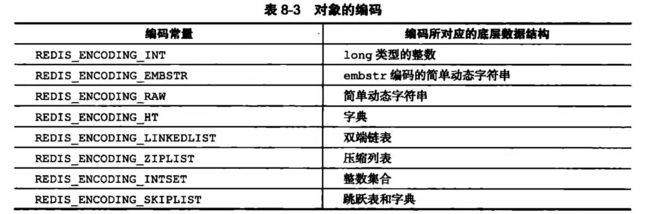
要注意type和encoding不是一一对应的,是组合!
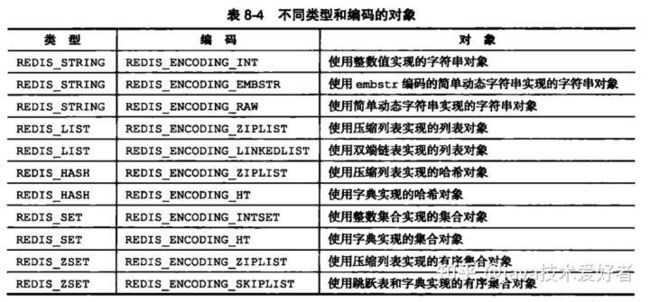
ptr指针
指向了实际保存value的数据结构。
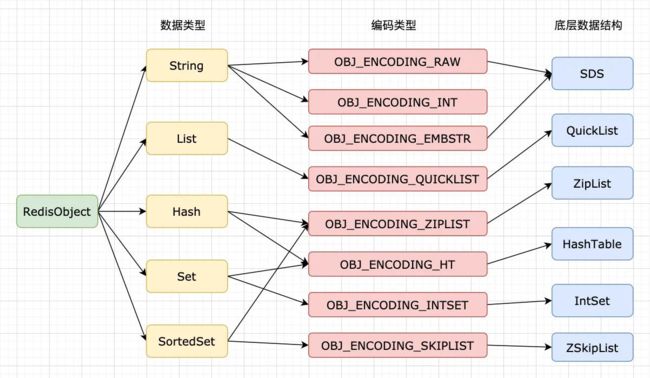
redis五种数据类型对应的底层数据结构
String字符串类型
String类型的编码方式,即encoding有三种:int、embstr、raw。
value的值是整数,encoding为int,没有对应底层数据结构;
value长度小于32,encoding为embstr,长度大于,32编码为raw,embstr和raw都使用SDS数据结构存储。

SDS
SDS是简单动态字符串simple dynamic string的缩写。
SDS有三个属性:
struct sdshdr{
int len; // 字符串长度
int free; // 未使用的字节长度
char buf[]; // 保存字符串的字节数组
}
c语言中的结构体struct,类似Java中的类class。
redis是c语言实现的,
c语言中的字符串类型不会记录自身长度,获取长度要通过遍历得到,时间复杂度是O(n),需要n次,(最多)
SDS只需读取len属性,时间复杂度是O(1),也就是最多1次;
SDS在修改前会根据free属性判断空间是否满足,不满足就会扩容,避免内存溢出;
SDS提供’空间预分配’和’惰性空间释放’两种策略,在分配空间时,分配的空间比实际需要的多,
避免频繁增加字符串长度导致多次扩容带来的成本升高,
当字符串收缩的时候,不会立即回收不使用的空间,等以后使用时释放。
hash哈希类型
哈希类型的编码方式有ziplist、ht两种,分别对应ziplist和hashtable两种底层数据结构,
当哈希对象的键值对数量小于512,并且所有键值对的长度都小于64字节时,使用压缩列表ziplist,否则使用hashtable。
ziplist压缩列表
压缩列表并不是说以某种算法压缩存储数据,它是一组连续的内存块,能够节省空间。
压缩列表的内存结构:
zlbytes:4个字节大小,是压缩列表占用内存的字节数;
zltail:4个字节大小,记录表尾节点距离起始地址的偏移量,用于快速定位到尾节点地址;
zllen:2个字节大小,压缩列表中的节点数;
entry:列表中的每一个元素;
zlend:压缩列表的特殊结束符号’0xFF’。

一个entry节点包含以下三部分:
previous_entry_ength:记录前一个节点entry的长度,可用于计算前一个节点的起始地址,因为它们的地址是连续的;
encoding:content的内容类型和长度;
content:每个节点的内容。

hashtable哈希表
hashtable和java中的hashmap相似。
list列表类型
redis3.2之前,列表类型使用ziplist、linkedlist两种底层数据结构存储,
当列表的长度小于512,并且所有元素的长度都小于64时,使用ziplist,否则使用linkedlist。
redis3.2以后,则统一使用quicklist。
ziplist压缩列表
上边说过了。
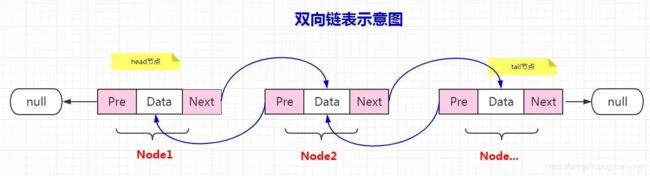
linkedlist、quicklist
linkedlist、quicklist是个双向链表,双向链表中的每个节点,分别持有对前一个和后一个节点的引用prev、next,
头结点的prev引用、尾结点的next引用分别指向null。
set集合类型
集合类型使用intset、hashtable这两种底层数据结构存储,
如果集合中的所有元素都可以转换成整数值,且长度小于512,使用intset,否则用hashtable。
intset整数集合
整数集合中的元素有三个属性:
encoding:编码方式,有INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64三种;
contents[]:元素内容;
length:元素内容长度。
整数集合中新增元素时,若是超出了长度,就会进行升级:
一、扩展数组contents的大小,并且数组的类型为新元素的类型;
二、将原来数组中的元素转为新元素的类型,并放到新的数组中;
三、整数集合在升级后就不会再降级,会一致保持升级后的状态。
hashtable哈希表
上边说过了。
有一点不同,
set中哈希表的value都是null,只用map的key实现集合。
zset有序集合类型
zset有序集合与集合相比,区别在于有序集合中的元素多了一个score属性,即排名的权重。
有序集合使用ziplist、skiplist这两种底层数据结构存储,
当集合长度小于128,并且所有的元素长度都小于64字节时,使用ziplist,否则使用skiplist。
ziplist压缩列表
上边说过了。
skiplist跳跃表
跳跃表是具有层次结构的链表。
它由很多层组成,每一层都是一个有序的链表,
由上到下每层节点数逐渐密集,最上层的节点最稀疏,跨度也最大,
下面这句话有点绕,但很重要:
每一层的每一个节点,都指向同一层下一位置的节点,和下一层同一位置的节点,
有点像mysql innodb的b+tree,支持范围查找,上层相当于索引层,下层是数据层,
bw是后退指针,在从下向上遍历的时候使用。

refs:
java技术爱好者:Redis的五种数据类型底层实现原理是什么
黎杜:最详细的Redis五种数据结构详解
溪午闻璐:Redis之跳跃表