什么是OLAP
一、什么是OLAP
OLAP(On-line Analytical Processing,联机分析处理)是在基于数据仓库多维模型的基础上实现的面向分析的各类操作的集合。可以比较下其与传统的OLTP(On-line Transaction Processing,联机事务处理)的区别来看一下它的特点: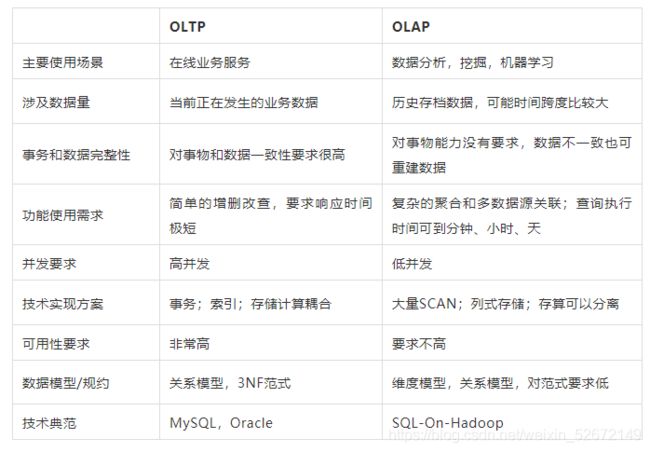 OLAP的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离了这两点,OLAP将不复存在,也就没有优势可言。
OLAP的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离了这两点,OLAP将不复存在,也就没有优势可言。
二、OLAP引擎的常见操作
下面所述几种OLAP操作,是针对Kimball的星型模型(Star Schema)和雪花模型(Snowflake Schema)来说的。在Kimball模型中,定义了事实和维度。
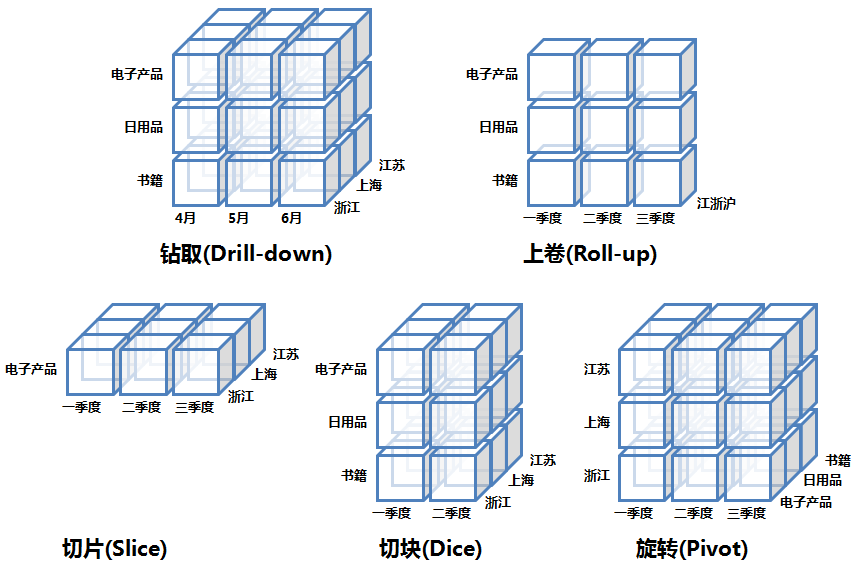
- 上卷(Roll Up)/聚合:选定某些维度,根据这些维度来聚合事实,如果用SQL来表达就是select dim_a, aggs_func(fact_b) from fact_table group by dim_a.
