SQL 语句继续学习之记录三
一,数据的插入(insert 语句的使用方法)
使用insert语句可以向表中插入数据(行)。原则上,insert语句每次执行一行数据的插入。
列名和值用逗号隔开,分别扩在()内,这种形式称为清单。
对表中所有列进行insert 操作时可以省略表名后的列清单。
插入null时需要在values子句的值清单中写入null。
可以为表中的列设定默认值(初始值)。默认值可以通过在create table语句中,为列设置default约束来设定。
插入默认值可以通过两种方式实现。即在insert语句的values子句中指定default关键字(显示方法),或省略列清单(隐式方法)。
使用 insert ...select 可以从其他表中复制数据。
1,什么是insert
通过create table 语句创建出来的表,可以将其比作一个空空如也的箱子,只有把数据装入到箱子中,它才能被称为数据库。
为了学习insert语句,我们创建一张新表,除了为hanbai_tanka 列(销售单价)设置了Default ) 的约束外,其他与之前的完全相同。

如上,仅仅创建了一张空表,还没有插入数据
2,insert 语句的基本语法
INSERT into <表名> (列1,列2,列3,...) values (值1,值2,值3,...);
由于shohin_id, shohin_mei,shohin_bunrui 列是字符型,所以插入的数据需要加单引号,torokubi是日期类型,也需要加单引号。
列清单—— (shohin_id,shohin_mei,shohin_bunrui,hanbai_tanka,shiire_tanka,torokubi)
值清单——('0001','T恤衫','衣服',1000,500,'2009-09-20')
注意,值清单中列的个数需和列清单中列的数量一致,否则语句错误。
并且,原则上,执行一次insert语句会插入一行数据。因此,插入多行时,通常需要循环执行所需次数的insert语句。但是关于多行insert,在部份DBMS中,支持如下多行insert 语句
insert into shoinIns values
('0002','打孔器','办公用品',500,320,'2009-09-11'),
('0003','运动T恤','衣服',4000,2800,null),
('0004','菜刀','厨房用具',3000,2800,'2009-09-20');如上,对表进行全列insert时,可以省略表名后的列清单。这时values子句的值会默认按照从左到右的顺序赋给每一列。
3,插入null
insert into shoinIns values
('0003','运动T恤','衣服',4000,2800,null),如上介绍中,insert语句中想要给某一列赋予null值时,可以直接在values子句的值清单中写入null,但是想要插入null的列一定不能设置not null 约束。
4,插入默认值
可以向表中插入默认值(初始值)。默认值的设定,可以通过在创建表的create table语句中设置default约束来实现。本次创建表语句时,
create table shoinIns
(shohin_id CHAR(4) not null,
shohin_mei VARCHAR(100) not null,
shohin_bunrui VARCHAR(32) not null,
hanbai_tanka INTEGER DEFAULT 0,
shiire_tanka INTEGER ,
torokubi DATE ,
primary key (shohin_id));其中hanbai_tanka integer Default 0, 意思就是为hanbai_tanka 列设置了0 这样的默认值,如果插入一行数据,在不提供值或者提供default值时,该值即为 0 。
有2中方式插入默认值,称为显示插入默认值或者隐式插入默认值。
1)显示插入默认值示例如下
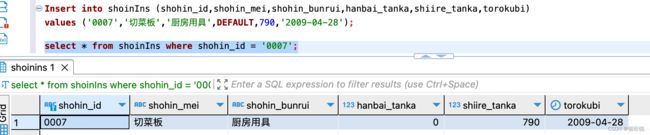
Insert into shoinIns (shohin_id,shohin_mei,shohin_bunrui,hanbai_tanka,shiire_tanka,torokubi)
values ('0007','切菜板','厨房用具',DEFAULT,790,'2009-04-28');上述Default 即为创建表时设置的 0,
2) 通过隐式方法插入默认值
插入默认值时可以不使用default关键字,只要在列清单和values 中省略设定了默认值的列即可
Insert into shoinIns (shohin_id,shohin_mei,shohin_bunrui,shiire_tanka,torokubi)
