Spark_Spark JOIN的种类 以及选择依据
参考文章 :
1.Spark join种类(>3种)及join选择依据
https://blog.csdn.net/rlnLo2pNEfx9c/article/details/106066081
Spark 内部JOIN 大致分为以下3种实现方式 :
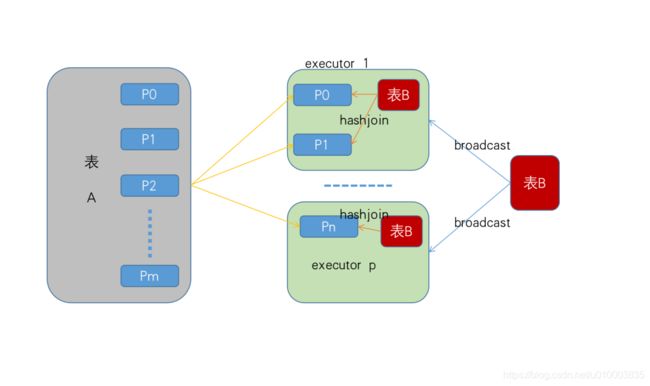
1.BroadCastHashJoin
2.ShuffledHashJoin
3.SortMergeJoin
1.BroadCastHashJoin
翻过源码之后你就会发现,Spark 1.6之前实现BroadCastHashJoin就是利用的Java的HashMap来实现的。大家感兴趣可以去Spark 1.6的源码里搜索BroadCastHashJoin,HashedRelation,探查一下源码。
具体实现就是driver端根据表的统计信息,当发现一张小表达到广播条件的时候,就会将小表collect到driver端,然后构建一个HashedRelation,然后广播。
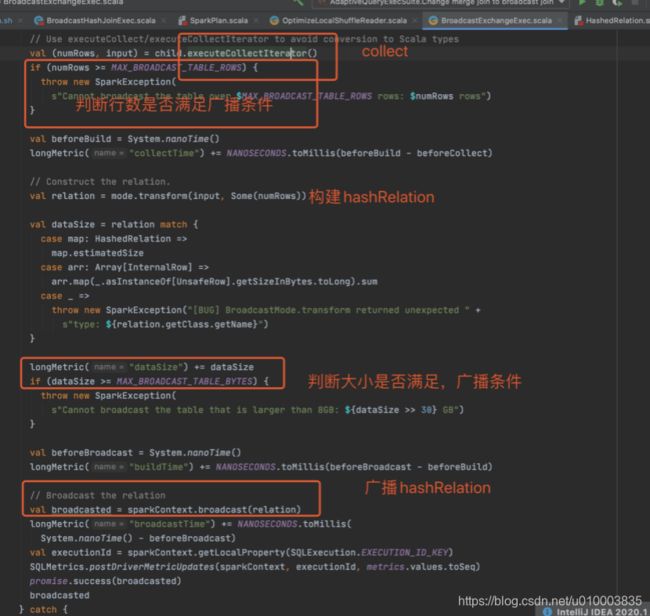
其实,就跟我们在使用Spark Streaming的时候广播hashmap一样。
重点强调里面 最大行数限制 和 最大bytes限制 并不是我们设置的自动广播参数限制,而是内部存储结构的限制。
2.ShuffledHashJoin
BroadCastHashJoin适合的是大表和小表的join策略,将整个小表广播。很多时候,参与join的表本身都不适合广播,也不适合放入内存,但是按照一定分区拆开后就可以放入内存构建为HashRelation。这个就是分治思想了,将两张表按照相同的hash分区器及分区数进行,对join条件进行分区,那么需要join的key就会落入相同的分区里,然后就可以利用本地join的策略来进行join了
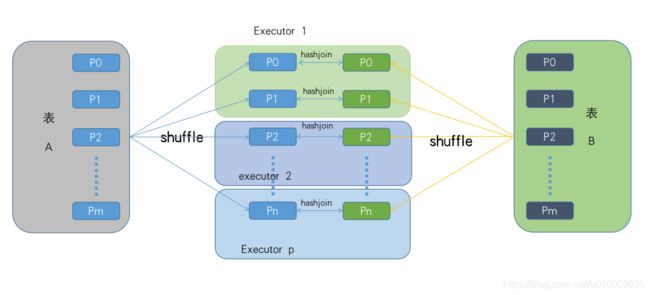
也即是ShuffledHashJoin有两个重要步骤:
- join的两张表有一张是相对小表,经过拆分后可以实现本地join。
- 相同的分区器及分区数,按照joinkey进行分区,这样约束后joinkey范围就限制在相同的分区中,不依赖其他分区完成join。
- 对小表分区构建一个HashRelation。然后就可以完成本地hashedjoin了,参考ShuffleHashJoinExec代码。
这个如下图:

3.SortMergeJoin
上面两张情况都是小表本身适合放入内存或者中表经过分区治理后适合放入内存,来完成本地化hashedjoin,小表数据放在内存中,很奢侈的,所以经常会遇到join,就oom。小表,中表都是依据内存说的,你内存无限,那是最好。
那么,大表和大表join怎么办?这时候就可以利用SortMergeJoin来完成。
SortMergeJoin基本过程如下:
- 首先采取相同的分区器及分区数对两张表进行重分区操作,保证两张表相同的key落到相同的分区。
- 对于单个分区节点两个表的数据,分别进行按照key排序。
- 对排好序的两张分区表数据执行join操作。join操作很简单,分别遍历两个有序序列,碰到相同join key就merge输出,否则取更小一边。
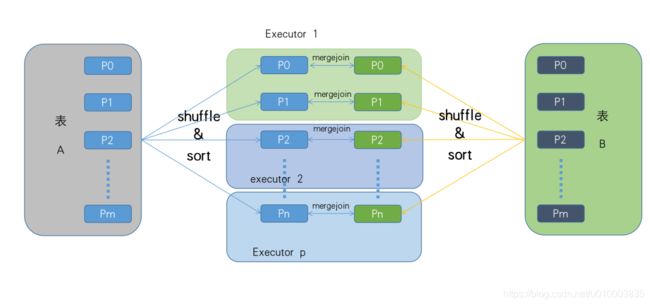
4.Spark 中 JOIN 策略的选择
1) Spark 3.1 +, 基于Hint
假如用户使用Spark SQL的适合用了hints,那Spark会先采用Hints提示的join方式。
BroadcastHashJoin
hints写法如下:
-- 支持 BROADCAST, BROADCASTJOIN and MAPJOIN 来表达 broadcast hint
SELECT /*+ BROADCAST(r) */ * FROM records r JOIN src s ON r.key = s.key
ShuffledHashJoin
hints的sql写法如下:
-- 支持 SHUFFLE_MERGE, MERGE and MERGEJOIN 来表达 SortMergeJoin hint
SELECT /*+ MERGEJOIN(r) */ * FROM records r JOIN src s ON r.key = s.key
