背景
在当下开源大语言模型火热的背景下,有很大一部分开发者希望本地部署开源 LLM ,用于研究 LLM 或者是基于开源 LLM 构建自己的 LLM 应用。笔者也正在尝试通过开源社区的一系列相关优秀项目,通过本地化部署服务来构建自己的 LLM 应用。那么本地部署一个开源 LLM 来构建一个聊天应用需要哪些准备呢?
- 本地环境的准备: 因为我们需要在本地部署一个开源的大模型,所以你需要准备一个相当硬核的本地环境。硬件上需要一台拥有高性能大显存的 NVDIA 显卡、大容量高速内存以及大容量固态硬盘,软件上则需要安装显卡驱动、CUDA、Python 环境。笔者这次选择跑 Baichuan-chat-13B 模型为例,我的基本配置是 CPU i9-13900K、GTX3090 24GB双卡、64GB 内存和 2TB 固态硬盘。
- 一个大型语言模型(LLM) :这是我们构建 LLM 应用的基础。不同的 LLM 根据预训练的数据和目标任务的不同,其模型结构和学到的知识也不相同。基于不同模型构建出来的 AI 应用表现也会不一样。你可以通过火热的 AI 社区 Hugging Face 上找自己感兴趣的开源 LLMs 来进行尝试和能力对比 。
- 一个 本地部署 LLM 的推理服务 : 推理服务可以将预训练好的 LLM 模型加载到本地服务器,并提供模型预测接口,这样就可以本地化使用 LLM 模型进行各种 NLP 任务,而不需要依赖云服务。你可以使用一些优秀的 GitHub 开源项目,这些项目对热门的开源 LLM 都做了推理服务的一键部署。知名度比较高、star 比较多的有 LocalAI、openLLM 等。
- 一个简单易用的“ LLM 操作系统”Dify.AI:如果要基于 LLM 的能力构建一个聊天应用,你可能需要学习研究全套的 LLM 技术栈,比如:不同模型的 API 调用、向量数据库选型、embedding 技术研究等等。如果你使用开源项目 Dify.AI(https://github.com/langgenius/dify) ,则可以省掉这些研究学习工作,帮助你通过可视化的界面即可快速创建基于不同 LLM 能力的 AI 应用。 Dify 最近的版本新增了对开源 LLMs 的支持,对托管在 HuggingFace 和 Replicate 上所有的模型都能快速调用和切换使用,同时支持本地部署方式能够基于 openLLM 和 Xorbits inference 推理服务来实现 AI 应用的构建。
本文笔者将尝试使用开源的 LLMOps 平台 Dify.AI + 开源的推理服务 Xinference + 开源模型 baichuan-chat-13B 为例,手把手实操教你在 windows 环境下,使用全套开源工具产品来构建一个 LLM 聊天应用。话不多说我们直接开工。
环境准备
基本的 conda 和 Python 一般应该都有了。不过本文还是从零开始介绍环境配置吧。
配置 python 环境
一般情况下建议使用 conda 进行 python 版本管理。先根据 conda 官网文档安装 conda。然后用 conda 初始化 Python 3.11 环境:
conda create --name python-3-11 python=3.11
conda activate python-3-11安装 CUDA
推荐直接从官网安装。我这是 Windows 11 就选下图版本。
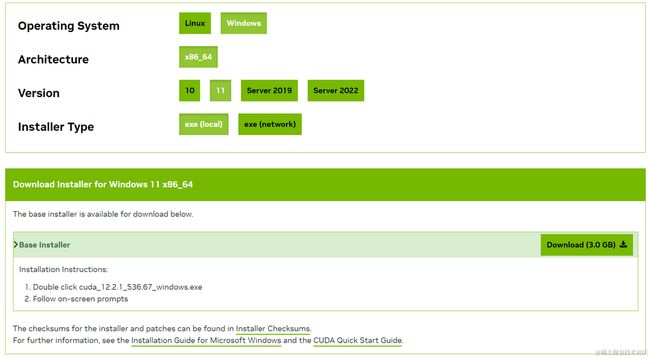
根据引导安装完,打开 NVDIA 控制面板 -> 系统信息 看到装上了。

WSL2 准备
由于 Dify 的 docker 部署推荐使用 WSL2 环境。所以现在先安装 WSL2 。参考微软官方指引。
第一步,管理员身份运行 CMD :

第二步,在 CMD 中用指令安装
wsl --install结果看到了支持的各种系统版本
适用于 Linux 的 Windows 子系统已安装。 以下是可安装的有效分发的列表。 请使用“wsl --install -d <分发>”安装。 NAME FRIENDLY NAME Ubuntu Ubuntu Debian Debian GNU/Linux kali-linux Kali Linux Rolling Ubuntu-18.04 Ubuntu 18.04 LTS Ubuntu-20.04 Ubuntu 20.04 LTS Ubuntu-22.04 Ubuntu 22.04 LTS OracleLinux_7_9 Oracle Linux 7.9 OracleLinux_8_7 Oracle Linux 8.7 OracleLinux_9_1 Oracle Linux 9.1 openSUSE-Leap-15.5 openSUSE Leap 15.5 SUSE-Linux-Enterprise-Server-15-SP4 SUSE Linux Enterprise Server 15 SP4 SUSE-Linux-Enterprise-15-SP5 SUSE Linux Enterprise 15 SP5 openSUSE-Tumbleweed openSUSE Tumbleweed
