多模态论文串讲(bryanyzhu老师)记录
文章目录
- 回顾ViLT和CLIP
- 序言
- ALBEF
-
- 摘要
- 方法
- 实验
- VLMo
-
- 引言
- 方法
- 实验
- BLIP
-
- 引言
- 实验
- CoCa
- BeiTv3
-
- 摘要
- 方法
- 实验
- 总结
传统的多模态:
检索, 视觉问答(闭集,分类,开集,生成), 视觉推理(判断文本能否描述图像), 视觉蕴含(给定假设能否推理出前提)
新颖的多模态:
language-guided detection, language-guided segmentation, text2img generation
只用Transformer Encoder的一些方法:
CLIP, ViLT, ALBEF, VLMo
同时使用Transformer Encoder和Decoder的一些方法:
BLIP, CoCa, BEIT v3, PaLI
截止时间为2022年12月12日.
回顾ViLT和CLIP

ViLT的研究动机是给视觉编码器减负.
a. VSE等, 视觉端庞大, 简单的模态交互;
b. CLIP等;
c. OSCAR, UNITER等, 复杂的模态交互(意识到模态交互的重要性);
d. ViLT等;
Textual Embedding : Tokenizer;
Visual Embedding : Patch Embedding;
Modality Interaction : 借鉴c类VLM.
缺陷: 性能比不过c类的方法. 训练复杂度较高.
序言
好的多模态模型是什么样的?
- 更大更强的视觉模型;
- 好的模态融合模型;
即c类模型.
那么目前的有哪些训练目标呢?
- Image Text Contrastive;
- Mask Language Modeling;
- Image Text Matching;
- WPA Loss(目标检测).
ALBEF

- 图像编码器大(12>6);
- 融合模块大(6);
符合先前工作的一些总结.
摘要
第一个贡献为: Align before Fuse
目标检测器得到的视觉特征和文本特征难以对齐(ViLT也抵制, 但是出发点是加快推理速度), 因为目标检测器提前训练好, 没有进行End2End的训练.
那么如何在MultiModal之前, 让图文特征对齐? 即提前用CLIPLoss对齐图文编码.
第二个贡献为: Momentum Distillation.
采用了MoCo提出的Momentum Encoder的形式, 提出了Momentum Model, 构建伪标签以达到自训练的结果, 目的是为了对抗噪声样本(Noisy Web Data).
通过互信息最大化的角度对ALBEF做理论分析, ITM MLM ITC最终的作用都是为同一个图像文本对提供不同的视角, 变相的在做一种data augmentation, 即语义匹配的图像文本对应该被认为是一对.
八卡机, 4m数据, 训练四天.
方法
Vision Transformer采用DEiT在Image-1k上训练出来的参数初始化. 文本模型采用BertModel. 为了控制计算复杂度, 最优配比, 模态融合, 将BertModel劈开, 另一半用作模态融合.
ITC: 取出图文编码器的cls token, 映射为256维度. 负样本储存在一个队列中.
ITM: 二分类, 加FC层. 过于容易, 于是在选取负样本的同时设置约束.
MLM: 在计算ITC和ITM Loss的时候都是原始的I和T, 在计算MLM时则是mask的T. 因此, ALBEF进行了两次前向过程.
Momentum Distillation: Noisy Data会带来一些偏差(负样本的文本包含图像中的一些描述, 甚至比正样本还要好, 这对ITC有很强的负面影响, MLM同理, 会有一些更好的词适合完形填空. 采用one-hot的形式一味地惩罚负样本对, 这对ITC和MLM不是很友好, 所以构建一个多类标签是自然而然的).
本文希望既能学到one-hot label的知识, 也能够学到pseudo targets的知识(当one-hot的知识不准确时), 于是选取相加的形式.
这一思想应用在ITC和MLM中. ITM是一个二分类任务, 且设计了特殊的负样本选取方式, 这是与动量蒸馏冲突的, 因此不采用.

上图展示了pseudo targets的效果.
数据集:
- CC3M, SBU, COCO, VG (CC3M和SBU已经丢失了近百万的数据) 图像有4M, 图文对有5.1M.
- CC12M, , SBU, COCO, VG 14M.
实验
四个标准实验 + VisualGrounding

