技术动态 | 事件图谱schema生成关键前沿技术:如何基于语言模型生成Event Schema代表工作解读...
转载公众号 | 老刘说NLP
做过事件抽取的朋友们都知道,事件schema是一个十分重要的存在,事件schema又称事件模式。
事件模式提供了一种概念性的、结构性的和形式化的语言来表示事件和对世界事件知识进行建模。
不过,在实际的研发过程中,我们会发现,由于现实世界事件的开放性、事件表达的多样性和事件知识的稀缺性,自动生成高质量和高覆盖率的事件模式难度较大。

最近,《Harvesting Event Schemas from Large Language Models》的工作十分有趣,该工作提出了一种新的事件模式归纳范式,从大规模预训练的语言模型中获取知识,设计了一个事件模式采集器(ESHer),通过基于上下文生成的概念化、置信度感知的模式结构化和基于图的模式聚合,自动诱导出高质量的事件模式。
本文对该工作进行介绍,供大家一起参考。
一、背景
事件是人类理解和体验世界的基本单位之一,一个事件是一个涉及多个参与者的特定事件,如爆炸、选举和婚姻。
为了表示事件和建立世界事件知识模型,事件模式提供了一种概念性、结构性和形式化的语言,可以描述事件的类型、特定事件的语义角色(槽)以及不同事件之间的关系。
由于其重要性,自动发现和构建大规模、高质量和高覆盖率的事件模式至关重要,即事件模式归纳。
不过,由于现实世界事件的开放性、事件表达的多样性以及事件知识的稀缺性,事件模式归纳是一项非难事。
首先,在现实世界的应用中,事件类型的规模非常大,新的事件类型不断出现,为了解决这个开放的问题,需要自动生成出事件模式,并且在不同的领域中具有较高的覆盖率。
其次,事件通常是用非常不同的自然语言语句来表达的,因此,通过将它们概念化和结构化为正式的事件模式来规范不同的事件表达。
最后,由于语言的经济原则,事件表达大多是不完整的,许多事件论据是缺失的。为了解决这个稀少的问题,事件模式的归纳方法必须将分散的事件进行聚集。
不过,到目前为止,所有大多数的事件模式仍然是由人类专家手工设计的,这是很昂贵和劳动密集型的,典型的包括MUC、ACE和TAC-KBP。
另一方面,传统的自动事件模式归纳方法仍然不能克服开放性、多样性和稀疏性的挑战。
例如:
自下而上的概念链接方法。通过解析和链接事件表达式与外部模式资源,如FrameNet,来消除事件类型/槽的覆盖,这受到外部模式再来源的质量和覆盖范围的限制。
自上而下的聚类方法。根据预定的模式模板(如5W1H模板,或具有预定的事件类型/槽数的模板)对事件表达进行聚类,这受到预定模板的高度约束。

二、Event Schema Harvester构成
形式上,给定一个未标记的语料库C和一个PLM,事件模式归纳方法可以发现事件集群Y = {y1, y2, ..., yN },其中N是发现的事件类型的数量。
对于每个事件集群y,自动将其概念化为一个名称t以及其相应的语义角色{st1,st2,...},其中et∈T,s∈S和T/S是开放域事件类型/槽的名称。
设计了Event Schema Harvester(ESHer),其框架如图2所示。
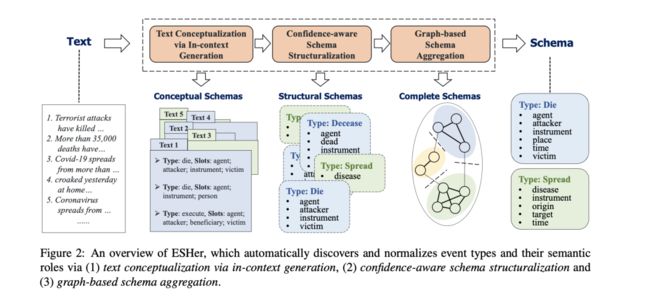
ESHer包含三个部分:
1)基于语境生成的文本概念化,将不同的事件表达转变成基于语境演示的概念化事件模式;
2)基于置信度评分的模式结构化,通过选择并将事件类型与它们的显著性、可靠性、一致性相关联来结构化事件模式;
3)基于图的模式聚合,通过基于图的聚类将分散的稀疏事件知识聚合到单个事件模式中,形成一个完整的事件模式。
三、基于语境生成的的文本概念化

