电商平台用户行为分析—SQL
分析工具:navicat for mysql
一、项目背景
数据来源于某电商平台关于电子、家电等产品的销售数据情况,将围绕产品和用户两大方面展开叙述,为电商平台制定策略提供分析及建议。

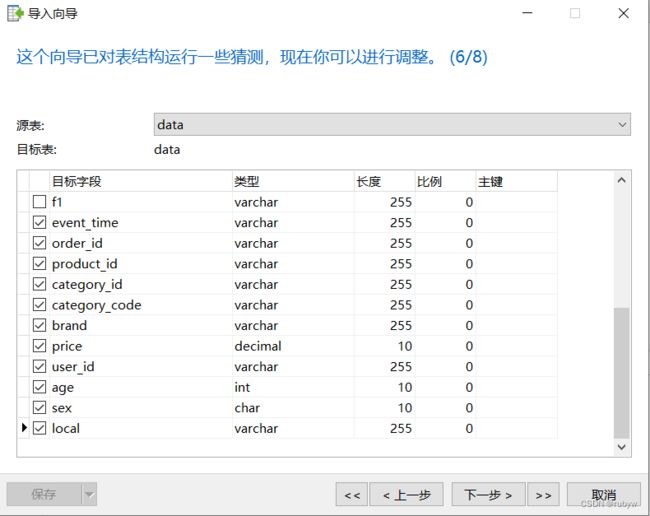
源数据共有11个字段,数据量共56W左右
字段解释:
1 event_time 下单时间
2 order_id 订单编号
3 product_id 产品编号
4 category_id 类别编号
5 category_code 类别
6 brand 品牌
7 price 价格
8 user_id 用户编号
9 age 年龄
10 sex 性别
11 local 省份
根据navicat的导入向导把源数据data.csv导入数据库名为behavior中的data表中,然后新建查询执行mysql语句进行相关分析。
二、数据清洗
1.重复值处理
- 查找重复值
SELECT * FROM data
GROUP BY event_time, order_id, product_id, category_id, category_code, brand, price, user_id, age, sex, `local`
HAVING COUNT(*) > 1;查出共有649条
- 去除重复值
DELETE FROM data
WHERE (event_time, order_id, product_id, category_id, category_code, brand, price, user_id, age, sex, `local`) in (
SELECT t.* FROM (
SELECT * FROM data
GROUP BY event_time, order_id, product_id, category_id, category_code, brand, price, user_id, age, sex, `local`
HAVING COUNT(*) > 1) t
)
AND
user_id NOT IN (
SELECT t.user_id FROM (
SELECT * FROM data
GROUP BY event_time, order_id, product_id, category_id, category_code, brand, price, user_id, age, sex, `local`
HAVING COUNT(*) > 1) t
);2.缺失值处理
- 查找空值
select count(event_time),count(order_id),count(product_id),count(category_id),count(category_code),count(brand),count(price),count(user_id),count(age),count(sex)
from data;
![]()
只有category_code,brand有缺失值,brand缺失值较少直接删除,category_code字段有大量缺失,不能直接删除,使用0填充,方便后续操作。
- 删除缺失值—brand
DELETE FROM `data`
WHERE brand IS NULL;- 填充缺失值—category_code
UPDATE data
SET category_code = 0
WHERE
category_code IS NULL;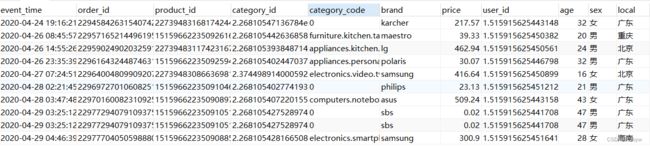
3.时间处理
-- 增加字段date_time
ALTER TABLE data ADD COLUMN date_time VARCHAR(255) NULL; -- 在表data中插入新的一列:列名为date_time,约束条件为NULL
UPDATE `data`
SET date_time = str_to_date(SUBSTRING_INDEX(event_time,' ',2), '%Y-%m-%d %H:%i:%s');
-- 取日期
ALTER TABLE data ADD COLUMN date DATE NULL; -- 在表data中插入新的一列:列名为date,数据类型为DATE,约束条件为NULL
UPDATE `data`
