【三等奖方案】小样本数据分类任务赛题「复兴15号」团队解题思路
第十届CCF大数据与计算智能大赛(2022 CCF BDCI)已圆满结束。大赛官方竞赛平台DataFountain(简称DF平台)将陆续释出各赛题获奖队伍的方案思路。
本方案为【小样本数据分类任务】赛题的三等奖获奖方案,赛题地址:https://datafountain.cn/competitions/582

获奖团队简介
团队名称:复兴15号
团队成员:我们是中国科学技术信息研究所的专利挖掘团队,本次参赛成员包括2名指导老师和5名队员,队员以硕士研究生为主。我们希望和企业界一道,来发现行业真问题、解决用户真痛点,让人工智能深度赋能专利行业,去创造更为广阔的价值空间。
所获奖项:三等奖
摘要
专利分类是专利信息处理的一项基础任务,在案源分配、专利分析、智能标注中具有重要用途。然而专利分类所依赖的标注资源成本高昂,如何在小样本标注资源的条件下提升专利自动分类效果,则彰显出重要的研究价值和广阔的应用前景。对此,我们提出一套可用于小样本专利分类的multi-Bert两阶段微调方法。在该方法中,不同类型的专利信息,如IPC编码和专利文本,被输入不同的Bert中完成特征提取、拼接、微调和预测;同时针对训练样本中存在类别不平衡现象,我们设计了一套两阶段预训练模型微调策略,即第一阶段对全部类别标签进行数据增强并进行模型微调,第二阶段针对少样本标签进行数据增强,并在前面模型微调基础上继续微调;此外,我们提出一种不再划分训练集、验证集而是利用全量训练集进行微调而用train loss作为模型保存条件的微调方法。实验证明,该方法可以有效提升预训练模型在小样本专利分类上的效果。
关键词
小样本分类、预训练模型、专利分类、数据增强
引言
1.1 任务介绍
专利分类体系是支持专利业务开展的基础设施,然而常见专利分类体系如IPC、CPC、USPC、F-Index、德温特手工编码等体系结构复杂、专业性强,对非知识产权专业人士而言在使用过程中有一定困难。对此,智慧芽综合用户搜索习惯等多种因素,制定了一套新的专利分类体系,以提升用户使用体验。
基于这套专利分类体系,比赛方将专利划分为 36 类,并对分类标签进行脱敏处理,要求参赛者根据比赛方提供的958条标注数据,提出一套算法,对测试集的类别进行单标签预测。在每条标注数据中,共有五个字段,即专利的脱敏 ID、标题、摘要、专利权人和分类脱敏标签,其中文本字段均为中文。不难看出,本次比赛任务是一个典型的小样本数据分类任务。
1.2 解题思路
本任务涉及两个要点,其一是专利数据,其二是小样本分类。小样本分类是件十分困难的任务,但具体到专利数据上,又有很多细节可以挖掘,比如专利信息中包含着丰富的题录字段、文本内容、引文信息以及图片说明,这些为提升小样本分类的效果提供了丰富的素材,再比如当前网上公开可获取的专利资源日趋丰富,包括专利原始数据集、专利标注数据、专利数据处理代码,甚至 bert-for-patents[1]这种高性能预训练模型也屡见不鲜。
在具体方法构建上,通过归纳训练集中各个标签下的样本内容,我们注意到比赛方所划分的 36 个类别倾向于按照技术领域划分。而专利本身具有丰富的技术领域或功能、应用分类标签,比如 IPC、CPC、USPC、德温特手工编码等,如何充分发挥这些标签的作用,将在本次比赛中起到至关重要的作用。为此,我们基于比赛平台交流讨论区公开的中国专利数据集,做了两件事情:
(1) 将该数据集的 IPC 分类字段抽取出来,并按照 IPC 五层拆分后形成字符串集合,并基于此集合进行词表构建和重头训练预训练模型,最终形成针对 IPC 编码的预训练模型;
(2) 以该数据集作为数据来源,为比赛方提供的训练集、测试集补充 IPC 字段,这里,我们根据专利的文本相似性,搜索出与训练集、测试集中专利最相近的外部专利,将其 IPC 补充到训练集和测试集中。
在模型选择上,由于预训练模型本身具有一定的小样本学习能力,外加本次比赛的分类标签不予公开,使用prompt方法存在一定困难,因此我们决定以预训练模型作为主要模型,通过微调-预测进行小样本数据分类。每个专利样本包括两类信息,其一是由标题、摘要、专利权人所组成的文本信息,其二是 IPC 标签信息,这两类信息分别交给两个预训练模型来处理,将这两类信息转化为向量表示后拼接起来,通过dropout处理后输入全连接层并反向推导,以此完成两个预训练模型的融合。
此外,伪标签也是小样本分类重要的提分点,因此我们需要对测试集多次预测并取多次预测结果中标签一致的专利样本及其预测标签作为伪标签;同时我们注意到比赛方提供的训练集存在严重的样本不平衡现象,而少样本标签存在训练不充分的现象,因此我们针对这些少样本标签再次形成伪标签,最终得到两类伪标签数据集作为增强数据。
方法
2.1 方法概述
基于上述思路,我们形成方法的总体流程如图 1 所示。在该流程中共包括四个步骤,即(1)为训练集和测试集补充IPC字段;(2)多次对测试集进行预测并形成伪标签,以实现数据增强;(3)在对全部类别标签和少样本类别标签进行数据增强后,分两阶段进行预训练模型微调;(4)对最终测试集进行标签预测。
虽然总体流程已经梳理清楚,但在具体方法实现层面上,仍然有三个问题需要解决,包括补充数据源的问题、增强数据的产生策略如何选择和预训练模型如何选择、优化、集成。对此,我们进行了大量文献调研和实证分析,并形成了应对方案如下:
问题一: 补充数据源如何选择?
