运维监控工具越来越多,但却毫无成效?
监控重点似乎是如何让那些从事监控的公司赚钱,而不是如何减少从客户端通过网络传输的日志和指标。
我必须坦白,很多次我都是因为监控平台的经验而求职成功,但现在的我非常讨厌监控。监控和可观察性工具的一大罪状是欺骗,让我们误以为这是一个简单的问题。监控小型应用程序或服务非常简单,但这些方法都没有可扩展性。
监控实际上就是一系列无休止的小故障,比如指标突然不见了,日志突然被删除了,用于追踪的 Web UI 突然不工作了。设置这些工具的时候,你以为设置好后就不用管了,但实际上维护的工作量会越来越大。有些工具坏了,而且永远无法修复。好多次,我进入一家公司后发现他们部署了一个没有人会喜欢的破烂。
感觉我们拥有的监控工具比以往任何时候都多,却毫无成效。如今似乎监控的重点是增加应用程序的输出,这样就可以让那些从事监控的公司赚钱。似乎我们很少考虑如何减少从客户端通过网络传输的日志和指标。相反,我们会运行更复杂的系统,捕获大量数据,然而这些数据的使用却越来越少。
本文阐述了我的一些建议和希望,我希望你能指出我的错误,并告诉我还有更好的解决方案。
一、日志
日志是一个很好的监控工具。就像一个个小纸条,告诉你系统内部发生了什么。根据我的经验,日志本质上就是“输出语句,并存储到磁盘”。由于磁盘空间被拿来存储根本没有用的信息,所以很快日志就无法扩展了,虽然这些信息在测试期间发挥了一定的作用,但如今已经没有人关心了。经常听到有人说:“我们来建立日志级别的监控。”但实际上,这个决定让我感到很迷惑。
1. 日志级别的监控没有任何意义
系统日志级别
**
**

Python级别
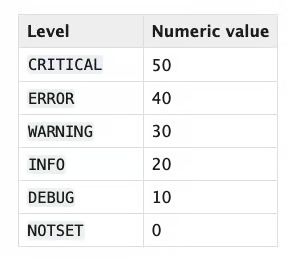
Golang
**
**

2. 日志格式花样百出
- **JSON 日志记录:**易于解析,但嵌套 JSON 可能会破坏解析器,而且开发人员很容易更改格式。
- **Windows 事件日志:**数据量过大,文档没有交待它有多少“标准”。
- **通用事件格式:**良好的规范,但我从未见过网络硬件公司之外的人使用这种格式。
- **GELF:**一种非常好的格式,旨在与 UDP 配合记录日志(一些大公司的要求)。
- **通用日志格式:**基本上是 Apache 日志:127.0.0.1 user-identifier frank [10/Oct/2000:13:55:36 -0700] “GET /apache_pb.gif HTTP/1.0” 200 2326。
- **Nginx 日志格式:**log_format combined '$remote_addr - r e m o t e u s e r [ remote_user [ remoteuser[time_local] ’ ‘“$request” $status KaTeX parse error: Double superscript at position 19: …y_bytes_sent ' '̲"http_referer" “$http_user_agent”’;
3. 日志的用途没有广泛的共识
传统思想认为,debug 级别的日志通常只在本地或在开发环境中使用,info 级别的日志通常会被丢弃(你可能并不需要知道应用程序何时完成了一些正常的操作),所以我们应该将所有info以上级别的日志都记录下来。问题是,对于一些系统而言,特别是分布式请求的现代微服务,通常日志记录是唯一了解系统内部发生了什么的渠道。
一种常见的做法是在请求中附加一些 ID 标头,例如 UUID。然后,将这个 UUID 返回给最终消费者,这样客服就能够根据这个 UUID 来判断“此时该客户干了什么”。因此,平台日志变成了调试平台内部所有问题的主要工具,而不仅仅捕捉系统崩溃前执行的语句。
这对客服非常重要(了解客户在何时做了什么);如果审计要求保留每次交互的记录,那么对审计也非常重要。因此,很快一个原本非常简单的要求“捕获并发送以上所有信息”就变成了一个更大的项目,日志搜索和捕获基础设施变成了关键任务。日志记录成为了回溯个人用户或交互实况的唯一方法。很快,这些数据会被发送到业务分析,日志就变成了记录收到的请求数量或该新客户是否使用该平台等的真实数据来源。
突然之间,似乎简单的 Syslog 系统已经无法满足这些需求了,因为你无法让别人通过 SSH 连接到服务器执行查询。你需要某种用户友好的界面。也许你可以尝试一下 ELK,但实际上运行 Elasticsearch 非常痛苦。你尝试了 SigNoz,确实有效,但结果是 SigNoz 本身也变成了一个经常会出错的关键业务。
很可能这并非组织中某个人的全职工作,他们只是碰巧承担起了日志记录的工作。他们安装了一些 Helm 图表,将其放在 OAuth 代理后面,然后期盼着能够得到最好的结果。然而,实际情况是他们不断收到来自日志系统消费者的大量投诉。“日志丢失,搜索出问题了,解析器无法返回预想的结果……”
日志开始充当商业智能的数据来源、客服工具、主要调试工具、了解部署的方式等。我的许多工作都有类似的经历,而且这种方法非常脆弱,经常会遇到这样的情况:“之前好好的,怎么突然就出问题了?”