SET date = date_format(date_time, '%Y-%m-%d');
-- 删除字段event_time
ALTER TABLE `data` DROP event_time;
-- 取月份
ALTER TABLE data ADD COLUMN month CHAR(10) NULL;
UPDATE `data`
SET month = EXTRACT(month from date);
-- 取时刻
ALTER TABLE data ADD COLUMN hour CHAR(10) NULL;
UPDATE `data`
SET hour = EXTRACT(hour FROM date_time);
-- 取周几
ALTER TABLE data ADD COLUMN weekday CHAR(10) NULL;
UPDATE `data`
SET weekday = dayofweek(date_time);
4.异常值处理
- date
SELECT date from data where date < '2020-04-24' or date > '2020-11-21';
DELETE from data where date < '2020-04-24' or date > '2020-11-21';
- age
-- 最大年龄、最小年龄
SELECT max(age), min(age) from data;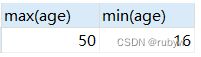
最大年龄50岁,最小年龄为16岁,没有异常
- price
SELECT min(price) FROM data;最小价格为0元,存在异常,查看这部分数据情况
SELECT * FROM `data`
WHERE price=0;
从price为0的这部分数据可以看出其对应的category_code大部分为缺失值,说明这部分商品很可能是赠品或中奖商品,不应该算入用户主动消费行为中,没有分析价值,所以予以删除。
DELETE FROM `data`
WHERE price=0;
三、用户分析
1.性别
-- 性别
SELECT
sex,
count(DISTINCT user_id) 用户人数,
concat(round(count(DISTINCT user_id)/(SELECT count(DISTINCT user_ID) FROM data)*100,2),'%') 用户占比,
round(sum(price)/10000,2) '消费金额(万美元)',
round(sum(price)/count(DISTINCT user_ID),2) '人均消费(万美元)',
concat(round(sum(price)/(SELECT sum(price) from data),2)*100,'%') 消费占比
FROM
data
GROUP BY
sex
WITH ROLLUP;
男女在人数和消费金额方面并无明显差异
2.年龄
-- 创建视图age_cut年龄分段
CREATE VIEW age_cut AS
SELECT order_id, product_id, category_id, category_code, brand, price, user_id, age, sex, `local`,
CASE
WHEN age <= 18 THEN '[16-18]'
WHEN age >=19 AND age <= 25 THEN '[19-25]'
WHEN age >= 26 AND age <= 35 THEN '[26-35]'
WHEN age >=36 AND age <= 45 THEN '[36-45]' ELSE '[45-50]' END AS age_cut,
date_time, date, `month`, `hour`, weekday
FROM data;
SELECT
age_cut,
count(DISTINCT user_id) 用户人数,
concat(round(count(DISTINCT user_id)/(SELECT count(DISTINCT user_ID) FROM data)*100,2),'%') 用户占比,
round(sum(price)/10000,2) '消费金额(万美元)',
count(order_id) AS 下单次数,