- 增加ITC后提升巨大;
- Hard Negtive较为有效;
- Momentum Distillation有效但提升不大;
- 数据量的增加是有效的.
VLMo
- 模型结构的改进;
- 训练方式的改进.
引言
研究动机1: 目前多模态的领域有两种结构, 第一种是双塔结构(CLIP, ALIGN), 融合模块简单, 做检索时可预先抽取特征再做简单推理, 十分高效, 但是融合方式简单, 无法做到较好的对齐(VQA, NLVR). 第二种是单塔结构, 弥补了双塔的缺陷, 但是检索时要把所有可能的图文对进行推理. 综上所述, 简单任务, 有速率要求选双塔, 难任务, 选单塔. 因此, 本文想提出一种可选的结构.
VLMo的训练目标和ALBEF保持一致.
VLMo发表时LAION还没出现, 且CLIP的WIT并没有公布, 所以苦于多模态数据较少. 本文提出先在各自模态的数据上预训练, 对图文编码器有很好的初始化参数.
方法
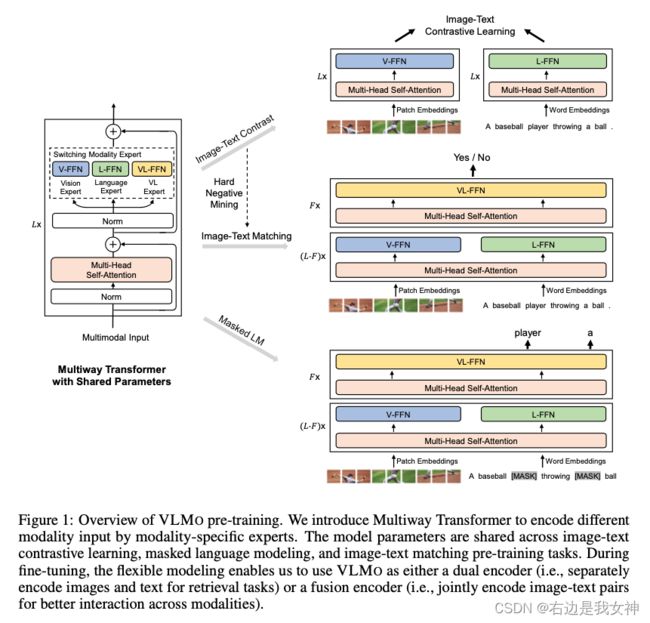
针对不同的模态, 有不同的FFN. 在block中, MHSA是共享的.
自由选择用哪个modality expert, 自由选择模式.
VLMo的训练代价很大, 64张V100也要训练两天.

视觉上训练后, 在文本上冻住, 只微调L-FFN, 效果不错.
进行多模态融合时, 全部打开.
VLMo最大的贡献应该是证明了参数共享是有效的!
实验

Unimodality能够帮助Multimodality. 反之或许也可以.
BLIP
引言
动机1 : Encoder Only的结构很难用于生成任务; 对于Decoder Only, 则很难用于image-text retrieval tasks(与VLMo类似)
动机2: 目前的模型在网上爬取的噪声数据训练, 使用嘈杂数据做预训练效果还是不好的, 虽然提升数据量可以缓解.

Filt模型判断是否匹配, Cap模型生成对应描述.
实验

ALBEF在文本编码器端, 把N层劈成N-L和L层, 目的是为了限制计算量.
VLMo统一不同模块的结构, 共享参数, 在使用时选取相应部分.
BLIP则是参考了ALBEF和VLMo的结构设计思想.
BLIP的左侧部分完全是ALBEF, 但是借鉴了VLMo的参数共享策略(共享参数控制了计算量).
因为有VLMo的参数共享策略, 所以直接增加了生成模块.
LM中的第一层是因果自注意力, 是不共享参数的.
对于三个文本模型, 用到的Token并不一样.

Filter如何训练? 把已经训练好的BLIP的ITM拿出来, 在COCO上做一些微调, 微调后的BILP就是Filter.
为什么还要captioner? BLIP的Decoder太强了, 在COCO上微调一下, 得到Captioner. 把网上爬取的图像, 生成文本, 然后FIlter筛选, 得到新的高质量的图文对.
CoCa

是ALBEF的后续工作.
两个区别:
- 视觉端后接Attentional Pooling;
- 文本端统一用decoder.
VLMo, ALBEF等模型在一个epoch中需要forward几次, 比较费时间, 所以CoCa希望能够在一个epoch中forward一次.
为了让ITC Loss和Captioning Loss能够同时计算, 所以文本端一开始就要用Causal Self Attention.
训练数据规模达到几十亿, 所以MLM已经没有必要了.
因为方法很简单, 所以可以scaled非常好.
BeiTv3
摘要
Motivation: 做大一统的视觉语言模型.
损失函数: Mask Modeling(多个损失函数依赖调参, 互补性和互斥性难以确定, 这带来Scaling困难的问题). 将Image视为Imglish, 统一为文本.
模型: Multiway Transformer(VLMo).
数据.
方法


实验
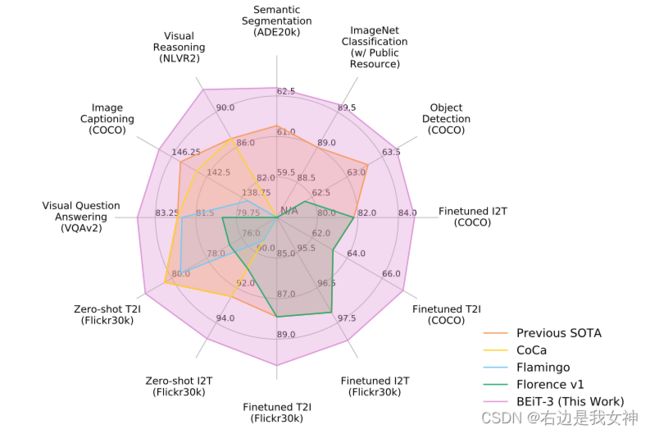
不是目标函数越多越好, 关键是能否互补.
数据也不是越多越好(BeiTv3 > CoCa).
总结
