【视频分割】【深度学习】MiVOS官方Pytorch代码解析--主界面解析
【视频分割】【深度学习】MiVOS官方Pytorch代码–主界面解析
与以往的深度学习模型的学习不同,MiVOS模型是需要与用户交互,需要用户界面支撑,增加了额外的学习成本,因此本博客从易到难先让读者大致了解构成用户界面的代码作用。
【解析代码地址】

【用interactive_gui_2.x.py代替interactive_gui.py】
文章目录
- 【视频分割】【深度学习】MiVOS官方Pytorch代码--主界面解析
- 前言
- 构建基础界面
-
- 主函数
-
- load_images函数
- load_video函数
- App(QWidget)窗口类
-
- __init__函数
- show_current_frame函数
- compose_current_im函数
- set_viz_mode函数
- overlay_davis/overlay_davis_fade函数
- update_interact_vis函数
- tl_slide函数
- on_prev/on_next函数
- 完善功能界面
-
- App(QWidget)窗口类
-
- __init__函数
- update_minimap函数
- on_motion函数
- get_scaled_pos函数
- on_zoom_plus/on_zoom_minus函数
- console_push_text函数
- 最终功能界面
-
- 主函数
- App(QWidget)窗口类
-
- __init__函数
- on_play/on_time函数
- hit_number_key函数
- vis_brush函数
- clear_brush函数
- on_press函数
- on_motion函数
- interaction_push_point函数
- on_release函数
- interaction_end_path
- clear_visualization函数
- 总结
前言
在详细解析MiVOS代码之前,首要任务是成功运行MiVOS代码【win10下参考教程】,后续学习才有意义。
本博客从零开始说明用户主界面的搭建过程,详细讲解构成用户主界面的各个模块代码,暂时不考虑深度学习的功能模块。讲解核心在interactive_gui.py文件,它是整个代码主函数,由PyQt5包构建用户交互界面,完整的interactive_gui.py代码运行效果如下图所示:
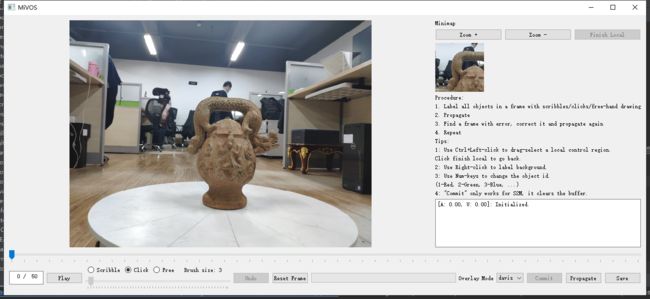
现在开始从零开始编写interactive_gui.py以及显示各阶段的界面效果。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
构建基础界面
从实现最简单的界面和基础功能开始!【代码:用interactive_gui_2.0.py代替interactive_gui.py】
主函数
主函数中ArgumentParser是python标准库里面用来处理命令行参数的库。
if __name__ == '__main__':
# Arguments parsing
parser = ArgumentParser()
# 指定输入图片的文件路径
parser.add_argument('--images', help='Folder containing input images. Either this or --video needs to be specified.')
# 指定输入视频的文件路径
parser.add_argument('--video', help='Video file readable by OpenCV. Either this or --images needs to be specified.', default='example/example.mp4')
# 限定图像/视频帧的大小(-1是保持原始大小)
parser.add_argument('--resolution', help='Pass -1 to use original size', default=480, type=int)
args = parser.parse_args()
if args.images is not None:
images = load_images(args.images, args.resolution if args.resolution > 0 else None)
elif args.video is not None:
images = load_video(args.video, args.resolution if args.resolution > 0 else None)
else:
raise NotImplementedError('You must specify either --images or --video!')