相信有此类经历的不止我一个,我只是把它放在了云/SaaS/对象存储中。
由于记录了每一条日志,因此成本也随着新客户的增加而增加。实质上,这种做法非常糟糕,尤其是当应用程序的流量很大,或者一天之内有很多请求时,就会变成一个非常严重的问题。我的经验是,各个公司都不希望监控应用程序的成本轻易超过托管应用程序的成本,即便是一些非常简单的应用程序。
日志记录发展的最终结果大致有两种:第一,为你关心的用户请求添加某种非日志系统;第二,坚持使用 SaaS,然后积极监控使用情况,希望获得最佳结果和/或维护一个完整的端到端日志记录基础架构,将所有信息写到你管理的磁盘。
日志这个概念本身没有任何问题,但它并不能作为真正的工具使用,除非你愿意投入大量的工程时间来维护日志,或者愿意向提供商支付大量资金。最重要的是,很快就会有人编写日志解析器,在遇到某些情况时发送警告,虽然这种做法本身没问题,但这会导致日志的重要性增加,下一步你就需要标准化日志记录格式,或者将旧格式转换为新格式 。
另一个问题是,存储日志是一件很愚蠢的事情。99.9999% 的日志永远都不会用到,你不过是将它们扔进仓库,直到最后也无人问津。更糟糕的是,还有人使用 Athena 之类的工具查询巨大的存储桶,不仅成本过高,而且压根没有开发人员花这么大力气去翻日志里的信息。
建议
如果日志消息是监控整个微服务系统的主要方式,那么就需要坐下来认真思考。它的成本是多少,出问题的频率有多高,可以扩展吗?不存储日志行不行?
如果出于合规性或法律原因必须存储日志,请务必使用另一个系统,不要用保存每一条请求的系统。将审计日志写入数据库(理想情况下)或日志记录管道外部的对象存储。我使用的是 DynamoDB,并衔接到了 SQS 管道 -> Lambda -> Dynam,效果不错。而内部的应用程序可以查询此信息,并且你无需担心 DynamoDB TTL 的日志过期问题。
如果日志记录不是很重要,那么就需要设置并强制执行较低的 SLA。99% 的 SLA 意味着每月减少 7 小时 14 分钟。这主要是一个管理问题,但这意味着你需要让系统出问题,打破人们认为日志系统无限可靠的惯性思维。
如果组织需要更高的 SLA,则可以花钱购买 SaaS 并将其计入运行应用程序的成本。尽可能为每个应用设置外部 SaaS 的收费标签非常重要。你需要向各个团队汇报说:“你们的应用程序在可观察性方面花了好多钱”,而不是“整个业务在可观察性上花了很多钱”。
采样很重要。OpenTelemetry 有一个 alpha 功能支持日志采样。它支持基于优先级的采样,这对我来说很关键。一部分日志的优先级不需要设得太高,但理想情况下,随着服务成熟,你可以不断调低优先级。
如果需要编写一堆正则表达式来解析日志,那么只能祈祷日志的格式不会变化。
希望和梦想
结构验证能成为 JSON 日志收集器的组件。我们应该确保日志遵循组织的结构,并统一决定是否将日志融入到我的系统中。如果能在开发环境中强制实现这一点更好,因为这样人们能立即看到日志没有显示。
采样日志更重要。我的梦想是将它们与部署联系起来,这样我就能在部署前、部署时以及部署后的一段时间内将保留率提高到 100%。收集器调用 API 查看应用程序的正常故障率是多少,如果应用程序的故障率保持不变,则增加采样。
我喜欢 GCP 的日志流方案:
尽管 Google Cloud 不会捕获每个数据包,但捕获的日志记录可能会非常大。你可以调整日志收集的以下方面来平衡流量的可见性需求与存储成本:
- **聚合间隔:**将某个时间间隔内的采样数据包聚合到一个日志条目中。这里的时间间隔可以是 5 秒(默认)、30 秒、1 分钟、5 分钟、10 分钟或 15 分钟。
- **采样率:**在写入日志之前,可以对日志数量进行采样,以减少日志数量。默认情况下,日志条目量按 0.5(50%)的比例采样,这意味着只保留一半的日志条目。你可以自由设置,范围为1.0(100%,保留所有日志条目)到 0.0(0%,不保留任何日志)。
- **元数据注释:**默认情况下,流日志条目使用元数据信息进行注释,例如源和目标虚拟机的名称或外部源和目标的地理区域。元数据注释可以关闭,也可以仅指定某些注释,以节省存储空间。
- **过滤:**默认情况下,为子网中的每个流生成日志。你可以设置过滤器,仅生成符合特定条件的日志。
我也希望能实现这一切。
二、指标
既然日志都是垃圾,信噪比过低,那么我们是不是可以考虑使用指标来代替。听起来貌似不错。刚开始的时候,指标会非常简单。添加与 Prometheus 兼容的指标非常简单,只需要一个客户端库。你必须确保 Prometheus 能够获取这些指标,通常只需要使用一些 Kubernetes DNS 正则表达式或内部区域 DNS。然后,为 Prometheus 添加一个 Grafana 前端,再使用 Google 一键登录就可以了。
实际上,Prometheus 适合在一台服务器上运行。如果需要添加更多指标和目标,则可以垂直扩展,但可以增长的规模是有限的。另外,当 Prometheus 出现问题时,整个技术栈都会失去可见性。接下来,你就需要设计联合。这时,人们就开始感到恐慌,并考虑花钱请人来做这件事。
三种扩展方式
你可以:
\1. 采用分层联合,即一台 Prometheus 服务器从另一台服务器获取更高级别的指标,如下图所示:
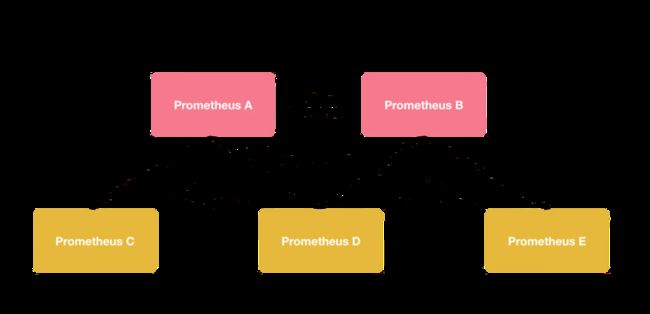
千万不要低估这种结构的复杂性。首先你需要将所有数据都存储下来,然后分析哪些指标重要、哪些指标不重要,如何在 Prometheus 内部进行聚合,而且你还需要为这些新服务添加带外监控。我亲身实验过,确实可行,但非常痛苦。
\2. 跨服务联合设置起来比较简单,但也有其怪异之处。底层是普通的 Prometheus,然后再通过一组 Prometheus 读取数据,并将所有服务都指向“主”节点。
这种设计可行,但需要大量磁盘空间,而且你仍然会遇到上面提到的监视问题。另外,这种方式的复杂性更进一步。
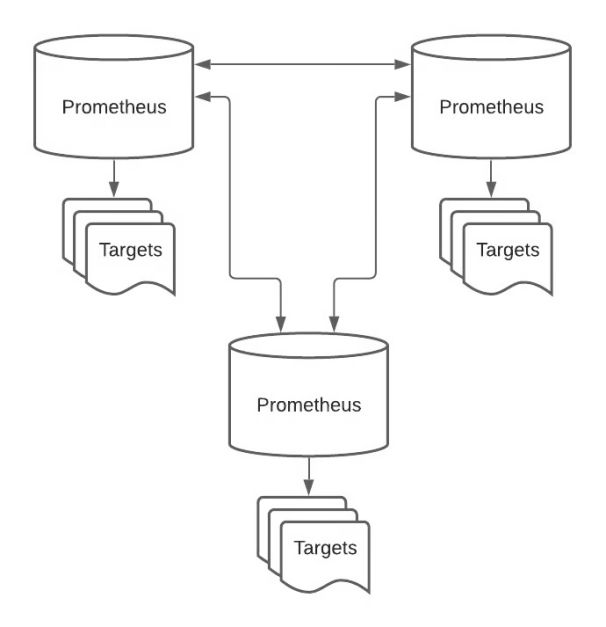
我需要一个端到端的指标与警报平台。
上述例子可以很好地处理短期指标。扩展规模取决于“机器的磁盘大小”,如果是放到云中,则没有任何问题。然而,所有这一切都是为了将指标作为开发人员的工具。与日志类似,随着指标的重要性越来越突出,人们对它们的兴趣会超出调试应用程序的范围。
接下来,你就需要追踪整个技术栈的各种信息,并进行各种分析,比如“营销活动有多成功”、“我们需要知道大客户的 API 集成是否突然增加了5倍,这样我们就可以告诉他们的客户经理。”以及“如果客户停止使用该平台,你能否告诉我们,这样我们就可以联系他们,并给他们一定的折扣?”等等。我的工作中会收到很多类似的请求。