- 下钻(Drill Down):上卷和下钻是相反的操作。它是选定某些维度,将这些维度拆解出小的维度(如年拆解为月,省份拆解为城市),之后聚合事实。
- 切片(Slicing、Dicing):选定某些维度,并根据特定值过滤这些维度的值,将原来的大Cube切成小cube。如dim_a in (‘CN’, ‘USA’)
- 旋转(Pivot/Rotate):维度位置的互换。
下图举了一个具体的例子:
三、OLAP分类
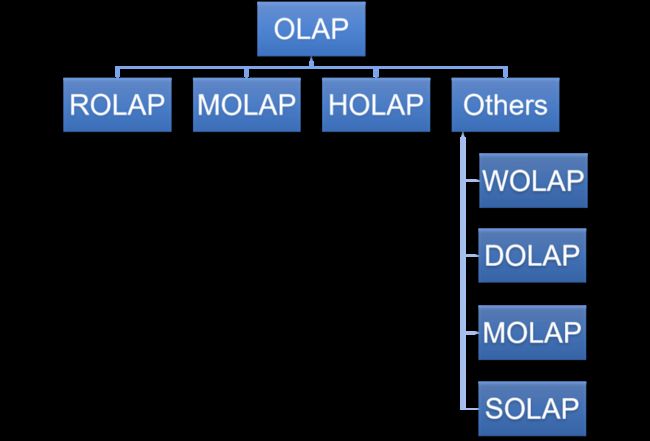
OLAP 是一种让用户可以用从不同视角方便快捷的分析数据的计算方法。主流的 OLAP 可以分为3类:多维OLAP ( Multi-dimensional OLAP )、关系型OLAP ( Relational OLAP ) 和混合OLAP ( Hybrid OLAP ) 三大类。
1.多维OLAP ( Multi-dimensional OLAP )
MOLAP基于直接支持多维数据和操作的本机逻辑模型。数据物理上存储在多维数组中, 并且使用定位技术来访问它们。
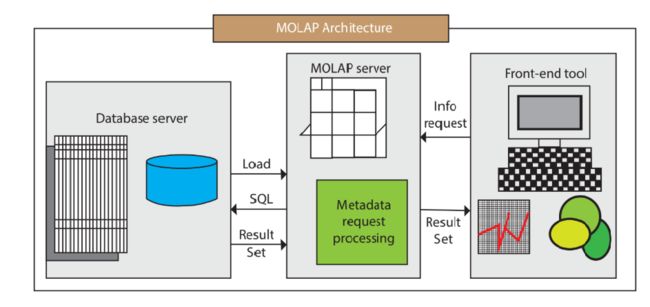
MOLAP架构包含了数据库服务器、MOLAP服务器和前端工具三个组件。
MOLAP的典型代表是:Druid 和 Kylin。MOLAP一般会根据用户定义的数据维度、度量(也可以叫指标)在数据写入时生成预聚合数据;Query查询到来时,实际上查询的是预聚合的数据而不是原始明细数据,在查询模式相对固定的场景中,这种优化提速很明显。
MOLAP 的优点和缺点都来自于其数据预处理 ( pre-processing ) 环节。数据预处理,将原始数据按照指定的计算规则预先做聚合计算,这样避免了查询过程中出现大量的即使计算,提升了查询性能。
但是这样的预聚合处理,需要预先定义维度,会限制后期数据查询的灵活性;如果查询工作涉及新的指标,需要重新增加预处理流程,损失了灵活度,存储成本也很高;同时,这种方式不支持明细数据的查询,仅适用于聚合型查询(如:sum,avg,count)。
因此,MOLAP 适用于查询场景相对固定并且对查询性能要求非常高的场景。如广告主经常使用的广告投放报表分析。
2.关系型OLAP ( Relational OLAP )
关系OLAP(ROLAP)是中间服务器, 它们位于关系后端服务器和用户前端工具之间,其使用关系或扩展关系DBMS来保存和处理仓库数据, 并使用OLAP中间件来提供丢失的数据。
ROLAP的体系结构如下图,其中包含了数据库服务器、ROLAP服务器和前端工具。
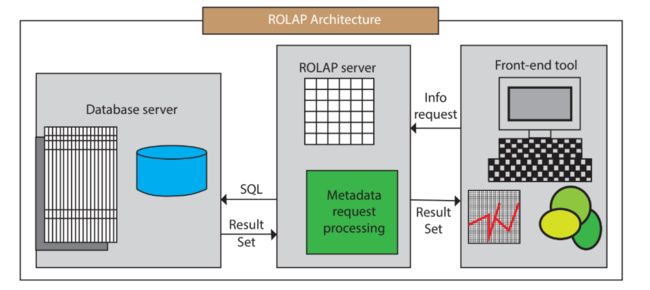
ROLAP的典型代表是:Presto,Impala,GreenPlum,Clickhouse,Elasticsearch,Hive,Spark SQL,Flink SQL。
ROLAP的优势在于以下两个方面:
