大数据学习:impala基础
impala基础
1. impala介绍
1.1 impala概述
- Impala是Cloudera公司推出,提供对HDFS、Hbase数据的高性能、低延迟的交互式SQL查询功能。
- 官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sq工具。
impala是参照谷歌的新三篇论文(Caffeine–网络搜索引擎、Pregel–分布式图计算、Dremel–交互式分析工具)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce。
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点。

1.2 impala与hive的关系
- impala是基于hive的大数据分析查询引擎,直接使用hive的元数据metadata。
- impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。
- 安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务。
1.3 impala优点
- 基于内存进行计算,能够对PB级数据进行交互式实时查询、分析,只要你内存足够大
- 摈弃了MR的计算,改用C+来实现,有针对性的硬件优化
- 在底层对硬件进行优化, LLVM统一编译运行:编译器,比较稳定,效率高
- 具有数据仓库的特性,可对hive数据直接做数据分析
- 支持列式存储
- 可以和Hbase整合,因为hive可以整合hbase
- 支持Data Local
- 数据本地化:无需数据移动,减少数据的传输
- 支持JDBC/ODBC远程访问
1.4 impala缺点
- 基于内存计算,对内存依赖性较大
- 基于hive,与hive共存亡,紧耦合
- 稳定性不如hive
- 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新
- 不支持用户定义函数UDF

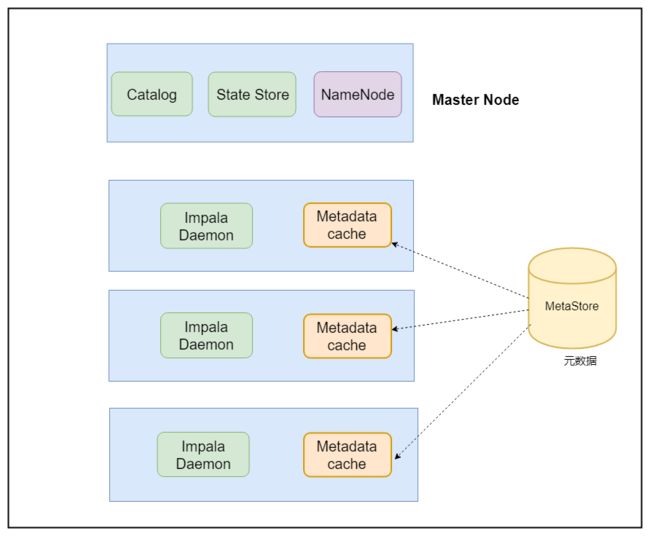
2. impala基础架构
Impala主要由Impalad、 State Store、Catalogd和CLI组成。
2.1 impala体系结构

2.1.1 Statestored
impala集群的主节点
- 为ImpalaDaemon提供查找服务,并周期性地检查Impala进程状态
补充说明:
如果某个Impalad节点由于硬件错误、软件错误或者其他原因导致离线,statestored就会通知其他的节点,避免其他节点再向这个离线的节点发送请求。
由于statestored是当集群节点有问题的时候起通知作用,所以它对Impala集群并不是有关键影响的。
如果statestored没有运行或者运行失败,其他节点和分布式任务会照常运行,只是说当节点掉线的时候集群会变得没那么健壮。当statestored恢复正常运行时,它就又开始与其他节点通信并进行监控。
2.1.2 Catalogd
impala集群的主节点
- 从Hive元数据库中同步元数据,分发表的元数据信息到各个impala daemon中
- 接收来自statestore的所有请求,告知哪些impalad节点是健康的
补充说明:
- Impala 1.2中加入的catalog服务减少了REFRESH和INVALIDATE METADATA语句的使用。
- 在之前的版本中,当在某个节点上执行了CREATE DATABASE、DROP DATABASE、CREATE TABLE、ALTER TABLE、或者DROP TABLE语句之后,需要在其它的各个节点上执行命令INVALIDATE METADATA来确保元数据信息的更新。
- 同样的,当你在某个节点上执行了INSERT语句,在其它节点上执行查询时就得先执行REFRESH table_name这个操作,这样才能识别到新增的数据文件。
- 需要注意的是,通过Impala执行的操作带来的元数据变化,有了catalog就不需要再执行REFRESH和INVALIDATE METADATA,但如果是通过Hive进行的建表、加载数据,则仍然需要执行REFRESH和INVALIDATE METADATA来通知Impala更新元数据信息。
2.1.3 impalad
- Impala的核心组件是运行在各个节点上面的impalad这个守护进程
- 接收client请求、Query执行并返回给中心协调节点
- 子节点上的守护进程,负责向statestore保持通信,汇报工作
- 执行计算。
因内存依赖大,所以最好不要和imapla的其他组件放到同一节点
最好是与hdfs的datanode节点部署在一起,提高查询计算(数据本地化)。
考虑集群性能问题,一般将StateStored 与 Catalogd 放在同一节点上,因两者之间要进行大量的通信。
2.2 impala查询过程
客户端连接到impala daemon 上,它的内部有三个组件;
Query planner(查询解析器)
- 将我们的字符串sql 语句解释成为执行计划,
Query coordinator(中心协调节点)
- coordinator从State Store请求其他的Impala daemons,并把查询分发给其他的Impala daemons
Query executor(查询执行器)
- 而做查询工作的是就是executor

