【深入MaxCompute】人力家:用MaxCompute 事务表2.0主键模型去重数据持续降本增效
简介: MaxCompute新增Transaction Table2.0(下文简称事务表2.0)表类型在2023年6月27日开始邀测,支持基于事务表2.0实现近实时的增全量一体的数据存储、计算解决方案。
作者: 石玉阳 人力家 高级数据研发工程师
业务简介
人力家是由阿里钉钉和人力窝共同投资成立,帮助客户进入人力资源数字化,依靠产品技术创新驱动战略的互联网公司。公司主要提供包括人事管理、薪酬管理、社保管理、增值服务在内的人力资源SaaS服务,加速对人力资源领域赋能,实现人力资源新工作方式。目前已服务电子商务、零售服务等领域的多行业客户。
人力家是一家典型的创业公司,目前处于一个竞争激烈的市场环境中,公司具有多产品性质,每个产品的数据具有独立性,同时为了配合内部CRM数据需求,更好地把数据整合,对于数仓团队来说是一个不小的挑战,对于数仓团队要求的是稳,准,及时响应。需要数仓团队既要满足内部的数据需求,也需要在计算的成本上实现优化。
业务痛点
在使用阿里云大数据计算服务MaxCompute过程中发现随着存量数据增加,增量数据去重成本越来越大,具体分析发现有如下4个原因
增量数据量级少
公司虽然是多产品,但每天新增的用户数据和历史变化的数据量相对于历史全量数据的量级(GB)比较下处于较小的数据量级(MB)。
历史数据二次计算
对于增量数据去重,每天利用昨日历史全量+今日新增数据开窗去重计算,但历史全量数据需要更新的数据部分其实很少,每次都需要把历史数据拉出来进行开窗去重计算,这无疑一笔比较大的计算成本。
开窗去重计算成本大
使用row_number函数开窗去重取得业务主键的最新数据需要把昨日历史数据+今日数据合并计算,用户表有亿级别大小,但为了数据去重节省存储成本和后续的建模运算,这部分成本是偏大的,其实大部分历史数据没有更新,本质上是不需要再次参与运算处理,每天一次的用户表去重单条SQL预估费用达到4.63元(按量付费)。
全量拉取成本大
如果每天全量拉取业务库数据,数据量是亿级别,但其实更新的数据量级少,对于业务端的db压力大,严重影响业务端db性能。
Transaction Table2.0数据去重改进
MaxCompute新增Transaction Table2.0(下文简称事务表2.0)表类型在2023年6月27日开始邀测,MaxCompute支持基于事务表2.0实现近实时的增全量一体的数据存储、计算解决方案。人力家数仓研发团队开始第一时间了解其特性和功能,人力家数仓团队发现其特性主键模型可以用来进行数据去重,减少开窗计算成本问题,主要实现方式如下。
- 每日增量用户基础信息开窗去重;
- 由于主键表的主键不能为空,需要过滤出业务主键为空的数据;
- 把每日增量数据开窗去重后的数据直接insert into 主键表,系统会自动进行按照业务主键进行去重计算。
具体改进实践措施
整体对比
| 去重SQL执行时间(单位s) | 去重SQL预估成本(单位元) | |
|---|---|---|
| 普通表 | 151 | 4.63 |