app = QApplication(sys.argv)
ex = App(images)
sys.exit(app.exec_())
load_images函数
函数在interact/interactive_utils.py文件内,主要辅助图像文件大小的限定
def load_images(path, min_side=None):
# 获取文件路径下所有jpg或png图片地址
fnames = sorted(glob.glob(os.path.join(path, '*.jpg')))
if len(fnames) == 0:
fnames = sorted(glob.glob(os.path.join(path, '*.png')))
frame_list = []
for i, fname in enumerate(fnames):
# 限定图片大小
if min_side:
image = Image.open(fname).convert('RGB')
w, h = image.size
# 设定图像宽高值的小值为min_side,大值按比计算得出
new_w = (w*min_side//min(w, h))
new_h = (h*min_side//min(w, h))
frame_list.append(np.array(image.resize((new_w, new_h), Image.BICUBIC), dtype=np.uint8))
else:
frame_list.append(np.array(Image.open(fname).convert('RGB'), dtype=np.uint8))
# 按0维将list存储的np数据堆叠
frames = np.stack(frame_list, axis=0)
return frames
load_video函数
函数在interact/interactive_utils.py文件内,主要辅助视频帧大小的限定
def load_video(path, min_side=None):
frame_list = []
# 获取视频地址
cap = cv2.VideoCapture(path)
while(cap.isOpened()):
_, frame = cap.read()
# 限定视频帧大小
if frame is None:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if min_side:
h, w = frame.shape[:2]
# 设定视频帧宽高值的小值为min_side,大值按比计算得出
new_w = (w*min_side//min(w, h))
new_h = (h*min_side//min(w, h))
frame = cv2.resize(frame, (new_w, new_h), interpolation=cv2.INTER_CUBIC)
frame_list.append(frame)
# 按0维将list存储的np数据堆叠
frames = np.stack(frame_list, axis=0)
return frames
App(QWidget)窗口类
QWidget类是所有用户界面对象的基类,主窗口类继承QWidget类
__init__函数
def __init__(self, images):
super().__init__()
self.images = images
self.num_frames, self.height, self.width = self.images.shape[:3]
# 设置窗口名称
self.setWindowTitle('MiVOS')
# 从屏幕上(100,100)位置开始,显示一个界面(宽->self.width,高->self.height+100)
self.setGeometry(100, 100, self.width,self.height + 100)
# 功能:显示当前展示图片/视频帧信息
self.lcd = QTextEdit()
self.lcd.setReadOnly(True)
self.lcd.setMaximumHeight(28)
self.lcd.setMaximumWidth(120)
self.lcd.setText('{: 4d} / {: 4d}'.format(0, self.num_frames - 1))
# 功能:图片/视频帧滑动条
self.tl_slider = QSlider(Qt.Horizontal)
# 改变滑动条时触发的改变
self.tl_slider.valueChanged.connect(self.tl_slide)
self.tl_slider.setMinimum(0)
self.tl_slider.setMaximum(self.num_frames-1)
self.tl_slider.setValue(0)
self.tl_slider.setTickPosition(QSlider.TicksBelow)
self.tl_slider.setTickInterval(1)
# 功能:设定图片/视频帧的光照情况
self.combo = QComboBox(self)
self.combo.addItem("davis")
self.combo.addItem("fade")
self.combo.addItem("light")
# 改变选择时触发的改变
self.combo.currentTextChanged.connect(self.set_viz_mode)