SortMergeJoin
hints的SQL写法如下:
-- 支持 SHUFFLE_MERGE, MERGE and MERGEJOIN 来表达 SortMergeJoin hint
SELECT /*+ MERGEJOIN(r) */ * FROM records r JOIN src s ON r.key = s.key
2) 未使用Hint
默认判断规则如下
Step1
1.先判断,假设join的表统计信息现实,一张表大小大于0,且小于等于用户配置的自动广播阈值则,采用广播。
plan.stats.sizeInBytes >= 0 && plan.stats.sizeInBytes <= conf.autoBroadcastJoinThreshold参数:spark.sql.autoBroadcastJoinThreshold
假设两张表都满足广播需求,选最小的。
Step2
2.不满足广播就判断是否满足ShuffledHashJoin,首先下面参数要设置为false,默认为true。
spark.sql.join.preferSortMergeJoin=true
还有两个条件,根据统计信息,表的bytes是广播的阈值*总并行度:
i
plan.stats.sizeInBytes < conf.autoBroadcastJoinThreshold * conf.numShufflePartitions
ii
并且该表bytes乘以3 要小于等于另一张表的bytes:
a.stats.sizeInBytes * 3 <= b.stats.sizeInBytes
那么这张表就适合分治之后,作为每个分区构建本地hashtable的表。
Step3
3.不满足广播,也不满足ShuffledHashJoin,就判断是否满足SortMergeJoin。条件很简单,那就是key要支持可排序。
def createSortMergeJoin() = {
if (RowOrdering.isOrderable(leftKeys)) {
Some(Seq(
joins.SortMergeJoinExec(
leftKeys
, rightKeys
, joinType
, condition
, planLater(left)
, planLater(right))))
} else {
None
}
}
这段代码是在SparkStrageties类,JoinSelection单例类内部。
createBroadcastHashJoin(hintToBroadcastLeft(hint), hintToBroadcastRight(hint))
.orElse {
if (hintToSortMergeJoin(hint)) createSortMergeJoin()
else None
}
.orElse(createShuffleHashJoin(hintToShuffleHashLeft(hint), hintToShuffleHashRight(hint))) .orElse {
if (hintToShuffleReplicateNL(hint)) createCartesianProduct()
else None
}
.getOrElse(createJoinWithoutHint())
5.Spark 中 JOIN 策略对于等值和非等值连接的支持
当然,这三种join都是等值join,之前的版本Spark仅仅支持等值join但是不支持非等值join,常见的业务开发中确实存在非等值join的情况,spark目前支持非等值join的实现有以下两种,由于实现问题,确实很容易oom。
Broadcast nested loop joinShuffle-and-replicate nested loop join。
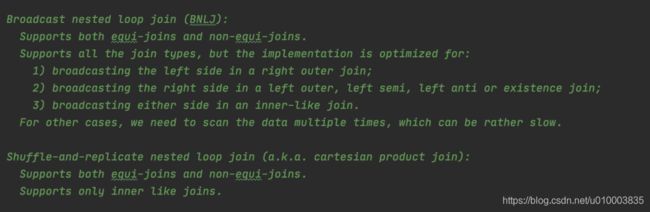
6.测试代码 基于Spark 2.2.0
我们写了一段代码用来测试如何进行策略的选择
package com.spark.test.offline.spark_sql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
/**
* Created by szh on 2020/6/7.
