- OpenCV 基础模块 Python 版
ice_junjun
OpenCVopencvpython计算机视觉
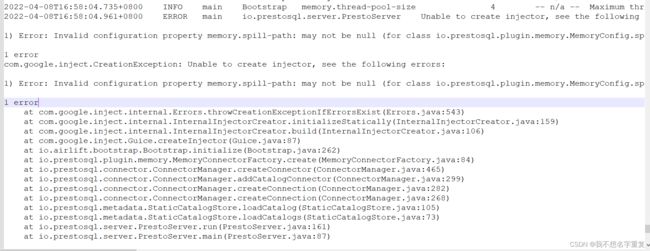
OpenCV基础模块权威指南(Python版)一、模块全景图plaintextOpenCV架构(v4.x+)├─核心层│├─core:基础数据结构与操作(Mat/Scalar/Point)│└─imgproc:图像处理流水线(滤波→变换→检测)├─交互层│├─highgui:GUI与媒体I/O(显示/捕获/交互)│└─video:视频分析(运动检测/目标跟踪)├─3D视觉层│└─calib3d:相
- 【Python系列】高效Parquet数据处理策略:合并与分析实践
小团团0
python开发语言
在大数据时代,数据的存储、处理和分析变得尤为重要。Parquet作为一种高效的列存储格式,被广泛应用于大数据处理框架中,如ApacheSpark、ApacheHive等。Parquet是一个开源的列存储格式,它被设计用于支持复杂的嵌套数据结构,同时提供高效的压缩和编码方案,以优化存储空间和查询性能。以下将详细介绍如何使用Python对Parquet文件进行数据处理与合并,并提供相应的源码示例。一、
- AsyncHttpClient使用说明书
有梦想的攻城狮
netty学习专栏Javaasynchttpclient异步处理netty
[[toc]]AsyncHttpClient(AHC)是一个高性能、异步的HTTP客户端库,广泛用于Java和Scala应用中,特别适合处理高并发、非阻塞的HTTP请求。它基于Netty或Java原生的异步HTTP客户端实现,支持HTTP/1.1和HTTP/2协议,适用于微服务、API调用、爬虫等场景。1.核心特性特性说明异步非阻塞基于事件驱动模型,避免线程阻塞,支持高并发(如每秒数千请求)。HT
- spark explain如何使用
fzip
Sparkspark执行计划
在Spark中,explain是分析SQL或DataFrame执行计划的核心工具,通过不同模式可展示查询优化和执行的详细信息,默认情况下,这个语句只提供关于物理计划的信息。以下是具体使用方法及不同模式的作用:1.explain的基本语法在Spark3.0及以上版本,explain支持多种模式参数,通过mode指定输出格式:#DataFrame调用方式df.explain(mode="simple"
- 【Spark】查询优化中分区(Partitioning)和分桶(Bucketing)是什么关系?什么时候应当分区,什么时候应当分桶?
petrel2015
spark大数据分布式数据库
在学习Spark的过程中,分区和分桶乍一看很像,都能为了计算加速,但是仔细一想,一查还是有些差异的,甚至说差异很大。那么具体有什么差异点,有什么相同点。我做出了如下的整理,供大家参考,欢迎指正。相同点分区(Partitioning)和分桶(Bucketing)在很多方面具有相似性,它们都是用于优化大数据查询性能的技术数据划分的目的:优化查询性能分区和分桶的核心目标是通过将数据分割成更小的逻辑单元来
- pyspark学习rdd处理数据方法——学习记录
亭午
学习
python黑马程序员"""文件,按JSON字符串存储1.城市按销售额排名2.全部城市有哪些商品类别在售卖3.上海市有哪些商品类别在售卖"""frompysparkimportSparkConf,SparkContextimportosimportjsonos.environ['PYSPARK_PYTHON']=r"D:\anaconda\envs\py10\python.exe"#创建Spark
- 数据湖Iceberg、Hudi和Paimon比较_数据湖框架对比(1)
2301_79098963
程序员知识图谱人工智能
4.Schema变更支持对比项ApacheIcebergApacheHudiApachePaimonSchemaEvolutionALLback-compatibleback-compatibleSelf-definedschemaobjectYESNO(spark-schema)NO(我理解,不准确)SchemaEvolution:指schema变更的支持情况,我的理解是hudi仅支持添加可选列
- Apache大数据旭哥优选大数据选题
Apache大数据旭
大数据定制选题javahadoopspark开发语言ideahive数据库架构
定制旭哥服务,一对一,无中介包安装+答疑+售后态度和技术都很重要定制按需求做要求不高就实惠一点定制需提前沟通好怎么做,这样才能避免不必要的麻烦python、flask、Django、mapreduce、mysqljava、springboot、vue、echarts、hadoop、spark、hive、hbase、flink、SparkStreaming、kafka、flume、sqoop分析+推