# 功能:显示图片/视频帧
self.main_canvas = QLabel()
self.main_canvas.setSizePolicy(QSizePolicy.Expanding, QSizePolicy.Expanding)
self.main_canvas.setAlignment(Qt.AlignCenter)
self.main_canvas.setMinimumSize(100, 100)
# 水平布局
navi = QHBoxLayout()
navi.addWidget(self.lcd)
navi.addStretch(1)
navi.addWidget(self.combo)
draw_area = QHBoxLayout()
draw_area.addWidget(self.main_canvas, 4)
# 垂直布局
layout = QVBoxLayout()
layout.addLayout(draw_area)
layout.addWidget(self.tl_slider)
layout.addLayout(navi)
self.setLayout(layout)
# 默认展示初始化
self.viz_mode = 'davis'
self.current_mask = np.zeros((self.num_frames, self.height, self.width), dtype=np.uint8)
self.cursur = 0
# <- and -> shortcuts 左右键切换
QShortcut(QKeySequence(Qt.Key_Left), self).activated.connect(self.on_prev)
QShortcut(QKeySequence(Qt.Key_Right), self).activated.connect(self.on_next)
self.show_current_frame()
self.show()
self.waiting_to_start = True # 等待开始
show_current_frame函数
def show_current_frame(self):
# 图片和mask融合
self.compose_current_im()
# 更新屏幕图片
self.update_interact_vis()
self.lcd.setText('{: 3d} / {: 3d}'.format(self.cursur, self.num_frames-1))
self.tl_slider.setValue(self.cursur)

compose_current_im函数
融合图片/视频帧及其掩膜(mask),调整显示的亮度
def compose_current_im(self):
if self.viz_mode == 'fade':
self.viz = overlay_davis_fade(self.images[self.cursur], self.current_mask[self.cursur])
elif self.viz_mode == 'davis':
self.viz = overlay_davis(self.images[self.cursur], self.current_mask[self.cursur])
elif self.viz_mode == 'light':
self.viz = overlay_davis(self.images[self.cursur], self.current_mask[self.cursur], 0.9)
else:
raise NotImplementedError
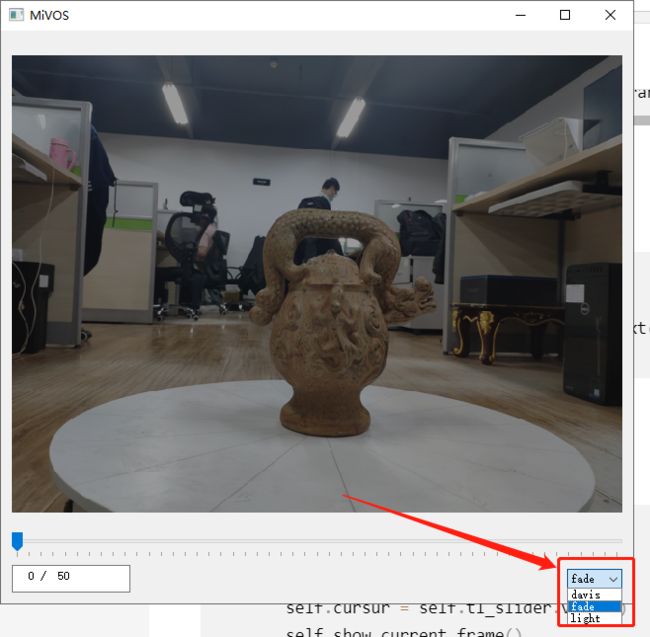
set_viz_mode函数
可以改变图像亮度模式
def set_viz_mode(self):
# 改变图像亮度模式
self.viz_mode = self.combo.currentText()
self.show_current_frame()
overlay_davis/overlay_davis_fade函数
函数在interact/interactive_utils.py文件内,融合图片及其掩膜
def overlay_davis(image, mask, alpha=0.5):
im_overlay = image.copy()
# 不同类型的mask转为对应颜色
colored_mask = color_map_np[mask]
# 融合掩膜和图片
foreground = image*alpha + (1-alpha)*colored_mask
binary_mask = (mask > 0)
im_overlay[binary_mask] = foreground[binary_mask]
# binary_dilation膨胀操作消除mask之间的小空白, 而^后异或操作得到小空白的位置并填充黑色(0)
countours = binary_dilation(binary_mask) ^ binary_mask
im_overlay[countours, :] = 0
return im_overlay.astype(image.dtype)
def overlay_davis_fade(image, mask, alpha=0.5):
im_overlay = image.copy()
colored_mask = color_map_np[mask]
foreground = image*alpha + (1-alpha)*colored_mask
