爬虫逆向实战(二十七)--某某招标投标网站招标公告
一、数据接口分析
主页地址:某网站
1、抓包
通过抓包可以发现数据接口是page

2、判断是否有加密参数
- 请求参数是否加密?
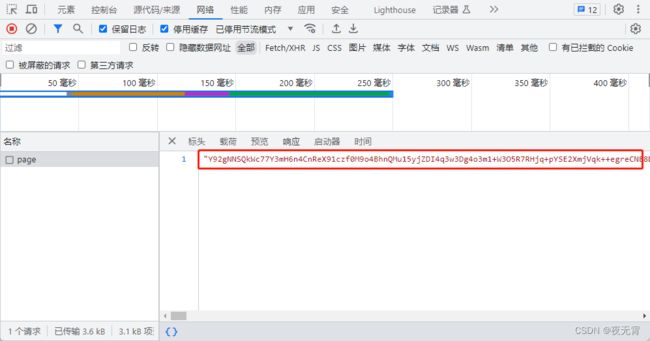
通过查看“载荷”模块可以发现,请求参数是一整个密文

- 请求头是否加密?
无 - 响应是否加密?
通过查看“响应”模块可以发现,响应数据是加密的
- cookie是否加密?
无
二、加密位置定位
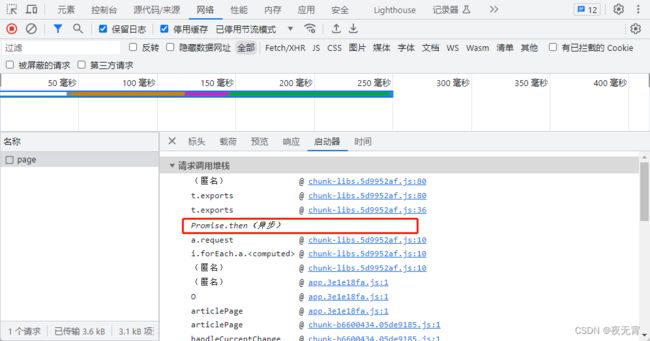
1、看启动器
查看启动器发现里面包含异步,所以无法正确找到加密位置
2、搜索关键字
因为加密参数是一整个密文,所以无法搜索关键字
3、hook
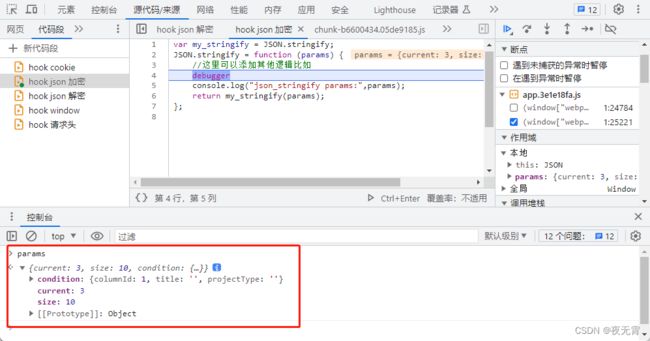
因为“载荷”是一整个密文,所以网站大概率会使用JSON.stringify将数据转换为json字符串再进行加密,所以我们可以hookJSON.stringify,hook代码:
var my_stringify = JSON.stringify;
JSON.stringify = function (params) {
debugger
console.log("json_stringify params:",params);
return my_stringify(params);
};
运行hook代码,再次点击翻页,发现可以断住
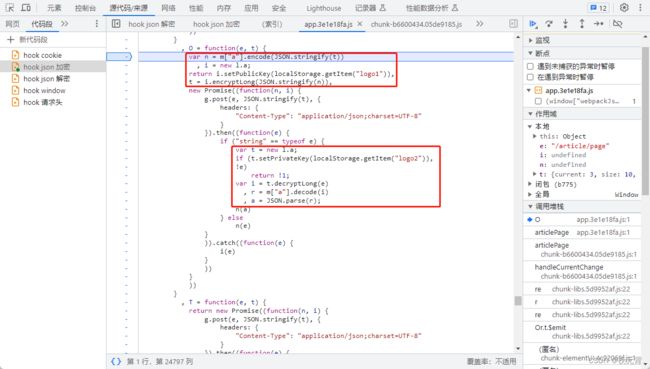
接着调试执行,我们就可以找到加密位置了,并且可以看到,在下面的回调方法中对响应进行了解密操作。
三、解决密钥
1、分析网站密钥的获取
在定位到加密以及解密位置后,我们可以看到网站加解密时需要密钥,并且网站的密钥获取是从本地存储中获取logo1和logo2
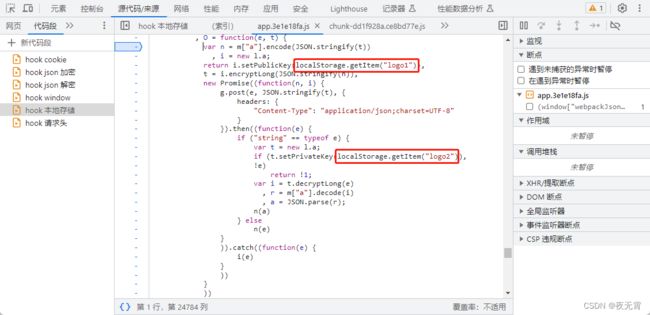
所以我们可以通过hooklocalStorage.setItem来找到网站是怎么生成的这两个参数。
hook代码:
var my_setItem = localStorage.setItem;
localStorage.setItem = function (key, value) {
debugger
return my_setItem.call(localStorage, key, value);
};
同时,为了让网站可以再次生成这两个参数,我们需要先将本地存储中的删除。在控制台中,进入“应用”这个标签页,再点击“本地存储空间”,然后点击清除按钮,就可以清除了。
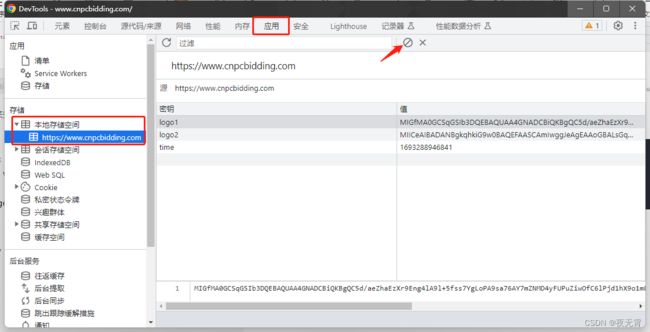
然后运行hook脚本,点击浏览器上方的后退按钮。注意:此处不能刷新页面,因为刷新页面hook代码将不再运行,同时,此网站是在首页向本地存储中放入的参数,所以我们要回退到首页生成。