round(sum(price)/count(DISTINCT user_ID),2) '人均消费(万美元)',
round(count(order_id)/count(DISTINCT user_id), 2) AS '人均下单(次)',
concat(round(sum(price)/(SELECT sum(price) from data),2)*100,'%') 消费占比
FROM
age_cut
GROUP BY
age_cut
WITH ROLLUP;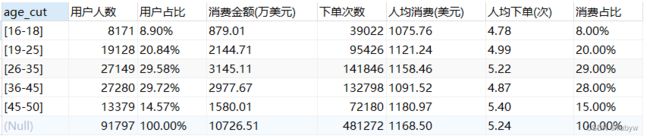
26-45岁人群的数量占比、消费金额、下单次数均比较大,是消费主力军,经济相对独立自主;
46-50岁人群的人均消费和人均下单都是最大的,虽然人数少,但具有巨大的消费潜力,家庭稳定,经济富裕,追求品质更高。
3.区域
SELECT
`local`,
count(DISTINCT user_id) 用户人数,
concat(round(count(DISTINCT user_id)/(SELECT count(DISTINCT user_ID) FROM data)*100,2),'%') 用户占比,
round(sum(price)/10000,2) '消费金额(万美元)',
round(sum(price)/count(DISTINCT user_ID),2) '人均消费(美元)',
concat(round(sum(price)/(SELECT sum(price) from data),2)*100,'%') 消费占比
FROM
data
GROUP BY
`local`
WITH ROLLUP;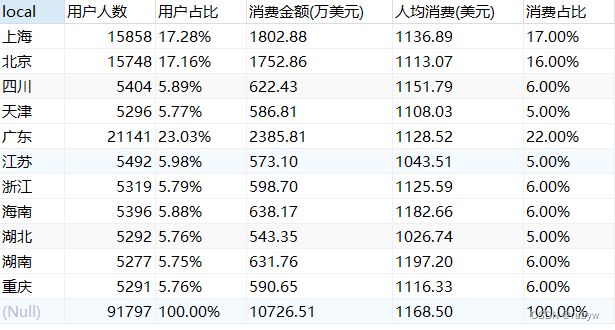
很明显从用户人数和消费金额来看,北京、上海、广东均位列前三名,也比较符合我们的认知,其中广东均为第一;
从人均消费情况来看,湖南、海南、四川位于前三名,其中只有湖南和海南的人均消费超过整体的人均消费水平。
四、用户行为分析
1.复购分析
-- 创建视图记录用户消费次序情况
create view `order of buy` as
select distinct user_id,date,
dense_rank()over(partition by user_id order by date) as buy_rank
from data; 
- 计算 复购率
-- 复购率
SELECT count(*)/(SELECT count(DISTINCT user_id) FROM data) AS 复购率
FROM `order of buy`
WHERE buy_rank = 2;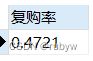
复购率为47%左右,不算高,说明用户的忠诚度不高。
- 计算用户复购周期
-- 用户复购周期情况
select A.user_id,A.date,
datediff(B.date,A.date) as `用户购买周期(天)`
from `order of buy` as A
join `order of buy` as B
on A.user_id = B.user_id
and A.buy_rank = B.buy_rank -1;
用户购买周期时间较长
- 计算用户平均复购周期
-- 用户平均复购周期
select avg(`用户购买周期(天)`) as `平均复购周期(天)`
from
(select A.user_id,A.date,
datediff(B.date,A.date) as `用户购买周期(天)`
from `order of buy` as A
join `order of buy` as B
on A.user_id = B.user_id
and A.buy_rank = B.buy_rank -1) as C;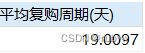
- 计算用户最长消费间隔
-- 用户最长消费间隔
select A.user_id,首次消费日期,最后消费日期,
datediff(最后消费日期,首次消费日期) as 最长消费间隔
from
( select user_id,date as 首次消费日期 from `order of buy`
where buy_rank = 1) as A
join