values ('0007','切菜板','厨房用具',790,'2009-04-28');但是注意,如果省略了没有设定默认值的列的话,该列的值就会被设定为null。如果省略的是设置了not null 约束列的话,insert语句就会出错。
如果设定默认值的列名被省略,就会自动设定为该列的默认值
如果没有设置默认值的列名被省略,就会自动设定为null
3) 从其他表中复制数据
除了使用values 子句指定具体的数据插入数据外,还可以从其他表中复制数据。如下示例
先创建一张表ShohinCopy表,表结构和shohin表完全一样
create table ShohinCopy
(shohin_id CHAR(4) not null,
shohin_mei VARCHAR(100) not null,
shohin_bunrui VARCHAR(32) not null,
hanbai_tanka INTEGER ,
shiire_tanka INTEGER ,
torokubi DATE ,
primary key (shohin_id));INSERT INTO ShohinCopy (shohin_id,shohin_mei,shohin_bunrui,hanbai_tanka,shiire_tanka,torokubi)
select shohin_id,shohin_mei,shohin_bunrui,hanbai_tanka,shiire_tanka,torokubi from shohin;
SELECT * from ShohinCopy;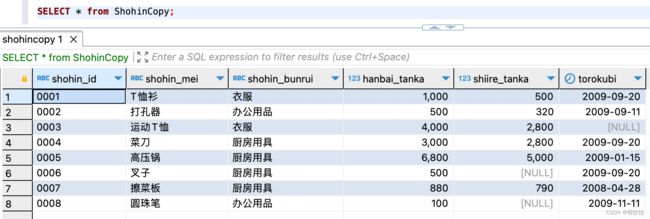
insert ...select 常用于数据备份
b insert 中多种多样的select
执行insert... select 时,select语句除了select... from ..外,还可以带其他的where, group by 等子句,之前学些到的select语句都可以使用。例如下面我们尝试将含有group by 的select 语句进行insert
创建ShohinBunrui 表的create table 语句
-- 创建ShohinBunrui 表的create table 语句
-- 用来汇总商品种类的表
create table ShohinBunrui
(shohin_bunrui varchar(32) not null,
sum_hanbai_tanka integer,
sum_shiire_tanka integer,
primary key (shohin_bunrui));该表是用来存储根据商品种类(shohin_bunrui) 计算出销售单价合计值以及进货单价合计值的表。我们从shohin表中取出数据放入该表中
INSERT into ShohinBunrui (shohin_bunrui,sum_hanbai_tanka,sum_shiire_tanka)
select shohin_bunrui,SUM(hanbai_tanka),SUM(shiire_tanka)
from shohin
group by shohin_bunrui;
二、数据的删除(delete 语句的使用方法)
如果想将整个表全部删除,可以使用drop table 语句;
如果只想删除表中全部数据,需使用delete 语句
如果想删除部份数据行,只需在where子句中书写对象数据的条件即可。
通过where子句指定删除对象的delete语句称为搜索型delete语句。
1,drop table 语句和delete语句
1)drop table 语句可以将表完全删除;
2)delete table 语句会留下表(容器),而删除表中的全部数据;
语法
1)drop table <表名>;
2)delete from <表名>;
2, 指定删除对象的delete 语句(搜索型delete)
想要删除表中部份数据行时,可以像使用where子句指定删除条件。指定了删除条件的delete语句称为搜索型delete。
删除部份数据行的搜索型delete语句语法
delete from <表名>
where <条件>;示例:假设我们要删除商品复制表中销售单价(hanbai_tanka) 大于等于4000的记录,即删除如下标记记录
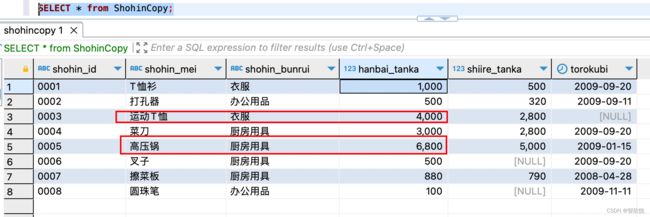
delete from ShohinCopy
where hanbai_tanka >= 4000;再次查询数据,结果即

