1 函数调用流程图
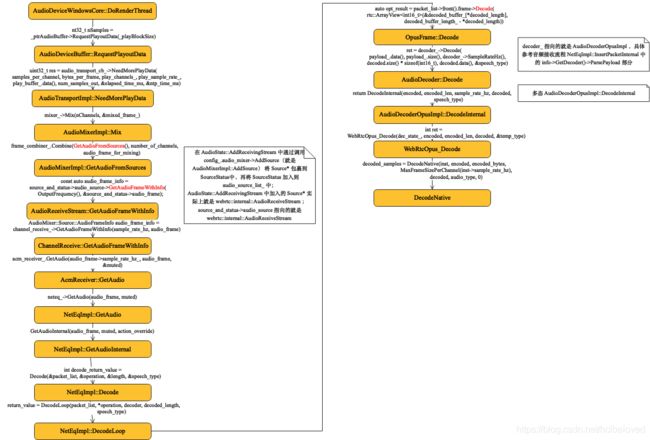
2 代码
AudioDeviceWindowsCore::DoRenderThread
===>
int32_t nSamples =
_ptrAudioBuffer->RequestPlayoutData(_playBlockSize); // AudioDeviceBuffer::RequestPlayoutData
int32_t AudioDeviceBuffer::RequestPlayoutData(size_t samples_per_channel) {
// The consumer can change the requested size on the fly and we therefore
// resize the buffer accordingly. Also takes place at the first call to this
// method.
const size_t total_samples = play_channels_ * samples_per_channel;
if (play_buffer_.size() != total_samples) {
play_buffer_.SetSize(total_samples);
RTC_LOG(LS_INFO) << "Size of playout buffer: " << play_buffer_.size();
}
size_t num_samples_out(0);
// It is currently supported to start playout without a valid audio
// transport object. Leads to warning and silence.
if (!audio_transport_cb_) {
RTC_LOG(LS_WARNING) << "Invalid audio transport";
return 0;
}
// Retrieve new 16-bit PCM audio data using the audio transport instance.
int64_t elapsed_time_ms = -1;
int64_t ntp_time_ms = -1;
const size_t bytes_per_frame = play_channels_ * sizeof(int16_t);
uint32_t res = audio_transport_cb_->NeedMorePlayData( // AudioTransportImpl::NeedMorePlayData
samples_per_channel, bytes_per_frame, play_channels_, play_sample_rate_,
play_buffer_.data(), num_samples_out, &elapsed_time_ms, &ntp_time_ms);
if (res != 0) {
RTC_LOG(LS_ERROR) << "NeedMorePlayData() failed";
}
// Derive a new level value twice per second.
int16_t max_abs = 0;
RTC_DCHECK_LT(play_stat_count_, 50);
if (++play_stat_count_ >= 50) {
// Returns the largest absolute value in a signed 16-bit vector.
max_abs =
WebRtcSpl_MaxAbsValueW16(play_buffer_.data(), play_buffer_.size());
play_stat_count_ = 0;
}
// Update playout stats which is used as base for periodic logging of the
// audio output state.
UpdatePlayStats(max_abs, num_samples_out / play_channels_);
return static_cast(num_samples_out / play_channels_);
}
int32_t AudioTransportImpl::NeedMorePlayData(const size_t nSamples,
const size_t nBytesPerSample,
const size_t nChannels,
const uint32_t samplesPerSec,
void* audioSamples,
size_t& nSamplesOut,
int64_t* elapsed_time_ms,
int64_t* ntp_time_ms) {
RTC_DCHECK_EQ(sizeof(int16_t) * nChannels, nBytesPerSample);
RTC_DCHECK_GE(nChannels, 1);
RTC_DCHECK_LE(nChannels, 2);
RTC_DCHECK_GE(
samplesPerSec,
static_cast(AudioProcessing::NativeRate::kSampleRate8kHz));
// 100 = 1 second / data duration (10 ms).
RTC_DCHECK_EQ(nSamples * 100, samplesPerSec);
RTC_DCHECK_LE(nBytesPerSample * nSamples * nChannels,
AudioFrame::kMaxDataSizeBytes);
mixer_->Mix(nChannels, &mixed_frame_); // AudioMixerImpl::Mix
*elapsed_time_ms = mixed_frame_.elapsed_time_ms_;
*ntp_time_ms = mixed_frame_.ntp_time_ms_;
const auto error = audio_processing_->ProcessReverseStream(&mixed_frame_);
RTC_DCHECK_EQ(error, AudioProcessing::kNoError);
nSamplesOut = Resample(mixed_frame_, samplesPerSec, &render_resampler_,
static_cast(audioSamples));
RTC_DCHECK_EQ(nSamplesOut, nChannels * nSamples);
return 0;
}
void AudioMixerImpl::Mix(size_t number_of_channels,
AudioFrame* audio_frame_for_mixing) {
RTC_DCHECK(number_of_channels >= 1);
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
CalculateOutputFrequency();
{
rtc::CritScope lock(&crit_);
const size_t number_of_streams = audio_source_list_.size();
frame_combiner_.Combine(GetAudioFromSources(), number_of_channels, // 注意这里 AudioMixerImpl::GetAudioFromSources
OutputFrequency(), number_of_streams,
audio_frame_for_mixing);
}
return;
}
AudioFrameList AudioMixerImpl::GetAudioFromSources() {
RTC_DCHECK_RUNS_SERIALIZED(&race_checker_);
AudioFrameList result;
std::vector audio_source_mixing_data_list;
std::vector ramp_list;
// Get audio from the audio sources and put it in the SourceFrame vector.
