Python第三方库PySpark框架基础应用(阶段六)
一,Spark,Pyspark介绍
1.1Spark介绍
Apache的Spark是用于大规模数据处理的统一(unified)分析引擎,简单来讲Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB,PB乃至EB级别的海量数据。
1.2Pypark介绍
Spark作为全球顶级的分布式计算框架,支持众多的编程语言进行开发。而python语言则是Spark重点支持的对象。重点体现在python的第三方库PySpark。
1.3PySpark第三方 库的安装
![]()

1.4构建PySpark执行环境的入口对象
如果想要使用pyspark库完成数据的处理,首先要构建一个执行环境的入口对象。PySpark的执行环境入口对象是:类SparkContext的类对象。
# 导包
from pyspark import SparkConf, SparkContext
# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext对象
sc = SparkContext(conf=conf)
# 打印PySpark的运行版本
print(sc.version)
# 停止SparkContext对象的运行(停止PySpark程序)
sc.stop()
运行后报错:
Java gateway process exited before sending its port number
解决方案:
(1)由于电脑中没有配置Java环境导致出错,只需要去官网下载Java的jdk并安装,然后配置好环境变量即可。
![]()
(2)jdk安装位置:

(3)环境变量配置:![]()
path目录下:
![]()
(4)重启PyCharm,运行程序

1.5PySpark编程模型
(1)SparkContext类对象是PySpark编程中一切功能的入口,都是通过此对象调用类中的一些方法使用。
三大步:

- 通过SparkContext对象完成数据输入。
- 输入数据后得到RDD对象,对RDD对象进行迭代计算
- 最终通过RDD对象的成员方法,完成数据输出工作,将结果输出到list列表,元组,字典,文本文件,数据库等。

二,数据输入
2.1理解RDD对象
- 输入的数据,都会得到一个RDD类的对象,RDD:弹性分布式数据集。
- PySpark针对数据的处理都是以RDD对象作为载体:(1)数据存储在RDD内(2)各类数据的计算方法,也都是RDD类的成员方法(3)RDD的数据计算方法返回值依旧是RDD对象。

2.2PySpark数据输入的两种方法
(1)PySpark支持通过SparkContext对象的parallelize方法将list,tuple,set,dic,str转换为RDD对象。
from pyspark import SparkConf,SparkContext
conf=SparkConf().setMaster("local[*]").setAppName("test_date_input")
#得到入口对象
scn=SparkContext(conf=conf)
list=[1,2,3,4,5,6]
#出入数据
rdd1=scn.parallelize(list)
rdd2=scn.parallelize((1,2,3,4,5,6))
rdd3=scn.parallelize("abcdef")
rdd4=scn.parallelize({"key1": "value1", "key2": "value2"})
#通过collect()查看RDD中的内容
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
scn.stop()
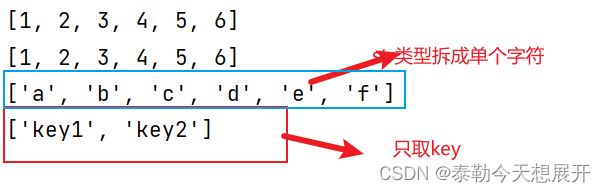
注意:字符串会被拆分出一个个的字符,存入RDD对象,字典仅key会被存入RDD对象。
(2)读取文件转换为RDD对象
#读取文件
from pyspark import SparkConf,SparkContext
conf=SparkConf().setMaster("local[*]").setAppName("test_date_input")
#得到入口对象
scn=SparkContext(conf=conf)
rdd=scn.textFile("E:\pythonProject/test1.txt")
print(rdd.collect())


三,数据计算
RDD中含有丰富的计算成员方法(算子)
3.1map方法
- 功能:map算子,是将RDD数据一条条进行处理的逻辑,方法参数接收的是处理函数func,返回RDD
- func函数可以在使用map()前定义好,然后直接传入,也可以直接在map(lambda 参数:方法体)定义lambda函数
rdd.map(func)