- [AI速读]CHISEL vs. SystemVerilog:用RISC-V核心对比两种硬件设计语言
iccnewer
risc-v设计语言
在硬件设计领域,选择合适的语言对开发效率、维护成本和最终性能都至关重要。最近,一项研究对比了两种硬件描述语言——CHISEL(基于Scala的嵌入式语言)和传统的SystemVerilog,它们分别实现了同一款RISC-V核心(SweRV-EL2)。以下是关键发现和结论。为什么选择CHISEL?CHISEL是一种基于Scala的高级硬件构造语言,它结合了面向对象和函数式编程的特性。与传统的Syst
- Azure Delta Lake、Databricks和Event Hubs实现实时欺诈检测
weixin_30777913
azure云计算
设计Azure云架构方案实现AzureDeltaLake和AzureDatabricks,结合AzureEventHubs/Kafka摄入实时数据,通过DeltaLake实现Exactly-Once语义,实时欺诈检测(流数据写入DeltaLake,批处理模型实时更新),以及具体实现的详细步骤和关键PySpark代码。完整实现代码需要根据具体数据格式和业务规则进行调整,建议通过DatabricksR
- 探索终端的新境界:Scurses与Onions框架深度揭秘
雷竹榕
探索终端的新境界:Scurses与Onions框架深度揭秘ScursesScurses,terminaldrawingAPIforScala,andOnions,aScursesframeworkforeasyterminalUI项目地址:https://gitcode.com/gh_mirrors/sc/Scurses在数字化的今天,终端不仅是命令行交互的简单界面,它成为了开发人员和系统管理员的
- 探索数据安全新境界:Apache Spark SQL Ranger Security插件深度揭秘
乌昱有Melanie
探索数据安全新境界:ApacheSparkSQLRangerSecurity插件深度揭秘项目地址:https://gitcode.com/gh_mirrors/sp/spark-ranger随着大数据的爆炸性增长,数据安全性成为了企业不可忽视的核心议题。在这一背景下,【ApacheSparkSQLRangerSecurityPlugin】以其强大的数据访问控制能力脱颖而出,成为数据处理领域的明星级
- 基于Azure云平台构建实时数据仓库
weixin_30777913
云计算azure开发语言sparkpython
设计Azure云架构方案实现AzureDeltaLake和AzureDatabricks,结合电商网站的流数据,构建实时数据仓库,支持T+0报表(如电商订单分析),具以及具体实现的详细步骤和关键PySpark代码。一、架构设计[电商网站]→[AzureEventHubs]→[AzureDatabricksStreaming]↓[AzureDeltaLake]←→[DatabricksSQLAnal
- 优化Apache Spark性能之JVM参数配置指南
weixin_30777913
jvmspark大数据开发语言性能优化
ApacheSpark运行在JVM之上,JVM的垃圾回收(GC)、内存管理以及堆外内存使用情况,会直接对Spark任务的执行效率产生影响。因此,合理配置JVM参数是优化Spark性能的关键步骤,以下将详细介绍优化策略和配置建议。通过以下优化方法,可以显著减少GC停顿时间、提升内存利用率,进而提高Spark作业吞吐量和数据处理效率。同时,要根据具体的工作负载和集群配置进行调整,并定期监控Spark应
- GraphCube、Spark和深度学习技术赋能快消行业关键运营环节
weixin_30777913
开发语言大数据深度学习人工智能spark
在快消品(FMCG)行业,需求计划(DemandPlanning)、库存管理(InventoryManagement)和需求供应管理(DemandSupplyManagement)是影响企业整体效率和利润水平的关键运营环节。GraphCube图多维数据集技术、Spark大数据分析处理技术和深度学习技术的结合,为这些环节提供了智能化、动态化和实时化的解决方案,显著提升业务运营效率和企业利润。一、技术
- IDEA本地启动flink 任务
Direction_Wind
intellij-ideaflinkjava
1pom中添加org.apache.flinkflink-clients_${scala.binary.version}${flink.version}org.apache.flinkflink-runtime-web_${scala.binary.version}${flink.version}2下载flink-dist包并3打印日志中搜索localhost可以找到flink的管理页面