for (auto& source_and_status : audio_source_list_) { // 在 AudioState::AddReceivingStream 中通过调用 config_.audio_mixer->AddSource(就是AudioMixerImpl::AddSource) 将 Source* 包裹到SourceStatus中,再将 SourceStatus 加入到 audio_source_list_ 中
const auto audio_frame_info = // AudioState::AddReceivingStream 中加入的 Source* 实际上就是 webrtc::internal::AudioReceiveStream
source_and_status->audio_source->GetAudioFrameWithInfo( // source_and_status->audio_source 指向的就是 webrtc::internal::AudioReceiveStream
OutputFrequency(), &source_and_status->audio_frame); // webrtc::internal::AudioReceiveStream::GetAudioFrameWithInfo
if (audio_frame_info == Source::AudioFrameInfo::kError) {
RTC_LOG_F(LS_WARNING) << "failed to GetAudioFrameWithInfo() from source";
continue;
}
audio_source_mixing_data_list.emplace_back(
source_and_status.get(), &source_and_status->audio_frame,
audio_frame_info == Source::AudioFrameInfo::kMuted);
}
// Sort frames by sorting function.
std::sort(audio_source_mixing_data_list.begin(),
audio_source_mixing_data_list.end(), ShouldMixBefore);
int max_audio_frame_counter = kMaximumAmountOfMixedAudioSources;
// Go through list in order and put unmuted frames in result list.
for (const auto& p : audio_source_mixing_data_list) {
// Filter muted.
if (p.muted) {
p.source_status->is_mixed = false;
continue;
}
// Add frame to result vector for mixing.
bool is_mixed = false;
if (max_audio_frame_counter > 0) {
--max_audio_frame_counter;
result.push_back(p.audio_frame);
ramp_list.emplace_back(p.source_status, p.audio_frame, false, -1);
is_mixed = true;
}
p.source_status->is_mixed = is_mixed;
}
RampAndUpdateGain(ramp_list);
return result;
}
AudioMixer::Source::AudioFrameInfo AudioReceiveStream::GetAudioFrameWithInfo(
int sample_rate_hz,
AudioFrame* audio_frame) {
AudioMixer::Source::AudioFrameInfo audio_frame_info =
channel_receive_->GetAudioFrameWithInfo(sample_rate_hz, audio_frame); // ChannelReceive::GetAudioFrameWithInfo
if (audio_frame_info != AudioMixer::Source::AudioFrameInfo::kError) {
source_tracker_.OnFrameDelivered(audio_frame->packet_infos_);
}
return audio_frame_info;
}
AudioMixer::Source::AudioFrameInfo ChannelReceive::GetAudioFrameWithInfo(
int sample_rate_hz,
AudioFrame* audio_frame) {
RTC_DCHECK_RUNS_SERIALIZED(&audio_thread_race_checker_);
audio_frame->sample_rate_hz_ = sample_rate_hz;
event_log_->Log(std::make_unique(remote_ssrc_));
// Get 10ms raw PCM data from the ACM (mixer limits output frequency)
bool muted;
if (acm_receiver_.GetAudio(audio_frame->sample_rate_hz_, audio_frame, // AcmReceiver::GetAudio
&muted) == -1) {
RTC_DLOG(LS_ERROR)
<< "ChannelReceive::GetAudioFrame() PlayoutData10Ms() failed!";
// In all likelihood, the audio in this frame is garbage. We return an
// error so that the audio mixer module doesn't add it to the mix. As
// a result, it won't be played out and the actions skipped here are
// irrelevant.
return AudioMixer::Source::AudioFrameInfo::kError;
}
if (muted) {
// TODO(henrik.lundin): We should be able to do better than this. But we
// will have to go through all the cases below where the audio samples may
// be used, and handle the muted case in some way.
AudioFrameOperations::Mute(audio_frame);
}
{
// Pass the audio buffers to an optional sink callback, before applying
// scaling/panning, as that applies to the mix operation.
// External recipients of the audio (e.g. via AudioTrack), will do their
// own mixing/dynamic processing.
rtc::CritScope cs(&_callbackCritSect);
if (audio_sink_) {
AudioSinkInterface::Data data(
audio_frame->data(), audio_frame->samples_per_channel_,
audio_frame->sample_rate_hz_, audio_frame->num_channels_,
audio_frame->timestamp_);
audio_sink_->OnData(data);
}
}
float output_gain = 1.0f;
{
rtc::CritScope cs(&volume_settings_critsect_);
output_gain = _outputGain;
}
// Output volume scaling
if (output_gain < 0.99f || output_gain > 1.01f) {
// TODO(solenberg): Combine with mute state - this can cause clicks!
AudioFrameOperations::ScaleWithSat(output_gain, audio_frame);
}
// Measure audio level (0-9)
// TODO(henrik.lundin) Use the |muted| information here too.
// TODO(deadbeef): Use RmsLevel for |_outputAudioLevel| (see
// https://crbug.com/webrtc/7517).
_outputAudioLevel.ComputeLevel(*audio_frame, kAudioSampleDurationSeconds);
if (capture_start_rtp_time_stamp_ < 0 && audio_frame->timestamp_ != 0) {
// The first frame with a valid rtp timestamp.
capture_start_rtp_time_stamp_ = audio_frame->timestamp_;
}
if (capture_start_rtp_time_stamp_ >= 0) {
// audio_frame.timestamp_ should be valid from now on.