*/
object SparkSQLStrategy {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf
sparkConf
.setAppName("Union data test")
.setMaster("local[1]")
.set("spark.sql.autoBroadcastJoinThreshold", "1048576")
.set("spark.sql.shuffle.partitions", "10")
.set("spark.sql.join.preferSortMergeJoin", "false")
val spark = SparkSession.builder()
.config(sparkConf)
.getOrCreate()
val sparkContext = spark.sparkContext
sparkContext.setLogLevel("WARN")
val arrayA = Array(
(1, "mm")
, (2, "cs")
, (3, "cc")
, (4, "px")
, (5, "kk")
)
val rddA = sparkContext
.parallelize(arrayA)
val rddADF = spark.createDataFrame(rddA).toDF("uid", "name")
rddADF.createOrReplaceTempView("userA")
spark.sql("CACHE TABLE userA")
//--------------------------
//--------------------------
val arrayB = new ArrayBuffer[(Int, String)]()
val nameArr = Array[String]("sun", "zhen", "hua", "kk", "cc")
//1000000
for (i <- 1 to 1000000) {
val id = i
val name = nameArr(Random.nextInt(5))
arrayB.+=((id, name))
}
val rddB = sparkContext.parallelize(arrayB)
val rddBDF = spark.createDataFrame(rddB).toDF("uid", "name")
rddBDF.createOrReplaceTempView("userB")
val arrListA = new ArrayBuffer[(Int, Int)]
for (i <- 1 to 40) {
val id = i
val salary = Random.nextInt(100)
arrListA.+=((id, salary))
}
spark
.createDataFrame(arrListA).toDF("uid", "salary")
.createOrReplaceTempView("listA")
val arrList = new ArrayBuffer[(Int, Int)]
for (i <- 1 to 4000000) {
val id = i
val salary = Random.nextInt(100)
arrList.+=((id, salary))
}
spark
.createDataFrame(arrList).toDF("uid", "salary")
.createOrReplaceTempView("listB")
val resultBigDF = spark
.sql("SELECT userB.uid, name, salary FROM userB LEFT JOIN listA ON userB.uid = listA.uid")
resultBigDF.show()
resultBigDF.explain(true)
val resultSmallDF = spark
.sql("SELECT userA.uid, name, salary FROM userA LEFT JOIN listA ON userA.uid = listA.uid")
resultSmallDF.show()
resultSmallDF.explain(true)
val resultBigDF2 = spark
.sql("SELECT userB.uid, name, salary FROM userB LEFT JOIN listb ON userB.uid = listB.uid")
resultBigDF2.show()
resultBigDF2.explain(true)
Thread
.sleep(60 * 10 * 1000)
sparkContext.stop()
}
}
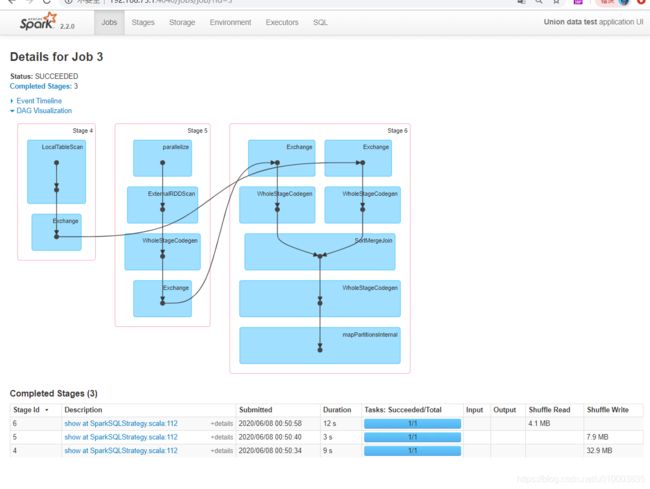
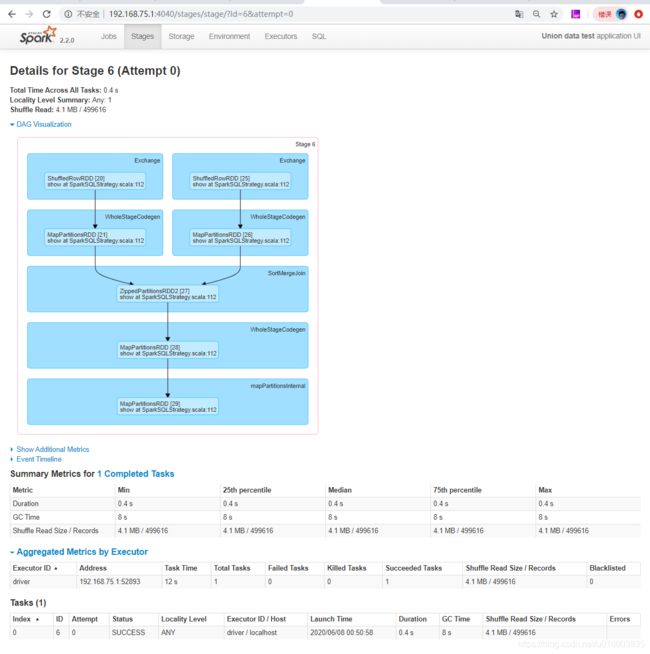
作业JOB划分

输出
+---+----+------+
|uid|name|salary|
+---+----+------+
| 1| sun| 62|
| 2| kk| 76|
| 3| sun| 64|
| 4| kk| 33|
| 5|zhen| 20|
| 6| hua| 17|
| 7| kk| 4|
| 8| cc| 62|
| 9| sun| 97|
| 10| sun| 87|
| 11| hua| 71|
| 12| kk| 42|
| 13| hua| 76|
| 14| sun| 93|
| 15|zhen| 7|
| 16| kk| 59|
| 17| hua| 98|
| 18| sun| 88|
| 19| cc| 49|
| 20| cc| 62|
+---+----+------+
only showing top 20 rows
== Parsed Logical Plan ==
'Project ['userB.uid, 'name, 'salary]
+- 'Join LeftOuter, ('userB.uid = 'listA.uid)
:- 'UnresolvedRelation `userB`
+- 'UnresolvedRelation `listA`
== Analyzed Logical Plan ==
uid: int, name: string, salary: int
Project [uid#58, name#59, salary#70]
+- Join LeftOuter, (uid#58 = uid#69)
:- SubqueryAlias userb