binary_mask = (mask > 0)
im_overlay[binary_mask] = foreground[binary_mask]
countours = binary_dilation(binary_mask) ^ binary_mask
im_overlay[countours, :] = 0
im_overlay[~binary_mask] = im_overlay[~binary_mask] * 0.6
return im_overlay.astype(image.dtype)
light和davis没去别是因为博文掩膜(mask)初始化为0
update_interact_vis函数
目前没添加任何操作,函数只是简单的进行了numpy数据转化为QImage数据,完成在主屏幕的显示
def update_interact_vis(self):
height, width, channel = self.viz.shape
bytesPerLine = 3 * width # 每行(步幅)的字节数 RGB每行就是隔3个
self.viz_with_stroke = self.viz
self.viz_with_stroke = self.viz_with_stroke.astype(np.uint8)
# QT的图像类,用QImage进行加载,np转qt
qImg = QImage(self.viz_with_stroke.data, width, height, bytesPerLine, QImage.Format_RGB888)
# QPixmap依赖于硬件,QImage不依赖于硬件
# 主屏幕显示图片
self.main_canvas.setPixmap(QPixmap(qImg.scaled(self.main_canvas.size(),
Qt.KeepAspectRatio, Qt.FastTransformation)))
tl_slide函数
移动图片/视频帧滑动条,改变主窗口
def tl_slide(self):
if self.waiting_to_start:
self.waiting_to_start = False
self.cursur = self.tl_slider.value()
self.show_current_frame()
on_prev/on_next函数
按键左右切换图片视频帧,改变主窗口
def on_prev(self):
self.cursur = max(0, self.cursur-1)
self.tl_slider.setValue(self.cursur)
def on_next(self):
self.cursur = min(self.cursur+1, self.num_frames-1)
self.tl_slider.setValue(self.cursur)
完善功能界面
继续完善界面功能。【代码:用interactive_gui_2.1.py代替interactive_gui.py】
App(QWidget)窗口类
__init__函数
新增的功能需要的核心代码
# 功能:辅助显示图片/视频帧
self.minimap = QLabel()
self.minimap.setSizePolicy(QSizePolicy.Expanding, QSizePolicy.Expanding)
self.minimap.setAlignment(Qt.AlignTop)
self.minimap.setMinimumSize(100, 100)
# 允许鼠标在主窗口上的跟踪操作
self.main_canvas.mouseMoveEvent = self.on_motion
# 允许鼠标一直追踪
self.main_canvas.setMouseTracking(True)
# 功能:局部缩放查看功能
self.zoom_p_button = QPushButton('Zoom +')
self.zoom_p_button.clicked.connect(self.on_zoom_plus)
self.zoom_m_button = QPushButton('Zoom -')
self.zoom_m_button.clicked.connect(self.on_zoom_minus)
# 功能:用户界面的Console控制台
self.console = QPlainTextEdit()
self.console.setReadOnly(True)
self.console.setMinimumHeight(100)
self.console.setMaximumHeight(100)
update_minimap函数
显示辅助小窗口。在主窗口上获取以鼠标当前位置为中心、宽高为zoom_pixels的图片区域作为小窗口显示。
def update_minimap(self):
# 定位鼠标位置
ex, ey = self.last_ex, self.last_ey
# 获得小屏幕的半径
r = self.zoom_pixels//2
# 小窗口显示图片的局部 min(self.width-r, ex) 是防止窗口包含padding部分
ex = int(round(max(r, min(self.width-r, ex))))
ey = int(round(max(r, min(self.height-r, ey))))
patch = self.viz_with_stroke[ey-r:ey+r, ex-r:ex+r, :].astype(np.uint8) # 小窗口显示