第一,在数据写入时,ROLAP并未使用像MOLAP那样的预聚合技术。ROLAP收到Query请求时,会先解析Query,生成执行计划,扫描数据,执行关系型算子,在原始数据上做过滤(Where)、聚合(Sum, Avg, Count)、关联(Join),分组(Group By)、排序(Order By)等,最后将结算结果返回给用户,整个过程都是即时计算,没有预先聚合好的数据可供优化查询速度,拼的都是资源和算力的大小。
第二,ROLAP 不需要进行数据预处理 ( pre-processing ),因此查询灵活,可扩展性好。这类引擎使用 MPP 架构 ( 与Hadoop相似的大型并行处理架构,可以通过扩大并发来增加计算资源 ),可以高效处理大量数据。
但是ROLAP也存在着劣势,那就是当数据量较大或 query 较为复杂时,查询性能也无法像 MOLAP 那样稳定。所有计算都是即时触发 ( 没有预处理 ),因此会耗费更多的计算资源,带来潜在的重复计算。
因此,ROLAP 适用于对查询模式不固定、查询灵活性要求高的场景。如数据分析师常用的数据分析类产品,他们往往会对数据做各种预先不能确定的分析,所以需要更高的查询灵活性。
3.混合OLAP ( Hybrid OLAP )
混合 OLAP,是 MOLAP 和 ROLAP 的一种融合。当查询聚合性数据的时候,使用MOLAP 技术;当查询明细数据时,使用 ROLAP 技术。在给定使用场景的前提下,以达到查询性能的最优化。混合OLAP的技术体系架构如下图:
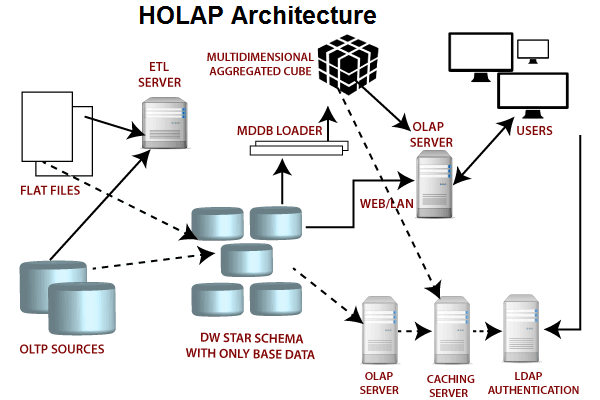
混合 OLAP的优势在于其很好的结合了MOLAP和ROLAP的优势之处,并且提供了所有聚合级别的快速访问。同时因为它仅将聚合信息存储在OLAP服务器上, 而详细记录保留在关系数据库中。因此, 不会保留详细记录的重复副本,平衡了磁盘空间需求。
混合 OLAP的劣势恰恰在于其由于集成了MOLAP和ROLAP,因此需要同时支持MOLAP和ROLAP,并且本身的体系结构也非常复杂。
4.Others
除此之外,还包含一些其他分类,包括启用Web的OLAP(WOLAP),桌面OLAP(DOLAP),移动OLAP(MOLAP)和空间OLAP(SOLAP)。但总体上不太流行,故此不再进行介绍。
四、开源OLAP引擎对比
针对于目前大数据业内非常流行的数个开源OLAP引擎:Hive、SparkSQL、FlinkSQL、Clickhouse、Elasticsearch、Druid、Kylin、Presto、Impala分别挑选了一些场景进行了对比,可以说目前没有一个引擎能在数据量,灵活程度和性能上做到完美,用户需要根据自己的需求进行选型。
1.并发能力与查询延迟对比
看到这里可能有人会提出疑问:Hive,SparkSQL,FlinkSQL这些它们要么查询速度慢,要么QPS上不去,怎么能算是OLAP引擎呢?其实OLAP的定义中并没有关于查询执行速度和QPS的限定。进一步来说,这里引出了衡量OLAP特定业务场景的两个重要的指标:
- 查询速度:Search Latency
- 查询并发能力:QPS
如果根据不同的查询场景、再按照查询速度与查询并发能力这两个指标来划分以上所列的OLAP引擎,这些OLAP引擎的能力划分如下:
场景一:简单查询
简单查询指的是点查、简单聚合查询或者数据查询能够命中索引或物化视图(物化视图指的是物化的查询中间结果,如预聚合数据)。这样的查询经常出现在【在线数据服务】的企业应用中,如阿里生意参谋、腾讯的广点通、京东的广告业务等,它们共同的特点是对外服务、面向B端商业客户(通常是几十万的级别);并发查询量(QPS)大;对响应时间要求高,一般是ms级别(可以想象一下,如果广告主查询页面投放数据,如果10s还没有结果,很伤害体验);查询模式相对固定且简单。从下图可知,这种场景最合适的是Elasticsearch、Druid、Kylin。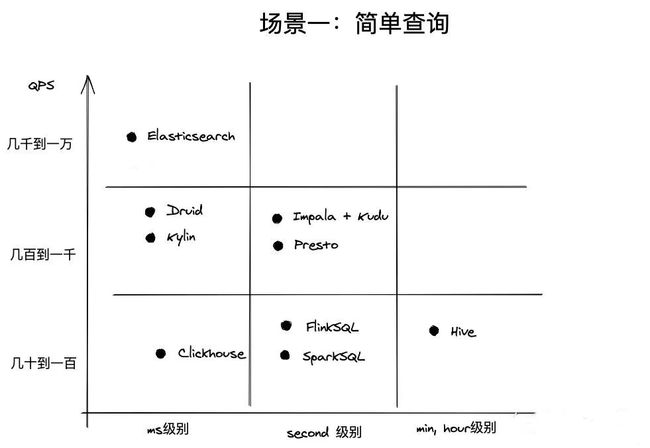
场景二:复杂查询
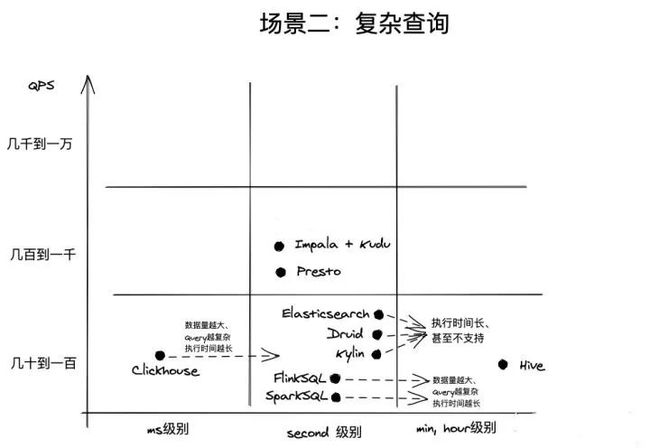
复杂查询指的是复杂聚合查询、大批量数据SCAN、复杂的查询(如JOIN)。在ad-hoc场景中,经常会有这样的查询,往往用户不能预先知道要查询什么,更多的是探索式的。这里也根据QPS和查询耗时分几种情况,如下图所示,根据业务的需求来选择对应的引擎即可。有一点要提的是FlinkSQL和SparkSQL虽然也能完成类似需求,但是它们目前还不是开箱即用,需要做周边生态建设,这两种技术目前更多的应用场景还是在通过操作灵活的编程API来完成流式或离线的计算上。
2.执行模型对比
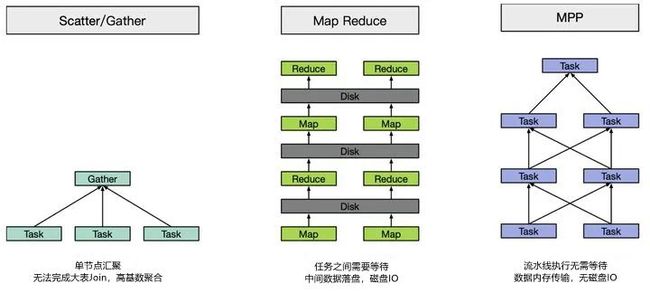
- Scatter-Gather执行模型:相当于MapReduce中的一趟Map和Reduce,没有多轮的迭代,而且中间计算结果往往存储在内存中,通过网络直接交换。Elasticsearch、Druid、Kylin都是此模型。
- MapReduce:Hive采用的正是这个模型。
- MPP:MPP学名是大规模并行计算,其实很难给它一个准确的定义。如果说的宽泛一点,Presto、Impala、Clickhouse、Spark SQL、Flink SQL这些都算。有人说Spark SQL和Flink SQL属于DAG模型,我们思考后认为,DAG并不算一种单独的模型,它只是生成执行计划的一种方式。
五、主流开源OLAP引擎的主要特点
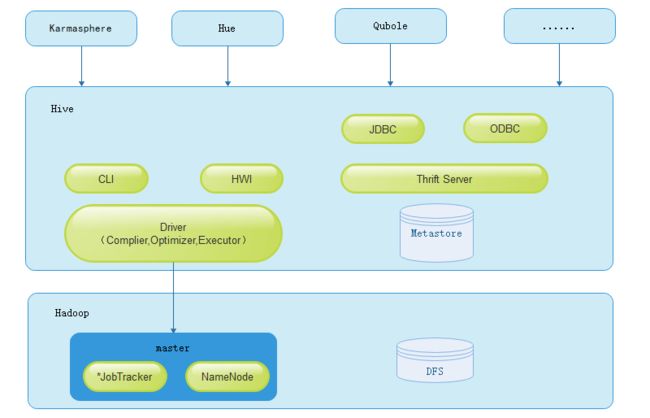
1.Hive
Hive是一个分布式SQL on Hadoop方案,底层依赖MapReduce计算模型执行分布式计算。Hive擅长执行长时间运行的离线批处理,数据量越大,优势越明显。Hive在数据量大、数据驱动需求强烈的互联网大厂比较流行。近2年,随着Clickhouse的逐渐流行,对于一些总数据量不超过百PB级别的互联网数据仓库需求,已经有多家公司改为了Clickhouse的方案。Clickhouse的优势是单个查询执行速度更快,不依赖Hadoop,架构和运维更简单。
2.Spark SQL、Flink SQL
