Python数学建模1-模拟人类一生中会认识多少人的模型统计与分析
大家好,我是微学AI,今天给大家带来Python数学建模1-模拟人类一生中会认识多少人的模型统计与分析。你有没有统计过从出生到现在你接触过多少人了,你认识了多少人了,可能你只是认识,但是现在基本不联系了,可能现在联系的只有个位数,在这忙碌的现代生活,人与人的空间距离被拉远了。今天我就来统计一下,构建模型看看我们一生中会认识多少人呢?
目录
1.背景介绍
2.数学模型描述
3.数学模型构建与代码实现
4.运行结果
5.总结
1.背景介绍
我们人的一生中会认识各种各样的人,有没有统计过我们这一生会认识多少人呢,中国有14亿人,但是我们身边认识的人可能就占其中的凤毛麟角,真正认识的人的个数可能无法精确计算的,因为每个人的社交圈和人际关系都是不同的。认识的人数可以从几十到几千不等,这取决于我们的职业、生活环境和日常社交活动。
在这么多认识的人里面,能够真正陪伴我们到最后的人,这通常是指亲密的伴侣、家人或者非常亲近的朋友。这个人在我们的一生中可能只有一个或者少数几个。他们与我们分享喜怒哀乐,支持我们的梦想,以及在困难时刻给予支持和鼓励。这些人对我们来说是宝贵的,值得我们好好珍惜和维护这种关系。
2.数学模型描述
现在有一个虚拟社会的模型,这个数学模型里面有10000个人是样本个体: 每个人在一生中可能会认识各种各样的人,统计80年后每个人认识的人数排名和认识认识的平均数。
模型条件1:在学生阶段:每个人会经历幼儿园,小学,初中,高中,大学这几个阶段,也有的人还有读研究生和博士,我们把他划分成8:2,有20%读读研究生和博士,每个几段每个人都有60个同学和10个各科老师,每个人50%会有10个其他同学好朋友,50%会有20个其他发小和朋友。
在学生学习阶段每个人随机会有0-20个意外认识的人。
模型条件2:在工作阶段:有40%的人有3个单位,有20%的人有4个单位,有20%的人有2个单位,有10%的人有1个单位,有5%的人有5个以上的单位(分别是5-8个单位),有5%的人没有单位,每个单位每人随机会认识40-180个工作上的朋友、合作伙伴(这个是正态分布)。
模型条件3:在退休阶段:每个人随机会认识30-70个退休生活上的老朋友,亲戚,年轻人(这个是正态分布)。
3.数学模型构建与代码实现
我们将构建一个有10000个人的模型,然后进行预测每个人遇到的人数,对每个人一生中认识的人数排名,并统计认识认识的平均数。
模型中用到了正态分布,正态分布是概率论和统计学中一种重要的连续概率分布,常被称为高斯分布。其数学原理可以通过以下方式表示:
正态分布的概率密度函数,可以表示为:
f ( x ) = 1 σ 2 π e − ( x − μ ) 2 2 σ 2 f(x) = \frac{1}{{\sigma \sqrt{2\pi}}} e^{-\frac{{(x-\mu)^2}}{{2\sigma^2}}} f(x)=σ2π1e−2σ2(x−μ)2
其中, x x x 是随机变量的取值, μ \mu μ 是均值, σ \sigma σ 是标准差。
正态分布的累积分布函数可以表示为:
F ( x ) = ∫ − ∞ x f ( t ) d t = 1 2 [ 1 + erf ( x − μ σ 2 ) ] F(x) = \int_{-\infty}^{x} f(t) \, dt = \frac{1}{2} \left[ 1 + \text{erf}\left( \frac{x-\mu}{\sigma\sqrt{2}} \right) \right] F(x)=∫−∞xf(t)dt=21[1+erf(σ2x−μ)]
其中, erf ( z ) \text{erf}(z) erf(z) 是误差函数。
根据正态分布的性质,大约 68% 的数据落在均值 μ ± 1 \mu \pm 1 μ±1 标准差 σ \sigma σ 的范围内,大约 95% 的数据落在 μ ± 2 σ \mu \pm 2\sigma μ±2σ 范围内,大约 99.7% 的数据落在 μ ± 3 σ \mu \pm 3\sigma μ±3σ 范围内。这被称为正态分布的 68-95-99.7 法则。
下面是实现的代码:
import numpy as np
import matplotlib.pyplot as plt
# 初始化
num_people = 10000
people = np.zeros(num_people)
# 生成一个服从正态分布的随机数字
def generate_random_number(mean,mins,maxs,sigma = 5):
# 使用numpy库生成一个服从正态分布的随机数
number = np.random.normal(mean, sigma)
# 对结果取整并限制在0到10之间
number = int(round(number))
number = max(mins, min(number, maxs))
return number
# 学生阶段
for i in range(num_people):
friends = 60*5 + 10 # 同学和老师
if np.random.rand() < 0.5:
friends += 20 # 其他同学好朋友
else:
friends += 30 # 其他发小和朋友
if np.random.rand() < 0.2:
friends += (60 + 10) * 2 # 研究生和博士阶段
# 0-10随机生成数字
friends += np.random.randint(0, 20)
people[i] += friends
# 工作阶段
for i in range(num_people):
num_jobs = np.random.choice([3, 4, 2, 1, np.random.randint(5, 9), 0], p=[0.4, 0.2, 0.2, 0.1, 0.05, 0.05])
for m in range(num_jobs):
friends =generate_random_number(120,40,180)
#friends = np.random.randint(40, 161) # 工作上的朋友、邻居、亲戚
people[i] += friends
# 退休阶段
for i in range(num_people):
friends = generate_random_number(60,30,70)
#friends = np.random.randint(30, 71) # 退休生活上的老朋友,亲戚,年轻人
people[i] += friends
# 排名和平均数
#rank = np.argsort(-people) + 1 # 按照从高到低排序,并将索引转换为排名(从1开始)
rank = np.argsort(people)[::-1]
average = np.mean(people)
for i in rank:
print("Rank {}: {}".format(i + 1, people[i]))
# 打印结果
print("Average number of people known:", average)
# 画图
plt.figure()
plt.hist(people, bins=20)
plt.title('Distribution of Number of People Known')
plt.xlabel('Number of People Known')
plt.ylabel('Frequency')
plt.show()
4.运行结果
我们看到遇到人数的排名:
Rank 4263: 1551.0
Rank 2190: 1545.0
Rank 5038: 1533.0
Rank 9674: 1517.0
Rank 7863: 1515.0
Rank 5988: 1514.0
Rank 569: 1514.0
Rank 973: 1512.0
Rank 9469: 1512.0
Rank 6025: 1511.0
Rank 2429: 1506.0
Rank 9857: 1504.0
Rank 4073: 1501.0
Rank 4721: 1500.0
Rank 9604: 1500.0
Rank 8893: 1497.0
Rank 6530: 1497.0
Rank 7289: 1496.0
Rank 6069: 1490.0
Rank 5171: 1488.0
Rank 1414: 1469.0
Rank 4347: 1420.0
Rank 1091: 1408.0
Rank 9573: 1406.0
Rank 1321: 1402.0
Rank 7111: 1401.0
Rank 5332: 1401.0
Rank 5681: 1400.0
Rank 4972: 1399.0
Rank 2777: 1397.0
Rank 1433: 1396.0
Rank 686: 1396.0
Rank 7207: 1396.0
Rank 7374: 1395.0
Rank 7938: 1395.0
Rank 3329: 1394.0
Rank 9229: 1392.0
Rank 7709: 1391.0
Rank 3458: 1390.0
Rank 5074: 1390.0
Rank 9244: 1386.0
Rank 727: 1386.0
Rank 7791: 1385.0
Rank 1668: 1384.0
Rank 5889: 1384.0
Rank 9352: 1383.0
...
以下是认识的人数分布图:
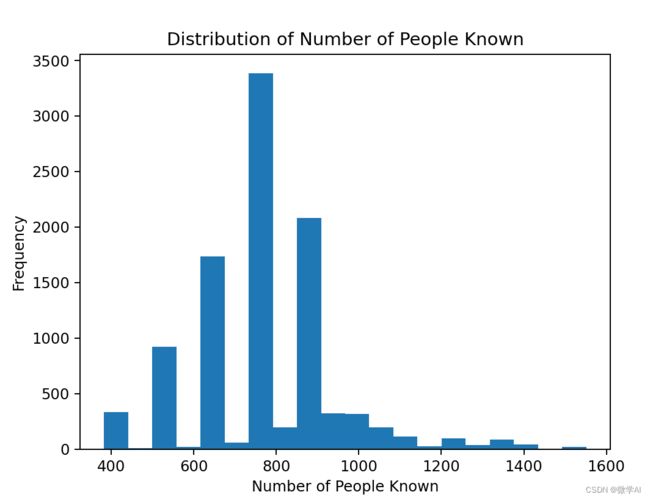
根据以上结果,每个人平均一生中真正会认识约775人,但是这个只是简单的模型预测,实际生活中可能会认识更多的人,也有相对内向的人可能认识的人就很少。
模型中认识人数最多的是1551人,这个表示真正有打交道的人,而不是一面之缘。
5.总结
在我们一生中,我们会认识许多人,我们要用心对待每一个我们遇到的人,因为他们都有可能成为我们人生中的那个特别的人。虽然这个特别的人的出现概率较低,但如果我们保持开放和善良的态度,我们就有更大的机会遇到他们。
但是真正能够陪伴我们走到最后的人却是非常罕见的。这个人可能是我们的伴侣,我们的挚爱。 数据告诉我们要懂得珍惜身边的人和与他们建立深厚的关系,我们要学会感恩,并且尽力去维护和培养那些与我们心灵相通、能够在困难时刻给予支持和理解的人际关系。