2.3 元数据缓存
1)impala集群中的元数据是保存在hive的metastore中的(mysql数据库中)
2)当impala集群启动之后,catalogd会从hive的metastore中把元数据信息同步过来,然后通过Statestore分发元数据信息到impala daemon中进行缓存。
3)如果在impala deamon中产生的元数据变更(创建库、创建表、修改表)操作。Catalog服务通知所有Impala daemons来更新缓存。这些都会缓存下来,然后通过catalog持久化这些信息到hive的metastore中.
4)如果是hive的客户端进行了元数据的变更操作,这个时候对于impala来说是不知道的,这里就需要impala去手动同步刷新.
2.3.1 refresh 命令手动同步
用于刷新某个表或者某个分区的数据信息,它会重用之前的表元数据,仅仅执行文件刷新操作
- 例如insert into、load data、alter table add partition、alter table drop partition等
REFRESH [table] //刷新某个表
REFRESH [table] PARTITION [partition] //刷新某个表的某个分区
2.3.2 imvalidate metadata 命令手动同步
用于刷新全库或者某个表的元数据,包括表的元数据和表内的文件数据.
- 例如hive中create table/drop table/alter table add columns等操作。
INVALIDATE METADATA; //重新加载所有库中的所有表
INVALIDATE METADATA [table] //重新加载指定的某个表
3. impala安装部署
3.1 配置本地yum源
- 由于impala没有提供tar包供我们进行安装,只提供了rpm包,所以我们在安装impala的时候,需要使用rpm包来进行安装,rpm包只有cloudera公司提供了,所以我们去cloudera公司网站进行下载rpm包即可,但是另外一个问题,impala的rpm包依赖非常多的其他的rpm包,可以一个个的将依赖找出来,也可以将所有的rpm包下载下来,制作成我们本地yum源来进行安装。
2)我们这里就选择制作本地yum源来进行安装,所以首先我们需要下载到所有的rpm包,下载地址如下
http://archive.cloudera.com/cdh5/repo-as-tarball/5.14.0/
镜像文件 cdh5.14.0-centos7.tar.gz
3.1.1 配置本地Yum的Repository
把node3服务器作为镜像源节点,使用httpd这个软件来作为服务端,启动httpd的服务来作为我们镜像源的下载地址
- 1.上传镜像文件到node3上
- 2.解压 tar -zxvf cdh5.14.0-centos7.tar.gz -C /opt/bigdata
- 3.安装httpd服务并启动
yum -y install httpd
systemctl start httpd.service
- 4.创建yum源配置文件
进入到/etc/yum.repos.d目录,新建文件
vim localimp.repo
[localimp]
name=localimp
baseurl=http://node3/cdh5.14.0
gpgcheck=0
enabled=1
- 5.创建apache httpd的读取连接
ln -s /opt/bigdata/cdh/5.14.0 /var/www/html/cdh5.14.0
- 6.页面访问本地yum源
http://node3/cdh5.14.
- 7.将node3上制作好的localimp配置文件发放到其他节点上去
scp /etc/yum.repos.d/localimp.repo node1:/etc/yum.repos.d
scp /etc/yum.repos.d/localimp.repo node2:/etc/yum.repos.d
3.2 安装规划
| 服务名称 | node1 | node2 | node3 |
|---|---|---|---|
| impala-catalog | 安装 | 不安装 | 不安装 |
| impala-state-store | 安装 | 不安装 | 不安装 |
| impala-server | 不安装 | 安装 | 安装 |
| impala-shell | 不安装 | 安装 | 安装 |
- 其中state-store 和 catalog 类似于 namenode一般部署在主节点
- 而 impala-server类似于datenode部署在子节点上
- impala-shell可以部署在任意节点上。它是impala的shell 客户端。
3.3 yum源安装
主节点node1执行以下命令进行安装
yum install impala-state-store -y
yum install impala-catalog -y
yum install bigtop-utils -y
从节点node2和node3执行以下命令进行安装
yum install impala-server -y
yum install impala-shell -y
yum install bigtop-utils -y
3.4 修改配置信息
3.4.1 修改 hive-site.xml文件
impala依赖于hive,所以首先需要进行hive的配置修改;
# node1机器修改hive-site.xml内容如下:
vim /opt/bigdata/hive/conf/hive-site.xml
<property>
<name>hive.metastore.urisname>
<value>thrift://node1:9083value>
property>
<property>
<name>hive.metastore.client.socket.timeoutname>