3.1.1,BUG1:
当代码写到这一步如果直接运行仍会报错。
from pyspark import SparkConf,SparkContext
con=SparkConf().setMaster("local[*]").setAppName("map_test")
sc=SparkContext(conf=con)
#准备RDD数据
rdd1=sc.parallelize([1,2,3,4])
#通过map()方法将列表元素都乘10
def func(x):
return x * 10
rdd2=rdd1.map(func)
print(rdd2.collect())
sc.stop()

- 报错原因:代码没有准确找到python解释器。
- 解决方法:在spark中设置环境变量指向python解释器的目录即可。
- 完整代码:
#设置环境变量,运行时可以找到python解释器
import os
os.environ['PYSPARK_PYTHON']="E:\Python_setup\python3.10\python.exe"
from pyspark import SparkConf,SparkContext
#设置环境变量,运行时可以找到python解释器
import os
os.environ['PYSPARK_PYTHON']="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("map_test")
sc=SparkContext(conf=con)
#准备RDD数据
rdd1=sc.parallelize([1,2,3,4])
#通过map()方法将列表元素都乘10
def func(x):
return x * 10
rdd2=rdd1.map(func)
print(rdd2.collect())
sc.stop()
3.1.2 BUG2
- 经过添加环境变量的配置,理论上是可以正常运行,但我的电脑仍然报错:
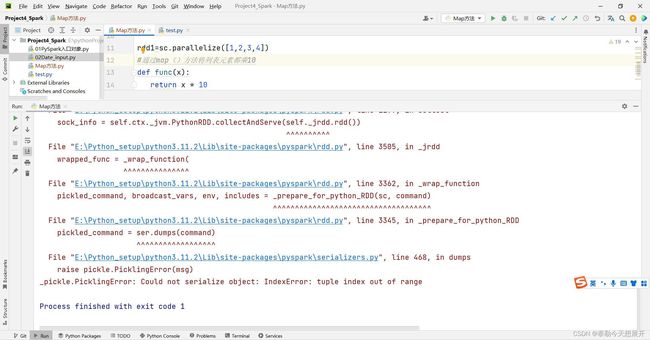
- 经过多次重装pyspark仍然不行
- 最终发现是python解释器版本问题,我的python解释器用的是3.11.2,版本太高导致的错误,最终通过改用python3.10成功运行,注意:更换解释器后pyspark第三方库要重新安装。
- 运行结果:

3.1.3Lambda函数和链式调用简化程序

"""
演示RDD的map成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "E:\Python_setup\python3.10\python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 通过map方法将全部数据都乘以10
# def func(data):
# return data * 10
rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5)
print(rdd2.collect())
# (T) -> U
# (T) -> T
# 链式调用
3.2flatMap方法
- 基本功能与map相似,能够一个个处理RDD数据,此外最主要的作用是进行解除嵌套操作。
- 对于嵌套的双层list=[[1,2,3],[4,5,6]],解除嵌套后变成单层嵌套[1,2,3,4,5,6]
- 先使用map()来提取列表单个单词
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
#准备RDD
rdd=sc.parallelize(["hello world","python 666"])
#需求:将RDD数据列表一个个单词提出来
rdd2=rdd.map(lambda date:date.split(" "))
print(rdd2.collect())
sc.stop()

- 使用flatMap解除嵌套
rdd2=rdd.flatMap(lambda date:date.split(" "))

3.3reduceByKey方法
- 针对KV形式的RDD数据,自动根据key分组,然后根据提供的聚合逻辑,完成组内数据value的聚合操作。
- KV形式的数据也就是二元元祖




from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
rdd=sc.parallelize([('男',99),('男',89),('女',86),('女',95)])
#求男生和女生两个组的成绩之和
rdd2=rdd.reduceByKey(lambda a,b:a+b)
print(rdd2.collect())
sc.stop()