点击回退后,发现可以断住

接着调试执行,我们就可以找到网站设置的位置了,同时,可以发现这个位置好像是在一个回调中。
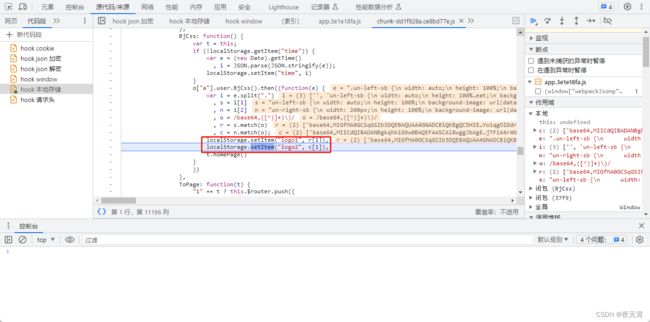
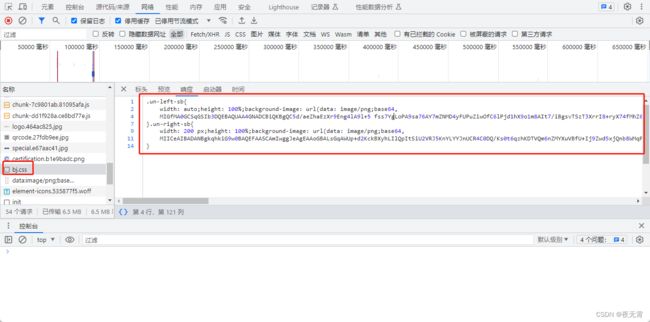
再次观察发包,可以发现网站确实是从一个bj.css的响应中提取的。所以我们就可以通过请求这个接口,按照网站的提取方法提取出密钥,或者自己写正则表达式将密钥提取出来。
四、验证码
1、获取数据错误
在扣完js之后,我们发送请求会发现,获取到的数据与网站抓包获取到的数据不太一致,网站抓包获取到的数据是一整个密文,而我们获取到的数据是一个json数据并且code是511
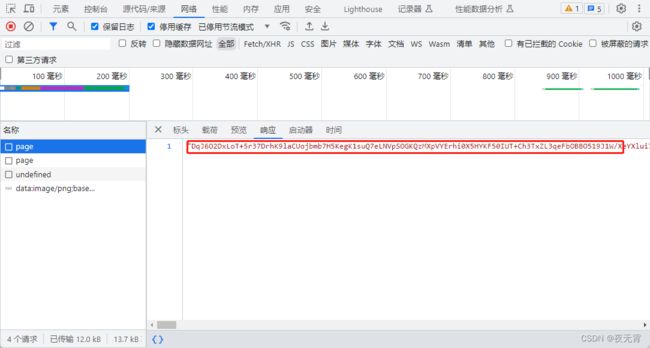
此时我们再次回到网站,发现网站在收到code为511的响应时,会出现一个验证码
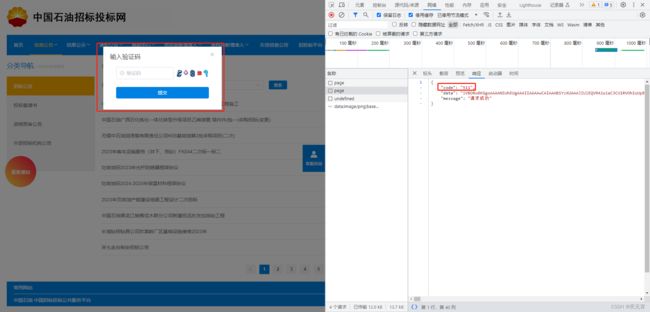
2、处理验证码
点击刷新验证码可以发现,网站是发送一个请求cms/validateCode/undefined获取的验证码,响应中的data是base64编码的图片数据。
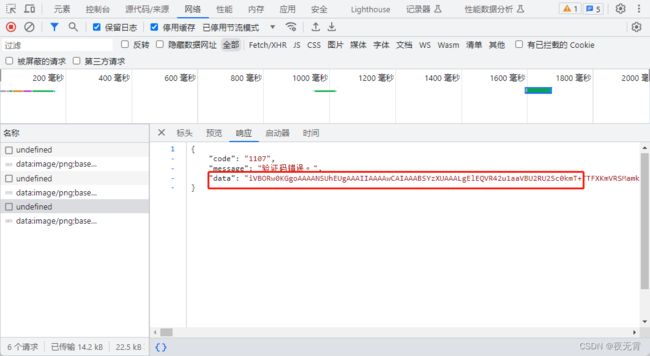
当我们输入一个错误的验证码时,可以发现,网站是将我们输入的内容拼接到路径中进行请求。