- 【新品发售】NVIDIA 发布全球最小个人 AI 超级计算机 DGX Spark
segmentfault
GTC2025大会上,NVIDIA正式推出了搭载NVIDIAGraceBlackwell平台的个人AI超级计算机——DGXSpark。赞奇可接受预订,直接私信后台即刻预订!DGXSpark(前身为ProjectDIGITS)支持AI开发者、研究人员、数据科学家和学生,在台式电脑上对大模型进行原型设计、微调和推理。用户可以在本地运行这些模型,或将其部署在NVIDIADGXCloud或任何其他加速云或
- Kafka Connect Node.js Connector 指南
丁操余
KafkaConnectNode.jsConnector指南kafka-connectequivalenttokafka-connect:wrench:fornodejs:sparkles::turtle::rocket::sparkles:项目地址:https://gitcode.com/gh_mirrors/ka/kafka-connect项目介绍KafkaConnectNode.jsConn
- JAVA学习-练习试用Java实现“对大数据集中的网络日志进行解析和异常行为筛查”
守护者170
java学习java学习
问题:编写一个Spark程序,对大数据集中的网络日志进行解析和异常行为筛查。解答思路:下面是一个简单的Spark程序示例,用于解析网络日志并筛查异常行为。这个示例假设日志文件格式如下:timestamp,ip_address,user_id,action,event,extra_info2023-01-0112:00:00,192.168.1.1,123,login,success,none202
- JAVA学习-练习试用Java实现“实现一个Spark应用,对大数据集中的文本数据进行情感分析和关键词筛选”
守护者170
java学习java学习
问题:实现一个Spark应用,对大数据集中的文本数据进行情感分析和关键词筛选。解答思路:要实现一个Spark应用,对大数据集中的文本数据进行情感分析和关键词筛选,需要按照以下步骤进行:1.环境准备确保的环境中已经安装了ApacheSpark。可以从[ApacheSpark官网](https://spark.apache.org/downloads.html)下载并安装。2.创建Spark应用以下是
- Hive与Spark的UDF:数据处理利器的对比与实践
窝窝和牛牛
hivesparkhadoop
文章目录Hive与Spark的UDF:数据处理利器的对比与实践一、UDF概述二、HiveUDF解析实现原理代码示例业务应用三、SparkUDF剖析-JDBC方式使用SparkThriftServer设置通过JDBC使用UDFSparkUDF的Java实现(用于JDBC方式)通过beeline客户端连接使用业务应用场景四、Hive与SparkUDF在JDBC模式下的对比五、实际部署与最佳实践六、总结
- 尚硅谷电商数仓6.0,hive on spark,spark启动不了
新时代赚钱战士
hivesparkhadoop
在datagrip执行分区插入语句时报错[42000][40000]Errorwhilecompilingstatement:FAILED:SemanticExceptionFailedtogetasparksession:org.apache.hadoop.hive.ql.metadata.HiveException:FailedtocreateSparkclientforSparksessio
- 数据中台(二)数据中台相关技术栈
Yuan_CSDF
#数据中台
1.平台搭建1.1.Amabari+HDP1.2.CM+CDH2.相关的技术栈数据存储:HDFS,HBase,Kudu等数据计算:MapReduce,Spark,Flink交互式查询:Impala,Presto在线实时分析:ClickHouse,Kylin,Doris,Druid,Kudu等资源调度:YARN,Mesos,Kubernetes任务调度:Oozie,Azakaban,AirFlow,
- 从0到1,带你快速上手Scala语言
qq_23519469
scala开发语言后端
什么是ScalaScala,读作“skah-lah”,是“ScalableLanguage”的缩写,是一门多范式编程语言。它就像是编程世界里的“变形金刚”,融合了面向对象编程(OOP)和函数式编程(FP)的特性,这意味着开发者能在同一语言中,把面向对象的设计和函数式编程的抽象结合起来使用,超级灵活!它运行在Java虚拟机(JVM)上,能与现有的Java代码无缝集成。这就好比Scala是Java的“
- 一文搞懂大数据神器Spark,真的太牛了!