该环节通过语境生成的文本概念化,将不同的事件表达转变成基于语境演示的概念化事件模式;
形式事件通常用不同的自然语言表述,这给模式归纳带来了严峻的挑战。
例如,"恐怖分子的袭击已经杀死了35,000多人 "和 "超过35,000人的死亡是由恐怖分子的袭击造成的 "表达的是同一个事件,但用词和句法结构完全不同。
为了解决这一问题,将不同的事件概念化为模式候选者,这可以提炼出事件模式知识并统一表示它们。
例如,将把上述两个例子中的事件类型和语义角色提炼为同一模式 "Type: die, Slots: agent; attacker; instrument; victim"。
在该环节,利用PLM语境生成能力,提出了一个无监督的文本到模式的框架。
具体来说,将文本概念化建模为一个语境中的生成过程:
→ Schema。
其中:Demonstrations表示示范, "示范 "是一个例子列表,用于指导PLM如何将文本概念化为模式,每个示范是一个<文本,模式>对,表示为 "文本→模式"。
这里 "文本 "是想要概念化的事件语料,"模式 "是概念化的模式,表示为 "类型:t,槽:st1;st2...",而"→"是一个特殊标记,将文本和事件模式分开。
在数据构成上,该工作直接从现有的人工标注事件数据集(如ACE,DuEE)中取样,此外,为了从一个实例中调用更多的事件知识,为每个文本生成n个模式候选者c1, c2, ...cn,其中n是一个超参数。
四、基于置信度评分的模式结构化

文本到模式组件在不同的表达方式中提炼和概念化了事件知识。
该环节旨在解决如何通过选择和评估每个事件类型的突出的、可靠的和一致的槽来结构化这些概念化的事件模式。
例如,可以通过评估事件类型 "die "和槽 "agent; at- tacker; instrument; victim "之间的关联来结构化 "die "事件框架。
在形式上,如下算法1所示,使用O来表示文本概念化的结果。

其中第j个实例是(textj,{cj1,cj2,...cjn})和{cj1, cj2, ...cjn}是n个生成的模式候选者,使用SlotSetj表示实例j的所有生成的槽的联合。
为了给事件类型选择高质量的槽,设计一套指标来估计槽的质量和类型-槽的关联,包括显著性、可靠性和一致性。
1、显著性Salience
一个事件类型t的显著槽应该经常出现在t的生成模式中,但在其他事件中出现的频率较低。
例如,对于 "死亡 "事件,"攻击者 "和 "受害者 "这两个槽位比 "人 "更突出。按照TF-IDF的思想,槽s在第j个实例中的显著性被计算为:

2、可靠性Reliability
如果一个槽位在一个实例的多个候选人中经常与其他槽位共同出现,那么它就是可靠的。
例如,在图2中,槽 "代理 "被认为对 "死亡 "事件是可靠的,因为它与所有其他槽共同出现。在使用上,使用PageRank算法来计算槽的可靠性,具体如下:
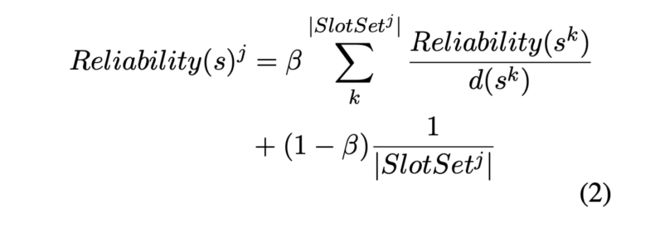

3、Consistency一致性
因为PLM可能会产生不忠实于输入事件表达的模式,所以也需要计算事件类型和槽的一致性。
具体地,使用基于WordNet、HowNet和BERT的语义相似性来评估生成的事件模式与事件表达的一致性。
与此对应的第j个实例中的槽的一致性得分是:

而槽位最终的最终可信度是通过结合显著性、可靠性和一致性的得分计算出来的:
 其中λ1和λ2是两个超参数。
其中λ1和λ2是两个超参数。
最后,只保留每个实例的前1个一致的事件类型,并过滤该实例中的所有槽,如果他们的置信度分数低于一定的阈值,则过滤该实例中的所有槽。
五、基于图的模式聚合

该环节旨在解决如何通过在不同的模式中聚合分散的语义角色来解决稀少的问题。
例如,可以通过将 "类型:死亡,槽位:代理人;攻击者;工具;受害者 "与 "类型:死亡,槽位:代理人;死亡,工具;地点;时间 "结合起来,获得一个更完整的 "死亡 "事件模式。
在这里,该工作提出了一种基于图的聚类方法,该方法首先将单个事件模式归入群组,然后将事件类型和槽聚集在同一群组中。
这里的逻辑在于,如果事件模式的原始表达式描述的是同一种发生(文本相似性),它们预先预测的类型是同义词(类型相似性),并且它们有许多共同的语义槽(槽集相似性),那么它们就属于同一事件类型。
例如,"die "和"decease "是同义词,"agent "和 "instru- ment "是共同的语义角色,因此它们很可能是同一事件类型。
在聚类上,采用Louvain算法将模式分割并归入群组。

其中,yˆj∈Y = {y1, y2, ..., yN }表示第j个模式被分配到第yˆj个事件集群,每个集群代表一个不同的事件类型。
对于事件槽,在槽中可能有同义的槽名代表相同的语义角色,例如,{死亡,受害者}是上述例子中的同义集。
因此,再次利用Louvain算法(来识别同义事件槽,然后选择最突出的槽来代表其同义词,例如,"受害者 "被选为同义词集{dead, victim}的代表槽名。
在构图阶段,构建一个图来模拟不同个体事件模式之间的相似性。
具体的,在图中,每个节点是一个事件模式,两个模式节点之间的相似性是通过考虑它们的事件表达式之间的相似性、事件类型之间的相似性和槽集之间的相似性来计算的:

Sim()代表语义相似度函数。
六、实验效果
为了验证方法的有效性,该工作做了系列实验。
首先,在数据集上,使用ERE-EN作为主要数据集。此外,为了评估不同领域和语言的事件模式归纳性能,进一步对其他数据集进行了测试。

其次,在模型上使用BLOOM模型对于文本概念化阶段的指示数据,从ACE和DuEE中分别抽取了英文和中文数据集的示范数据。
最后,看看实验效果。
1、定性与定量结论
图三中给出了具体的效果,图3显示了由ESHer从ERE-EN和ChFinAnn数据集中诱导出的几个模式,并显示了与人类专家结果的比较。
可以看出,ESHer可以诱导出高质量的事件模式,有以下几个发现:
1)大部分生成的事件类型与专家标注的事件类型直接匹配;
2)自动生成的槽和人工注释的槽之间有很大的重叠;
3)一些不匹配的槽通过人工检查也是合理的。这也表明,仅仅依靠专家是很难获得高覆盖率的模式的。
4)一些缺失的槽是在文本概念化中产生的,但在置信度感知的结构化中却被放弃了,这表明通过引入人在环的方式可以进一步提高性能。
5)通过适当的语境演示,ESHer可以很容易地扩展到不同的语言,例如,英语用于ERE-EN,中文用于ChFinAnn。
再看定量结论。
对于定量结果,在表1中可以看到具体的效果。

可以看到:
对于事件类型的发现,ESHer恢复了ERE-EN中38个事件类型中的21.05%,几乎所有发现的事件类型(85.92%)都是可以接受的。
对于事件槽的归纳,ESHer恢复了115个槽中的11.30%,44.95%的发现的槽可以被直接接受,35.21%的槽可以从候选中选出。
2、事件提及聚类的结果
该工作通过事件提及聚类任务来评估ESHer的有效性。
选择了15个提及次数最多的事件类型,并将所有的候选者分为几组,用于ERE-EN。
为了评估聚类是否与原始类型一致,选择了几个标准指标:
1)ARI测量相似度;
2)NMI测量归一化互信息;
3)BCubed-F1测量汇总的精度和召回率。
对于上述所有指标,数值越高,模型的性能就越好。
在基线对比上,该工作将ESHer与以下基于特征的方法进行比较:Kmeans、AggClus、JCSC、Triframes-CW、Triframes-Watset和ETypeClus,在参数设置上使用默认的设置来设置这些集群的所有超参数。
 表2显示了总体以及消融实验的结果,可以得到以下结论:
表2显示了总体以及消融实验的结果,可以得到以下结论:
首先,ESHer在所有指标上都超过了ERE-EN的所有基线。
ESHer以56.59的ARI、67.72的NMI和62.43的BCubed-F1实现了最先进的性能,这是因为ESHer充分地利用了PLM的in-context学习能力,因此可以有效地解决多样化和稀疏的挑战。
其次,代表性、可靠性和一致性估计都是有用的,并且是相互补充的。
与完整的ESHer模型相比,所有五个变体都在不同程度上表现出了下降的性能。ESHer优于ESHer-Salience 23.75 ARI, 9.81 NMI和9.92 BCubed-F1,这一结果验证了显著性分数对于识别好槽的有效性。
ESHer优于ESHer-Consistency 19.08 ARI, 1.60 NMI和11.74 BCubed-F1,这表明一致性估计也是不可缺少的。这些结果也验证了高质量的槽集对基于图的聚合是有益的。
3、不同领域的结果
在不同领域的测试上,下图4显示了结果模式,可以看到ESHer在不同的领域也是稳定的,并且可以推广到其他不同的环境。

但该工作提出了一些问题还需解决,包括如下三种。
1)粒度对齐问题:同一模式中的槽可能有不同的粒度,例如,在大流行病领域的模式1中的 "人 "和 "医生、病人";
2)多义性问题:在泛大流行病领域的模式2中的事件类型 "管理 "误导了槽 "管理员";
3)情感表达:事件模式知道应该是客观的,但 "煽动者 "传达了负面情绪。
总结
本文主要介绍了《Harvesting Event Schemas from Large Language Models》这一关于事件模式自动生成的有趣工作,其核心在于利用生成的方式来做候选模式,通过打分过滤,最后通过图聚类方式得到最终结果。
当然,本文是对该工作的介绍,有些解读不是很到位甚至存在错误,关于进一步的细节,可以看论文原文。后面,我们将对论文源代码做进一步地阅读,供大家参考。
感谢这个有趣的工作。
参考文献
1、https://arxiv.org/abs/2305.07280
2、https://github.com/TangJiaLong/Event-Schema-Harvester
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。