当前互联网上开源了大量专利原始数据集和标注数据集,这为将深度学习技术应用于专利服务提供的必要的基础设施,比如 NTCIR(日本国立信息学研究所信息检索系统测试数据集项目)的第 3-8 期评测活动中发布了面向专利的信息检索、技术分类、数据挖掘和自动翻译任务及其相关数据集[2];TREC-CHEM(文本检索会议的化学信息检索研讨会)自 2009 年至 2011 年先后构建了三个化学专利数据集[3],供化学领域的技术调查、现有技术搜索、化学图像识别等任务的技术评测使用,我们罗列了一部分数据集,见附录一。
但当我们调研这些数据集后发现,它们以英文、德文、日文、法文为主,不仅中文专利极度稀缺,且专利权人来自中国的专利占比较小,而随机抽样显示比赛方提供的专利数据中,专利权人来自中国的情况占比为80.5%,因此我们选用比赛平台交流社区公开的中国专利数据集作为补充数据来源。通过相似度计算,获取与测试集、训练集最相似的专利记录,并将其 IPC 字段补充到测试集、训练集中。

图 1 总体流程图
问题二: 增强数据的产生策略如何选择?
通过统计训练集中各个分类标签下的样本分布情况如图2所示,我们注意到该训练集存在严重的样本不平衡问题,而测评指标使用的是 Macro-Average F1-value,也就是说,在计算最终得分时,不同标签处于对等地位。所以除了对全部分类标签进行数据增强外,我们需要专门对训练不充分的少样本标签进行数据增强。

图 2 训练集中各类标签下的样本分布
问题三:预训练模型如何选择、优化和集成?
专利语料和通用语料如新闻、百科相比特点突出,比如专利文本句子较长、句式复杂、包含较多科学概念、技术术语,这些科学概念、技术术语之间语义关系类型多样。这使得如果将深度学习应用于专利数据实现好的技术效果,就必须利用专利语料重新生成词嵌入向量,例如 Risch 等[4]利用基于专利语料的静态词嵌入,即 fastText 替代通用词嵌入向量后,在 IPC 分类准确率上取得了 17%的提升;而我们团队在之前文章中也验证了使用基于专利文本的词嵌入可以显著提升专利文本上命名实体识别与语义关系抽取的模型效果[5]。
因此我们利用比赛平台交流社区公开的中国专利数据集,重新创建词表和从头训练 Bert,但在分类效果甚至达不到使用同样特征的bert-base-chinese (详见表1),原因经分析是该中国专利数据集包含专利约 280 万件,不满足从头训练预训练模型所要求的语料体量,更适合的使用方式是在 bert-base-chinese 基础上利用这批专利数据继续训练,使之适应专利文本的领域特点。实验结果显示继续训练后分类效果的线上得分为 0.56,较之前取得了约5个百分点的提升;进一步将专利翻译成英文并使用Bert-for-patents进行微调和预测,在没有使用任何trick的情况下线上得分为0.59,较之前有大幅提升。这让我们意识到谷歌基于 1 亿条专利全文数据训练的 Bert 的强大之处,也让我们下定决心以Bert-for-patents为主要模型进行专利分类。
此外,我们从比赛平台交流社区公开的中国专利数据集中采集了大量的IPC标签信息,这让我们可以基于这些标签信息创建词表并训练一个使用 IPC组合作为文本内容的定制化Bert;不仅如此,由于IPC具有部、大类、小类、大组、小组五级层次结构,而每一级代表不同技术领域的概括层次,为发掘不同层次技术领域信息在专利分类上的作用,我们将前述IPC标签按照5级拆分,例如某专利的IPC号码为H04L27/26和 H04L5/00,它对应的IPC字符串就是“H H04 H04L H04L27 H04L2726 H H04 H04L H04L5 H04L500”,这些字符串最终形成 IPC-Bert 的训练语料。至于将Bert-for-patents和IPC-Bert进行模型集成,我们把由Bert-for-patents和IPC-Bert输出的专利文本和IPC组合表示向量进行拼接,并使它通过dropout和全连接层进行反向传播,以此完成对模型的集成。