( select user_id,
max(date) as 最后消费日期 from `order of buy`
where buy_rank > 1
group by user_id ) as B
on A.user_id = B.user_id; 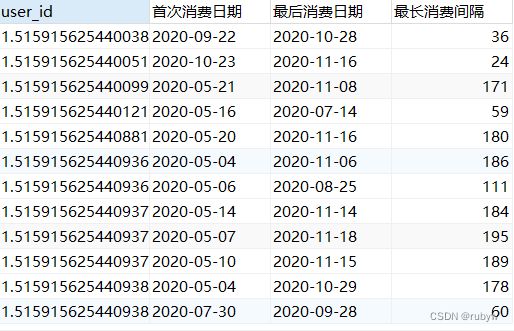
-- 平均最长消费间隔时间
select avg(最长消费间隔) as 平均最长消费间隔
from
(select A.user_id,首次消费日期,最后消费日期,
datediff(最后消费日期,首次消费日期) as 最长消费间隔
from
( select user_id,date as 首次消费日期 from `order of buy`
where buy_rank = 1) as A
join
( select user_id,
max(date) as 最后消费日期 from `order of buy`
where buy_rank > 1
group by user_id ) as B
on A.user_id = B.user_id) as C ; 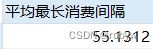
平均复购周期为19天,平均最长消费间隔为55天,考虑到商品耐用的性质也算合理
2.月份
-- 用户人数、消费额按月份分布
SELECT b.month, a.用户数, b.消费额, round(b.消费额/a.用户数, 2) AS 平均消费额 FROM(
(SELECT month, count(DISTINCT user_id) AS 用户数
FROM `data`
GROUP BY `month`) AS a
RIGHT JOIN
(SELECT `month`, sum(price) AS 消费额
FROM `data`
GROUP BY `month`) AS b
ON b.month=a.month);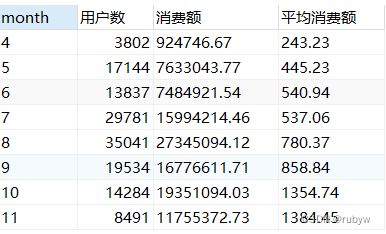
八月份的用户数、消费额均为最高;
十月、十一月的平均消费额较高,其中十一月的用户数较少但平均消费额确实最高的;
四月份的用户数、消费额、平均消费额均为最低,可以分析下原因制定对应措施刺激用户消费。
3.时刻
-- 用户人数、消费额按时刻分布
SELECT a.hour, a.用户数, b.消费额, round(b.消费额/a.用户数, 2) AS 平均消费额 FROM(
(SELECT hour, count(DISTINCT user_id) AS 用户数
FROM `data`
GROUP BY `hour`) AS a
JOIN
(SELECT `hour`, sum(price) AS 消费额
FROM `data`
GROUP BY `hour`) AS b
ON b.hour=a.hour);用户喜欢在上午7点-10点进行下单消费
4.星期
-- 用户人数、消费额按星期分布
SELECT b.weekday, a.用户数, b.消费额, round(b.消费额/a.用户数, 2) AS 平均消费额 FROM(
(SELECT weekday, count(DISTINCT user_id) AS 用户数
FROM `data`
GROUP BY `weekday`) AS a
JOIN
(SELECT `weekday`, sum(price) AS 消费额
FROM `data`
GROUP BY `weekday`) AS b
ON b.weekday=a.weekday);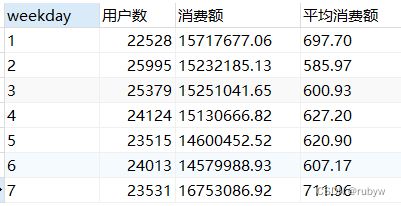
星期二的用户数最多,但平均消费额却最低;
星期日的用户数较低,但消费额和平均消费额却是最大的。
-- 用户人数、下单次数、消费金额按时刻、年龄段分布
SELECT hour, age_cut, count(DISTINCT user_id) AS 用户数, count(order_id) AS 下单次数, sum(price) AS 消费金额
FROM age_cut
GROUP BY `hour`, age_cut
ORDER BY `hour`;五、用户价值分析
1.帕累托分析
-- 20%的用户
SELECT count(DISTINCT user_id)*0.2 FROM `data`;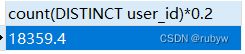