所以我们可以先请求undefined接口获取到一个验证码,然后破解验证码(我是使用的第三方打码平台),将破解的验证码拼接到路径中,再次发送请求,然后再获取数据即可。
五、扣js
将加密以及解密位置的代码扣出,缺啥补啥即可。
该网站使用的是webpack,我们可以发现,网站加密时使用的l和m都是来自于webpack中的模块,

所以我们可以在f = n("e2b4")打断点,然后进入到n方法中,扣出加载器,然后再将需要的模块扣出即可。
六、源代码
js源代码因为字数太多无法上传,所以就放在了资源中,在文章最上方点击“立即下载”即可
python源码:
"""
Email:[email protected]
Date: 2023/8/29 11:41
"""
import time
import execjs
import requests
from utils.chaojiying import ChaojiyingClient
class Spider:
def __init__(self):
self.session = requests.session()
self.session.headers = {
"MACHINE_CODE": str(int(time.time() * 1000)),
"Origin": "https://www.cnpcbidding.com",
"Referer": "https://www.cnpcbidding.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36",
}
with open('reverse.js', 'r', encoding='utf-8') as f:
self.js_obj = execjs.compile(f.read())
self.bj = ''
self.pic_str = ''
def get_bj(self):
url = "https://www.cnpcbidding.com/cms/css/bj.css"
response = self.session.get(url)
self.bj = response.text
def get_img_code(self):
url = "https://www.cnpcbidding.com/cms/validateCode/undefined"
response = self.session.get(url)
cjy = ChaojiyingClient('lan8sjk', 'lan8@2023', '946014')
pic_data = cjy.post_pic_base64(response.json()['data'], 6001)
self.pic_str = pic_data['pic_str']
url = "https://www.cnpcbidding.com/cms/validateCode/" + str(self.pic_str)
response = self.session.get(url)
print(response.text)
print(response)
def get_data(self):
data = self.js_obj.call('get_params', self.bj)
self.session.headers['Content-Type'] = "application/json;charset=UTF-8"
url = "https://www.cnpcbidding.com/cms/article/page"
response = self.session.post(url, data=data)
data = self.js_obj.call('get_data', self.bj, response.text)
print(data)
if __name__ == '__main__':
s = Spider()
s.get_bj()
s.get_img_code()
s.get_data()