2.2 方法实现
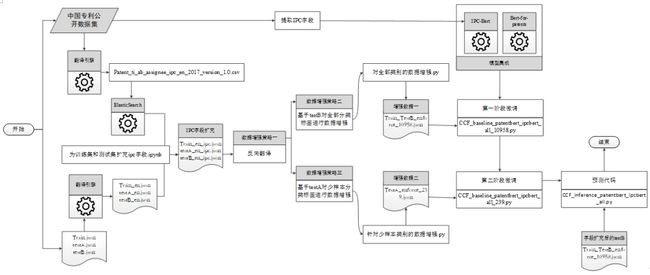
图 3 方法实现的具体流程图
方法实现的具体流程详见图 3,具体包括:
(1) 专利翻译
专利翻译的目标是将比赛方提供的中文专利数据翻译为英文,从而可以使用Bert-for-patents进行微调和预测;同时我们将中国专利数据集外部数据也翻译为英文,为后续通过相似度计算向训练集、测试集补充数据和从外部数据集中提炼主题词表、本体库等提供必要条件。翻译工作采用了我单位自研的科技大数据翻译引擎,由于该翻译引擎采用分布式架构,因此可以在40个小时内完成对全部专利数据的翻译任务。
(2) 字段扩充
为扩充训练集和测试集的专利字段,我们将翻译后的中国专利数据集外部数据导入ElasticSearch搜索引擎中,进而以标题和摘要字段作为检索项,通过专利检索,将相关度最高的结果作为数据来源,对训练集和测试集进行字段扩充。
(3) 数据增强
我们采用了两种数据增强方式,其一是反向翻译,即通过英文→中文→英文的转换过程实现专利文本改写,以提升模型的泛化能力;其二是生成伪标签,即将多次预测结果进行统计,从中抽取出预测结果一致的专利样本,以其预测结果作为该专利样本的标签,从而扩充训练集。我们注意到训练集中36类标签下的样本分布存在明显的不平衡现象,尤其xx,因此我们生成了两个伪标签数据集,其一是对B榜数据集进行8次预测,其中预测结果始终一致的专利样本为13077条,为减少模型微调时间,我们从中随机抽取10000条,并与训练集的958条样本相结合,形成对全部36类标签进行增强的增强数据集一;其二是对A榜进行36次预测,选取阈值34,筛选出239条专利记录形成增强数据二,对少样本标签12,13,14,17,21,22,27,28,29,31,32,35共12个类别进行数据增强。
(4) 模型微调和预测
这部分包括三方面内容:① 根据上一步骤所形成两个伪标签数据集,我们设计了一个两阶段策略对预训练模型进行微调,即首先使用10958条增强数据对包含全部标签的专利样本进行微调,并在此微调后模型的基础上使用239条增强数据继续训练,以提升对少样本标签的预测能力;② 在IPC-bert和Bert-for-patents集成上,我们将由这两个Bert输出的向量拼接起来,并辅以 Dropout和全连接层操作,来实现多个Bert的集成;③ 将比赛方提供的958条标注样本划分为训练集和验证集,分别用于模型的训练和验证。值得一提的是第三方面的工作,最初我们将这些标注样本按照一定比例,例如 8:2 随机划分为训练集和验证集,但很快发现由于训练样本过少、训练不充分,模型效果受数据集划分的随机性影响太大,以致无法辨别线上得分的提升究竟是模型本身得到优化还是这次数据集划分的效果好;因此我们使用K-fold策略进行数据集划分,即随机将数据集划分为K等份,按顺序依次选取每一份作为验证集,其余作为训练集,从而得到K个版本的训练集-验证集划分,微调后共得到K个版本的模型,并从中选取验证集得分较高的模型,作为最终模型进行测试集标签预测。
但很快我们发现同一模型的线上和线下表现并不一致,线下表现优异的模型,线上得分可能最差,为此,我们收集了18次线上、线下得分形成对照组,并进行了相关分析和假设检验如图 4 所示。结果显示在线上、线下得分显著相关的假设检验中,P值为 0.000223,线上、线下得分的相关系数为-0.38106,这说明偶然因素导致线上、线下存在分差的概率相当,线上、线下得分的相关性较弱。

图 4 线上线下得分的相关性分析
基于上述分析,我们放弃了K-fold的数据集划分和模型选择策略,进而采取一种比较激进的做法,即不再划分训练集和验证集,而是全部标注数据投入模型训练,训练过程中保存两个版本的模型参数,即 train loss 最小时候的模型参数和训练最后一步的模型参数,在预测中我们加载 train loss 最小时的模型参数。
实验
3.1 数据情况和模型设置