<value>3600value>
property>
3.4.2 将hive的安装目录发送到node2与node3上
在node1上执行命令
cd /opt/bigdata/
scp -r hive node2:$PWD
scp -r hive node3:$PWD
3.4.3 启动hive的metastore服务
在node1上启动hive的metastore服务
cd /opt/bigdata/hive
nohup bin/hive --service metastore &
注意:一定要保证mysql的服务正常启动,否则metastore的服务不能够启动
3.4.4 所有hadoop节点修改hdfs-site.xml文件
所有节点创建文件夹,并且授权
##用root用户创建,并授权给hadoop用户
mkdir -p /var/run/hdfs-sockets
chown -R hadoop:hadoop /var/run/hdfs-sockets
修改所有节点的hdfs-site.xml添加以下配置,修改完之后重启hdfs集群生效
vim /opt/bigdata/hadoop/etc/hadoop/hdfs-site.xml
<!--短路读取 就是允许impala把一些信息存储在本地磁盘上,可以加快计算的速度-->
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
</property>
<!--打开块位置的存储的元数据信息-->
<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>
<!--Datanode和DFSClient之间沟通的Socket的本地文件路径-->
<property>
<name>dfs.domain.socket.path</name>
<value>/var/run/hdfs-sockets/dn</value>
</property>
<!--分布式文件系统中并行RPC的超时-->
<property>
<name>dfs.client.file-block-storage-locations.timeout.millis</name>
<value>10000</value>
</property>
<!--<property>
<name>dfs.datanode.hdfs-blocks-metadata.enabled</name>
<value>true</value>
</property>-->
三台机器执行以下命令给文件夹授权
sudo chown -R hadoop:hadoop /var/run/hdfs-sockets/
3.4.5 重启hdfs
start-dfs.sh
3.4.6 创建hadoop与hive的配置文件的连接
- impala的配置目录为 /etc/impala/conf
- 这个路径下面需要把 core-site.xml、hdfs-site.xml、hive-site.xml拷贝到这里来,但是我们这里使用软连接的方式会更好。
- 所有节点执行以下命令创建链接到impala配置目录下来
ln -s /opt/bigdata/hadoop/etc/hadoop/core-site.xml /etc/impala/conf/core-site.xml
ln -s /opt/bigdata/hadoop/etc/hadoop/hdfs-site.xml /etc/impala/conf/hdfs-site.xml
ln -s /opt/bigdata/hive/conf/hive-site.xml /etc/impala/conf/hive-site.xml
3.4.7 所有节点修改impala默认配置
所有节点修改impala默认配置
vi /etc/default/impala
#指定集群的CATALOG_SERVICE和STATE_STORE服务地址
IMPALA_CATALOG_SERVICE_HOST=node1
IMPALA_STATE_STORE_HOST=node1
3.4.8 所有节点创建mysql的驱动包的软连接
mkdir -p /usr/share/java
ln -s /opt/bigdata/apache-hive-1.2.2-bin/lib/mysql-connector-java-5.1.46.jar /usr/share/java/mysql-connector-java.jar
3.4.9 所有节点修改bigtop的java路径(root)
修改bigtop的java_home路径
vim /etc/default/bigtop-utils
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
4. impala集群的启动和停止
4.1 启动
1、需要启动HDFS
##用hadoop用户启动hadoop,hive 用root用户启动impala
start-dfs.sh
2、启动hive的元数据服务
- 在node1上执行命令
cd /opt/bigdata/hive
nohup bin/hive --service metastore &
3、启动impala
- 在主节点node1上启动以下服务
service impala-state-store start
service impala-catalog start
- 在从节点node2和node3上启动impala-server
service impala-server start
4、查看impala进程是否存在
ps -ef | grep impala
注意:启动之后所有关于impala的日志默认都在 /var/log/impala这个路径下,node1机器上面应该有二个进程,node2与node3机器上面只有一个进程,如果进程个数不对,去对应目录下查看报错日志