// Compute elapsed time.
int64_t unwrap_timestamp =
rtp_ts_wraparound_handler_->Unwrap(audio_frame->timestamp_);
audio_frame->elapsed_time_ms_ =
(unwrap_timestamp - capture_start_rtp_time_stamp_) /
(GetRtpTimestampRateHz() / 1000);
{
rtc::CritScope lock(&ts_stats_lock_);
// Compute ntp time.
audio_frame->ntp_time_ms_ =
ntp_estimator_.Estimate(audio_frame->timestamp_);
// |ntp_time_ms_| won't be valid until at least 2 RTCP SRs are received.
if (audio_frame->ntp_time_ms_ > 0) {
// Compute |capture_start_ntp_time_ms_| so that
// |capture_start_ntp_time_ms_| + |elapsed_time_ms_| == |ntp_time_ms_|
capture_start_ntp_time_ms_ =
audio_frame->ntp_time_ms_ - audio_frame->elapsed_time_ms_;
}
}
}
{
RTC_HISTOGRAM_COUNTS_1000("WebRTC.Audio.TargetJitterBufferDelayMs",
acm_receiver_.TargetDelayMs());
const int jitter_buffer_delay = acm_receiver_.FilteredCurrentDelayMs();
rtc::CritScope lock(&video_sync_lock_);
RTC_HISTOGRAM_COUNTS_1000("WebRTC.Audio.ReceiverDelayEstimateMs",
jitter_buffer_delay + playout_delay_ms_);
RTC_HISTOGRAM_COUNTS_1000("WebRTC.Audio.ReceiverJitterBufferDelayMs",
jitter_buffer_delay);
RTC_HISTOGRAM_COUNTS_1000("WebRTC.Audio.ReceiverDeviceDelayMs",
playout_delay_ms_);
}
return muted ? AudioMixer::Source::AudioFrameInfo::kMuted
: AudioMixer::Source::AudioFrameInfo::kNormal;
}
int AcmReceiver::GetAudio(int desired_freq_hz,
AudioFrame* audio_frame,
bool* muted) {
RTC_DCHECK(muted);
// Accessing members, take the lock.
rtc::CritScope lock(&crit_sect_);
if (neteq_->GetAudio(audio_frame, muted) != NetEq::kOK) { //NetEqImpl::GetAudio
RTC_LOG(LERROR) << "AcmReceiver::GetAudio - NetEq Failed.";
return -1;
}
const int current_sample_rate_hz = neteq_->last_output_sample_rate_hz();
// Update if resampling is required.
const bool need_resampling =
(desired_freq_hz != -1) && (current_sample_rate_hz != desired_freq_hz);
if (need_resampling && !resampled_last_output_frame_) {
// Prime the resampler with the last frame.
int16_t temp_output[AudioFrame::kMaxDataSizeSamples];
int samples_per_channel_int = resampler_.Resample10Msec(
last_audio_buffer_.get(), current_sample_rate_hz, desired_freq_hz,
audio_frame->num_channels_, AudioFrame::kMaxDataSizeSamples,
temp_output);
if (samples_per_channel_int < 0) {
RTC_LOG(LERROR) << "AcmReceiver::GetAudio - "
"Resampling last_audio_buffer_ failed.";
return -1;
}
}
// TODO(henrik.lundin) Glitches in the output may appear if the output rate
// from NetEq changes. See WebRTC issue 3923.
if (need_resampling) {
// TODO(yujo): handle this more efficiently for muted frames.
int samples_per_channel_int = resampler_.Resample10Msec(
audio_frame->data(), current_sample_rate_hz, desired_freq_hz,
audio_frame->num_channels_, AudioFrame::kMaxDataSizeSamples,
audio_frame->mutable_data());
if (samples_per_channel_int < 0) {
RTC_LOG(LERROR)
<< "AcmReceiver::GetAudio - Resampling audio_buffer_ failed.";
return -1;
}
audio_frame->samples_per_channel_ =
static_cast(samples_per_channel_int);
audio_frame->sample_rate_hz_ = desired_freq_hz;
RTC_DCHECK_EQ(
audio_frame->sample_rate_hz_,
rtc::dchecked_cast(audio_frame->samples_per_channel_ * 100));
resampled_last_output_frame_ = true;
} else {
resampled_last_output_frame_ = false;
// We might end up here ONLY if codec is changed.
}
// Store current audio in |last_audio_buffer_| for next time.
memcpy(last_audio_buffer_.get(), audio_frame->data(),
sizeof(int16_t) * audio_frame->samples_per_channel_ *
audio_frame->num_channels_);
call_stats_.DecodedByNetEq(audio_frame->speech_type_, *muted);
return 0;
}
int NetEqImpl::GetAudio(AudioFrame* audio_frame,
bool* muted,
absl::optional action_override) {
TRACE_EVENT0("webrtc", "NetEqImpl::GetAudio");
rtc::CritScope lock(&crit_sect_);
if (GetAudioInternal(audio_frame, muted, action_override) != 0) { //NetEqImpl::GetAudioInternal
return kFail;
}
RTC_DCHECK_EQ(
audio_frame->sample_rate_hz_,
rtc::dchecked_cast(audio_frame->samples_per_channel_ * 100));
RTC_DCHECK_EQ(*muted, audio_frame->muted());
SetAudioFrameActivityAndType(vad_->enabled(), LastOutputType(),
last_vad_activity_, audio_frame);
last_vad_activity_ = audio_frame->vad_activity_;
last_output_sample_rate_hz_ = audio_frame->sample_rate_hz_;
RTC_DCHECK(last_output_sample_rate_hz_ == 8000 ||
last_output_sample_rate_hz_ == 16000 ||
last_output_sample_rate_hz_ == 32000 ||
last_output_sample_rate_hz_ == 48000)
<< "Unexpected sample rate " << last_output_sample_rate_hz_;
return kOK;
}
int NetEqImpl::GetAudioInternal(AudioFrame* audio_frame,
bool* muted,
absl::optional action_override) {
PacketList packet_list;
DtmfEvent dtmf_event;
Operations operation;
bool play_dtmf;
*muted = false;
last_decoded_timestamps_.clear();
last_decoded_packet_infos_.clear();
tick_timer_->Increment();
stats_->IncreaseCounter(output_size_samples_, fs_hz_);
const auto lifetime_stats = stats_->GetLifetimeStatistics();
expand_uma_logger_.UpdateSampleCounter(lifetime_stats.concealed_samples,
fs_hz_);
speech_expand_uma_logger_.UpdateSampleCounter(
lifetime_stats.concealed_samples -
lifetime_stats.silent_concealed_samples,
fs_hz_);
// Check for muted state.