20%的用户大约有18360名
-- 消费前20%用户消费额总占比
SELECT round(sum(t.`消费额`)/(select sum(price) from data), 4) AS 消费额占比
FROM(
SELECT user_id AS 用户, sum(price) as 消费额
FROM data
GROUP BY user_id
ORDER BY 消费额 DESC
LIMIT 18360) t 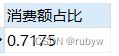
消费前二十名的用户却只贡献了72%左右的消费,接近80%,差不多满足“二八原则”。
2.RFM模型
-- 创建RFM模型视图
CREATE VIEW RFM AS
SELECT a.user_id, a.R, b.F, b.M FROM(
-- 计算R值
(select user_id,
datediff('2020-11-21',date) as R
from `order of buy` as A
where buy_rank =
(select max(buy_rank) from `order of buy` as B
where A.user_id = B.user_id)) AS a
JOIN
-- 计算F、M值
(select user_id,
count(order_id) as F,
sum(price) as M
from data
group by user_id) AS b
ON a.user_id=b.user_id);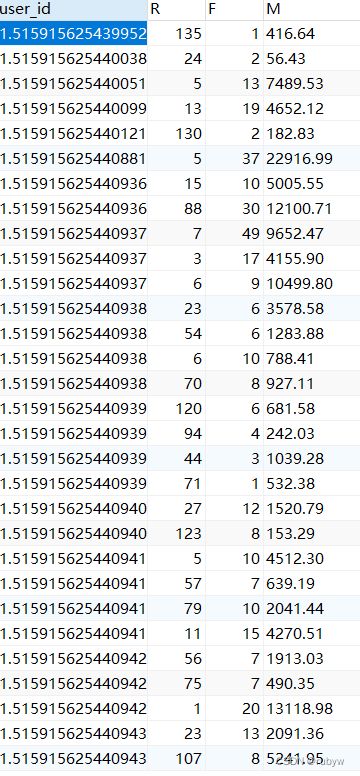
-- 计算RFM阈值
select avg(R) as R阈值,avg(F) as F阈值,avg(M) as M阈值
from RFM; 
-- 创建视图RFM用户价值分类
create view RFM用户价值分类 as
select user_id,
case when R > 97.0029 and F > 5.2430 and M > 1168.490588 then '重要价值用户'
when R > 97.0029 and F < 5.2430 and M > 1168.490588 then '重要发展用户'
when R < 97.0029 and F > 5.2430 and M > 1168.490588 then '重要保持用户'
when R < 97.0029 and F < 5.2430 and M > 1168.490588 then '重要挽留用户'
when R > 97.0029 and F > 5.2430 and M < 1168.490588 then '一般价值用户'
when R > 97.0029 and F < 5.2430 and M < 1168.490588 then '一般发展用户'
when R < 97.0029 and F > 5.2430 and M < 1168.490588 then '一般保持用户'
when R < 97.0029 and F < 5.2430 and M < 1168.490588 then '一般挽留用户'
end as 用户价值分类
from RFM;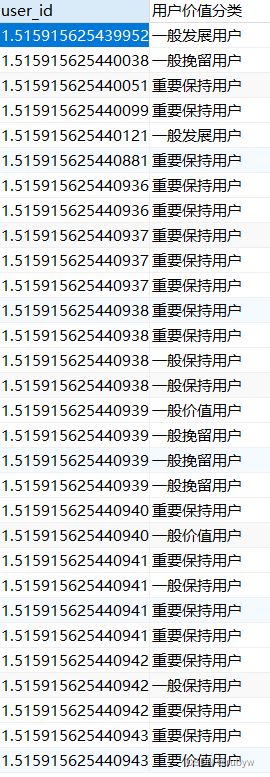
-- 用户价值分类统计分析
select 用户价值分类,count(user_id) as 用户数,
concat(round(count(user_id)/(select count(user_id) from rfm)*100,2),'%') as 用户数比率
from rfm用户价值分类
group by 用户价值分类
order by 用户价值分类; 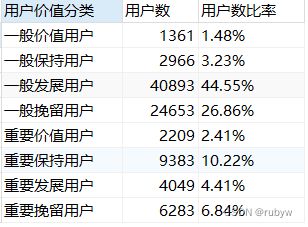
其中,一般发展用户和一般挽留用户数量最多,明显大于其他用户,处于流失边缘的客户很高,重要价值客户反而很少。
六、产品分析
1.销量 TOP10
-- 销量TOP10的产品
SELECT product_id, count(product_id) AS 销量, category_code
FROM `data`
GROUP BY product_id
ORDER BY 销量 DESC