: +- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- SubqueryAlias lista
+- Project [_1#64 AS uid#69, _2#65 AS salary#70]
+- LocalRelation [_1#64, _2#65]
== Optimized Logical Plan ==
Project [uid#58, name#59, salary#70]
+- Join LeftOuter, (uid#58 = uid#69)
:- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- LocalRelation [uid#69, salary#70]
== Physical Plan ==
*Project [uid#58, name#59, salary#70]
+- *BroadcastHashJoin [uid#58], [uid#69], LeftOuter, BuildRight
:- *Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- Scan ExternalRDDScan[obj#52]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [uid#69, salary#70]
+---+----+------+
|uid|name|salary|
+---+----+------+
| 1| mm| 62|
| 2| cs| 76|
| 3| cc| 64|
| 4| px| 33|
| 5| kk| 20|
+---+----+------+
== Parsed Logical Plan ==
'Project ['userA.uid, 'name, 'salary]
+- 'Join LeftOuter, ('userA.uid = 'listA.uid)
:- 'UnresolvedRelation `userA`
+- 'UnresolvedRelation `listA`
== Analyzed Logical Plan ==
uid: int, name: string, salary: int
Project [uid#8, name#9, salary#70]
+- Join LeftOuter, (uid#8 = uid#69)
:- SubqueryAlias usera
: +- Project [_1#3 AS uid#8, _2#4 AS name#9]
: +- SerializeFromObject [assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1 AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, true) AS _2#4]
: +- ExternalRDD [obj#2]
+- SubqueryAlias lista
+- Project [_1#64 AS uid#69, _2#65 AS salary#70]
+- LocalRelation [_1#64, _2#65]
== Optimized Logical Plan ==
Project [uid#8, name#9, salary#70]
+- Join LeftOuter, (uid#8 = uid#69)
:- InMemoryRelation [uid#8, name#9], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas), `userA`
: +- *Project [_1#3 AS uid#8, _2#4 AS name#9]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#4]
: +- Scan ExternalRDDScan[obj#2]
+- LocalRelation [uid#69, salary#70]
== Physical Plan ==
*Project [uid#8, name#9, salary#70]
+- *BroadcastHashJoin [uid#8], [uid#69], LeftOuter, BuildRight
:- InMemoryTableScan [uid#8, name#9]
: +- InMemoryRelation [uid#8, name#9], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas), `userA`
: +- *Project [_1#3 AS uid#8, _2#4 AS name#9]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#4]
: +- Scan ExternalRDDScan[obj#2]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [uid#69, salary#70]
20/06/08 00:50:40 WARN TaskSetManager: Stage 4 contains a task of very large size (160161 KB). The maximum recommended task size is 100 KB.
20/06/08 00:50:43 WARN TaskSetManager: Stage 5 contains a task of very large size (20512 KB). The maximum recommended task size is 100 KB.
+---+----+------+
|uid|name|salary|
+---+----+------+
| 22|zhen| 40|
| 32|zhen| 81|
| 60| cc| 73|
| 90| cc| 12|
| 92|zhen| 90|
| 95| cc| 95|
|108| cc| 49|
|123| hua| 44|
|128| sun| 50|
|144|zhen| 63|
|148| cc| 2|
|153| cc| 64|
|155|zhen| 88|
|167| cc| 94|
|168| sun| 18|
|205| kk| 6|
|209| hua| 78|
|229| cc| 22|
|247| sun| 53|
|288| cc| 94|