qq_23519469
大数据spark分布式
Spark是什么在如今这个大数据时代,数据量呈爆炸式增长,传统的数据处理方式已经难以满足需求。就拿电商平台来说,每天产生的交易数据、用户浏览数据、评论数据等,数量巨大且种类繁多。假如要对这些数据进行分析,比如分析用户的购买行为,找出最受欢迎的商品,预测未来的销售趋势等,用普通的单机处理方式,可能需要花费很长时间,甚至根本无法完成。这时,Spark就应运而生了。Spark是一个开源的、基于内存计算的
- Flink读取kafka数据并写入HDFS
王知无(import_bigdata)
Flink系统性学习专栏hdfskafkaflink
硬刚大数据系列文章链接:2021年从零到大数据专家的学习指南(全面升级版)2021年从零到大数据专家面试篇之Hadoop/HDFS/Yarn篇2021年从零到大数据专家面试篇之SparkSQL篇2021年从零到大数据专家面试篇之消息队列篇2021年从零到大数据专家面试篇之Spark篇2021年从零到大数据专家面试篇之Hbase篇
- 元戎启行最新战略RoadAGI:所有移动智能体都将被AI驱动
量子位
2025年3月18日(北京时间),元戎启行作为国内人工智能企业代表,出席由NVIDIA主办的GTC大会。会上,公司CEO周光发表了技术主题演讲,展示了公司的最新战略布局RoadAGI,并发布道路通用人工智能平台——AISpark(以下简称”Spark平台”)。RoadAGI是元戎启行实现物理世界通用人工智能的关键一步,旨在让包括智能驾驶汽车在内的移动智能体,都具有在道路上自主行驶、与物理世界深度交
- SparkSQL编程-RDD、DataFrame、DataSet
早拾碗吧
Sparksparkhadoop大数据sparksql
三者之间的关系在SparkSQL中Spark为我们提供了两个新的抽象,分别是DataFrame和DataSet。他们和RDD有什么区别呢?首先从版本的产生上来看:RDD(Spark1.0)—>Dataframe(Spark1.3)—>Dataset(Spark1.6)如果同样的数据都给到这三个数据结构,他们分别计算之后,都会给出相同的结果。不同是的他们的执行效率和执行方式。在后期的Spark版本中
- How Spark Read Sftp Files from Hadoop SFTP FileSystem
IT•轩辕
CloudyComputationsparkhadoop大数据
GradleDependenciesimplementation('org.apache.spark:spark-sql_2.13:3.5.3'){excludegroup:"org.apache.logging.log4j",module:"log4j-slf4j2-impl"}implementation('org.apache.hadoop:hadoop-common:3.3.4'){exc
- pyspark 遇到**Py4JJavaError** Traceback (most recent call last) ~\AppData\
2pi
sparkpython
Py4JJavaErrorTraceback(mostrecentcalllast)~\AppData\Local\Temp/ipykernel_22732/1401292359.pyin---->1feat_df.show(5,vertical=True)D:\Anaconda3\envs\recall-service-cp4\lib\site-packages\pyspark\sql\data
- 基本数据类型和引用类型的初始值
3213213333332132
java基础
package com.array;
/**
* @Description 测试初始值
* @author FuJianyong
* 2015-1-22上午10:31:53
*/
public class ArrayTest {
ArrayTest at;
String str;
byte bt;
short s;
int i;
long
- 摘抄笔记--《编写高质量代码:改善Java程序的151个建议》
白糖_
高质量代码
记得3年前刚到公司,同桌同事见我无事可做就借我看《编写高质量代码:改善Java程序的151个建议》这本书,当时看了几页没上心就没研究了。到上个月在公司偶然看到,于是乎又找来看看,我的天,真是非常多的干货,对于我这种静不下心的人真是帮助莫大呀。
看完整本书,也记了不少笔记
- 【备忘】Django 常用命令及最佳实践
dongwei_6688
django
注意:本文基于 Django 1.8.2 版本
生成数据库迁移脚本(python 脚本)
python manage.py makemigrations polls
说明:polls 是你的应用名字,运行该命令时需要根据你的应用名字进行调整
查看该次迁移需要执行的 SQL 语句(只查看语句,并不应用到数据库上):
python manage.p
- 阶乘算法之一N! 末尾有多少个零
周凡杨
java算法阶乘面试效率
&n
- spring注入servlet
g21121
Spring注入
传统的配置方法是无法将bean或属性直接注入到servlet中的,配置代理servlet亦比较麻烦,这里其实有比较简单的方法,其实就是在servlet的init()方法中加入要注入的内容:
ServletContext application = getServletContext();
WebApplicationContext wac = WebApplicationContextUtil
- Jenkins 命令行操作说明文档
510888780
centos
假设Jenkins的URL为http://22.11.140.38:9080/jenkins/
基本的格式为
java
基本的格式为