if (enable_muted_state_ && expand_->Muted() && packet_buffer_->Empty()) {
RTC_DCHECK_EQ(last_mode_, kModeExpand);
audio_frame->Reset();
RTC_DCHECK(audio_frame->muted()); // Reset() should mute the frame.
playout_timestamp_ += static_cast(output_size_samples_);
audio_frame->sample_rate_hz_ = fs_hz_;
audio_frame->samples_per_channel_ = output_size_samples_;
audio_frame->timestamp_ =
first_packet_
? 0
: timestamp_scaler_->ToExternal(playout_timestamp_) -
static_cast(audio_frame->samples_per_channel_);
audio_frame->num_channels_ = sync_buffer_->Channels();
stats_->ExpandedNoiseSamples(output_size_samples_, false);
*muted = true;
return 0;
}
int return_value = GetDecision(&operation, &packet_list, &dtmf_event,
&play_dtmf, action_override);
if (return_value != 0) {
last_mode_ = kModeError;
return return_value;
}
AudioDecoder::SpeechType speech_type;
int length = 0;
const size_t start_num_packets = packet_list.size();
int decode_return_value =
Decode(&packet_list, &operation, &length, &speech_type); //NetEqImpl::Decode
assert(vad_.get());
bool sid_frame_available = (operation == kRfc3389Cng && !packet_list.empty());
vad_->Update(decoded_buffer_.get(), static_cast(length), speech_type,
sid_frame_available, fs_hz_);
// This is the criterion that we did decode some data through the speech
// decoder, and the operation resulted in comfort noise.
const bool codec_internal_sid_frame =
(speech_type == AudioDecoder::kComfortNoise &&
start_num_packets > packet_list.size());
if (sid_frame_available || codec_internal_sid_frame) {
// Start a new stopwatch since we are decoding a new CNG packet.
generated_noise_stopwatch_ = tick_timer_->GetNewStopwatch();
}
algorithm_buffer_->Clear();
switch (operation) {
case kNormal: {
DoNormal(decoded_buffer_.get(), length, speech_type, play_dtmf);
if (length > 0) {
stats_->DecodedOutputPlayed();
}
break;
}
case kMerge: {
DoMerge(decoded_buffer_.get(), length, speech_type, play_dtmf);
break;
}
case kExpand: {
RTC_DCHECK_EQ(return_value, 0);
if (!current_rtp_payload_type_ || !DoCodecPlc()) {
return_value = DoExpand(play_dtmf);
}
RTC_DCHECK_GE(sync_buffer_->FutureLength() - expand_->overlap_length(),
output_size_samples_);
break;
}
case kAccelerate:
case kFastAccelerate: {
const bool fast_accelerate =
enable_fast_accelerate_ && (operation == kFastAccelerate);
return_value = DoAccelerate(decoded_buffer_.get(), length, speech_type,
play_dtmf, fast_accelerate);
break;
}
case kPreemptiveExpand: {
return_value = DoPreemptiveExpand(decoded_buffer_.get(), length,
speech_type, play_dtmf);
break;
}
case kRfc3389Cng:
case kRfc3389CngNoPacket: {
return_value = DoRfc3389Cng(&packet_list, play_dtmf);
break;
}
case kCodecInternalCng: {
// This handles the case when there is no transmission and the decoder
// should produce internal comfort noise.
// TODO(hlundin): Write test for codec-internal CNG.
DoCodecInternalCng(decoded_buffer_.get(), length);
break;
}
case kDtmf: {
// TODO(hlundin): Write test for this.
return_value = DoDtmf(dtmf_event, &play_dtmf);
break;
}
case kUndefined: {
RTC_LOG(LS_ERROR) << "Invalid operation kUndefined.";
assert(false); // This should not happen.
last_mode_ = kModeError;
return kInvalidOperation;
}
} // End of switch.
last_operation_ = operation;
if (return_value < 0) {
return return_value;
}
if (last_mode_ != kModeRfc3389Cng) {
comfort_noise_->Reset();
}
// We treat it as if all packets referenced to by |last_decoded_packet_infos_|
// were mashed together when creating the samples in |algorithm_buffer_|.
RtpPacketInfos packet_infos(last_decoded_packet_infos_);
// Copy samples from |algorithm_buffer_| to |sync_buffer_|.
//
// TODO(bugs.webrtc.org/10757):
// We would in the future also like to pass |packet_infos| so that we can do
// sample-perfect tracking of that information across |sync_buffer_|.
sync_buffer_->PushBack(*algorithm_buffer_);
// Extract data from |sync_buffer_| to |output|.
size_t num_output_samples_per_channel = output_size_samples_;
size_t num_output_samples = output_size_samples_ * sync_buffer_->Channels();
if (num_output_samples > AudioFrame::kMaxDataSizeSamples) {
RTC_LOG(LS_WARNING) << "Output array is too short. "
<< AudioFrame::kMaxDataSizeSamples << " < "
<< output_size_samples_ << " * "
<< sync_buffer_->Channels();
num_output_samples = AudioFrame::kMaxDataSizeSamples;
num_output_samples_per_channel =
AudioFrame::kMaxDataSizeSamples / sync_buffer_->Channels();
}
sync_buffer_->GetNextAudioInterleaved(num_output_samples_per_channel,
audio_frame);
audio_frame->sample_rate_hz_ = fs_hz_;
// TODO(bugs.webrtc.org/10757):
// We don't have the ability to properly track individual packets once their
// audio samples have entered |sync_buffer_|. So for now, treat it as if
// |packet_infos| from packets decoded by the current |GetAudioInternal()|
// call were all consumed assembling the current audio frame and the current
// audio frame only.