height, width, channel = patch.shape
bytesPerLine = 3 * width
# QT的图像类,用QImage进行加载,np转qt
qImg = QImage(patch.data, width, height, bytesPerLine, QImage.Format_RGB888)
self.minimap.setPixmap(QPixmap(qImg.scaled(self.minimap.size(),
Qt.KeepAspectRatio, Qt.FastTransformation)))
需要在show_current_frame函数中添加以下代码同步
self.update_minimap()
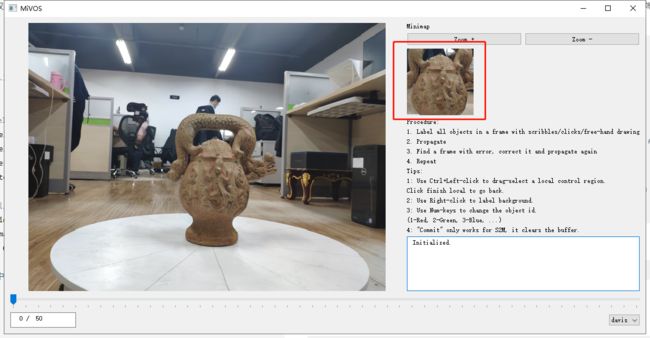
on_motion函数
获取鼠标在主屏幕图片上的坐标位置
def on_motion(self, event):
ex, ey = self.get_scaled_pos(event.x(), event.y())
self.last_ex, self.last_ey = ex, ey
self.update_interact_vis()
self.update_minimap()
get_scaled_pos函数
主屏幕尺寸是随着窗口尺寸改变而改变,用户可以自定义更改窗口大小,鼠标在主屏幕图片上的坐标位置是不唯一的。鼠标坐标需要在不同主屏幕尺寸下有统一的标准。
def get_scaled_pos(self, x, y):
# 图片尺寸
oh, ow = self.image_size.height(), self.image_size.width()
# 主屏幕尺寸
nh, nw = self.main_canvas_size.height(), self.main_canvas_size.width()
# 以原始图片尺寸为基准,获得主屏幕/图片的尺寸最小缩放比
h_ratio = nh/oh
w_ratio = nw/ow
dominate_ratio = min(h_ratio, w_ratio)
# 缩放鼠标位置
x /= dominate_ratio
y /= dominate_ratio
# 缩放主屏幕
fh, fw = nh/dominate_ratio, nw/dominate_ratio
# 主屏幕尺寸大于等于图片大小,鼠标xy坐标是需要落图片上才有效
x -= (fw-ow)/2
y -= (fh-oh)/2
x = max(0, min(self.width-1, x))
y = max(0, min(self.height-1, y))
# 正确的鼠标坐标位置
return x, y
需要在update_interact_vis函数中添加以下代码获取必要数据信息
# 主屏幕当前尺寸
self.main_canvas_size = self.main_canvas.size()
# 主屏幕中图片当前尺寸
self.image_size = qImg.size()
on_zoom_plus/on_zoom_minus函数
在原图上截取部分区域(zoom_pixels尺寸)并在相对固定的辅助窗口上显示。
zoom_pixels越小,局部关注的越细微,局部占比就放大
def on_zoom_plus(self):
self.zoom_pixels -= 25
# 设定最小尺寸
self.zoom_pixels = max(50, self.zoom_pixels)
self.update_minimap()
zoom_pixels越大,局部关注的越粗略,局部占比就缩小
def on_zoom_minus(self):
self.zoom_pixels += 25
# 设定最大尺寸
self.zoom_pixels = min(self.zoom_pixels, 300)
self.update_minimap()
console_push_text函数
Console控制台输出
def console_push_text(self, text):
text = ' %s' % (text)
self.console.appendPlainText(text)
self.console.moveCursor(QTextCursor.End)
在函数需要显示信息时添加下列代码
self.console_push_text("xxxxxxxx")

最终功能界面
不包括深度学习模型功能模块的部分。【代码:用interactive_gui_2.2.py代替interactive_gui.py】
主函数
新增功能的代码
# 增加目标个数
parser.add_argument('--num_objects', help='Default: 1 if no masks provided, masks.max() otherwise', type=int)
num_objects = args.num_objects
if num_objects is None:
num_objects = 1
App(QWidget)窗口类
__init__函数
# 功能:自动播放
self.play_button = QPushButton('Play')
self.play_button.clicked.connect(self.on_play)
# 自动播放所需计时器
self.timer = QTimer()
self.timer.setSingleShot(False)
self.timer.timeout.connect(self.on_time)