在大部分场景下,Hive计算速度过慢,别说不能满足那些要求高QPS、低查询延迟的的对外在线服务的需求,就连企业内部的产品、运营、数据分析师也会经常抱怨Hive执行ad-hoc查询太慢。这些痛点,推动了MPP内存迭代和DAG计算模型的诞生和发展,诸如Spark SQL、Flink SQL、Presto这些技术,目前在企业中也非常流行。Spark SQL、Flink SQL的执行速度更快,编程API丰富,同时支持流式计算与批处理,并且有流批统一的趋势,使大数据应用更简单。
3.Clickhouse
ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。目前国内社区火热,各个大厂纷纷跟进大规模使用。
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。
ClickHouse部署架构简单,易用,不依赖Hadoop体系(HDFS+YARN)。它比较擅长的地方是对一个大数据量的单表进行聚合查询。Clickhouse用C++实现,底层实现具备向量化执行(Vectorized Execution)、减枝等优化能力,具备强劲的查询性能。目前在互联网企业均有广泛使用,比较适合内部BI报表型应用,可以提供低延迟(ms级别)的响应速度,也就是说单个查询非常快。
但是Clickhouse也有它的局限性,在OLAP技术选型的时候,应该避免把它作为多表关联查询(JOIN)的引擎,也应该避免把它用在期望支撑高并发数据查询的场景,OLAP分析场景中,一般认为QPS达到1000+就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1000已经非常不容易。例如Clickhouse,如果如数据量是TB级别,聚合计算稍复杂一点,单集群QPS一般达到100已经很困难了,所以它更适合企业内部BI报表应用,而不适合如数十万的广告主报表或者数百万的淘宝店主相关报表应用。Clickhouse的执行模型决定了它会尽全力来执行一个Query,而不是同时执行很多Query。
4.Elasticsearch
提到Elasticsearch,很多人的印象是这是一个开源的分布式搜索引擎,底层依托Lucene倒排索引结构,并且支持文本分词,非常适合作为搜索服务。并且用Elasticsearch作为搜索引擎,一个三节点的集群,支撑1000+的查询QPS也不是什么难事,这是搜索场景。
但是,我们这里要讲的内容是Elasticsearch的另一个功能,即作为聚合(aggregation)场景的OLAP引擎,它与搜索型场景区别很大。聚合场景,可以等同于select c1, c2, sum(c3), count(c4) from table where c1 in (‘china’, ‘usa’) and c2 < 100 这样的SQL,也就是做多维度分组聚合。虽然Elasticsearch DSL是一个复杂的JSON而不是SQL,但是意思相同,可以互相转换。
用Elasticsearch作为OLAP引擎,有几项优势:(1)擅长高QPS(QPS > 1K)、低延迟、过滤条件多、查询模式简单(如点查、简单聚合)的查询场景。(2)集群自动化管理能力(shard allocation,recovery)能力非常强。集群、索引管理和查看的API非常丰富。