audio_frame->packet_infos_ = std::move(packet_infos);
if (sync_buffer_->FutureLength() < expand_->overlap_length()) {
// The sync buffer should always contain |overlap_length| samples, but now
// too many samples have been extracted. Reinstall the |overlap_length|
// lookahead by moving the index.
const size_t missing_lookahead_samples =
expand_->overlap_length() - sync_buffer_->FutureLength();
RTC_DCHECK_GE(sync_buffer_->next_index(), missing_lookahead_samples);
sync_buffer_->set_next_index(sync_buffer_->next_index() -
missing_lookahead_samples);
}
if (audio_frame->samples_per_channel_ != output_size_samples_) {
RTC_LOG(LS_ERROR) << "audio_frame->samples_per_channel_ ("
<< audio_frame->samples_per_channel_
<< ") != output_size_samples_ (" << output_size_samples_
<< ")";
// TODO(minyue): treatment of under-run, filling zeros
audio_frame->Mute();
return kSampleUnderrun;
}
// Should always have overlap samples left in the |sync_buffer_|.
RTC_DCHECK_GE(sync_buffer_->FutureLength(), expand_->overlap_length());
// TODO(yujo): For muted frames, this can be a copy rather than an addition.
if (play_dtmf) {
return_value = DtmfOverdub(dtmf_event, sync_buffer_->Channels(),
audio_frame->mutable_data());
}
// Update the background noise parameters if last operation wrote data
// straight from the decoder to the |sync_buffer_|. That is, none of the
// operations that modify the signal can be followed by a parameter update.
if ((last_mode_ == kModeNormal) || (last_mode_ == kModeAccelerateFail) ||
(last_mode_ == kModePreemptiveExpandFail) ||
(last_mode_ == kModeRfc3389Cng) ||
(last_mode_ == kModeCodecInternalCng)) {
background_noise_->Update(*sync_buffer_, *vad_.get());
}
if (operation == kDtmf) {
// DTMF data was written the end of |sync_buffer_|.
// Update index to end of DTMF data in |sync_buffer_|.
sync_buffer_->set_dtmf_index(sync_buffer_->Size());
}
if (last_mode_ != kModeExpand && last_mode_ != kModeCodecPlc) {
// If last operation was not expand, calculate the |playout_timestamp_| from
// the |sync_buffer_|. However, do not update the |playout_timestamp_| if it
// would be moved "backwards".
uint32_t temp_timestamp =
sync_buffer_->end_timestamp() -
static_cast(sync_buffer_->FutureLength());
if (static_cast(temp_timestamp - playout_timestamp_) > 0) {
playout_timestamp_ = temp_timestamp;
}
} else {
// Use dead reckoning to estimate the |playout_timestamp_|.
playout_timestamp_ += static_cast(output_size_samples_);
}
// Set the timestamp in the audio frame to zero before the first packet has
// been inserted. Otherwise, subtract the frame size in samples to get the
// timestamp of the first sample in the frame (playout_timestamp_ is the
// last + 1).
audio_frame->timestamp_ =
first_packet_
? 0
: timestamp_scaler_->ToExternal(playout_timestamp_) -
static_cast(audio_frame->samples_per_channel_);
if (!(last_mode_ == kModeRfc3389Cng || last_mode_ == kModeCodecInternalCng ||
last_mode_ == kModeExpand || last_mode_ == kModeCodecPlc)) {
generated_noise_stopwatch_.reset();
}
if (decode_return_value)
return decode_return_value;
return return_value;
}
int NetEqImpl::Decode(PacketList* packet_list,
Operations* operation,
int* decoded_length,
AudioDecoder::SpeechType* speech_type) {
*speech_type = AudioDecoder::kSpeech;
// When packet_list is empty, we may be in kCodecInternalCng mode, and for
// that we use current active decoder.
AudioDecoder* decoder = decoder_database_->GetActiveDecoder(); //以 opus 为例, decoder 指向的是 webrtc::AudioDecoderOpusImpl
if (!packet_list->empty()) {
const Packet& packet = packet_list->front();
uint8_t payload_type = packet.payload_type;
if (!decoder_database_->IsComfortNoise(payload_type)) {
decoder = decoder_database_->GetDecoder(payload_type);
assert(decoder);
if (!decoder) {
RTC_LOG(LS_WARNING)
<< "Unknown payload type " << static_cast(payload_type);
packet_list->clear();
return kDecoderNotFound;
}
bool decoder_changed;
decoder_database_->SetActiveDecoder(payload_type, &decoder_changed);
if (decoder_changed) {
// We have a new decoder. Re-init some values.
const DecoderDatabase::DecoderInfo* decoder_info =
decoder_database_->GetDecoderInfo(payload_type);
assert(decoder_info);
if (!decoder_info) {
RTC_LOG(LS_WARNING)
<< "Unknown payload type " << static_cast(payload_type);
packet_list->clear();
return kDecoderNotFound;
}
// If sampling rate or number of channels has changed, we need to make
// a reset.
if (decoder_info->SampleRateHz() != fs_hz_ ||
decoder->Channels() != algorithm_buffer_->Channels()) {
// TODO(tlegrand): Add unittest to cover this event.
SetSampleRateAndChannels(decoder_info->SampleRateHz(),
decoder->Channels());
}
sync_buffer_->set_end_timestamp(timestamp_);
playout_timestamp_ = timestamp_;
}
}
}
if (reset_decoder_) {
// TODO(hlundin): Write test for this.
if (decoder)
decoder->Reset();
// Reset comfort noise decoder.
