图像识别(一): 深度学习TensorFlow框架+神经网络 VS 机器学习SKlearn+随机森林RandomForestClassifier
正在学习TensorFlow2.0,为了更好的理解数据建模分类问题,对比不同算法的差异和原理,利用入门级的图像识别案例,尝试对比传统机器学习的建模效果。
1.导入需要的包
将需要的包全部导入,这里部分包在此案例中没有用到,懒的删了,实际项目中最好不要导入多余包。
import tensorflow as tf
import pandas as pd
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import pickle
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split,KFold
from sklearn.metrics import *
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
2.导入数据集
这里使用Fashion MNIST数据集,获取数据集代码如下,共60000训练集,10000测试集,每张图片是28*28的像素。
(train_images, train_labels), (test_images, test_labels) = keras.datasets.fashion_mnist.load_data()
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
print(train_images.shape)
print(train_labels.shape)
print(test_images.shape)
print(test_labels.shape)
--
(60000, 28, 28)
(60000,)
(10000, 28, 28)
(10000,)
3.数据处理
看一下数据集里的原始图片。
for i in range(1):
n=train_labels[i]
name =class_names[n]
plt.figure()
plt.imshow(train_images[i])
plt.colorbar()
plt.grid(False)
plt.title(name)
plt.show()
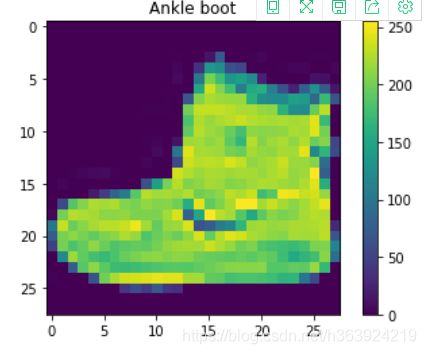
看一下前10个,灰度处理。
train_images = train_images / 255.0
test_images = test_images / 255.0
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
#plt.imshow(train_images[i])
plt.xlabel(class_names[train_labels[i]])
plt.show()

4.利用keras构建神经网络模型
构建一个输入层,四个隐藏层,一个全连接层;测试了添加不同个隐层,隐层个数越多训练准确度越高,但要防止过拟合。
model = keras.Sequential(
[
layers.Flatten(input_shape=[28, 28]),
layers.Dense(256, activation='relu'),
layers.Dense(32, activation='relu'),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
先后测试了迭代次数,当前训练集,迭代20次以上会逐渐稳定,这里没有进行详细调参,为了运行效率,迭代次数暂定为10,模型训练准确率达到90%以上。
model.fit(train_images, train_labels, epochs=10)

5.基于神经网络模型验证
预测并可视化
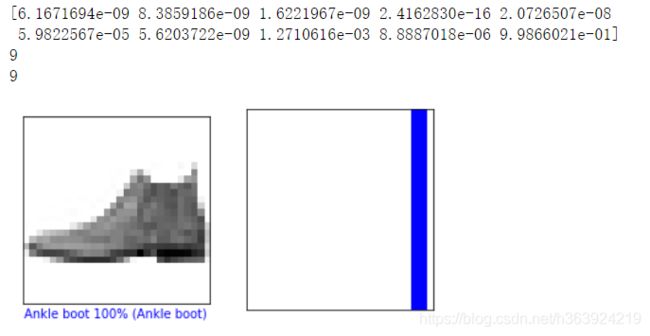
predictions = model.predict(test_images)
print(predictions[0])
print(np.argmax(predictions[0]))
print(test_labels[0])
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()
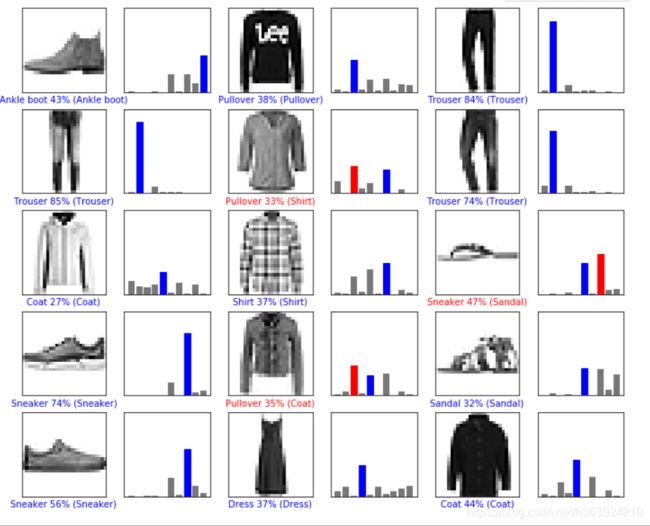
# 可视化结果
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()