# 允许鼠标在主窗口上的操作
self.main_canvas.mousePressEvent = self.on_press
self.main_canvas.mouseReleaseEvent = self.on_release
这里通过数字键盘123切换不同的目标
# 选择合适的目标
for i in range(1, num_objects + 1):
# 创建快捷键
QShortcut(QKeySequence(str(i)), self).activated.connect(functools.partial(self.hit_number_key, i))
这里是一些临时定义的变量,在有深度学习功能的完整代码是被放到其他py文件里的
### 临时定义 添加深度学习模块后 会将这部分实现被写到其他模块
self.interaction_drawn_map = np.empty((self.height, self.width), dtype=np.uint8) # 鼠标运动轨迹图
self.interaction_drawn_map.fill(0) # 填充0
self.interaction_curr_path = [[] for _ in range(self.num_objects + 1)] # 不同的目标分开记录不同的鼠标运动轨迹图list+background的list
self.interaction_size = 3
Pimages = images_to_torch(images, device='cpu')
self.Pimages, self.Ppad = pad_divide_by(Pimages, 16, Pimages.shape[-2:])
t = Pimages.shape[1]
h, w = Pimages.shape[-2:]
self.Propagate_np_masks = np.zeros((t, h, w), dtype=np.uint8)
self.brush_size = 3
### 临时定义
on_play/on_time函数
用户点击播发按钮时候自动切换图片
def on_play(self):
# 定时器是否在运行
if self.timer.isActive():
self.timer.stop()
else:
# 设置触发的时间间隔
self.timer.start(10000 / 25)
按照一定的时间触发on_time函数,拨动视频滑动条切换图片
def on_time(self):
self.cursur += 1
if self.cursur > self.num_frames-1:
self.cursur = 0
self.tl_slider.setValue(self.cursur)
hit_number_key函数
通过数字键盘123切换不同的目标,为了用户方便感知是否切换不同目标,后续会有vis_brush/clear_brush函数来产生/销毁激光标记点。
def hit_number_key(self, number):
if number == self.current_object:
return
self.current_object = number
self.clear_brush()
self.vis_brush(self.last_ex, self.last_ey)
self.update_interact_vis()
self.show_current_frame()
vis_brush函数
鼠标放在主屏幕上时,会有一个小的激光标记点,根据切换的目标不同而颜色不同。原理则是将产生的激光点图与对应的alpha图和原始图像做简单的加权运算融合而来。
def vis_brush(self, ex, ey):
self.brush_vis_map = cv2.circle(self.brush_vis_map,
(int(round(ex)), int(round(ey))), self.brush_size//2+1, color_map[self.current_object], thickness=-1)
self.brush_vis_alpha = cv2.circle(self.brush_vis_alpha,
(int(round(ex)), int(round(ey))), self.brush_size//2+1, 0.5, thickness=-1)
用按键切换后
clear_brush函数
鼠标在移动过程中,激光点位置是不同的,需要将激光点图与对应的alpha图重置初始化,而后在由vis_brush重新设置。
def clear_brush(self):
self.brush_vis_map.fill(0)
self.brush_vis_alpha.fill(0)
on_press函数
鼠标点击时触发的信号pressed是很多操作的控制信号。
def on_press(self, event):
if self.waiting_to_start:
self.waiting_to_start = False
self.pressed = True
self.right_click = (event.button() != 1) # button()鼠标 左键0 中键1 右键2
self.on_motion(event)
on_motion函数
更新on_motion函数,不再只是获取鼠标坐标位置,需要记录鼠标在图片上的轨迹操作,不用的目标需要不同的画笔,self.current_object决定当前目标。