ComfortNoiseDecoder* cng_decoder = decoder_database_->GetActiveCngDecoder();
if (cng_decoder)
cng_decoder->Reset();
reset_decoder_ = false;
}
*decoded_length = 0;
// Update codec-internal PLC state.
if ((*operation == kMerge) && decoder && decoder->HasDecodePlc()) {
decoder->DecodePlc(1, &decoded_buffer_[*decoded_length]);
}
int return_value;
if (*operation == kCodecInternalCng) {
RTC_DCHECK(packet_list->empty());
return_value = DecodeCng(decoder, decoded_length, speech_type);
} else {
return_value = DecodeLoop(packet_list, *operation, decoder, decoded_length, // 注意这里
speech_type);
}
if (*decoded_length < 0) {
// Error returned from the decoder.
*decoded_length = 0;
sync_buffer_->IncreaseEndTimestamp(
static_cast(decoder_frame_length_));
int error_code = 0;
if (decoder)
error_code = decoder->ErrorCode();
if (error_code != 0) {
// Got some error code from the decoder.
return_value = kDecoderErrorCode;
RTC_LOG(LS_WARNING) << "Decoder returned error code: " << error_code;
} else {
// Decoder does not implement error codes. Return generic error.
return_value = kOtherDecoderError;
RTC_LOG(LS_WARNING) << "Decoder error (no error code)";
}
*operation = kExpand; // Do expansion to get data instead.
}
if (*speech_type != AudioDecoder::kComfortNoise) {
// Don't increment timestamp if codec returned CNG speech type
// since in this case, the we will increment the CNGplayedTS counter.
// Increase with number of samples per channel.
assert(*decoded_length == 0 ||
(decoder && decoder->Channels() == sync_buffer_->Channels()));
sync_buffer_->IncreaseEndTimestamp(
*decoded_length / static_cast(sync_buffer_->Channels()));
}
return return_value;
}
AudioDecoder* DecoderDatabase::GetActiveDecoder() const {
if (active_decoder_type_ < 0) {
// No active decoder.
return NULL;
}
return GetDecoder(active_decoder_type_); // 注意这里
}
AudioDecoder* DecoderDatabase::GetDecoder(uint8_t rtp_payload_type) const {
const DecoderInfo* info = GetDecoderInfo(rtp_payload_type);
return info ? info->GetDecoder() : nullptr;
}
const DecoderDatabase::DecoderInfo* DecoderDatabase::GetDecoderInfo(
uint8_t rtp_payload_type) const {
DecoderMap::const_iterator it = decoders_.find(rtp_payload_type);
if (it == decoders_.end()) {
// Decoder not found.
return NULL;
}
return &it->second;
}
AudioDecoder* DecoderDatabase::DecoderInfo::GetDecoder() const {
if (subtype_ != Subtype::kNormal) {
// These are handled internally, so they have no AudioDecoder objects.
return nullptr;
}
if (!decoder_) {
// TODO(ossu): Keep a check here for now, since a number of tests create
// DecoderInfos without factories.
RTC_DCHECK(factory_);
decoder_ = factory_->MakeAudioDecoder(audio_format_, codec_pair_id_); // factory_ 就是 CreateBuiltinAudioDecoderFactory() 的返回值
}
RTC_DCHECK(decoder_) << "Failed to create: " << rtc::ToString(audio_format_);
return decoder_.get();
}
rtc::scoped_refptr CreateBuiltinAudioDecoderFactory() {
return CreateAudioDecoderFactory<
#if WEBRTC_USE_BUILTIN_OPUS
AudioDecoderOpus, NotAdvertised,
#endif
AudioDecoderIsac, AudioDecoderG722,
#if WEBRTC_USE_BUILTIN_ILBC
AudioDecoderIlbc,
#endif
AudioDecoderG711, NotAdvertised>();
}
template
rtc::scoped_refptr CreateAudioDecoderFactory() {
// There's no technical reason we couldn't allow zero template parameters,
// but such a factory couldn't create any decoders, and callers can do this
// by mistake by simply forgetting the <> altogether. So we forbid it in
// order to prevent caller foot-shooting.
static_assert(sizeof...(Ts) >= 1,
"Caller must give at least one template parameter");
return rtc::scoped_refptr(
new rtc::RefCountedObject<
audio_decoder_factory_template_impl::AudioDecoderFactoryT>());
}
template
class AudioDecoderFactoryT : public AudioDecoderFactory {
public:
std::vector GetSupportedDecoders() override {
std::vector specs;
Helper::AppendSupportedDecoders(&specs);
return specs;
}
bool IsSupportedDecoder(const SdpAudioFormat& format) override {
return Helper::IsSupportedDecoder(format);
}
std::unique_ptr MakeAudioDecoder(
const SdpAudioFormat& format,
absl::optional codec_pair_id) override {
return Helper::MakeAudioDecoder(format, codec_pair_id);
}
};
std::unique_ptr AudioDecoderFactoryT::MakeAudioDecoder(
const SdpAudioFormat& format,
absl::optional codec_pair_id) override {
return Helper::MakeAudioDecoder(format, codec_pair_id);
}
template
struct Helper {
static void AppendSupportedDecoders(std::vector* specs) {
T::AppendSupportedDecoders(specs);
Helper::AppendSupportedDecoders(specs);
}
static bool IsSupportedDecoder(const SdpAudioFormat& format) {
auto opt_config = T::SdpToConfig(format);
static_assert(std::is_same>::value,
"T::SdpToConfig() must return a value of type "
"absl::optional");
return opt_config ? true : Helper::IsSupportedDecoder(format);
}
static std::unique_ptr MakeAudioDecoder(
const SdpAudioFormat& format,
absl::optional codec_pair_id) {
auto opt_config = T::SdpToConfig(format);
return opt_config ? T::MakeAudioDecoder(*opt_config, codec_pair_id) // 以 opus 为例
: Helper::MakeAudioDecoder(format, codec_pair_id);
}
};
std::unique_ptr AudioDecoderOpus::MakeAudioDecoder(
Config config,
absl::optional /*codec_pair_id*/) {
RTC_DCHECK(config.IsOk());
return std::make_unique(config.num_channels,
config.sample_rate_hz); // 注意这里
}
int NetEqImpl::DecodeLoop(PacketList* packet_list,
const Operations& operation,
AudioDecoder* decoder,// 以 opus 为例, decoder 指向的是 webrtc::AudioDecoderOpusImpl
int* decoded_length,
AudioDecoder::SpeechType* speech_type) {
RTC_DCHECK(last_decoded_timestamps_.empty());
RTC_DCHECK(last_decoded_packet_infos_.empty());
// Do decoding.
while (!packet_list->empty() && !decoder_database_->IsComfortNoise(
packet_list->front().payload_type)) {
assert(decoder); // At this point, we must have a decoder object.