3.4案例1
- 完成使用pyspark实现单词计数案例:读取文件hello.txt文件,统计单词出现几次。
- hello.txt文件内容:

from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
#01读文件
rdd1=sc.textFile("E:\pythonProject/hello.txt")
# print(rdd1.collect())
#02取出每个单词,存入单个列表,而不是嵌套列表
word_rdd2=rdd1.flatMap(lambda x:x.split(" "))
# print(word_rdd2.collect())
#03将列表中单词转换成 双元元组('itheima',1), 'itheima',1), ('itcast', 1),以便使用reduceBykey进行数量统计
tulpe_word_rdd3=word_rdd2.map(lambda word:(word,1))
# print(tulpe_word_rdd3.collect())
#04统计数量
num_rdd4=tulpe_word_rdd3.reduceByKey(lambda a,b:a+b)
print(num_rdd4.collect())
sc.stop()

- 结果
![]()
- 运行出现警告:UserWarning: Please install psutil to have better support with spilling
- 安装:psutil第三方库即可解决
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple psutil
3.5filter方法
- 功能:过滤想要的数据进行保留,返回的是BOOL类型,返回ture被保留

from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
rdd1=sc.parallelize([1,2,3,4,5])
#过滤选取偶数
rdd2=rdd1.filter(lambda num:num%2==0)
print(rdd2.collect())
sc.stop()

3.6distinct方法
- 对RDD数据进行去重操作,返回新RDD
- 语法:rdd.distinct()无需传参
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
rdd1=sc.parallelize([1,2,2,3,4,4,5])
rdd2=rdd1.distinct()
print(rdd2.collect())
sc.stop()

3.7sortBy方法
- 功能:对RDD数据进行排序,基于指定的排序依据

- 对以下结果进行排序,以第二个列为参考值。

from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
#01读文件
rdd1=sc.textFile("E:\pythonProject/hello.txt")
# print(rdd1.collect())
#02取出每个单词,存入单个列表,而不是嵌套列表
word_rdd2=rdd1.flatMap(lambda x:x.split(" "))
# print(word_rdd2.collect())
#03将列表中单词转换成 双元元组('itheima',1), 'itheima',1), ('itcast', 1),以便使用reduceBykey进行数量统计
tulpe_word_rdd3=word_rdd2.map(lambda word:(word,1))
# print(tulpe_word_rdd3.collect())
#04统计数量
num_rdd4=tulpe_word_rdd3.reduceByKey(lambda a,b:a+b)
# print(num_rdd4.collect())
#05对结果进行排序
result_rdd5=num_rdd4.sortBy(lambda x:x[1],ascending=False,numPartitions=1)#ascending=False表示降序排序
print(result_rdd5.collect())
sc.stop()

四,数据输出
将RDD对象输出为python对象或文件。

4.1输出为python对象
4.1.1collect()算子
- 功能:将RDD各个分区中的数据,统一收集到Driver中,形成一个list对象
- 用法:rdd.collect()
4.1.2reduce()算子
- 功能:对rdd数据按照传入的函数逻辑进行聚合,与reduceBykey不同的是不需要按照key进行分组,即传入的数据不需要是双元元组。
- 用法:rdd.reduce(func)

4.1.3take()算子
- 功能:取rdd的前N个元素,组合成list返回。
- 用法:rdd.take(5)取前五个数据
4.1.4count()算子
- 功能:计算rdd中有多少条数据,返回一个数字。
- 用法:rdd.count()
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
rdd1=sc.parallelize([1,2,3,4,5,6])
#collect()算子
rdd2=rdd1.collect()
print(rdd2)
#take()算子
rdd3=rdd1.take(4)
print(rdd3)
#reduce()算子
rdd4=rdd1.reduce(lambda a,b:a+b)
print(rdd4)
#count()算子
rdd5=rdd1.count()
print(rdd5)