| Transaction Table2.0 | 72 | 0.06 |
成本和计算时间对比
1、建表语句和插入更新语句
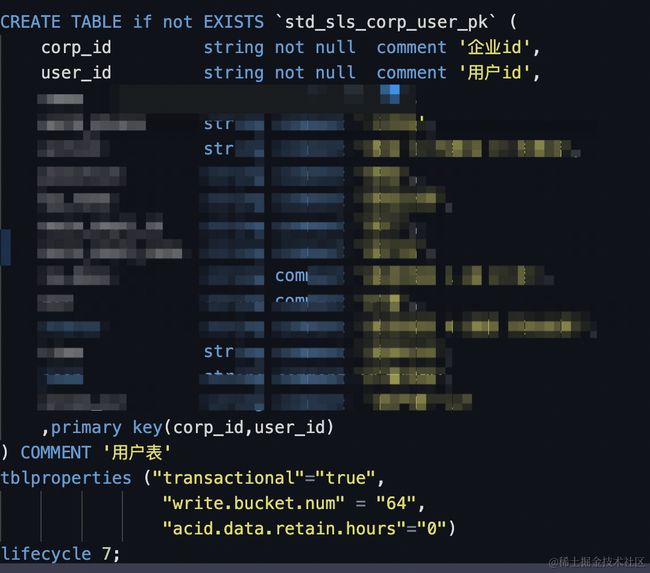
更新语句
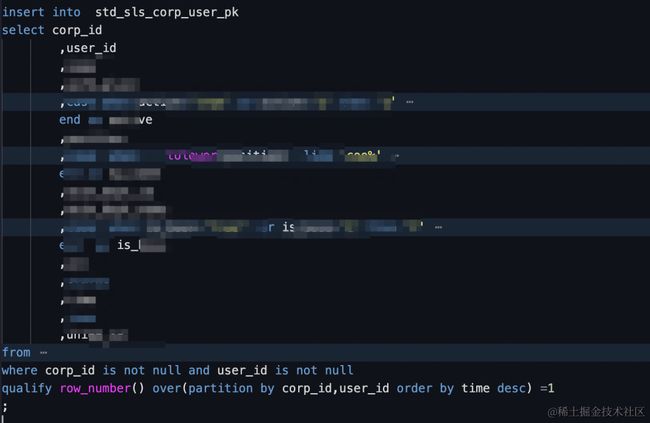
2、成本和计算
分区表去重运行预估成本:
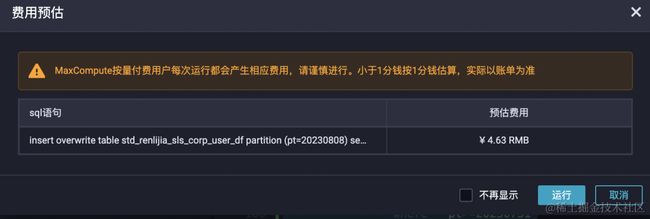
预估费用,不能作为实际计费标准,仅供参考,实际费用请以账单为准。
主键表去重运行预估成本:
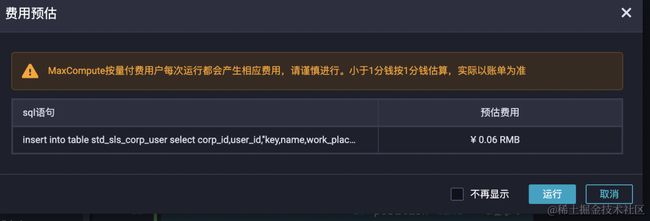
预估费用,不能作为实际计费标准,仅供参考,实际费用请以账单为准。
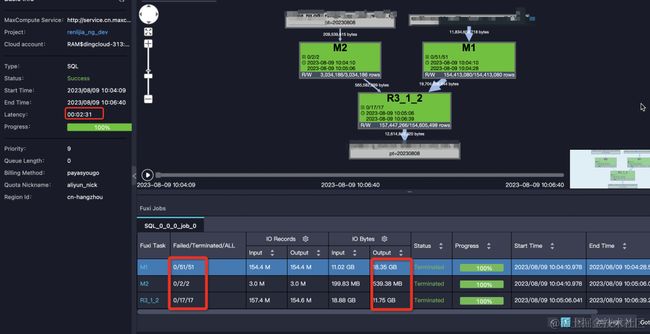
分区表计算时间和资源
事务表2.0主键表计算时间和资源
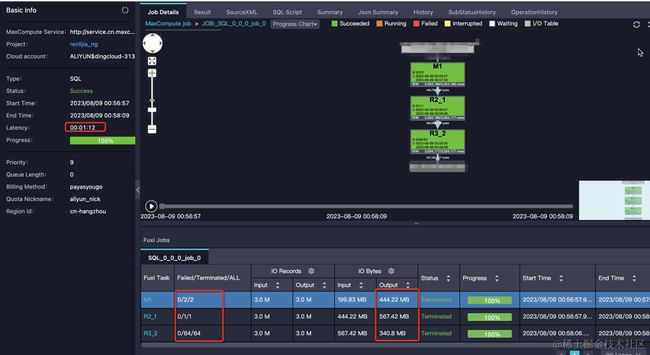
通过上述对比,用户表每天的计算SQL成本从4.63元下降到0.06元,计算时间缩短一半,reduce_num明显增加,map端减少,reduce端的数据量明显变多。
合并小文件
事务表2.0支持近实时增量写入和timetravel查询特性,在数据频繁写入的场景中,必然会引入大量的小文件,需要设计合理高效的合并策略来对小文件进行合并以及数据去重,解决大量小文件读写IO低效以及缓解存储系统的压力,但也要避免频繁Compact引发严重的写放大和冲突失败。
目前主要支持两种数据合并方式:
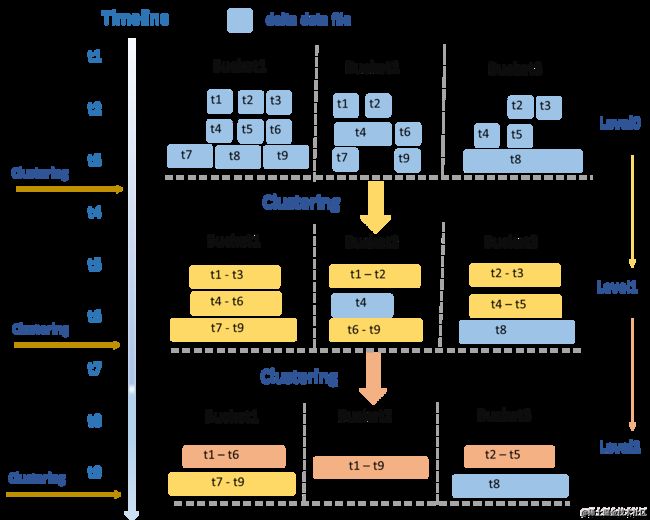
- Clustering:只是把Commit的DeltaFile合并成一个大文件,不改变数据内容。系统内部会根据新增的文件大小、文件数量等因素周期性地执行,不需要用户手动操作。主要解决小文件IO读写效率和稳定性问题。
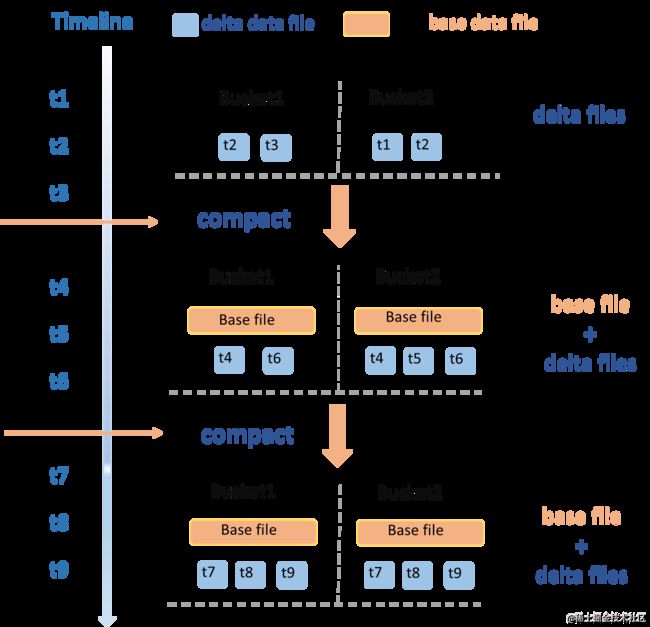
- Compaction:会把所有的数据文件按照一定策略进行Merge操作,生成一批新的BaseFile,相同PK的数据行只存储最新的状态,不包含任何历史状态,也不会包含任何系统列信息,因此BaseFile本身不支持timetravel操作,主要用于提升查询效率。支持用户根据业务场景主动触发,也支持通过设置表属性由系统周期性自动触发。
综上面对主键表面对增量数据时,并不会马上对其进行小文件合并,这样会有大量的小文件产生,小文件会占有大量的存储空间且不利于数据查询速度,针对以上情况,我们可以在insert into 后增加手动合并下主键表的小文件或者也可通过配置表属性按照时间频率、Commit次数等维度自动触发Compaction机制,或等待系统进行的Clustering合并。如果是每日的新增仅一次的数据更新,这里更推荐使用系统的Clustering机制。
注意点:
desc extend table_name显示出来的file_num 和 size是包含回收站数据的,目前没办法准确显示,可以清空回收站数据或者Compaction 观察日志结尾的filenum数量。