def on_motion(self, event):
ex, ey = self.get_scaled_pos(event.x(), event.y())
self.last_ex, self.last_ey = ex, ey
self.clear_brush()
self.vis_brush(ex, ey)
self.update_minimap()
if self.pressed:
obj = 0 if self.right_click else self.current_object
self.vis_map, self.vis_alpha = self.interaction_push_point(ex, ey, obj, (self.vis_map, self.vis_alpha))
self.update_interact_vis()
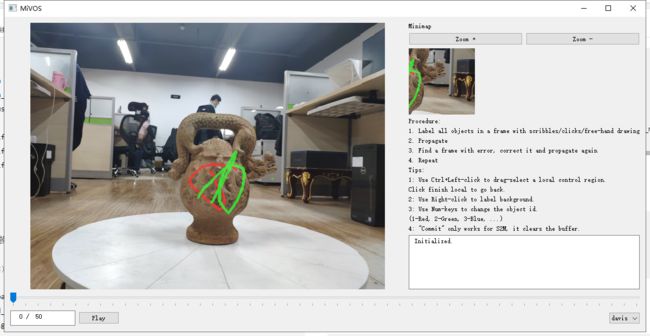
interaction_push_point函数
临时函数。深度学习功能模块的部分代码,但因为不涉及深度学习的功能,我把它提取出来作为App类的一个临时函数,用来记录鼠标在图片上的轨迹操作,在后续加入深度学习模块后会舍弃,在on_motion函数上被调用。
def interaction_push_point(self, x, y, k, vis=None):
if vis is not None:
vis_map, vis_alpha = vis
# 针对不同的目标分开记录鼠标运行轨迹
selected = self.interaction_curr_path[k]
# 更新:将当前目标的运动坐标加入鼠标运行轨迹图
selected.append((x, y))
if len(selected) >= 2: # 至少有一个目标
self.interaction_drawn_map = cv2.line(self.interaction_drawn_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
k, thickness=self.interaction_size)
# 不同目标用不同颜色画笔画出综合运动轨迹图
if vis is not None:
if k == 0:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.interaction_size)
else:
vis_map = cv2.line(vis_map,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
color_map[k], thickness=self.interaction_size)
# Visualization on/off boolean filter
vis_alpha = cv2.line(vis_alpha,
(int(round(selected[-2][0])), int(round(selected[-2][1]))),
(int(round(selected[-1][0])), int(round(selected[-1][1]))),
0.75, thickness=self.interaction_size)
更新update_interact_vis函数的部分代码,主屏展示图片需要原始图片和轨迹图和鼠标激光位置图做简单加权运算。
vis_map = self.vis_map
vis_alpha = self.vis_alpha
brush_vis_map = self.brush_vis_map
brush_vis_alpha = self.brush_vis_alpha
self.viz_with_stroke = self.viz*(1-vis_alpha) + vis_map*vis_alpha
self.viz_with_stroke = self.viz_with_stroke*(1-brush_vis_alpha) + brush_vis_map*brush_vis_alpha
self.viz_with_stroke = self.viz_with_stroke.astype(np.uint8)
on_release函数
完成在主屏幕图片上的鼠标操作
def on_release(self, event):
self.on_motion(event)
self.interaction_end_path()
self.update_interacted_mask()
self.pressed = self.right_click = False
interaction_end_path
临时函数。消除所有运动轨迹图,方便下次操作。
def interaction_end_path(self):
self.interaction_curr_path = [[] for _ in range(self.num_objects + 1)]
clear_visualization函数
清除主屏展示图片。
def clear_visualization(self):
self.vis_map.fill(0)
self.vis_alpha.fill(0)
在tl_slide函数内增加,每次切换屏幕将清除所有鼠标针对不同目标的运动轨迹,因为加入深度学习模块后,只要保留模型输出的不同目标的mask掩码即可,画笔勾出的草图不再需要。
self.clear_visualization()
总结
尽可能简单、详细的介绍MiVOS用户界面代码的作用。后续正式开始讲解MiVOS的模型原理和代码。