我使用选择安装了默认的 Ubuntu 版本:
wsl --install -d Ubuntu之后就可以在 CMD 中使用 wsl命令进入Ubuntu 了。
第三步,安装 Docker Desktop
去 Docker 官方文档下载 Docker Desktop。安装时注意勾上
Use WSL 2 instead of Hyper-V选项。安装完成后重启电脑。通过 CMD 查看是否正常安装好。wsl -l --verbose NAME STATE VERSION * Ubuntu Running 2 docker-desktop Running 2
可以看到 WSL 中 Ubuntu 和 Docker 都运行起来了,并且确认是 WSL2 版本。第四步,为 WSL 配置代理
由于每次重启后 WSL 的 ip 地址都会变更,所以我们可以编写一个脚本来解决。第 4 行改为你自己的端口号。
#!/bin/sh hostip=$(cat /etc/resolv.conf | grep nameserver | awk '{ print $2 }') wslip=$(hostname -I | awk '{print $1}') port=7890 PROXY_HTTP="http://${hostip}:${port}" set_proxy(){ export http_proxy="${PROXY_HTTP}" export HTTP_PROXY="${PROXY_HTTP}" export https_proxy="${PROXY_HTTP}" export HTTPS_proxy="${PROXY_HTTP}" export ALL_PROXY="${PROXY_SOCKS5}" export all_proxy=${PROXY_SOCKS5} git config --global http.https://github.com.proxy ${PROXY_HTTP} git config --global https.https://github.com.proxy ${PROXY_HTTP} echo "Proxy has been opened." } unset_proxy(){ unset http_proxy unset HTTP_PROXY unset https_proxy unset HTTPS_PROXY unset ALL_PROXY unset all_proxy git config --global --unset http.https://github.com.proxy git config --global --unset https.https://github.com.proxy echo "Proxy has been closed." } test_setting(){ echo "Host IP:" ${hostip} echo "WSL IP:" ${wslip} echo "Try to connect to Google..." resp=$(curl -I -s --connect-timeout 5 -m 5 -w "%{http_code}" -o /dev/null www.google.com) if [ ${resp} = 200 ]; then echo "Proxy setup succeeded!" else echo "Proxy setup failed!" fi } if [ "$1" = "set" ] then set_proxy elif [ "$1" = "unset" ] then unset_proxy elif [ "$1" = "test" ] then test_setting else echo "Unsupported arguments." fi可以修改
~/.bashrc方便使用命令:alias proxy="source /path/to/proxy.sh"
第五步,进入 Ubuntu 安装 conda 配置 python
和前面的环境准备一样,参照官方文档安装 conda 配置 python,不过是安装 linux 版本。
第六步,安装 WSL 的 CUDA
进入官网,选择 WSL-Ubuntu 版本,按照指引使用命令行安装。

修改~/.bashrc将 CUDA 添加至环境变量:export LD_LIBRARY_PATH=/usr/local/cuda-12.2/lib64
第七步,安装 PyTorch
进入 PyTorch 官网,按照环境安装 PyTorch 。
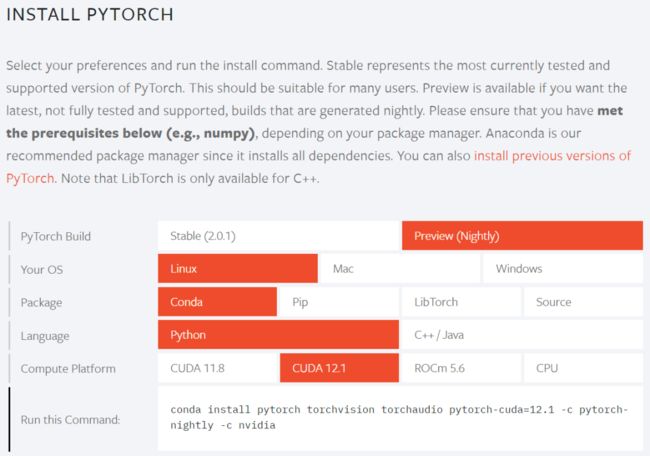