// The number of channels in the |sync_buffer_| should be the same as the
// number decoder channels.
assert(sync_buffer_->Channels() == decoder->Channels());
assert(decoded_buffer_length_ >= kMaxFrameSize * decoder->Channels());
assert(operation == kNormal || operation == kAccelerate ||
operation == kFastAccelerate || operation == kMerge ||
operation == kPreemptiveExpand);
auto opt_result = packet_list->front().frame->Decode( //OpusFrame::Decode
rtc::ArrayView(&decoded_buffer_[*decoded_length],
decoded_buffer_length_ - *decoded_length));
last_decoded_timestamps_.push_back(packet_list->front().timestamp);
last_decoded_packet_infos_.push_back(
std::move(packet_list->front().packet_info));
packet_list->pop_front();
if (opt_result) {
const auto& result = *opt_result;
*speech_type = result.speech_type;
if (result.num_decoded_samples > 0) {
*decoded_length += rtc::dchecked_cast(result.num_decoded_samples);
// Update |decoder_frame_length_| with number of samples per channel.
decoder_frame_length_ =
result.num_decoded_samples / decoder->Channels();
}
} else {
// Error.
// TODO(ossu): What to put here?
RTC_LOG(LS_WARNING) << "Decode error";
*decoded_length = -1;
last_decoded_packet_infos_.clear();
packet_list->clear();
break;
}
if (*decoded_length > rtc::dchecked_cast(decoded_buffer_length_)) {
// Guard against overflow.
RTC_LOG(LS_WARNING) << "Decoded too much.";
packet_list->clear();
return kDecodedTooMuch;
}
} // End of decode loop.
// If the list is not empty at this point, either a decoding error terminated
// the while-loop, or list must hold exactly one CNG packet.
assert(packet_list->empty() || *decoded_length < 0 ||
(packet_list->size() == 1 && decoder_database_->IsComfortNoise(
packet_list->front().payload_type)));
return 0;
}
// class OpusFrame : public AudioDecoder::EncodedAudioFrame
absl::optional OpusFrame::Decode(
rtc::ArrayView decoded) const override {
AudioDecoder::SpeechType speech_type = AudioDecoder::kSpeech;
int ret;
if (is_primary_payload_) {
ret = decoder_->Decode( // decoder_ 指向的就是 AudioDecoderOpusImpl ,具体参考音频接收流程 NetEqImpl::InsertPacketInternal 中的 info->GetDecoder()->ParsePayload 部分
payload_.data(), payload_.size(), decoder_->SampleRateHz(),
decoded.size() * sizeof(int16_t), decoded.data(), &speech_type);
} else {
ret = decoder_->DecodeRedundant(
payload_.data(), payload_.size(), decoder_->SampleRateHz(),
decoded.size() * sizeof(int16_t), decoded.data(), &speech_type);
}
if (ret < 0)
return absl::nullopt;
return DecodeResult{static_cast(ret), speech_type};
}
int AudioDecoder::Decode(const uint8_t* encoded,
size_t encoded_len,
int sample_rate_hz,
size_t max_decoded_bytes,
int16_t* decoded,
SpeechType* speech_type) {
TRACE_EVENT0("webrtc", "AudioDecoder::Decode");
rtc::MsanCheckInitialized(rtc::MakeArrayView(encoded, encoded_len));
int duration = PacketDuration(encoded, encoded_len);
if (duration >= 0 &&
duration * Channels() * sizeof(int16_t) > max_decoded_bytes) {
return -1;
}
return DecodeInternal(encoded, encoded_len, sample_rate_hz, decoded, // 多态 AudioDecoderOpusImpl::DecodeInternal
speech_type);
}
int AudioDecoderOpusImpl::DecodeInternal(const uint8_t* encoded,
size_t encoded_len,
int sample_rate_hz,
int16_t* decoded,
SpeechType* speech_type) {
RTC_DCHECK_EQ(sample_rate_hz, sample_rate_hz_);
int16_t temp_type = 1; // Default is speech.
int ret =
WebRtcOpus_Decode(dec_state_, encoded, encoded_len, decoded, &temp_type); // 注意这里
if (ret > 0)
ret *= static_cast(channels_); // Return total number of samples.