![]()
![]()
4.2 停止
- 在主节点node1上关闭以下服务
service impala-state-store stop
service impala-catalog stop
- 在从节点node2和node3上关闭impala-server
service impala-server stop
5. impala的web管理界面
启动好impala集群之后,可以访问web地址,查看集群相关信息
- 访问 statestored 的管理界面http://node1:25010/

- 访问 catalogd 的管理界面http://node1:25020/
- 访问 impalad 的管理界面http://node2:25000/

6. impala的使用
6.1 impala-shell的外部命令参数语法
1.不需要进入到impala-shell交互命令行当中即可执行的命令参数
2.impala-shell后面执行的时候可以带很多参数:
- -h 查看帮助文档
impala-shell -h
- -r 刷新整个元数据,数据量大的时候,比较消耗服务器性能
impala-shell -r
- -v 查看对应版本
impala-shell -v -V
- -f 执行查询文件
cd /opt/install
vim impala-shell.sql
select * from course.score;
通过-f 参数来执行执行的查询文件
impala-shell -f impala-shell.sql
- -p 显示查询计划
impala-shell -f impala-shell.sql -p
6.2 impala-shell的内部命令参数语法
在node2或者是node3上进入impala-shell命令行之后可以执行的语法
1)help
- 帮助文档


2)connect
connect hostname连接到某一台机器上面去执行

3)refresh 刷新
refresh dbname.tablename增量刷新,刷新某一张表的元数据,主要用于刷新hive当中数据表里面的数据改变的情况
4)invalidate metadata
invalidate metadata全量刷新,性能消耗较大,主要用于hive当中新建数据库或者数据库表的时候来进行刷新
5)explain
- 用于查看sql语句的执行计划
explain select * from default.employee;
explain的值可以设置成0,1,2,3等几个值,其中3级别是最高的,可以打印出最全的信息
set explain_level=3;
6) profile命令:
- 执行sql语句之后执行,可以打印出更加详细的执行步骤
- 主要用于查询结果的查看,集群的调优等
select * from course.score;
profile;
7)注意
- (1) 在hive窗口当中插入的数据或者新建的数据库或者数据库表,在impala当中是不可直接查询到的,需要刷新数据库,使用命令 invalidate metadata;
- (2) 在impala-shell当中插入的数据,在impala当中是可以直接查询到的,不需要刷新数据库,其中使用的就是catalog这个服务的功能实现的,catalog是impala1.2版本之后增加的模块功能,主要作用就是同步impala之间的元数据.
6.3 创建数据库
impala-shell进入到impala的交互窗口
6.3.1 查看所有数据库
show databases;
6.3.2 创建与删除数据库
创建数据库
create database if not exists mydb1;
这里会涉及到在hdfs上无法创建目录权限的问题
(1)关闭文件权限检查: 修改hdfs-site.xml文件添加以下配置
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
(2) 修改文件权限
hdfs dfs -chmod 777 /user/hive/warehouse
删除数据库
drop database if exists mydb1;
6.4 创建表
创建表的语法跟hive一样
内部表:
create table mydb1.student1(id int ,name string ,age int ) row format delimited fields terminated by '\t' ;
外部表:
create external table mydb1.student2(id int ,name string ,age int ) row format delimited fields terminated by '\t' location '/user/hive/warehouse/student2';
6.5 向表中加载数据
insert语句插入数据
insert into student1 values (1, 'zhangsan', 25 );
insert into student1 values (2, 'lisi', 20 );
insert into student1 values (3, 'xiaozhang', 35 );
insert into student1 values (4, 'laowang', 45 );
通过load hdfs的数据到impala表中
# 准备数据student.txt并上传到hdfs的 /impala/data路径下去(注意目录权限)
11 zhangsan1 15
22 zhangsan2 20
33 zhangsan3 30
44 zhangsan4 50
加载数据
load data inpath '/impala/data' into table student1;
使用insert into select 语法
insert into user1 select * from user2;
6.6 查询数据
select * from student1;
6.7 清空表数据
truncate student1;
6.8 删除表数据
drop table student1;
7. impala操作实战
1、在hive中创建一张表
create table access_user(
session_id string,
cookie_id string,
visit_time string,
user_id string,
age int,
sex string,