这样环境准备总算完成了。
部署推理服务 Xinference
根据 Dify 的部署文档,Xinference 支持的模型还挺多的。这次就选 Xinference 尝试下 baichuan-chat-3B 吧。
Xorbits inference 是一个强大且通用的分布式推理框架,旨在为大型语言模型、语音识别模型和多模态模型提供服务,甚至可以在笔记本电脑上使用。它支持多种与GGML兼容的模型,如 ChatGLM, Baichuan, Whisper, Vicuna, Orca 等。 Dify 支持以本地部署的方式接入 Xinference 部署的大型语言模型推理和 embedding 能力。
安装 Xinfernece
在 WSL 中执行如下命令:
$ pip install "xinference"上面的命令会安装 Xinference 用于推理的基础依赖。Xinference 还支持用 ggml 推理 和 PyTorch 推理,需要装如下的依赖:
$ pip install "xinference[ggml]"
$ pip install "xinference[pytorch]"
$ pip install "xinference[all]"启动 Xinference 并下载部署 baichuan-chat-3B 模型
在 WSL 中执行下面的命令:
$ xinference -H 0.0.0.0Xinference 默认会在本地启动一个 worker,端点为:http://127.0.0.1:9997,端口默认为 9997。 默认只可本机访问,配置了 -H 0.0.0.0,非本地客户端可任意访问。 如需进一步修改 host 或 port,可查看 xinference 的帮助信息:xinference --help。
2023-08-25 18:08:31,204 xinference 27505 INFO Xinference successfully started. Endpoint: http://0.0.0.0:9997
2023-08-25 18:08:31,204 xinference.core.supervisor 27505 INFO Worker 0.0.0.0:53860 has been added successfully
2023-08-25 18:08:31,205 xinference.deploy.worker 27505 INFO Xinference worker successfully started.在浏览器中打开: http://localhost:9997,选择 baichuan-chat,pytorch,13B,4bit,点击 create 部署。

或者使用 CLI 部署:
xinference launch --model-name baichuan-chat --model-format pytorch --size-in-billions 13 --quantization 4由于不同模型在不同硬件平台兼容性不同,请查看 Xinference 内置模型 确定创建的模型是否支持当前硬件平台。
使用 Xinference 管理模型
要查看部署好的所有模型,在命令行中,执行下面的命令:
$ xinference list 会显示类似下面的信息:
UID Type Name Format Size (in billions) Quantization
------------------------------------ ------ ------------- -------- -------------------- --------------
0db1e250-4330-11ee-b9ef-00155da30d2d LLM baichuan-chat pytorch 13 4-bit0db1e250-4330-11ee-b9ef-00155da30d2d 就是刚才部署的模型的 uid 。
部署 Dify.AI
主要流程参考官网部署文档。
Clone Dify
Clone Dify 源代码至本地
git clone https://github.com/langgenius/dify.gitStart Dify
进入 dify 源代码的 docker 目录,执行一键启动命令:
cd dify/docker
docker compose up -d部署结果:
[+] Running 7/7
✔ Container docker-weaviate-1 Running 0.0s
✔ Container docker-web-1 Running 0.0s
✔ Container docker-redis-1 Running 0.0s
✔ Container docker-db-1 Running 0.0s
✔ Container docker-worker-1 Running 0.0s