我需要大量指标。
随着时间的推移,人们想要的指标数量必然会增加,保留时间也会增加。他们不仅需要有关服务的更多具体信息,而且很多时候还需要与客户或特定路线有关的信息。此外,他们还希望根据这些路线发出警报,将这些信息就地存储起来,并使用指标执行各种上游操作。
这时,指标相关的工作就会变得越来越复杂。
Cortex
Cortex 是一个推送服务,你可以从 Prometheus 栈推送指标,并进行处理。Cortex 有一些非常好的功能,包括删除冗余 Prometheus 服务器传入的重复样本。因此,你可以建立一堆冗余 Prometheus,将它们指向 Cortex,然后只存储一个指标。为此,你需要添加一个键值存储,所以你的工作量又增加了。以下是你需要添加的 Cortex 服务:
- Distributor
- Ingester
- Querier
- Compactor
- Store gateway
- Alertmanager(可选)
- Configs API(可选)
- Overrides exporter(可选)
- Query frontend(可选)
- Query scheduler(可选)
- Ruler(可选)
我用过 Cortex,感觉良好,但是需要花费很多心思才能运行起来。除了运行和管理 Prometheus 服务器,还需要编写配置和监控,完全就是一个大项目。此外,你还可以考虑在 kubernetes 集群或服务器组中运行 Cortex。
Thanos
Thanos 的作用相似,但设计不同。它是一个 sidecar 进程,可以获取指标并使用更简单的模块化系统移动它们。我刚开始使用 Thanos,我发现这是一个非常简单的系统。然而,除了一些非常简单的设置外,你还需要添加很多东西。不过,在 Cortex 和 Thanos之间,我更推荐 Thanos,因为它易于上手。以下是你需要添加的 Thanos 服务:
- **Sidecar:**连接到 Prometheus,读取数据,和/或将其上传到云存储。
- **Store Gateway:**提供云存储桶内的指标。
- **Compactor:**对云存储桶中存储的数据进行压缩、降低采样并应用保留。
- **Receiver:**从 Prometheus 的远程写入预写日志接收数据,公开和/或将其上传到云存储。
- **Ruler/Rule:**根据 Thanos 中的数据评估记录和警报规则,公开和/或上传数据。
- **Querier/Query:**实现 Prometheus v1 API,聚合来自底层组件的数据。
- **Query Frontend:**实现 Prometheus v1 API,将其代理到 Querier,同时缓存响应,并按每天的查询拆分响应(可选)。
这也太复杂了,我还是会选择 SaaS。
这些工具很棒,但价格不菲。所有与日志记录相同的规则都适用。你需要仔细监控数据的获取,并确保不会意外捕获高基数指标。等到月底收到账单时,你会吓一跳,因此在实际使用前,请先做好评估和测试。
建议