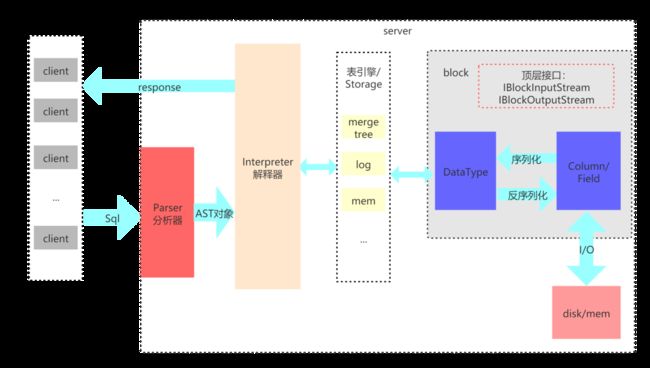
ES的执行引擎是最简单的Scatter-Gather模型,相当于MapReduce计算模型的一趟Map和Reduce。Scatter和Gather之间的节点数据交换也是基于内存的不会像MapReduce那样每次Shuffle要先落盘。ES底层依赖的Lucene文件格式,我们可以把Lucene理解为一种行列混存的模式,并且在查询时通过FST,跳表等加快数据查询。这种Scatter-Gather模型的问题是,如果Gather/Reduce的数据量比较大,由于ES是单节点执行,可能会非常慢。整体来讲,ES是通过牺牲灵活性,提高了简单OLAP查询的QPS、降低了延迟。
用Elasticsearch作为OLAP引擎,有几项劣势:多维度分组排序、分页。不支持Join。在做aggregation后,由于返回的数据嵌套层次太多,数据量会过于膨胀。
ElasticSearch和Solar也可以归为宽表模型。但其系统设计架构有较大不同,这两个一般称为搜索引擎,通过倒排索引,应用Scatter-Gather计算模型提高查询性能。对于搜索类的查询效果较好,但当数据量较大或进行扫描聚合类查询时,查询性能会有较大影响。
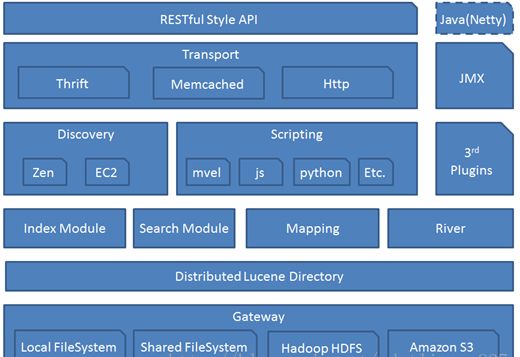
5.Presto
Presto、Impala、GreenPlum均基于MPP架构,相比Elasticsearch、Druid、Kylin这样的简单Scatter-Gather模型,在支持的SQL计算上更加通用,更适合ad-hoc查询场景,然而这些通用系统往往比专用系统更难做性能优化,所以不太适合做对查询QPS(参考值QPS > 1000)、延迟要求比较高(参考值search latency < 500ms)的在线服务,更适合做公司内部的查询服务和加速Hive查询的服务。Presto还有一个优秀的特性是使用了ANSI标准SQL,并且支持超过30+的数据源Connector。
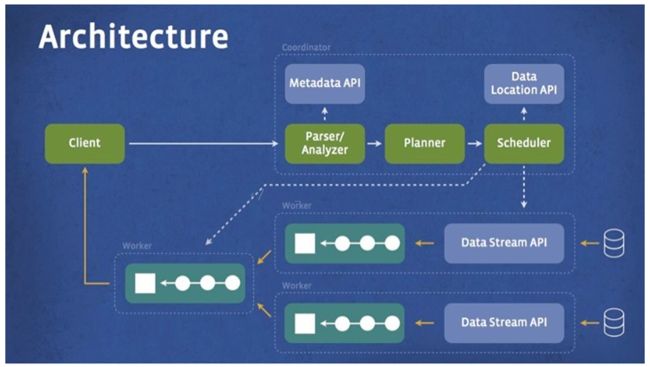
6.Impala
Impala 是 Cloudera 在受到 Google 的 Dremel 启发下开发的实时交互SQL大数据查询工具,是CDH 平台首选的 PB 级大数据实时查询分析引擎。它拥有和Hadoop一样的可扩展性、它提供了类SQL(类Hsql)语法,在多用户场景下也能拥有较高的响应速度和吞吐量。它是由Java和C++实现的,Java提供的查询交互的接口和实现,C++实现了查询引擎部分,除此之外,Impala还能够共享Hive Metastore,甚至可以直接使用Hive的JDBC jar和beeline等直接对Impala进行查询、支持丰富的数据存储格式(Parquet、Avro等)。