千万需要注意的是,删除表中数据时(delete 语句),只能使用where 子句,不能使用其他的例如group by, having, order by 等子句,由于delete是对表中原始数据进行处理,group by,having是用来抽取数据时进行展示限定,order by 也是对从表中抽取数据后进行处理,所以这些句子都不能参与到delete 语句中
三,数据的更新(update 语句的使用方法)
使用update语句可以更新表中的数据
更新部份数据行时可以使用where来指定更新对象的条件。通过where子句指定更新对象的update语句称为搜索型update语句
update 语句可以将列的值更新为null
同时更新多列时,可以在update语句的set子句中,使用逗号分隔更新对象的多个列
1,update 语句的基本语法
update <表名>
set <列名> = <表达式>;示例,我们把商品(shohin )表中torokubi列(登记日期)的所有数据统一更新为“2009-10-10”
update shohin
set torokubi = '2009-10-10';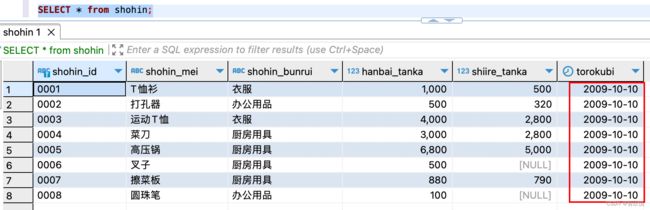
2, 通常情况,很少会直接将某列全部行数据更新为某个特定值,更多的是找到某一行或者某几行数据进行更新,此时就需要用到where 语句,类似delete语句中使用where指定条件一样。
示例,我们将商品表中厨房用具的销售单价更新为原来的10 倍,参考如下代码
update shohin
set hanbai_tanka = hanbai_tanka * 10
where shohin_bunrui = '厨房用具';3, 使用null进行更新
使用update 也可以将列更新为null(改更新俗称为null清空),此时只需要将赋值表达式右边的值直接写为null即可
示例:我们将商品编号(shohin_id) 为0008 的数据(圆珠笔)的登记日期(torokubi) 更新为null,
update shohin
set torokubi = NULL
where shohin_id = '0008';
注意:使用update 语句可以将值清空为null(但只限于未设置not null 约束的列)
4,多列更新
update 语句的set 语句支持同时将多个列作为更新对象。例如,我们刚将销售单价更新为原来的10 倍,如果我们希望同时将进货单价更新为原来的一半,可以考虑如下方案,
方案一, 将两个要求分两次完成,第一次只修改销售单价,第二次只修改进货单价;
方案二, 通过一个update 语句,将两个需求同时完成,此处有2种写法,但是由于一种方法并非所有DBMS支持,我们仅介绍一种所有DBMS都支持的方案实现,示例如下
UPDATE shohin
set hanbai_tanka = hanbai_tanka * 10,
shiire_tanka = shiire_tanka / 2
where shohin_bunrui = '厨房用具';四,事务
1,什么是事务
在RDBMS中,事务代表了对表中数据进行更新的单位。简单来说,事务就是需要在同一个处理单元中执行的一系列更新处理的集合。
对表进行更新需要使用insert,update, delete 三种语句。但通常情况下,更新处理并不是执行一次就结束了,而是需要执行一系列连续的操作。这时,事务的价值就要体现了。
最常见的示例就是,转账操作,转账操作意味着要两个操作,一个账户减少金额,另一个增加金额,这两个操作要全部完成,才意味着转账成功。转账就可以作为一个事务来看待。
2,创建事务
如果想在DBMS中创建事务,可以按照如下语法结构编写sql语句
事务开始语句,
DML 语句;
DML语句;
DML语句;
事务结束语句(commit 或者rollback);
使用事务开始语句和事务结束语句,将一系列DML语句(insert/update/delete语句)括起来,就实现了一个事务处理。
注意:在标准sql中并没有定义事务的开始语句,而是由各个DBMS自己来定义的。
mysql 的事务开始语句是start transaction
sql server 和postgreSQL 的开始语句是begin transaction
oracle 和DB2 没有开始语句
示例,假如我们将运动T恤的销售单价降低1000元,将T恤的销售单价上调1000 元,
将上述操作放在一个事务中处理,以mysql示例是
start transaction;
-- 将运动T恤的销售单价降低1000
update shohin
set hanbai_tanka = hanbai_tanka - 1000
where shohin_mei = '运动T恤';
-- 将T恤的销售单价上浮1000
update shohin
set hanbai_tanka = hanbai_tanka + 1000
where shohin_mei = 'T恤衫';