visit_url string,
visit_os string,
browser_name string,
visit_ip string,
province string,
city string,
page_id string,
goods_id string,
shop_id string
)row format delimited fields terminated by ',';
2、加载数据到hive表中
- 测试数据user50w.csv文件
load data local inpath '/home/hadoop/user50w.csv' into table access_user;
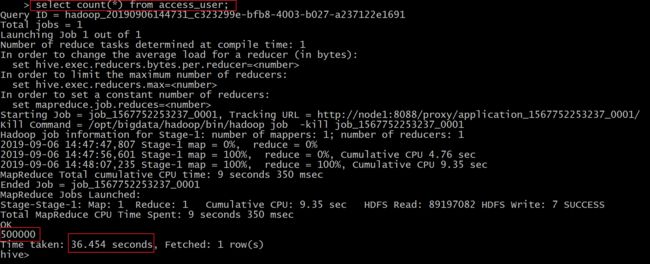
3、hive中执行查询语句
select count(*) from access_user;
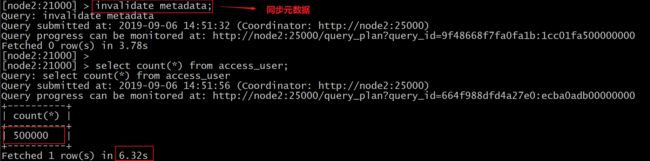
4、impala-shell中同步hive的元数据
invalidate metadata;
5、impala-shell中执行查询语句
select count(*) from access_user;
6、order by语句
- 基础语法
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
Select * from employee ORDER BY id asc;
7、group by语句
select name, sum(salary) from employee group by name;
8、having语句
- 基础语法
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
-- 按年龄对表进行分组,并选择每个组的最大工资,并显示大于20000的工资
select max(salary) from employee group by age having max(salary) > 20000;
9、limit语句
select * from employee order by id limit 4;
10、impala当中的数据表导入几种方式
- 第一种方式,通过load hdfs的数据到impala当中去
create table user(id int ,name string,age int ) row format delimited fields terminated by "\t";
准备数据user.txt并上传到hdfs的 /user/impala路径下去
1 hello 15
2 zhangsan 20
3 lisi 30
4 wangwu 50
加载数据
load data inpath '/user/impala/' into table user;
查询加载的数据
select * from user;
如果查询不不到数据,那么需要刷新一遍数据表
refresh user;
- 第二种方式:
create table user2 as select * from user;
- 第三种方式:
insert into 不推荐使用 因为会产生大量的小文件
千万不要把impala当做一个数据库来使用
- 第四种方式:
insert into select 用的比较多
8. impala的JDBC操作
构建maven工程,添加依赖
<dependency>
<groupId>com.clouderagroupId>
<artifactId>ImpalaJDBC41artifactId>
<version>2.5.42version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-serviceartifactId>
<version>1.2.1version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-jdbcartifactId>
<version>1.2.1version>
<exclusions>
<exclusion>
<groupId>org.apache.hivegroupId>
<artifactId>hive-service-rpcartifactId>
exclusion>
<exclusion>
<groupId>org.apache.hivegroupId>
<artifactId>hive-serviceartifactId>
exclusion>
exclusions>
dependency>
开发代码:
package com.xichuan.dev;
import java.sql.*;
/**
* Created by XiChuan on 2020/4/21.
*/
public class TestImpala {
//impala的url连接地址
private static String url = "jdbc:impala://node2:21050/default";
//数据库连接
private static Connection conn;
private static PreparedStatement ps;
public static void main(String[] args) {
try {
//获取数据库连接
conn = DriverManager.getConnection(url);
//定义查询的sql语句
String sql="select * from mydb1.student1 limit 5";
//预编译sql语句
ps= conn.prepareStatement(sql);
//执行sql查询
ResultSet rs = ps.executeQuery();
while(rs.next()){
String id = rs.getString("id");
String name = rs.getString("name");
String age = rs.getString("age");
System.out.println(id+"\t"+name+"\t"+age+"\t");
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
if(conn!=null){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}