上图可知,验证30张图片中有一张预测错误,运动鞋预测成了凉鞋,Sandal 95%Sneaker,这两个确实很像。
下面是测试单个样本预测结果,得分最高的为Ankle boot。
img = test_images[0]
img = (np.expand_dims(img,0))
print(img.shape)
predictions_single = model.predict(img)
print(predictions_single)
plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)

至此,深度学习的模型构建完毕,下面用传统机器学习模型试一下。
6.处理成二维数据
将原来的600002828的数据集,转换为60000*784的二维矩阵。
(train_images, train_labels), (test_images, test_labels) = keras.datasets.fashion_mnist.load_data()
train_images = train_images / 255.0
test_images = test_images / 255.0
train_images2=train_images.reshape(train_images.shape[0],train_images.shape[1]*train_images.shape[2])
train_images2.shape
----
(60000, 784)
由于将28*28图片转换成数组,特征输入相当于是784纬,尝试进行模型训练,在我的小笔记上完全跑不出来,没办法,这里只取了前1000张图片进行训练。
train_images2=train_images2[0:1000]
train_labels=train_labels[0:1000]
7.构造随机森林模型
构建模型代码
def model_RandomForest(Xtrain,Ytrain,is_optimize=1):
"""
训练随机森林
"""
RandomForest = RandomForestClassifier()
if is_optimize==1:
param_grid_Log_RegRandomForest = [{"n_estimators":list(range(50,100,10)),"max_depth":list(range(3,10)),"min_samples_split":list(range(100,500,50))}]
score = make_scorer(accuracy_score)
RandomForest = GridSearchCV(RandomForest,param_grid_Log_RegRandomForest,score,cv=3)
RandomForest = RandomForest.fit(train_images2, train_labels)
return RandomForest
def trainmodel_RF(x_train_stand,y_train):
"""
目的:训练模型,随机森林
x_train_stand:训练集输入,
y_train:训练集标签,与输入相对应
"""
#训练模型
print("随机森林训练中")
RandomForest = model_RandomForest(trainmodel_RF, train_labels)
with open("RandomForestModel50.pickle","wb") as pickle_file:
pickle.dump(RandomForest,pickle_file) #随机森林的拟合模型
Str = "随机森林训练完成"
return print(Str)
开始执行训练,1000张图片大概10分钟左右,比TensorFlow慢多了(5次迭代1分钟左右,准确率达0.9),如果训练原始60000张图片,时间上大家可以想象一下。
trainmodel_RF(train_images2,train_labels)
8.验证随机森林模型效果
首先,转换测试集为矩阵。
test_images2=test_images.reshape(test_images.shape[0],test_images.shape[1]*test_images.shape[2])
test_images2.shape
--------
(10000, 784)
载入模型
with open("RandomForestModel50.pickle","rb") as pickle_file:
RandomForest = pickle.load(pickle_file) #随机森林的拟合模型
预测结果,这里要用predict_proba方法。
#RandomForest.predict(test_images2)
RandomForest.predict_proba(test_images2)[0]
----
array([0.00687536, 0.001 , 0.00407277, 0.01328021, 0.00239895,
0.21373124, 0.00681082, 0.2150638 , 0.10346379, 0.43330307])
打印准确率,准确率0.742(已经很不错了,我们只是用了区区1000张图片进行训练,TensorFlow可是用了60000张图片)
print("随机森林准确率: {:.3f}".format(accuracy_score(test_labels,RandomForest.predict(test_images2))))
---
随机森林准确率: 0.742
可视化效果
predictions_pro=RandomForest.predict_proba(test_images2)
# 可视化结果
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions_pro, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions_pro, test_labels)
plt.show()
可视化30张图片中,有3张预测错误,只训练1000张图片的情况下,对比TensorFlow已经相当不错了,但运行效率确实不敢恭维。
9.总结
对比了深度学习算法和传统机器学习算法,但不管是什么目的都是一样的,脱离不了“分类”这个范围;使用TensorFlow构建神经网络模型相对简单,模型构建效率也很高,而使用集成学习模型,需要将图片转换为二维矩阵,28*28的图片相当于给随机森林模型输入了784个特征,这样造成模型效率很低。
总结来说,对于图像识别此类的问题,还是借助用深度学习框架构建神经网络模型;但是如果在数据搜集难度大的项目,样本量比较小,对于分类问题集成学习模型的效果也不会太差,实际项目中根据具体场景进行合理选择。