4.2输出到文件中
4.2.1saveAsTextFile算子
- 功能:将rdd数据写入文本文件中
- 支持本地写出,hdfs等文件系统

from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
#01输出为python对象
# rdd1=sc.parallelize([1,2,3,4,5,6])
# #collect()算子
# rdd2=rdd1.collect()
# print(rdd2)
# #take()算子
# rdd3=rdd1.take(4)
# print(rdd3)
# #reduce()算子
# rdd4=rdd1.reduce(lambda a,b:a+b)
# print(rdd4)
# #count()算子
# rdd5=rdd1.count()
# print(rdd5)
#02输出到本地文本文件
#创建rdd对象
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize([("hello",3),("spark",5),("Hi",7)])#创建双元祖
rdd3=sc.parallelize([[1,3,5],[6,7,9],[11,13,15]])
#输出到文本文件
rdd1.saveAsTextFile("E:\pythonProject/spark_output1")
rdd2.saveAsTextFile("E:\pythonProject/spark_output2")
rdd3.saveAsTextFile("E:\pythonProject/spark_output3")
4.2.2配置Hadoop依赖
直接运行会出错,需要配置Hadoop依赖:

- 下载Hadoop安装包并解压
- 在python代码os模块中配置:
os.environ["HADOOP_HOME"]="E:\Python_setup\spark输出到文件,Hadoop依赖配置\hadoop-3.0.0"
- 下载winutils.exe,放入Hadoop解压文件夹的bin目录
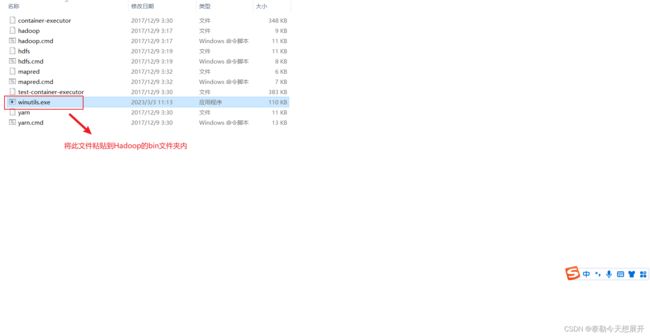
- 下载hadoop.dll,放入C:\Windows\System32文件夹

- 运行结果:
from pyspark import SparkConf,SparkContext
import os
os.environ["PYSPARK_PYTHON"]="E:\Python_setup\python3.10\python.exe"
os.environ["HADOOP_HOME"]="E:\Python_setup\spark输出到文件,Hadoop依赖配置\hadoop-3.0.0"
con=SparkConf().setMaster("local[*]").setAppName("test_spark")
sc=SparkContext(conf=con)
#01输出为python对象
# rdd1=sc.parallelize([1,2,3,4,5,6])
# #collect()算子
# rdd2=rdd1.collect()
# print(rdd2)
# #take()算子
# rdd3=rdd1.take(4)
# print(rdd3)
# #reduce()算子
# rdd4=rdd1.reduce(lambda a,b:a+b)
# print(rdd4)
# #count()算子
# rdd5=rdd1.count()
# print(rdd5)
#02输出到本地文本文件
#创建rdd对象
rdd1=sc.parallelize([1,2,3,4,5])
rdd2=sc.parallelize([("hello",3),("spark",5),("Hi",7)])#创建双元祖
rdd3=sc.parallelize([[1,3,5],[6,7,9],[11,13,15]])
#输出到文本文件
rdd1.saveAsTextFile("E:\pythonProject/spark_output1")
rdd2.saveAsTextFile("E:\pythonProject/spark_output2")
rdd3.saveAsTextFile("E:\pythonProject/spark_output3")


- numSlices=1设置分区为1
rdd1=sc.parallelize([1,2,3,4,5],numSlices=1)
rdd2=sc.parallelize([("hello",3),("spark",5),("Hi",7)],numSlices=1)#创建双元祖
rdd3=sc.parallelize([[1,3,5],[6,7,9],[11,13,15]],numSlices=1)