本次实验的原始数据集文件共六个,包括比赛方提供的train.json、testA.json、testB.json 和中国专利公开数据集的三个专利文件。在模型超参数的设置如下:Epoch=40,seed=42,learning_rate=1e-5,min_lr=1e-6,weight_decay=1e-6,Bert-for-patents 的最大输入长度为512,IPC-Bert 的最大输入长度为 150。
3.2 实验结果
在整个参赛过程中,我们尝试的技术方案较多,这里仅列出具有里程碑意义的 20 次实验,具体详情如表 1 所示,从中不难得到五个结论:
(1) 多模型联合可以有效提升小样本的分类效果,例如当将模型 10 的 Bert-for-patents 与 IPC-bert 结合形成模型11 后,线上得分从 0.59 提升至 0.605;
(2) 基于专利的 IPC 共现网络,我们使用图神经网络(包括GCN、Graphsage 等)将专利向量化并将其集成到 Bert 中,相关模型有 6、7、8、9、13,但这种做法的分类效果忽高忽低、并不稳定;
(3) 当不再划分数据集进行微调时,模型的线上得分相比通过 K-fold 策略选出最优模型仅略微下降,比如使用 K-fold 策略的模型 14 得分为 0.61,当不再划分数据集后,得分为 0.604,处于可接受范围之内;
(4) 数据增强是非常重要的提分点,尤其伪标签的引入,极大提升了模型效果。
(5) Label smooth 是一种防止模型训练过拟合的正则化技术,由于本任务中模型复杂而训练数据稀少,极容易出现过拟合问题,因此引入 label smooth 技术可以提升模型的线上得分,但引入伪标签后 label smooth 的效果出现退化,原因经分析后认为是引入伪标签后训练数据得以充实,模型训练面临的主要问题由过拟合转变为欠拟合。综上,对于小样本分类问题,label smooth 技术与基于数据增强的伪标签需要根据模型复杂情况和数据规模进行取舍。
表 1 不同实验方案的结果汇总

3.3 错误分析
除此以外,我们对验证集的输出结果进行了错误分析。所谓错误分析,即将预测结果和真实结果通过对照和人工判读,将预测错误的样本划分到不同类别中,以便输出错误原因,为模型优化提供方向指引。
这部分工作基于混淆矩阵和对分类标签含义解读展开,我们发现存在一些模型很难判断的标签对,比如标签6和12、17和24、18和5、20和28,根据网友对标签含义的解读,这些标签的内容如下:
6: 智能算法、智能系统、无人驾驶、无人机、成像设备;
12:传感器、三维重建、摄像机;
17:锂电池,车辆电池
24:车辆、轨道、列车、车辆组件及装置
18:无机、合成、生物
5:材料、化学、生物
20:药物、合成、生物
28:烧结、锅炉、制药固体废弃物余热回收焚烧炉
从上述加粗字体可见,这些标签的部分内容存在较强的语义关联,从而导致模型难以取得正确的判断结果。我们需要更多的训练数据,或者从多个角度对现有数据展开探索,才能更好描述这些类别的边界,来提升模型的分类效果。
3.4 值得尝试的方案
当前模型从专利本身信息中获取线索,来判断专利类型。除此以外,还有一种思路值得尝试,就是如果两件专利越相似,那么它们属于同一标签类型的可能性就越大。因此,除了专利本身信息以外,我们还可以将专利与专利之间的相似关系结合进来,当某专利的类型难以判断时,可以参考和这个专利相似的其他专利的标签情况,从而得到一个更为全面的类别判断。具体实现时,用 Bert 对专利内容建模、用图神经网络对专利关联网络建模,两者集成后的结构如图 5 所示。
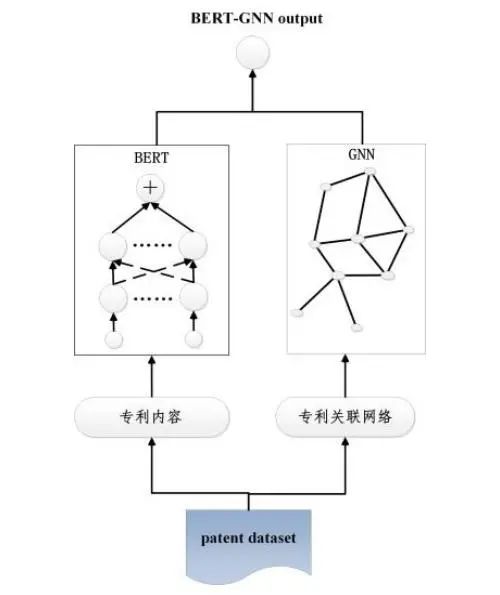
图 5 Bert-GNN 联合模型
总结与前瞻
持续将近三个月的 2022 年小样本数据分类算法竞赛终于快要落下帷幕。在这三个月中,我们尝试了大量算法,各类专利数据也详细摸了一遍,团队成员无论在对各大主流算法的效果、适用范围的认识上还是在对专利数据的理解上,都较之前有大幅提升,这在三个月前是无法想象的,感谢智慧芽和datafountain提供这么好的竞赛平台,我们希望这样的比赛能持续办下去,尤其考虑专利类比赛在当前国内外大小数据竞赛中并不多见的事实和知识产权日益得到国家、企业重视的背景,这样的比赛就格外珍贵和意义深远。
