Spark Streaming从Kafka中获取数据,并进行实时单词统计,统计URL出现的次数
1、创建Maven项目
创建的过程参考:http://blog.csdn.net/tototuzuoquan/article/details/74571374
2、启动Kafka
A:安装kafka集群:http://blog.csdn.net/tototuzuoquan/article/details/73430874
B:创建topic等:http://blog.csdn.net/tototuzuoquan/article/details/73430874
3、编写Pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>cn.toto.sparkgroupId>
<artifactId>bigdataartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>1.7maven.compiler.source>
<maven.compiler.target>1.7maven.compiler.target>
<encoding>UTF-8encoding>
<scala.version>2.10.6scala.version>
<spark.version>1.6.2spark.version>
<hadoop.version>2.6.4hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-compilerartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-reflectartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.38version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-flume_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka_2.10artifactId>
<version>${spark.version}version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/scalasourceDirectory>
<testSourceDirectory>src/test/scalatestSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.mavengroupId>
<artifactId>scala-maven-pluginartifactId>
<version>3.2.2version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
<configuration>
<args>
<arg>-make:transitivearg>
<arg>-dependencyfilearg>
<arg>${project.build.directory}/.scala_dependenciesarg>
args>
configuration>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-surefire-pluginartifactId>
<version>2.18.1version>
<configuration>
<useFile>falseuseFile>
<disableXmlReport>truedisableXmlReport>
<includes>
<include>**/*Test.*include>
<include>**/*Suite.*include>
includes>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-shade-pluginartifactId>
<version>2.4.3version>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>shadegoal>
goals>
<configuration>
<filters>
<filter>
<artifact>*:*artifact>
<excludes>
<exclude>META-INF/*.SFexclude>
<exclude>META-INF/*.DSAexclude>
<exclude>META-INF/*.RSAexclude>
excludes>
filter>
filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.toto.spark.FlumeStreamingWordCountmainClass>
transformer>
transformers>
configuration>
execution>
executions>
plugin>
plugins>
build>
project>4.编写代码
package cn.toto.spark
import cn.toto.spark.streams.LoggerLevels
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by toto on 2017/7/13.
* 从kafka中读数据,并且进行单词数量的计算
*/
object KafkaWordCount {
/**
* String :单词
* Seq[Int] :单词在当前批次出现的次数
* Option[Int] :历史结果
*/
val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(i => (x, i)) }
}
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
//这里的args从IDEA中传入,在Program arguments中填写如下内容:
//参数用一个数组来接收:
//zkQuorum :zookeeper集群的
//group :组
//topic :kafka的组
//numThreads :线程数量
//hadoop11:2181,hadoop12:2181,hadoop13:2181 g1 wordcount 1 要注意的是要创建line这个topic