数据时空旅行查询和历史数据修复
对于事务表2.0类型的表,MaxCompute支持查询回溯到源表某个历史时间或者版本进行历史Snapshot查询(TimeTravel查询),也支持指定源表某个历史时间区间或者版本区间进行历史增量查询(Incremental查询), 需要设置acid.data.retain.hours才可以使用TimeTravel查询和Incremental查询。
数据时空旅行查询
1、基于TimeTravel 查询截止到指定时间(例如datetime格式的字符串常量)的所有历史数据(需要设置)
select * from mf_tt2 timestamp as of '2023-06-26 09:33:00' where dd='01' and hh='01';
查询历史数据和版本号
show history for table mf_tt2 partition(dd='01',hh='01');
查询截止到指定version常量的所有历史数据
select * from mf_tt2 version as of 2 where dd='01' and hh='01';
2、基于Incremental 查询指定时间(例如datetime格式的字符串常量)区间的历史增量数据,常量值需要根据具体操作的时间来配置
select * from mf_tt2 timestamp between '2023-06-26 09:31:40' and '2023-06-26 09:32:00' where dd= '01' and hh='01';
查询指定version区间的历史增量数据
select * from mf_tt2 version between 2 and 3 where dd ='01' and hh = '01';
数据修复
基于TimeTravel 查询截止到指定时间的全量数据直接insert into 一张临时表,清空当前事务表2.0主键表数据,把临时表数据insert into当前事务表2.0主键表。
注意事项及未来规划
动态硬删数据
对于历史数据没办法硬删除(这部分需要依赖flink-cdc),目前可以通过软删实现,或者通过一段时间的历史数据积累,拿出所有历史数据进行过滤重新整体插入主键表;这里提一点就是flink-cdc+flink-sql支持delete实时硬删数据,但是单表的flink-cdc任务比较重,多个表需要不同的server-id,对于业务系统源头断的db压力大,不是很推荐,期待后续的cdas整库同步。
存储空间增加
事务表2.0主键模型数据存储空间相比于分区表开窗后的数据占有的存储空间大一点,主要是开窗后的数据分布更均匀,数据压缩比更大,但是相对于sql每次的每天一次的计算成本,存储空间所占有的每日费用处于较低的费用级(可忽略)。
flink-cdc
配合flink-cdc直接可以直接实现准实时数据同步,提高数据新鲜度。
整库同步
期待阿里云实时计算Flink的cdas语法目标端整合MaxCompute端做到整库同步和ddl变更。
物化视图
利用物化视图+flink-cdc组合方式可以做到