通过本次参赛,我们意识到预训练模型在小样本分类中的巨大优势,同时多bert联合训练、数据增强、label smooth这些trick也在比赛中发挥了巨大作用。当然,就专利中丰富的题录字段、文本信息、引文关系以及说明图片而言,目前开发的专利信息还远远不够,参赛各队更多集中在比赛方提供的标题、摘要、专利权人字段上穷尽各种算法“内卷”,当前算法红利在小样本专利分类任务上的潜力并没完全发挥出来,这也给未来该任务上能取得的性能上限留下了巨大的想象空间,未来值得期待。
虽然比赛马上就要结束,但队员仍然意犹未尽,我们还有不少想法有待验证,有些想法也许能够将当前的小样本专利分类效果提升到一个新的水平,但做这些工作都需要一个前提,就是获取比赛方在测试集上的标注信息,以及 36 类标签的含义。当然,比赛方有自己的考虑我们也完全理解,所以一个退而求其次的办法就是用专利的主 IPC 编码来替换比赛方自定义的类别标签,用一个次优的方案继续小样本专利分类方法的研究。
最后,除了小样本专利分类任务外,人工智能可以在更多的专利核心问题上大展拳脚,比如技术功效矩阵的自动构建、专利的新颖性判断和测度、专利有效性检索中的对比文件查找、专利无效宣告判定中破坏可专利性的证据识别,在这些问题面前,一个团队的力量显得非常渺小,我们希望能够和企业界联合起来,集成各自优势,来发现行业真问题、解决用户真痛点,让人工智能深度赋能专利行业,去创造更为广阔的价值空间。
致谢
致谢智慧芽、datafountain提供的比赛平台,感谢邵林航、沐鑫等老师的组织协调,感谢网友理塘丁真、Ai 兔兔、覃辉、小龙虾丶 cary、闪电_、DF1655601980228、JYH、哈哈的 ls 在比赛平台交流社区和比赛群中的无私分享,这些内容在比赛的特定阶段让我们受益匪浅。
参考
[1] Srebrovic R, Yonamin J. Leveraging the BERT algorithm for Patents with TensorFlow and BigQuery. [EB/OL][2022-11-18].
https://services.google.com/fh/files/blogs/bert_for_patents_white_paper.pdf
[2] NTCIR (NII Testbeds and Community for Information access Research) project[EB/OL][2022-11-18]
http://research.nii.ac.jp/ntcir/index-en.html
[3] Lupu M,Huang J,Zhu J,et al. (2009) TREC-CHEM: large scale chemical information retrieval evaluation at TREC[J]. Acm Sigir Forum, 43(2):63-70.
[4] Risch, J., & Krestel, R. (2019). Domain-specific word embeddings for patent classification. Data Technologies and Applications, 53(1),108–122.
[5] Chen L, Xu S, Zhu L, et al. (2020). A deep learning based method for extracting semantic information from patent documents[J]. Scientometrics, 125(1): 289-312.
我是行业领先的大数据竞赛平台 @DataFountain ,欢迎广大政企校军单位合作办赛,推动优秀数据人才揭榜挂帅!