java -jar jenkins-cli.jar [-s JENKINS_URL] command [options][args]
下面具体介绍各个命令的作用及基本使用方法
1. &nb
- UnicodeBlock检测中文用法
布衣凌宇
UnicodeBlock
/** * 判断输入的是汉字 */ public static boolean isChinese(char c) { Character.UnicodeBlock ub = Character.UnicodeBlock.of(c);
- java下实现调用oracle的存储过程和函数
aijuans
javaorale
1.创建表:STOCK_PRICES
2.插入测试数据:
3.建立一个返回游标:
PKG_PUB_UTILS
4.创建和存储过程:P_GET_PRICE
5.创建函数:
6.JAVA调用存储过程返回结果集
JDBCoracle10G_INVO
- Velocity Toolbox
antlove
模板toolboxvelocity
velocity.VelocityUtil
package velocity;
import org.apache.velocity.Template;
import org.apache.velocity.app.Velocity;
import org.apache.velocity.app.VelocityEngine;
import org.apache.velocity.c
- JAVA正则表达式匹配基础
百合不是茶
java正则表达式的匹配
正则表达式;提高程序的性能,简化代码,提高代码的可读性,简化对字符串的操作
正则表达式的用途;
字符串的匹配
字符串的分割
字符串的查找
字符串的替换
正则表达式的验证语法
[a] //[]表示这个字符只出现一次 ,[a] 表示a只出现一
- 是否使用EL表达式的配置
bijian1013
jspweb.xmlELEasyTemplate
今天在开发过程中发现一个细节问题,由于前端采用EasyTemplate模板方法实现数据展示,但老是不能正常显示出来。后来发现竟是EL将我的EasyTemplate的${...}解释执行了,导致我的模板不能正常展示后台数据。
网
- 精通Oracle10编程SQL(1-3)PLSQL基础
bijian1013
oracle数据库plsql
--只包含执行部分的PL/SQL块
--set serveroutput off
begin
dbms_output.put_line('Hello,everyone!');
end;
select * from emp;
--包含定义部分和执行部分的PL/SQL块
declare
v_ename varchar2(5);
begin
select
- 【Nginx三】Nginx作为反向代理服务器
bit1129
nginx
Nginx一个常用的功能是作为代理服务器。代理服务器通常完成如下的功能:
接受客户端请求
将请求转发给被代理的服务器
从被代理的服务器获得响应结果
把响应结果返回给客户端
实例
本文把Nginx配置成一个简单的代理服务器
对于静态的html和图片,直接从Nginx获取
对于动态的页面,例如JSP或者Servlet,Nginx则将请求转发给Res
- Plugin execution not covered by lifecycle configuration: org.apache.maven.plugin
blackproof
maven报错
转:http://stackoverflow.com/questions/6352208/how-to-solve-plugin-execution-not-covered-by-lifecycle-configuration-for-sprin
maven报错:
Plugin execution not covered by lifecycle configuration:
- 发布docker程序到marathon
ronin47
docker 发布应用
1 发布docker程序到marathon 1.1 搭建私有docker registry 1.1.1 安装docker regisry
docker pull docker-registry
docker run -t -p 5000:5000 docker-registry
下载docker镜像并发布到私有registry
docker pull consol/tomcat-8.0
- java-57-用两个栈实现队列&&用两个队列实现一个栈
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
import java.util.Stack;
/*
* Q 57 用两个栈实现队列
*/
public class QueueImplementByTwoStacks {
private Stack<Integer> stack1;
pr
- Nginx配置性能优化
cfyme
nginx
转载地址:http://blog.csdn.net/xifeijian/article/details/20956605
大多数的Nginx安装指南告诉你如下基础知识——通过apt-get安装,修改这里或那里的几行配置,好了,你已经有了一个Web服务器了。而且,在大多数情况下,一个常规安装的nginx对你的网站来说已经能很好地工作了。然而,如果你真的想挤压出Nginx的性能,你必
- [JAVA图形图像]JAVA体系需要稳扎稳打,逐步推进图像图形处理技术
comsci
java
对图形图像进行精确处理,需要大量的数学工具,即使是从底层硬件模拟层开始设计,也离不开大量的数学工具包,因为我认为,JAVA语言体系在图形图像处理模块上面的研发工作,需要从开发一些基础的,类似实时数学函数构造器和解析器的软件包入手,而不是急于利用第三方代码工具来实现一个不严格的图形图像处理软件......