+---+----+------+
only showing top 20 rows
== Parsed Logical Plan ==
'Project ['userB.uid, 'name, 'salary]
+- 'Join LeftOuter, ('userB.uid = 'listB.uid)
:- 'UnresolvedRelation `userB`
+- 'UnresolvedRelation `listb`
== Analyzed Logical Plan ==
uid: int, name: string, salary: int
Project [uid#58, name#59, salary#81]
+- Join LeftOuter, (uid#58 = uid#80)
:- SubqueryAlias userb
: +- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- SubqueryAlias listb
+- Project [_1#75 AS uid#80, _2#76 AS salary#81]
+- LocalRelation [_1#75, _2#76]
== Optimized Logical Plan ==
Project [uid#58, name#59, salary#81]
+- Join LeftOuter, (uid#58 = uid#80)
:- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- LocalRelation [uid#80, salary#81]
== Physical Plan ==
*Project [uid#58, name#59, salary#81]
+- SortMergeJoin [uid#58], [uid#80], LeftOuter
:- *Sort [uid#58 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(uid#58, 10)
: +- *Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- Scan ExternalRDDScan[obj#52]
+- *Sort [uid#80 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(uid#80, 10)
+- LocalTableScan [uid#80, salary#81]
分SQL分析
其中 userA 是小表 ,userB是大表 , listA是小表,listB是大表
阶段一
val resultBigDF = spark
.sql("SELECT userB.uid, name, salary FROM userB LEFT JOIN listA ON userB.uid = listA.uid")
resultBigDF.show()
resultBigDF.explain(true)
可以看到userB LEFT JOIN listA 是使用的Broadcast SHUFFLE JOIN
== Parsed Logical Plan ==
'Project ['userB.uid, 'name, 'salary]
+- 'Join LeftOuter, ('userB.uid = 'listA.uid)
:- 'UnresolvedRelation `userB`
+- 'UnresolvedRelation `listA`== Analyzed Logical Plan ==
uid: int, name: string, salary: int
Project [uid#58, name#59, salary#70]
+- Join LeftOuter, (uid#58 = uid#69)
:- SubqueryAlias userb
: +- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- SubqueryAlias lista
+- Project [_1#64 AS uid#69, _2#65 AS salary#70]
+- LocalRelation [_1#64, _2#65]== Optimized Logical Plan ==
Project [uid#58, name#59, salary#70]
+- Join LeftOuter, (uid#58 = uid#69)
:- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- LocalRelation [uid#69, salary#70]== Physical Plan ==
*Project [uid#58, name#59, salary#70]
+- *BroadcastHashJoin [uid#58], [uid#69], LeftOuter, BuildRight
:- *Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- Scan ExternalRDDScan[obj#52]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [uid#69, salary#70]
阶段二
val resultSmallDF = spark
.sql("SELECT userA.uid, name, salary FROM userA LEFT JOIN listA ON userA.uid = listA.uid")
resultSmallDF.show()
resultSmallDF.explain(true)
可以看到userA LEFT JOIN listA 使用的是Broadcast Hash JOIN
== Parsed Logical Plan ==
'Project ['userA.uid, 'name, 'salary]
+- 'Join LeftOuter, ('userA.uid = 'listA.uid)
:- 'UnresolvedRelation `userA`
+- 'UnresolvedRelation `listA`== Analyzed Logical Plan ==
uid: int, name: string, salary: int
Project [uid#8, name#9, salary#70]
+- Join LeftOuter, (uid#8 = uid#69)
:- SubqueryAlias usera