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf,Seconds(5))
ssc.checkpoint("E:\\wordcount\\outcheckpoint")
//"alog-2016-04-16,alog-2016-04-17,alog-2016-04-18"
//"Array((alog-2016-04-16, 2), (alog-2016-04-17, 2), (alog-2016-04-18, 2))"
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//保存到内存和磁盘,并且进行序列化
val data: ReceiverInputDStream[(String, String)] =
KafkaUtils.createStream(ssc, zkQuorum, group, topicMap, StorageLevel.MEMORY_AND_DISK_SER)
//从kafka中写数据其实也是(key,value)形式的,这里的_._2就是value
val words = data.map(_._2).flatMap(_.split(" "))
val wordCounts = words.map((_, 1)).updateStateByKey(updateFunc,
new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}5.配置IDEA中运行的参数:
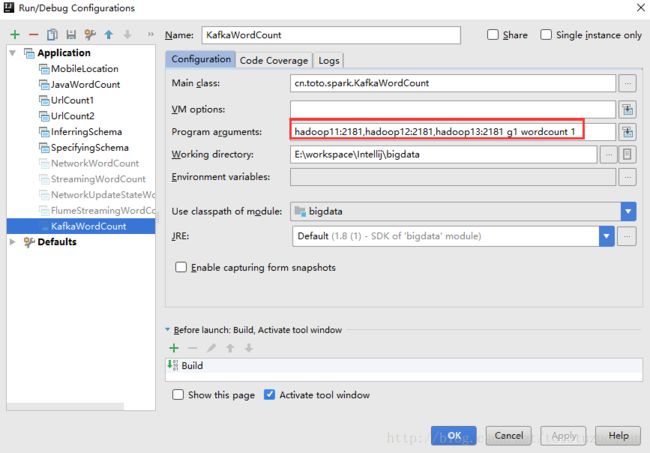
配置说明:
hadoop11:2181,hadoop12:2181,hadoop13:2181 g1 wordcount 1
hadoop11:2181,hadoop12:2181,hadoop13:2181 :zookeeper集群地址
g1 :组
wordcount :kafka的topic
1 :线程数为16、创建kafka,并在kafka中传递参数
启动kafka
[root@hadoop1 kafka]# pwd
/home/tuzq/software/kafka/servers/kafka
[root@hadoop1 kafka]# bin/kafka-server-start.sh config/server.properties 1>/dev/null 2>&1 &创建topic
[root@hadoop1 kafka]# bin/kafka-topics.sh --create --zookeeper hadoop11:2181 --replication-factor 1 --partitions 1 --topic wordcount
Created topic "wordcount".查看主题
bin/kafka-topics.sh --list --zookeeper hadoop11:2181启动一个生产者发送消息(我的kafka在hadoop1,hadoop2,hadoop3这几台机器上)
[root@hadoop1 kafka]# bin/kafka-console-producer.sh --broker-list hadoop1:9092 --topic wordcount
No safe wading in an unknown water
Anger begins with folly,and ends in repentance
No safe wading in an unknown water
Anger begins with folly,and ends in repentance
Anger begins with folly,and ends in repentance使用spark-submit来运行程序
#启动spark-streaming应用程序
bin/spark-submit --class cn.toto.spark.KafkaWordCount /root/streaming-1.0.jar hadoop11:2181 group1 wordcount 17、查看运行结果
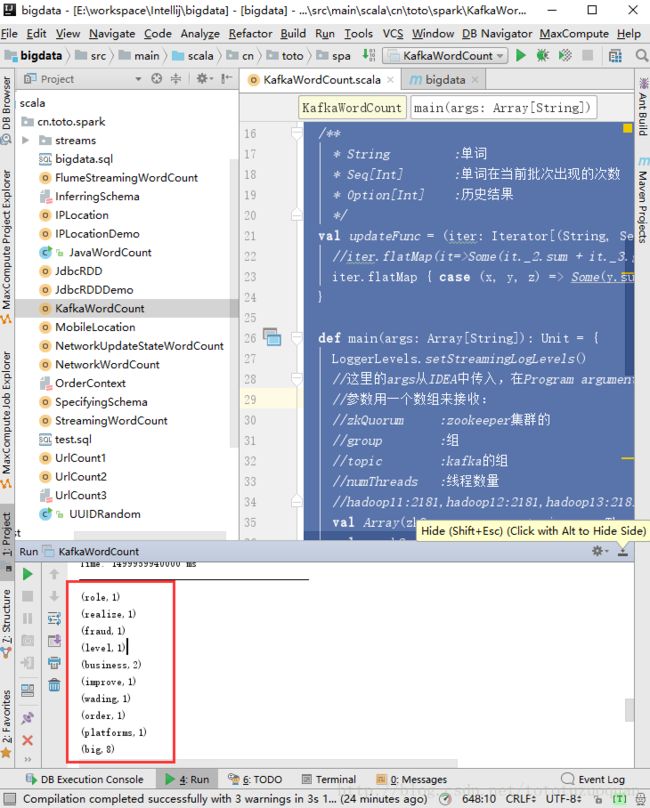
8、再如统计URL出现的次数
package cn.toto.spark
import org.apache.spark.{HashPartitioner, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Created by toto on 2017/7/14.
*/
object UrlCount {
val updateFunc = (iterator: Iterator[(String, Seq[Int], Option[Int])]) => {
iterator.flatMap{case(x,y,z)=> Some(y.sum + z.getOrElse(0)).map(n=>(x, n))}
}
def main(args: Array[String]) {
//接收命令行中的参数
val Array(zkQuorum, groupId, topics, numThreads, hdfs) = args
//创建SparkConf并设置AppName
val conf = new SparkConf().setAppName("UrlCount")
//创建StreamingContext
val ssc = new StreamingContext(conf, Seconds(2))
//设置检查点
ssc.checkpoint(hdfs)
//设置topic信息
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//重Kafka中拉取数据创建DStream
val lines = KafkaUtils.createStream(ssc, zkQuorum ,groupId, topicMap, StorageLevel.MEMORY_AND_DISK).map(_._2)
//切分数据,截取用户点击的url
val urls = lines.map(x=>(x.split(" ")(6), 1))
//统计URL点击量
val result = urls.updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
//将结果打印到控制台
result.print()
ssc.start()
ssc.awaitTermination()
}
}