*speech_type = ConvertSpeechType(temp_type);
return ret;
}
int WebRtcOpus_Decode(OpusDecInst* inst, const uint8_t* encoded,
size_t encoded_bytes, int16_t* decoded,
int16_t* audio_type) {
int decoded_samples;
if (encoded_bytes == 0) {
*audio_type = DetermineAudioType(inst, encoded_bytes);
decoded_samples = WebRtcOpus_DecodePlc(inst, decoded, 1);
} else {
decoded_samples = DecodeNative(inst, encoded, encoded_bytes, // 注意这里
MaxFrameSizePerChannel(inst->sample_rate_hz),
decoded, audio_type, 0);
}
if (decoded_samples < 0) {
return -1;
}
/* Update decoded sample memory, to be used by the PLC in case of losses. */
inst->prev_decoded_samples = decoded_samples;
return decoded_samples;
}
static int DecodeNative(OpusDecInst* inst, const uint8_t* encoded,
size_t encoded_bytes, int frame_size,
int16_t* decoded, int16_t* audio_type, int decode_fec) {
int res = -1;
if (inst->decoder) {
res = opus_decode(inst->decoder, encoded, (opus_int32)encoded_bytes, // 注意这里
(opus_int16*)decoded, frame_size, decode_fec);
} else {
res = opus_multistream_decode(
inst->multistream_decoder, encoded, (opus_int32)encoded_bytes,
(opus_int16*)decoded, frame_size, decode_fec);
}
if (res <= 0)
return -1;
*audio_type = DetermineAudioType(inst, encoded_bytes);
return res;
}
int opus_decode(OpusDecoder *st, const unsigned char *data,
opus_int32 len, opus_int16 *pcm, int frame_size, int decode_fec)
{
VARDECL(float, out);
int ret, i;
int nb_samples;
ALLOC_STACK;
if(frame_size<=0)
{
RESTORE_STACK;
return OPUS_BAD_ARG;
}
if (data != NULL && len > 0 && !decode_fec)
{
nb_samples = opus_decoder_get_nb_samples(st, data, len);
if (nb_samples>0)
frame_size = IMIN(frame_size, nb_samples);
else
return OPUS_INVALID_PACKET;
}
ALLOC(out, frame_size*st->channels, float);
ret = opus_decode_native(st, data, len, out, frame_size, decode_fec, 0, NULL, 1);// 注意这里
if (ret > 0)
{
for (i=0;ichannels;i++)
pcm[i] = FLOAT2INT16(out[i]);
}
RESTORE_STACK;
return ret;
}
int opus_decode_native(OpusDecoder *st, const unsigned char *data,
opus_int32 len, opus_val16 *pcm, int frame_size, int decode_fec,
int self_delimited, opus_int32 *packet_offset, int soft_clip)
{
int i, nb_samples;
int count, offset;
unsigned char toc;
int packet_frame_size, packet_bandwidth, packet_mode, packet_stream_channels;
/* 48 x 2.5 ms = 120 ms */
opus_int16 size[48];
if (decode_fec<0 || decode_fec>1)
return OPUS_BAD_ARG;
/* For FEC/PLC, frame_size has to be to have a multiple of 2.5 ms */
if ((decode_fec || len==0 || data==NULL) && frame_size%(st->Fs/400)!=0)
return OPUS_BAD_ARG;
if (len==0 || data==NULL)
{
int pcm_count=0;
do {
int ret;
ret = opus_decode_frame(st, NULL, 0, pcm+pcm_count*st->channels, frame_size-pcm_count, 0);
if (ret<0)
return ret;
pcm_count += ret;
} while (pcm_count < frame_size);
celt_assert(pcm_count == frame_size);
if (OPUS_CHECK_ARRAY(pcm, pcm_count*st->channels))
OPUS_PRINT_INT(pcm_count);
st->last_packet_duration = pcm_count;
return pcm_count;
} else if (len<0)
return OPUS_BAD_ARG;
packet_mode = opus_packet_get_mode(data);
packet_bandwidth = opus_packet_get_bandwidth(data);
packet_frame_size = opus_packet_get_samples_per_frame(data, st->Fs);
packet_stream_channels = opus_packet_get_nb_channels(data);
count = opus_packet_parse_impl(data, len, self_delimited, &toc, NULL,
size, &offset, packet_offset);
if (count<0)
return count;
data += offset;
if (decode_fec)
{
int duration_copy;
int ret;
/* If no FEC can be present, run the PLC (recursive call) */
if (frame_size < packet_frame_size || packet_mode == MODE_CELT_ONLY || st->mode == MODE_CELT_ONLY)
return opus_decode_native(st, NULL, 0, pcm, frame_size, 0, 0, NULL, soft_clip);
/* Otherwise, run the PLC on everything except the size for which we might have FEC */
duration_copy = st->last_packet_duration;
if (frame_size-packet_frame_size!=0)
{
ret = opus_decode_native(st, NULL, 0, pcm, frame_size-packet_frame_size, 0, 0, NULL, soft_clip);
if (ret<0)
{
st->last_packet_duration = duration_copy;
return ret;
}
celt_assert(ret==frame_size-packet_frame_size);
}
/* Complete with FEC */
st->mode = packet_mode;
st->bandwidth = packet_bandwidth;
st->frame_size = packet_frame_size;
st->stream_channels = packet_stream_channels;
ret = opus_decode_frame(st, data, size[0], pcm+st->channels*(frame_size-packet_frame_size),
packet_frame_size, 1);
if (ret<0)
return ret;
else {
if (OPUS_CHECK_ARRAY(pcm, frame_size*st->channels))
OPUS_PRINT_INT(frame_size);
st->last_packet_duration = frame_size;
return frame_size;
}
}
if (count*packet_frame_size > frame_size)
return OPUS_BUFFER_TOO_SMALL;
/* Update the state as the last step to avoid updating it on an invalid packet */
st->mode = packet_mode;
st->bandwidth = packet_bandwidth;
st->frame_size = packet_frame_size;
st->stream_channels = packet_stream_channels;
nb_samples=0;
for (i=0;ichannels, frame_size-nb_samples, 0);
if (ret<0)
return ret;
celt_assert(ret==packet_frame_size);
data += size[i];
nb_samples += ret;
}
st->last_packet_duration = nb_samples;
if (OPUS_CHECK_ARRAY(pcm, nb_samples*st->channels))
OPUS_PRINT_INT(nb_samples);
#ifndef FIXED_POINT
if (soft_clip)
opus_pcm_soft_clip(pcm, nb_samples, st->channels, st->softclip_mem);
else
st->softclip_mem[0]=st->softclip_mem[1]=0;
#endif
return nb_samples;
}