方面级别情感分析介绍
个人笔记如有错误 欢迎交流指正
参考综述:A Survey on Aspect-Based Sentiment Analysis:Tasks, Methods, and Challenges
1. 方面级别情感分析介绍
由于细粒度情感分析是由早期的情感分析发展来的, 所有在讲细粒度情感分析之前我们需要要了解一下什么是情感分析。
说明: (细粒度情感分析也叫方面级别情感分析, 本文统一称为细粒度情感分析)
1.1 普通情感分析
早期情感分析通常只关注文本的整体情感极性,将文本划分为正向、负向或中性等简单的情感类别。这种情感分析方法主要用于判断文本整体的情感倾向,但无法提供关于情感细节的深入信息。
举个普通情感分析的例子:
输入文本: TCL电视让我感觉很棒,画质一流!
目标输出: 正向
普通情感分析只需要判断这个句子是正向/积极的就算是完成任务了
缺点1: 得到文本信息比较少,
缺点2: 如果有的句子很长, 既有正向,也有负向的情绪的话就不好分类。
为了弥补普通情感分析的缺点,于是慢慢有了细粒度情感分析的研究
1.2 细粒度情感分析
细粒度情感分析(Fine-grained Sentiment Analysis)是一种自然语言处理NLP技术,旨在从给定的文本或句子中提取一个或多个特定的情感元素。对于海量的文本信息来说,这样的细粒度信息很难人工抽取,2012年便有人开始研究。目前的细粒度情感分析任务通常涉及四个情感元素,他们分别是方面术语,观点术语,方面类别, 情感极性等四个情感元素。那么什么是方面术语, 观点术语, 方面类别, 和情感极性呢。
- **方面术语a: **一般是文本中明确出现的描述目标,如图2“The pizza is delicious”句中的“pizza”就是方面术语。
特殊情况: 当目标被隐式表达(例如“It’s overestimated”)时,由于方面术语是代词,这种情况我们一般将方面术语表示为一个名为“null”的特殊术语。(一般是主语)
- 观点/意见词o: 一般是(主语)表达自己对目标对象的意见的表达方式。如图2“The pizza is delicious”句中的“delicious”就是观点术语。(一般是宾语)
- 方面类别C: 一个预定义好的类别集合, 一般用于对方面术语的分类, 该集合为每个特定的感兴趣的领域预定义。例如,pizza 的方面类别是food。 (方面类别与方面术语是一对多的关系)
- 情绪极性: 表示当前文本/情感元组的情感极性, 通常包括正面、负面和中性。

1.3 普通情感分析和细粒度情感分析进行对比
细粒度情感分析举个例子: 细粒度情感分析—四元组抽取
输入文本: TCL电视让我感觉很棒,画质一流!
目标输出: (TCL电视 , 很棒, 品牌, 正向) (画质, 一流, 画面色彩,正向)
以四元组任务为例 我们不但要得到输入文本的情感极性, 还要抽取文本句子的方面术语, 观点术语,以及方面分类。 相比图1的情感分析是不是信息更多了,而且可以有效解决缺点1和缺点2,感觉瞬间变得很有趣, 有趣的代价是事情也变得复杂起来了。

2. 细粒度情感分析研究现状
目前的细粒度情感分析研究根据通过文本句子需要预测的情感元素数量,现有研究进一步将细粒度情感分析子任务分为单一细粒度情感分析任务和复合细粒度情感分析任务。单个细粒度情感分析任务主要包括方面词提取(ATE)、观点词提取(OTE)、方面类别检测(ACD)和方面情感分类(ASC)。复合细粒度情感分析子任务从文本评论中提取更详细的信息,并联合预测多个情感元组元素。其中包括方面意见项对提取(AOPE)、方面类别情感分析(ACSA)、方面情感三联体提取(ASTE)、方面类别情感检测(ACSD),以及最近提出的基于方面的情感四元预测(ASQP)。
2.1 细粒度情感分析子任务
各种ABSA任务之间的关系图如下所示:

2.1 单一细粒度情感分析任务(Single Tasks)
单一细粒度情感分析任务是指抽取某个关键情感元素(也就是四个情感元素中的任意一个),如图4中的黄色部分
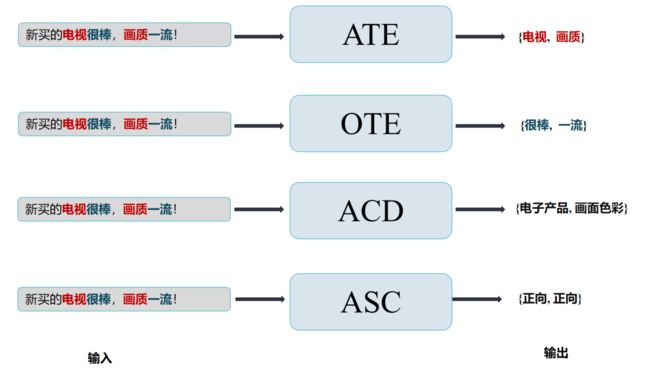
方面术语提取(ATE): 方面术语提取是ABSA的一项基本任务,目的是提取给定文本中用户表达意见的显式方面表达。(分类/抽取任务)
**意见术语提取(OTE): **意见词提取是识别对该方面的意见表达的任务。由于意见项和方面项总是同时出现,仅提取意见项而不考虑其关联方面是没有意义的。(分类/抽取任务)
方面情感分类(ASC): 也称为基于方面/目标/层次的情感分类,旨在预测句子中特定方面的情感极性。(分类任务)
方面类别检测(ACD): 方面类别检测(Aspect category detection, ACD)是为给定的句子识别被讨论的方面类别,这些类别属于一个预定义的类别集 (分类任务)
以文本: TCL电视让我感觉很棒,画质一流!
四个单一的细粒度情感任务的目标输出如下图所示
2. 复合细粒度情感分析任务(Compound Tasks)
复合ABSA子任务从文本评论中提取更详细的信息,并联合预测多个情感元素元组。(如4中的蓝色部分) 这些任务可以被视为单一细粒度情感任务的组合。然而,这些复合任务的目标不仅是提取多个情感元素,而且还通过预测对(即两个元素)、三联(即三个元素)、甚至四联(即四个元素)格式的元素来耦合它们。显然我们的最终目标是实现细粒度的情感分析,而能够使用封装更加良好的复合任务是更有前途的。
常见的复合任务有:
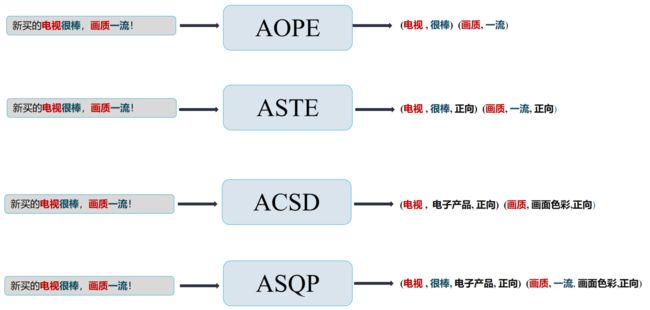
方面-意见对抽取(AOPE): 从给定文本中提取相应的(方面,意见术语)对
方面情感三元组提取(ASTE): 从给定文本中提取去相应的(方面,意见术语, 情感极性)三元组
方面-类别-情感检测(ACSD): 从给定文本中提取去相应的(方面,方面类别, 情感极性)三元组
方面情感四元组预测(ASQP): 从给定文本中提取去相应的(方面,意见术语,方面类别, 情感极性)四元组
以文本: TCL电视让我感觉很棒,画质一流!
四个主要的复合细粒度情感任务的目标输出如下图所示

3.1 管道方法Pipeline
首先采用两个序列标注模型,第一阶段分别提取带有情感的方面和意见词。
第二阶段,利用分类器从预测的方面和观点中寻找有效的方面-观点对,最终构建三元组预测;为了更好地利用多个情感元素之间的关系。
3.2 位置感知标记方案
位置感知标记方案是一种在自然语言处理任务中使用的标记方案,旨在对文本中的单词或字符进行标记,并同时表示它们在原始文本中的位置信息。位置感知标记方案通常用于序列标注任务,例如命名实体识别、词性标注和语义角色标注等。
位置感知标记方案BIOS通过引入位置信息来弥补这一不足。它使用额外的标记来指示单词或字符在文本中的相对位置,通常有以下几种常见的标记:
- B:表示实体的起始位置(Beginning)。
- I:表示实体的中间位置(Inside)。
- E:表示实体的结束位置(End)。
- S:表示一个独立的实体(Single)。
3.3 机器阅读理解
双向MRC框架:一个预测方面项,然后是意见项,另一个先预测意见,然后是方面。最终得到方面意见术语对 然后预测情感极性。
3.4 序列到序列Seq2Seq
目前基于Seq2Seq的情感研究方法主要专注于目标输出的构造。例如将目标输出构造为自然语言的句子,或者是集合结构, 树结构等等。而且有研究显示情感元素的预测顺序对模型的效果也是很重要的。