LIMIT 10;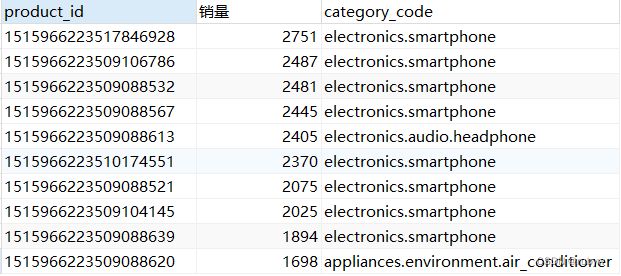
-- 销量TOP10的产品种类
SELECT category_id, count(category_id) AS 销量, category_code
FROM `data`
GROUP BY category_id
ORDER BY 销量 DESC
LIMIT 10;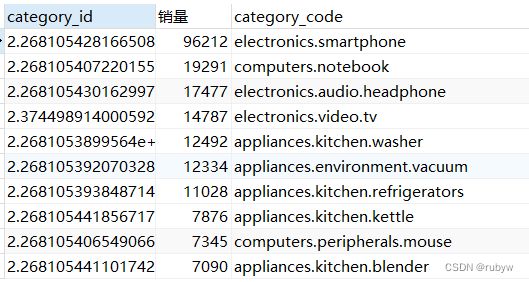
-- 销量TOP10的品牌
SELECT brand, count(brand) AS 销量
FROM `data`
GROUP BY brand
ORDER BY 销量 DESC
LIMIT 10;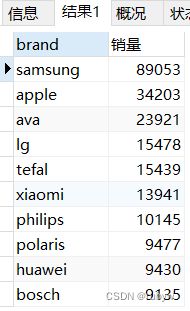
销量前十的产品大部分是智能手机;
销量前十的产品种类主要是电子产品、电脑相关产品、厨房用具;
销量表现最好的品牌是三星,其次苹果;
2.销售额TOP10
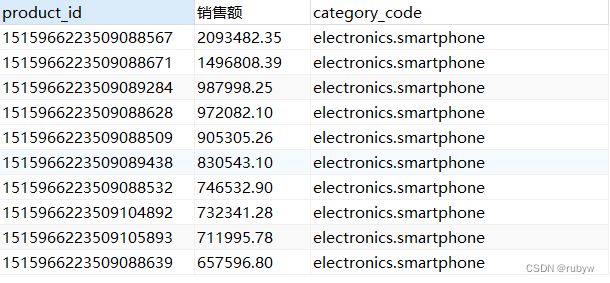
-- 销售额TOP10的产品
SELECT product_id, sum(price) AS 销售额, category_code
FROM `data`
GROUP BY product_id
ORDER BY 销售额 DESC
LIMIT 10;
-- 销售额TOP10的品牌
SELECT brand, sum(price) AS 销售额
FROM `data`
GROUP BY brand
ORDER BY 销售额 DESC
LIMIT 10;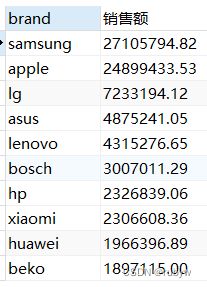
销售额中表现最好的是智能手机, 表现最好的品牌是三星。
3.三星手机对应的人群特征
- 年龄
-- 年龄
SELECT age_cut, count(brand) AS 销量
FROM age_cut
WHERE brand='samsung'
GROUP BY age_cut
ORDER BY 销量 DESC;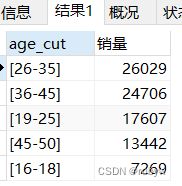
三星用户的年龄主要集中在26—45岁年龄群
- 性别
-- 性别
SELECT sex, count(brand) AS 销量
FROM data
WHERE brand='samsung'
GROUP BY sex
ORDER BY 销量 DESC;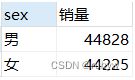
男女用户数量差别不大
- 区域
SELECT `local`, count(brand) AS 销量
FROM data
WHERE brand='samsung'
GROUP BY `local`
ORDER BY 销量 DESC;
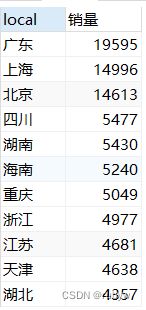
区域主要集中在广东、上海、北京这三个城市
七、结论
1.用户总体特点:
- 男性、女性在消费人数、消费金额相差不大,在喜爱产品类别、品牌上基本一致;
- 26-45岁人群主要是在职人员,经济独立自主,是消费主力军;46-50岁人群家庭稳定、经济压力较小,购买力强,追求更高的品质;
- 北上广城市是消费主力市场,湖南、海南、四川市场潜力巨大,购买力强,后续可重点关注拓展;
2.用户行为习惯特点:
- 由于产品具有耐消耗的特质,所以复购周期相对较长,但在接受范围内;
- 用户在八月份表现最好,在十月份、十一月份这样有活动的月份用户却不活跃,下单较少,没有吸引到用户,需要对活动策划反思,在四月份表现最差,需要寻找原因;
- 用户喜欢在上午7点-10点下单;
- 在星期二下单的用户最多,但大都是小额消费;在星期日下单的用户最少,但大都是大额消费。
3.用户价值分析:
- 用户消费接近“二八原则”,即20%的用户贡献80%的销售,需要对这部分高价值用户重点关注,进行更精细化的营销,后续为这些高价值用户提供更多的高价值消费品,但也要扩大其他用户消费;
- 一般发展用户和一般挽留用户数量占比最多,需要对一般发展用户重点关注,刺激消费频率和力度,处于流失边缘的客户需要分析原因。
4.产品分析
- 销量、销售额表现最好的产品种类是电子产品、产品是智能手机、品牌是三星;
- 三星对应的消费人群特征和用户的总体特征基本一致;
- 表现较差的产品可能已经过时被淘汰,可以考虑是否下架。