: +- Project [_1#3 AS uid#8, _2#4 AS name#9]
: +- SerializeFromObject [assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1 AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, true) AS _2#4]
: +- ExternalRDD [obj#2]
+- SubqueryAlias lista
+- Project [_1#64 AS uid#69, _2#65 AS salary#70]
+- LocalRelation [_1#64, _2#65]== Optimized Logical Plan ==
Project [uid#8, name#9, salary#70]
+- Join LeftOuter, (uid#8 = uid#69)
:- InMemoryRelation [uid#8, name#9], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas), `userA`
: +- *Project [_1#3 AS uid#8, _2#4 AS name#9]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#4]
: +- Scan ExternalRDDScan[obj#2]
+- LocalRelation [uid#69, salary#70]== Physical Plan ==
*Project [uid#8, name#9, salary#70]
+- *BroadcastHashJoin [uid#8], [uid#69], LeftOuter, BuildRight
:- InMemoryTableScan [uid#8, name#9]
: +- InMemoryRelation [uid#8, name#9], true, 10000, StorageLevel(disk, memory, deserialized, 1 replicas), `userA`
: +- *Project [_1#3 AS uid#8, _2#4 AS name#9]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#3, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#4]
: +- Scan ExternalRDDScan[obj#2]
+- BroadcastExchange HashedRelationBroadcastMode(List(cast(input[0, int, false] as bigint)))
+- LocalTableScan [uid#69, salary#70]

阶段三
val resultBigDF2 = spark
.sql("SELECT userB.uid, name, salary FROM userB LEFT JOIN listb ON userB.uid = listB.uid")
resultBigDF2.show()
resultBigDF2.explain(true)
userB LEFT JOIN listB ,大表之间关联使用的是 SortMergeJoin
== Parsed Logical Plan ==
'Project ['userB.uid, 'name, 'salary]
+- 'Join LeftOuter, ('userB.uid = 'listB.uid)
:- 'UnresolvedRelation `userB`
+- 'UnresolvedRelation `listb`== Analyzed Logical Plan ==
uid: int, name: string, salary: int
Project [uid#58, name#59, salary#81]
+- Join LeftOuter, (uid#58 = uid#80)
:- SubqueryAlias userb
: +- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(assertnotnull(input[0, scala.Tuple2, true]))._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- SubqueryAlias listb
+- Project [_1#75 AS uid#80, _2#76 AS salary#81]
+- LocalRelation [_1#75, _2#76]== Optimized Logical Plan ==
Project [uid#58, name#59, salary#81]
+- Join LeftOuter, (uid#58 = uid#80)
:- Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- ExternalRDD [obj#52]
+- LocalRelation [uid#80, salary#81]== Physical Plan ==
*Project [uid#58, name#59, salary#81]
+- SortMergeJoin [uid#58], [uid#80], LeftOuter
:- *Sort [uid#58 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(uid#58, 10)
: +- *Project [_1#53 AS uid#58, _2#54 AS name#59]
: +- *SerializeFromObject [assertnotnull(input[0, scala.Tuple2, true])._1 AS _1#53, staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, assertnotnull(input[0, scala.Tuple2, true])._2, true) AS _2#54]
: +- Scan ExternalRDDScan[obj#52]
+- *Sort [uid#80 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(uid#80, 10)
+- LocalTableScan [uid#80, salary#81]