commit;在postgreSql 和sql Server 中,示例如下
Begin transaction;
-- 将运动T恤的销售单价降低1000
update shohin
set hanbai_tanka = hanbai_tanka - 1000
where shohin_mei = '运动T恤';
-- 将T恤的销售单价上浮1000
update shohin
set hanbai_tanka = hanbai_tanka + 1000
where shohin_mei = 'T恤衫';
commit;3,commit 提交处理
commit 是提交事务包含的全部更新处理的结束指令。相当于文件处理中的覆盖保存。一旦提交,就无法恢复到事务开始前的状态了。因此,在提交之前一定要确认是否真的需要进行这些更新。
万一由于误操作提交了包含错误更新的事务,就只能重新回到重新建表、重新插入数据这样繁琐的老路上了。由于可能会造成数据无法恢复的后果,请大家一定要注意。
4,rollback——取消处理
rollback 是取消事务包含的全部更新处理的结束指令。想当于文件处理中的放弃保存。一旦回滚,数据库就会恢复到事务开始之前的状态。通常回滚并不会像提交那样造成打鬼吗的数据损失。
如下, 表中的数据不会发生任何更新,因为事务未被提交,直接被回滚了
start transaction;
-- 将运动T恤的销售单价降低1000
update shohin
set hanbai_tanka = hanbai_tanka - 1000
where shohin_mei = '运动T恤';
-- 将T恤的销售单价上浮1000
update shohin
set hanbai_tanka = hanbai_tanka + 1000
where shohin_mei = 'T恤衫';
rollback;5,事务处理何时开始
几乎所有的数据库产品的事务都无需开始指令。这是因为大部分情况下,事务在数据库连接建立时就已经悄悄开始了,并不需要用户再明确发出开始指令。例如,oracle 数据库连接建立之后,第一条sql 语句执行的同时,事务就已经开始了。像这样不使用指令而悄悄开始事务的情况下,应该如何区分各个事务呢?通常会有如下两种情况。
A:每条sql语句就是一个事务(自动提交模式);
B: 直到用户执行commit或者rollback为止算做一个事务。
在默认使用B模式的oracle中,事务都是直到用户自己执行提交或者回滚指令才会结束。
自动提交的情况需要特别注意的是delete语句。如果不是自动提交,即使使用delete语句删除了数据表,也可以通过rollback命令取消该事务的处理,恢复表中的数据。但这仅限于明示开始事务,或者关闭自动提交的情况,如果不小心在自动模式下执行了delete操作,即使再回滚也无济于事了。
6, ACID 特性
DBMS的事务都遵循四种标准规格的约定。将这四种特性的首字母结合起来统称为ACID特性。这些约定是所有DBMS都必须遵守的规则。这些约定是所有DBMS都必须遵守的规则。
1)原子性(Atomicity)
原子性是指在事务结束时,其中所包含的更新处理要么全部执行,要么完全不执行的特性。例如前面示例中,运动T恤价格降低,T恤价格价格上涨,如果放在一个事务中处理,必须遵守运动T恤价格降低,T恤价格上涨这两个事情全部完成,或者这两个商品价格都不变。不可能出现运动T恤价格改变(commit),但是T恤价格没有变动(rollback)的情况。
2)一致性(Consistency)
一致性指的是事务中包含的处理,要满足数据库提前设置的约束,如主键约束或者not null 约束等。例如,设置了not null 约束的列是不能更新为null的,试图插入违反主键约束的记录就会出错,无法执行,对事务来说,这些不合法的sql会被回滚。也就是说这些sql处理会被取消,不会执行。
一致性也称为完整性。
3) 隔离性(Isolation)
隔离性指的是保证不同事务之间互不干扰的特性。该特性保证了事务之间不会互相嵌套。此外,在某个事务中进行的更改,在该事务结束之前,对其他事务而言是不可见的。因此,即使某个事务向表中添加了记录,在没有提交之前,其他事务是看不到新添加的记录的。
4)持久性(Durability)
持久性也可以称为耐久性,指的是事务(不论是提交还是会滚)一旦结束,DBMS会保证该时点的数据状态得以保存的稳定性。即使由于系统故障导致数据丢失,数据库也一定能通过某种手段进行恢复。
如果不能保证持久性,即使是正常提交结束的事务,一旦发生了系统故障,就会导致数据丢失,一切都需要从头再来的后果。
保证持久性的方法根据实现的不同而不同,其中最常见的就是将事务的执行记录保存到硬盘等存储介质中(该执行记录称为日志)。当发生故障时,可以通过日志恢复到故障发生前的状态。