&nb
- MonkeyRunner的使用
dai_lm
androidMonkeyRunner
要使用MonkeyRunner,就要学习使用Python,哎
先抄一段官方doc里的代码
作用是启动一个程序(应该是启动程序默认的Activity),然后按MENU键,并截屏
# Imports the monkeyrunner modules used by this program
from com.android.monkeyrunner import MonkeyRun
- Hadoop-- 海量文件的分布式计算处理方案
datamachine
mapreducehadoop分布式计算
csdn的一个关于hadoop的分布式处理方案,存档。
原帖:http://blog.csdn.net/calvinxiu/article/details/1506112。
Hadoop 是Google MapReduce的一个Java实现。MapReduce是一种简化的分布式编程模式,让程序自动分布到一个由普通机器组成的超大集群上并发执行。就如同ja
- 以資料庫驗證登入
dcj3sjt126com
yii
以資料庫驗證登入
由於 Yii 內定的原始框架程式, 採用綁定在UserIdentity.php 的 demo 與 admin 帳號密碼: public function authenticate() { $users=array( &nbs
- github做webhooks:[2]php版本自动触发更新
dcj3sjt126com
githubgitwebhooks
上次已经说过了如何在github控制面板做查看url的返回信息了。这次就到了直接贴钩子代码的时候了。
工具/原料
git
github
方法/步骤
在github的setting里面的webhooks里把我们的url地址填进去。
钩子更新的代码如下: error_reportin
- Eos开发常用表达式
蕃薯耀
Eos开发Eos入门Eos开发常用表达式
Eos开发常用表达式
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2014年8月18日 15:03:35 星期一
&
- SpringSecurity3.X--SpEL 表达式
hanqunfeng
SpringSecurity
使用 Spring 表达式语言配置访问控制,要实现这一功能的直接方式是在<http>配置元素上添加 use-expressions 属性:
<http auto-config="true" use-expressions="true">
这样就会在投票器中自动增加一个投票器:org.springframework
- Redis vs Memcache
IXHONG
redis
1. Redis中,并不是所有的数据都一直存储在内存中的,这是和Memcached相比一个最大的区别。
2. Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
3. Redis支持数据的备份,即master-slave模式的数据备份。
4. Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
Red
- Python - 装饰器使用过程中的误区解读
kvhur
JavaScriptjqueryhtml5css
大家都知道装饰器是一个很著名的设计模式,经常被用于AOP(面向切面编程)的场景,较为经典的有插入日志,性能测试,事务处理,Web权限校验, Cache等。
原文链接:http://www.gbtags.com/gb/share/5563.htm
Python语言本身提供了装饰器语法(@),典型的装饰器实现如下:
@function_wrapper
de
- 架构师之mybatis-----update 带case when 针对多种情况更新
nannan408
case when
1.前言.
如题.
2. 代码.
<update id="batchUpdate" parameterType="java.util.List">
<foreach collection="list" item="list" index=&
- Algorithm算法视频教程
栏目记者
Algorithm算法
课程:Algorithm算法视频教程
百度网盘下载地址: http://pan.baidu.com/s/1qWFjjQW 密码: 2mji
程序写的好不好,还得看算法屌不屌!Algorithm算法博大精深。
一、课程内容:
课时1、算法的基本概念 + Sequential search
课时2、Binary search
课时3、Hash table
课时4、Algor
- C语言算法之冒泡排序
qiufeihu
c算法
任意输入10个数字由小到大进行排序。
代码:
#include <stdio.h>
int main()
{
int i,j,t,a[11]; /*定义变量及数组为基本类型*/
for(i = 1;i < 11;i++){
scanf("%d",&a[i]); /*从键盘中输入10个数*/
}
for
- JSP异常处理
wyzuomumu
Webjsp
1.在可能发生异常的网页中通过指令将HTTP请求转发给另一个专门处理异常的网页中:
<%@ page errorPage="errors.jsp"%>
2.在处理异常的网页中做如下声明:
errors.jsp:
<%@ page isErrorPage="true"%>,这样设置完后就可以在网页中直接访问exc