✔ Container docker-api-1 Running 0.0s
✔ Container docker-nginx-1 Started 0.9s 最后检查是否所有容器都正常运行:
docker compose ps运行状态:
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
docker-api-1 langgenius/dify-api:0.3.16 "/bin/bash /entrypoi…" api 24 hours ago Up 3 hours 5001/tcp
docker-db-1 postgres:15-alpine "docker-entrypoint.s…" db 33 hours ago Up 3 hours 0.0.0.0:5432->5432/tcp
docker-nginx-1 nginx:latest "/docker-entrypoint.…" nginx 24 hours ago Up 4 minutes 0.0.0.0:80->80/tcp
docker-redis-1 redis:6-alpine "docker-entrypoint.s…" redis 33 hours ago Up 3 hours 6379/tcp
docker-weaviate-1 semitechnologies/weaviate:1.18.4 "/bin/weaviate --hos…" weaviate 33 hours ago Up 3 hours
docker-web-1 langgenius/dify-web:0.3.16 "/bin/sh ./entrypoin…" web 33 hours ago Up 3 hours 3000/tcp
docker-worker-1 langgenius/dify-api:0.3.16 "/bin/bash /entrypoi…" worker 33 hours ago Up 3 hours 5001/tcp包括 3 个业务服务 api / worker / web,以及 4 个基础组件 weaviate / db / redis / nginx。
Docker 启动成功后,在浏览器中访问:http://127.0.0.1/。设置过密码,登陆后,会进入应用列表页。
至此,成功使用 Docker 部署了 Dify 社区版。
在 Dify 接入 Xinference
配置模型供应商
在 设置 > 模型供应商 > Xinference 中填入模型信息:
- Model Name 是你自己起给模型部署的名字。
- Server URL 是 xinference 的 end point 地址。
- Model UID 则是通过
xinference list获取到的部署的模型的 UID
需要注意的是 Sever Url 不能用 localhost。因为如果填 localhost,访问的是 docker 里的 localhost,会导致访问失败。解决方案是将 Sever Url 改成局域网 ip。
而 WSL 环境下则需要使用 WSL 的 IP 地址。
在 WSL 中使用命令获取:
hostname -I
172.31.157.121
使用 baichuan-chat
创建应用,就可以在应用中使用上一步配置的 baichuan-chat-3B 模型啦。在 Dify 的提示词编排界面,选择 baichuan-chat 模型,设计你的应用提示词(prompt),即可发布一个可访问的 AI 应用。
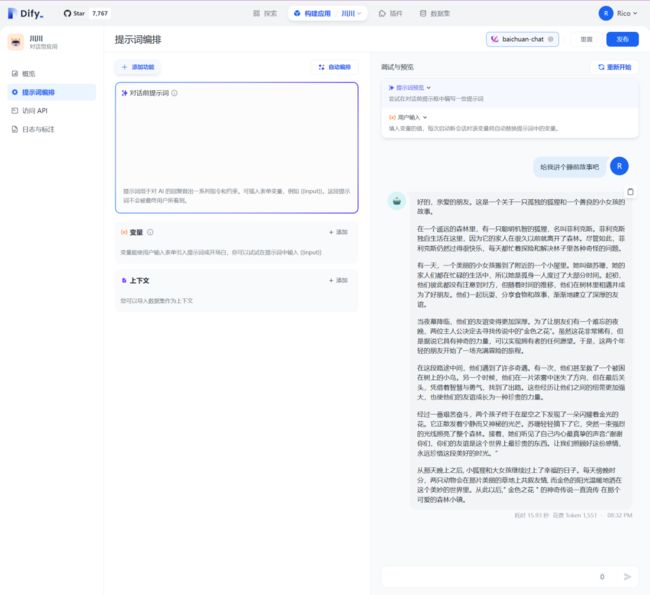
以上,就是本地部署 Dify 接入 Xinference 部署的 baichuan-chat 的全过程。 至此,我们基于 baichuan-chat-13B 的一个基本的聊天应用就基本完成了。
后记
当然,对于一个生产级别的 LLM 应用来说,只是完成大模型的接入和推理、聊天交互是远远不够。我们还需要针对性的对 LLM 进行 Prompt 的调优、添加私有数据作为上下文,亦或者是对 LLM 本身进行微调等工作,这需要长期的迭代和优化才能使得 LLM 应用表现越来越好。Dify.AI 作为一个中间件工具平台,提供了一个完整 LLM App 技术栈的可视化的操作系统。完成了以上的基础服务部署后,后续的应用迭代和改进都可以基于 Dify 来完成,使得 LLM 应用的构建和管理变得更加简单和易用,在业务数据的处理上直接上传即可自动完成清洗处理,后续也将提供数据标注和改进的服务,甚至你的业务团队都可以参与协作。
目前 LLM 的发展和应用落地还处于非常早期的阶段,相信在不久后,无论是 LLM 的能力释放,还是基于 LLM 之上的各个工具能力的不断完善,都会不断降低开发者探索 LLM 能力的门槛,让更多丰富场景的 AI 应用涌现。