此外,Impala 没有再使用缓慢的 Hive+MapReduce 批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由 Query Planner、Query Coordinator 和 Query Exec Engine 三部分组成),可以直接从 HDFS 或 HBase 中用 SELECT、JOIN 和统计函数查询数据,从而大大降低了延迟。Impala经常搭配存储引擎Kudu一起提供服务,这么做最大的优势是点查比较快,并且支持数据的Update和Delete。
7.Druid
Druid 是一种能对历史和实时数据提供亚秒级别的查询的数据存储。Druid 支持低延时的数据摄取,灵活的数据探索分析,高性能的数据聚合,简便的水平扩展。Druid支持更大的数据规模,具备一定的预聚合能力,通过倒排索引和位图索引进一步优化查询性能,在广告分析场景、监控报警等时序类应用均有广泛使用;
Druid的特点包括:
Druid实时的数据消费,真正做到数据摄入实时、查询结果实时
Druid支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发
Druid的核心是时间序列,把数据按照时间序列分批存储,十分适合用于对按时间进行统计分析的场景
Druid把数据列分为三类:时间戳、维度列、指标列
Druid不支持多表连接
Druid中的数据一般是使用其他计算框架(Spark等)预计算好的低层次统计数据
Druid不适合用于处理透视维度复杂多变的查询场景
Druid擅长的查询类型比较单一,一些常用的SQL(groupby 等)语句在druid里运行速度一般
Druid支持低延时的数据插入、更新,但是比hbase、传统数据库要慢很多
与其他的时序数据库类似,Druid在查询条件命中大量数据情况下可能会有性能问题,而且排序、聚合等能力普遍不太好,灵活性和扩展性不够,比如缺乏Join、子查询等。
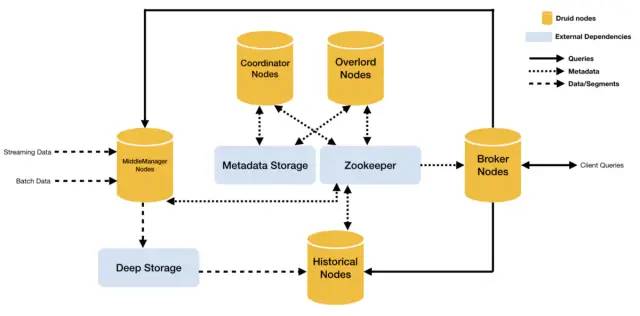
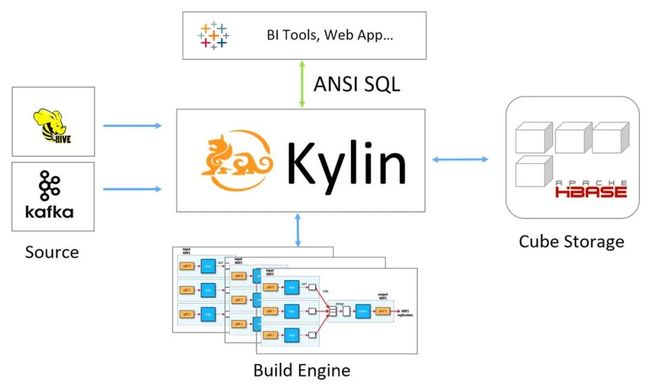
8.Kylin
Kylin自身就是一个MOLAP系统,多维立方体(MOLAP Cube)的设计使得用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体进行数据的预聚合。
适合Kylin的场景包括:
用户数据存在于Hadoop HDFS中,利用Hive将HDFS文件数据以关系数据方式存取,数据量巨大,在500G以上
每天有数G甚至数十G的数据增量导入
有10个以内较为固定的分析维度
简单来说,Kylin中数据立方的思想就是以空间换时间,通过定义一系列的纬度,对每个纬度的组合进行预先计算并存储。有N个纬度,就会有2的N次种组合。所以最好控制好纬度的数量,因为存储量会随着纬度的增加爆炸式的增长,产生灾难性后果。
六、总结
本文通过介绍了什么是OLAP以及OLAP的分类,从而对目前主流的8款OLAP引擎进行了介绍和对比,但是关于最终在技术选型上如何选择合适的大数据引擎,还是需要用户根据实际情况进行选择。只凭借本篇文章,还无法作为选型的建议。