从第一天开始就为指标的保留定义一个硬性限制。指标的保留时间对你的构建工作就很大的影响。我使用了一个唯一的Prometheus,并将指标的保留时间限制为 30 天。我知道有些人希望保留更长的时间,但我觉得 30 天足够了。
如果指标是主要的可观察工具,那就必须做到尽善尽美。如果整个业务都依赖 Prometheus,那么升级 Prometheus 就会变得更加困难,而且每次停机上下沟通也需要花费很多时间。我会尝试使用 Thanos 或 Cortex,这样如果想长期保留大量指标,你就有更大的灵活性。
列出可接受的最终状态。如果指标的数量庞大,那么 Cortex 是更好的选择。我见过有些人非常了解 Cortex,他们使用 Cortex 来控制和处理所有指标,且速度高达每秒160 万个。然而,如果目标不是单一的数量,而是长期存储和可访问性,那么我会选择 Thanos。
与许多人不同,我认为指标就是会占用大量的时间。我从未见过一个完全不需要干涉的系统,可以大批量工作而无需高昂的成本。你需要监视指标系统,更改它们获取的数据,修改配置,这些工作非常耗时。
三、追踪
我们可以通过日志了解系统的内部情况,但日志的信噪比很低。指标也可以告诉我们系统内部发生的情况,但当基数过大时就不适用了。追踪是五年前热门的新技术。追踪解决了以前的许多问题,而且还可以收集有关请求的大量数据。此外,追踪还可以实现不依赖平台的监控。请求从应用程序发出,经过负载均衡器,到后端和微服务,然后再返回,你可以一路追踪。
对我来说,追踪的真正优势在于它自带采样功能。它是调试和故障排除的工具,而非服务于合规性或商业用途。因此,随着时间的推移,人们并不会强加各种奇怪的要求。你可以非常安全地进行采样,因为追踪只适用于开发人员排除故障。
根据我的经验,我认为最合适的做法是使用 SaaS 并配置跟踪。我使用最多且体验最好的是 Cloud Trace。它很容易实现,而且价格控制很简单,还有我喜欢的故障排除元素。
在我看来,追踪的问题是没有人使用它,我监控了团队使用跟踪的情况,发现只有一小部分开发团队登录使用它们。我不知道为什么这个工具无法获得更多开发人员的喜爱。可能是人们更喜欢指标和日志,或者是他们没有看到使用追踪的价值。到目前为止,我还没有见过“正确使用”的追踪。
希望有一天这种情况会改变。
四、总结
也许我对监控的看法是错误的。也许有人很喜欢监控,而我却在苦苦挣扎。我的经验是监控是一种非常不受欢迎的内部服务。这项工作需要付出大量努力,花费大量的资金,而且永远不会给公司带来任何利润。
我认为最合适的做法是使用 SaaS 并配置跟踪。我使用最多且体验最好的是 Cloud Trace。它很容易实现,而且价格控制很简单,还有我喜欢的故障排除元素。
在我看来,追踪的问题是没有人使用它,我监控了团队使用跟踪的情况,发现只有一小部分开发团队登录使用它们。我不知道为什么这个工具无法获得更多开发人员的喜爱。可能是人们更喜欢指标和日志,或者是他们没有看到使用追踪的价值。到目前为止,我还没有见过“正确使用”的追踪。
希望有一天这种情况会改变。
四、总结
也许我对监控的看法是错误的。也许有人很喜欢监控,而我却在苦苦挣扎。我的经验是监控是一种非常不受欢迎的内部服务。这项工作需要付出大量努力,花费大量的资金,而且永远不会给公司带来任何利润。
原文链接:https://matduggan.com/were-all-doing-metrics-wrong/