Restormer
## Overlapped image patch embedding with 3x3 Conv
class OverlapPatchEmbed(nn.Module):
def __init__(self, in_c=3, embed_dim=48, bias=False):
super(OverlapPatchEmbed, self).__init__()
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, x):
x = self.proj(x)
return x
OverlapPatchEmbed 将输入图像传递给一个3x3的卷积层,得到一个嵌入结果。由于其步长为1且有填充,该卷积操作保持了输入图像的空间尺寸。这与许多其他的patch embedding方法不同,这些方法通常使用较大的卷积核和步长来直接将图像分割成不重取的patch。这里的方法允许邻近的patch有重叠,因此得名 “OverlapPatchEmbed”
class Downsample(nn.Module):
def __init__(self, n_feat):
super(Downsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat//2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelUnshuffle(2))
def forward(self, x):
return self.body(x)
Downsample 模块首先使用卷积层将输入特征图的通道数减半,然后使用像素反洗牌操作进一步降采样特征图。这两步操作联合起来为输入特征图提供了降采样效果

这是Pytorch的官方文档,可以看到,Downsample模块先用二维卷积层nn.Conv2d把输入通道减半,然后用nn.PixelUnshuffle将通道数x4,长/2,宽/2,所以总体上该模块是将通道数x2,长/2,宽/2。
class Upsample(nn.Module):
def __init__(self, n_feat):
super(Upsample, self).__init__()
self.body = nn.Sequential(nn.Conv2d(n_feat, n_feat*2, kernel_size=3, stride=1, padding=1, bias=False),
nn.PixelShuffle(2))
def forward(self, x):
return self.body(x)

Transformer Block不改变输出维度
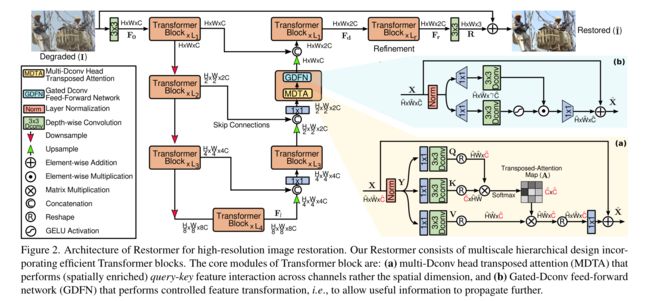
以下是Restormer的实现代码,与上图完全一致。
##---------- Restormer -----------------------
class Restormer(nn.Module):
def __init__(self,
inp_channels=3,
out_channels=3,
dim = 48,
num_blocks = [4,6,6,8],
num_refinement_blocks = 4,
heads = [1,2,4,8],
ffn_expansion_factor = 2.66,
bias = False,
LayerNorm_type = 'WithBias', ## Other option 'BiasFree'
dual_pixel_task = False ## True for dual-pixel defocus deblurring only. Also set inp_channels=6
):
super(Restormer, self).__init__()
self.patch_embed = OverlapPatchEmbed(inp_channels, dim)#3x3卷积层
self.encoder_level1 = nn.Sequential(*[TransformerBlock(dim=dim, num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor\
, bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.down1_2 = Downsample(dim) ## From Level 1 to Level 2
self.encoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor,\
bias=bias,LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.down2_3 = Downsample(int(dim*2**1)) ## From Level 2 to Level 3
self.encoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor, \
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.down3_4 = Downsample(int(dim*2**2)) ## From Level 3 to Level 4
self.latent = nn.Sequential(*[TransformerBlock(dim=int(dim*2**3), num_heads=heads[3], ffn_expansion_factor=ffn_expansion_factor, \
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[3])])
self.up4_3 = Upsample(int(dim*2**3)) ## From Level 4 to Level 3
self.reduce_chan_level3 = nn.Conv2d(int(dim*2**3), int(dim*2**2), kernel_size=1, bias=bias)
self.decoder_level3 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**2), num_heads=heads[2], ffn_expansion_factor=ffn_expansion_factor,\
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[2])])
self.up3_2 = Upsample(int(dim*2**2)) ## From Level 3 to Level 2
self.reduce_chan_level2 = nn.Conv2d(int(dim*2**2), int(dim*2**1), kernel_size=1, bias=bias)
self.decoder_level2 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[1], ffn_expansion_factor=ffn_expansion_factor, \
bias=bias, LayerNorm_type=LayerNorm_type) for i in range(num_blocks[1])])
self.up2_1 = Upsample(int(dim*2**1)) ## From Level 2 to Level 1 (NO 1x1 conv to reduce channels)
self.decoder_level1 = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias,\
LayerNorm_type=LayerNorm_type) for i in range(num_blocks[0])])
self.refinement = nn.Sequential(*[TransformerBlock(dim=int(dim*2**1), num_heads=heads[0], ffn_expansion_factor=ffn_expansion_factor, bias=bias, \
LayerNorm_type=LayerNorm_type) for i in range(num_refinement_blocks)])
#### For Dual-Pixel Defocus Deblurring Task ####
self.dual_pixel_task = dual_pixel_task
if self.dual_pixel_task:
self.skip_conv = nn.Conv2d(dim, int(dim*2**1), kernel_size=1, bias=bias)
###########################
self.output = nn.Conv2d(int(dim*2**1), out_channels, kernel_size=3, stride=1, padding=1, bias=bias)
def forward(self, inp_img):
inp_enc_level1 = self.patch_embed(inp_img)#F0
out_enc_level1 = self.encoder_level1(inp_enc_level1)
inp_enc_level2 = self.down1_2(out_enc_level1)
out_enc_level2 = self.encoder_level2(inp_enc_level2)
inp_enc_level3 = self.down2_3(out_enc_level2)
out_enc_level3 = self.encoder_level3(inp_enc_level3)
inp_enc_level4 = self.down3_4(out_enc_level3)
latent = self.latent(inp_enc_level4)
inp_dec_level3 = self.up4_3(latent)
inp_dec_level3 = torch.cat([inp_dec_level3, out_enc_level3], 1)
inp_dec_level3 = self.reduce_chan_level3(inp_dec_level3)
out_dec_level3 = self.decoder_level3(inp_dec_level3)
inp_dec_level2 = self.up3_2(out_dec_level3)
inp_dec_level2 = torch.cat([inp_dec_level2, out_enc_level2], 1)
inp_dec_level2 = self.reduce_chan_level2(inp_dec_level2)
out_dec_level2 = self.decoder_level2(inp_dec_level2)
inp_dec_level1 = self.up2_1(out_dec_level2)
inp_dec_level1 = torch.cat([inp_dec_level1, out_enc_level1], 1)
out_dec_level1 = self.decoder_level1(inp_dec_level1)
out_dec_level1 = self.refinement(out_dec_level1)
#### For Dual-Pixel Defocus Deblurring Task ####
if self.dual_pixel_task:
out_dec_level1 = out_dec_level1 + self.skip_conv(inp_enc_level1)
out_dec_level1 = self.output(out_dec_level1)
###########################
else:
out_dec_level1 = self.output(out_dec_level1) + inp_img
return out_dec_level1